【プチ論文読み】OpenAI CLIPについて
最近のVision & Languageモデルの画像エンコード部分で頻繁に使われているCLIPの論文を読みつつまとめます。
ただこの論文、実験等が非常に多くボリュームがすごいため、そもそもどういうもので、何がすごいのか?といった観点をまとめて行きます。
まとめ
- 言語と画像のマルチモーダルモデル
- インターネットから収集した画像とテキストの40億ペアからなるデータセットを使って学習し、多くの下流タスクに対するZero Shot性能を高めることが可能になった
モチベーション?
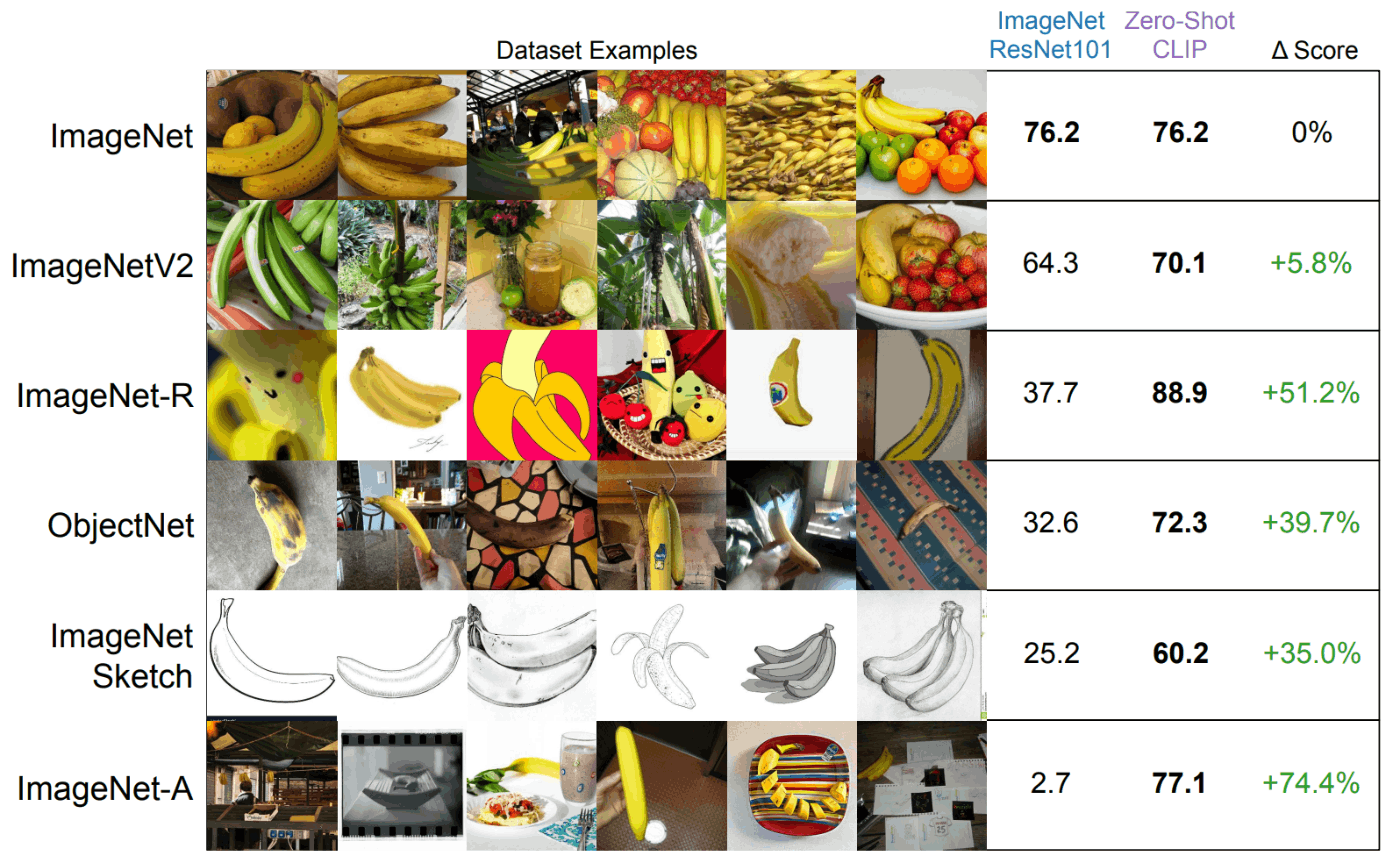
そもそも自然言語の世界ではGPT-3でゼロショット転移が可能になっていました。コンピュータビジョンの分野では、ImageNetなどのラベル付きデータ(犬, 猫, ...など)で学習するのが一般的ですが、これは拡張性が低いという問題があります。
どういうことかというと、犬とか猫とかラベルつけされたデータで学習したモデルは、犬と猫を判定するタスクに最適化されていて、別の用途に使用しようと思うとデータの作成とモデル作成からやり直す必要があります。
この問題を解決しようというのがCLIPになります。
といいつつも、過去に似たような研究はあったそうです。
-
Mori, Y et al., Image-to-word transformation based on dividing and vector quantizing images with words. Citeseer, 1999.
