チュートリアル: TerraformによるAWSマルチアカウント構築
TerraformによるAWSマルチアカウント構築
プロジェクトの概要
このAWS Terraformプロジェクトは、複数の環境(開発、ステージング、本番)と各環境内の複数のクライアント企業のAWSインフラストラクチャをコードとして管理するためのものです。
プロジェクトの目的
- 複数環境と複数クライアント企業のAWSインフラストラクチャの一貫した管理
- インフラストラクチャのバージョン管理と再現性の確保
- クライアントごとのコスト管理とモニタリング
- デプロイメントの自動化と効率化
- セキュリティとコンプライアンスの強化
最終的なファイル・フォルダ構造
aws-terraform/
├── .github
│ └── workflows
│ ├── terraform.yml
│ └── lambda.yml
├── .gitignore
├── LICENSE
├── README.md
├── environments
│ ├── dev
│ │ ├── backend.tf
│ │ ├── clients
│ │ │ ├── mew
│ │ │ │ ├── main.tf
│ │ │ │ └── variables.tf
│ │ │ └── pikachu
│ │ │ ├── main.tf
│ │ │ └── variables.tf
│ │ ├── main.tf
│ │ ├── terraform.tfvars
│ │ ├── variables.tf
│ │ └── versions.tf
│ ├── prod
│ └── staging
├── infra_base
│ ├── main.tf
│ ├── outputs.tf
│ ├── terraform.tfvars
│ └── variables.tf
├── modules
│ ├── async_processing
│ │ ├── function.zip
│ │ ├── lambda
│ │ │ ├── index.js
│ │ │ ├── package-lock.json
│ │ │ └── package.json
│ │ ├── main.tf
│ │ ├── outputs.tf
│ │ └── variables.tf
│ └── network
│ ├── main.tf
│ ├── outputs.tf
│ └── variables.tf
└── scripts
├── terraform-ops.sh
└── package-lambda.sh
チュートリアル手順
1. プロジェクトの初期設定
1.1. プロジェクトディレクトリの作成
mkdir aws-terraform
cd aws-terraform
1.2. Gitリポジトリの初期化
git init
1.3. .gitignoreファイルの作成
touch .gitignore
.gitignoreファイルに以下の内容を追加します:
# .gitignore
# Terraformの一時ファイルやディレクトリを無視する
**/.terraform/*
*.tfstate
*.tfstate.*
crash.log
*.tfvars
!terraform.tfvars
.terraformrc
terraform.rc
# その他の一般的な無視ファイル
.DS_Store
*.log
*.bak
# Lambda関連のファイルを無視する
**/node_modules/
*.zip
modules/async_processing/function.zip
# 環境固有の設定ファイルを無視する(必要に応じて)
# environments/**/terraform.tfvars
# IDEやエディタの設定ファイルを無視する
.vscode/
.idea/
*.swp
*.swo
# OS生成ファイルを無視する
Thumbs.db
# AWS CLIの設定ファイルを無視する(セキュリティのため)
.aws/
# スクリプトの一時ファイルや出力を無視する
scripts/*.log
scripts/*.out
# Terraformのプランファイルを無視する
**/tfplan
# その他のプロジェクト固有の一時ファイルや出力ディレクトリ
/tmp/
/output/
2. Terraformの状態保存用リソースの作成
2.1. infra_baseディレクトリの作成
mkdir -p infra_base
cd infra_base
2.2. 必要なファイルの作成
touch main.tf variables.tf terraform.tfvars outputs.tf
infra_base/main.tfファイルに以下の内容を追加します:
# infra_base/main.tf
# AWSプロバイダーの設定
# これにより、AWSのリソースを操作できるようになります
provider "aws" {
region = "ap-northeast-1" # 東京リージョンを使用します
}
# 現在のAWSアカウントIDを取得します
# これは、リソース名にアカウントIDを含めるために使用されます
data "aws_caller_identity" "current" {}
# Terraformの状態を保存するS3バケットを作成します
# このバケットは、Terraformが管理するインフラの状態を保存するために使用されます
resource "aws_s3_bucket" "terraform_state" {
# バケット名にはアカウントIDを含めて、一意性を確保します
bucket = "terraform-state-${data.aws_caller_identity.current.account_id}"
# タグを設定します。これにより、AWSコンソールでリソースを識別しやすくなります
tags = {
Name = "terraform-state-${data.aws_caller_identity.current.account_id}"
Project = var.project_name
ManagedBy = "Terraform"
}
}