- 画像とペアになったテキストドキュメントの中の名詞や形容詞を予測することで、コンテンツベースの画像検索を改善する方法を探求
-
Joulin, A et al., Learning visual features from large weakly supervised
data. 2016.- 画像キャプション内の単語を予測するために訓練されたCNNが有用な画像表現を学習する
-
Li, A et al., Learning visual n-grams from web data. 2017.
- 個々の単語だけでなくフレーズを予測し、学習した視覚情報のに基づいてターゲットクラスのスコアリングを行い、ゼロショットで他の画像分類データセットに転移できるシステムを考案
ですが、2021年の時点では自然言語の教師情報をしようして画像を学習するというアプローチは非常に稀でした。理由は単純にベンチマークに対する精度がかなり低いからと予想されていました。
上記3の研究ですらImageNetに対して11.5%で、SOTAの90%近いスコアと比較して精度が低いことは明らかです。
何をしたのか?
考え方
アプローチとしては自然言語に含まれる教師データから知覚を学習するというものです。
自然言語から学習することで...
- 教師データがスケールしやすく拡張性が非常に高い
- 画像と言語を結びつけることでゼロショット転移を可能にする
というメリットがあります。
アーキテクチャ
テキストがどの画像とペアになるかを予測を行います。
下の図は論文に記載のある図ですが、学習時の全体像を表しています。
具体的には N 個のバッチが与えられたら、画像 N 個とテキスト N 個で N x N の組み合わせがありますが、実際のペアになる組み合わせ(対角成分)のコサイン類似度が最大化するように、一方ペアではない組み合わせ(非対角成分)のコサイン類似度が最小化するように Text Encoder と Image Encoder を学習します。
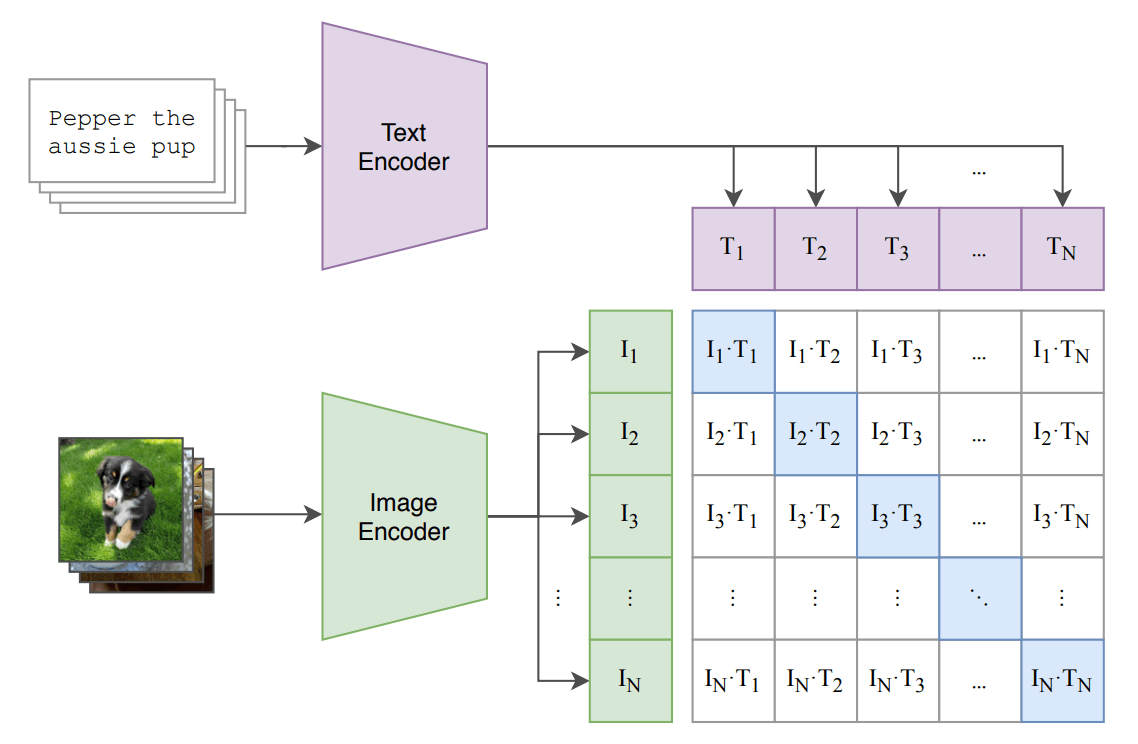
Image EncoderはVision Transfomerベースで、Text EncoderはTransfomerベースのモデルとなっています。
論文に記載のある以下のコードも解説します。

# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
- image_encoder
- 画像をエンコードする部分
- ResNetやVision Transformerを用いる
- text_encoder
- テキストをエンコードする部分
- CBOW(Continuous Bag of Words)やText Transformerを用いる
I_f = image_encoder(I) # [n, d_i]
T_f = text_encoder(T) # [n, d_t]
-
I_f- 画像をエンコードした後の特徴表現
-
Shape = [n, d_i]-
nはミニバッチのサイズ -
d_iは画像のエンコード後の次元
-
-
T_f- テキストをエンコードした後の特徴表現
-
Shape = [n, d_t]-
nはミニバッチのサイズ -
d_tはテキストのエンコード後の次元
-
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
I_f と T_f をそれぞれ学習された重み W_i と W_t で線形変換し、画像とテキストの共通の埋め込み空間(I_e, T_e)にマッピングしています。
L2正規化により、各ベクトルを単位ベクトルに変換して、コサイン類似度が適切に計算されるようにしています。
logits = np.dot(I_e, T_e.T) * np.exp(t)
ここでは、画像とテキストのペアの類似度を計算しています。
I_e(画像の埋め込み)と T_e(テキストの埋め込み)を内積し、これに学習されたスケールパラメータ t の指数関数でスケールをかけています。
この内積の結果が、ペアごとの類似度(コサイン類似度)を反映しています。
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t) / 2
labels には、各ペアに対する正解のインデックスが入ります。たとえば、labelsが [0, 1, 2, ..., n-1] のように設定され、各画像は対応するテキストと正しいペアになるようにしています。
loss_i は、画像を基準にしたクロスエントロピー損失で、logits のコサイン類似度を用いて、画像のエンコード結果とテキストのエンコード結果を比較しています(axis=0)。
loss_t は、テキストを基準にしたクロスエントロピー損失で、テキストのエンコード結果を画像のエンコード結果と比較しています(axis=1)。
loss は、これら2つの損失を平均して全体の損失を計算しています。
データセット
これまでは、MS-COCO, Visual Genomeなどのデータセットが使用されてきましたが、
例えばMS-COCOは約10万枚のデータセットしかなく、現代のデータセットとしては小規模です。
CLIPでは自然言語から学習するという話がありましたが、嬉しいことにインターネット上には自然言語が大量に公開されているので、インターネットから集めて4億ペアの画像とテキストのデータセットを作成しました。
何ができるようになったのか?
ゼロショット転移
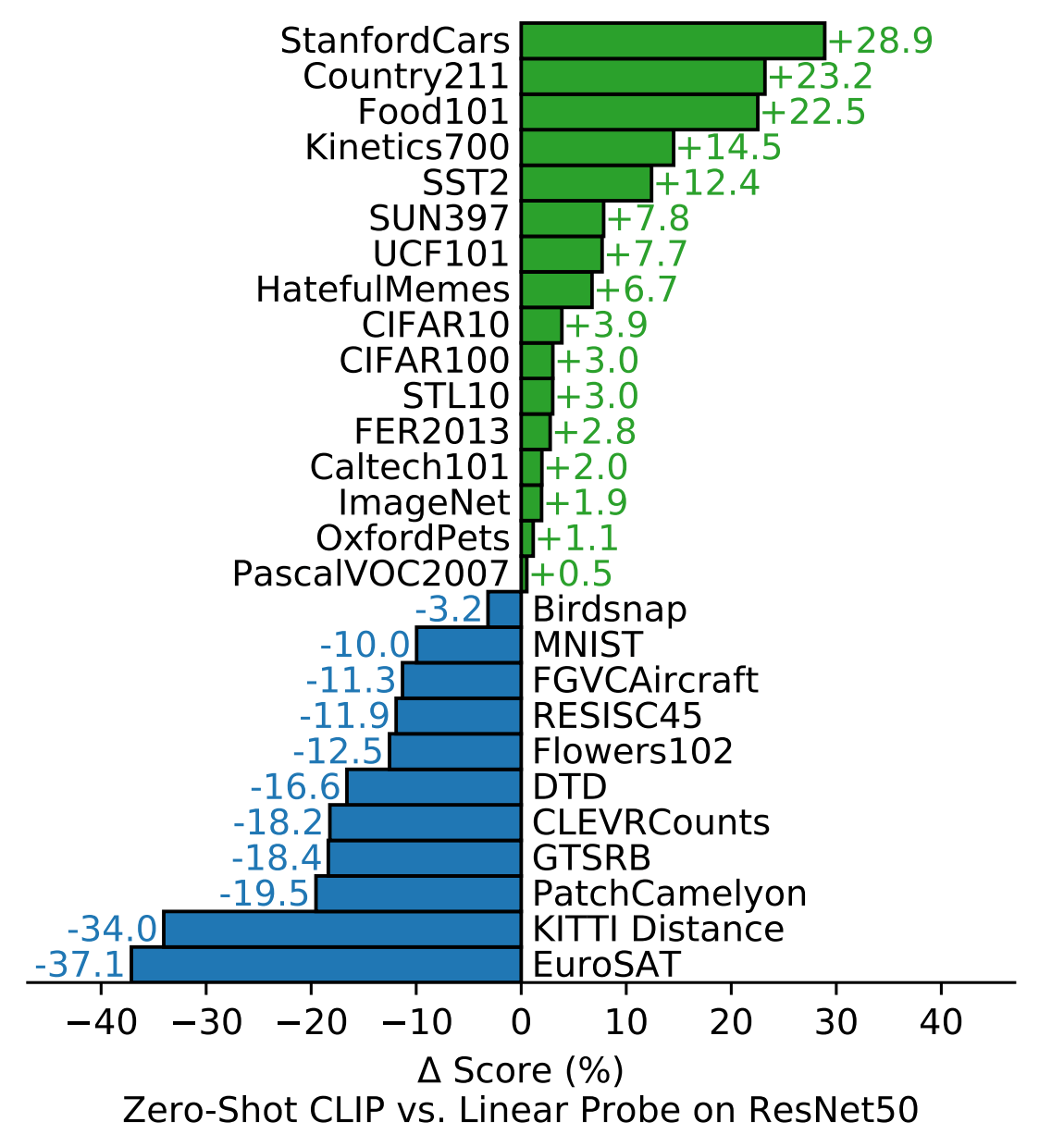
教師あり学習モデルのResNet-50と比較したところ、27個のデータセットで16勝という結果が得られました。
一方で、リンパ腫瘍の検出(PatchCamelyon)やドイツの道路交通標識(GTSRB)など特定の分野に特化したデータセットでは精度が出ませんでした。
表現学習能力比較
複数のデータセットでの評価を、いくつかのモデルでスケールを変えながら比較していますが、スケールに関係なくCLIPは全てのモデルを上回っています。
(スケール小のCLIP vs スケール大のEfficientNetなら後者ですが、スケールを揃えるとCLIPの方が良い)

推論の時の流れ
画像をInputして分類タスクをすることを考えます。
- データセットを作成する
- ラベルをText Encoderに入れますが、その前に
A Photo of a ~という形にします - 上記をすると事前学習と推論時のラベルが近くなり精度が改善したとのことです
- ラベルをText Encoderに入れますが、その前に
- 推論する
- 画像をInputしてImage Encoderに入れます
- 1で作成したN個のラベルのどれと近いかを計算し、画像分類を行います

その他
GPUが手元にあればこれで遊べそうですね
Discussion