# S3バケットのバージョニングを有効にします
# これにより、状態ファイルの変更履歴を保持できます
resource "aws_s3_bucket_versioning" "terraform_state" {
bucket = aws_s3_bucket.terraform_state.id
versioning_configuration {
status = "Enabled"
}
}
# S3バケットのサーバーサイド暗号化を有効にします
# これにより、保存されたデータが自動的に暗号化されます
resource "aws_s3_bucket_server_side_encryption_configuration" "terraform_state" {
bucket = aws_s3_bucket.terraform_state.id
rule {
apply_server_side_encryption_by_default {
sse_algorithm = "AES256"
}
}
}
# S3バケットのパブリックアクセスをブロックします
# これにより、バケットとその中のオブジェクトへの不正アクセスを防ぎます
resource "aws_s3_bucket_public_access_block" "terraform_state" {
bucket = aws_s3_bucket.terraform_state.id
block_public_acls = true
block_public_policy = true
ignore_public_acls = true
restrict_public_buckets = true
}
# Terraformの状態ロックを管理するDynamoDBテーブルを作成します
# これにより、複数の人が同時に状態を変更することを防ぎます
resource "aws_dynamodb_table" "terraform_state_lock" {
name = "terraform-state-lock"
billing_mode = "PAY_PER_REQUEST" # 使用量に応じた課金モード
hash_key = "LockID"
attribute {
name = "LockID"
type = "S" # 文字列型
}
tags = {
Name = "terraform-state-lock"
Project = var.project_name
ManagedBy = "Terraform"
}
}
# GitHub ActionsのOIDC設定を取得します
# これは、GitHub ActionsとAWS間の信頼関係を確立するために使用されます
data "http" "github_actions_openid_configuration" {
url = "https://token.actions.githubusercontent.com/.well-known/openid-configuration"
}
# GitHub ActionsのOIDC証明書を取得します
# これは、GitHub Actionsの認証に使用される証明書の情報を取得します
data "tls_certificate" "github_actions" {
url = jsondecode(data.http.github_actions_openid_configuration.response_body).jwks_uri
}
# GitHub Actions用のOIDC Providerを作成します
# これにより、AWSはGitHub Actionsからの認証要求を信頼できるようになります
resource "aws_iam_openid_connect_provider" "github_actions" {
url = "https://token.actions.githubusercontent.com"
client_id_list = ["sts.amazonaws.com"]
thumbprint_list = data.tls_certificate.github_actions.certificates[*].sha1_fingerprint
}
# GitHub Actions用のIAMロールを作成します
# このロールにより、GitHub ActionsがAWSリソースにアクセスできるようになります
resource "aws_iam_role" "github_actions" {
name = "${var.project_name}-github-actions-role"
# 信頼ポリシーを定義します。これにより、GitHub ActionsがこのロールをAssumeできるようになります
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Action = "sts:AssumeRoleWithWebIdentity"
Effect = "Allow"
Principal = {
Federated = aws_iam_openid_connect_provider.github_actions.arn
}
Condition = {
StringLike = {
"token.actions.githubusercontent.com:sub" = "repo:${var.github_repo}:*"
}
}
}
]
})
tags = {
Name = "${var.project_name}-github-actions-role"
Project = var.project_name
ManagedBy = "Terraform"
}
}
# GitHub Actions用のIAMポリシーをアタッチします
# これにより、GitHub ActionsがAWSリソースを操作する権限を得ます
resource "aws_iam_role_policy_attachment" "github_actions" {
policy_arn = "arn:aws:iam::aws:policy/AdministratorAccess" # 注意: 本番環境では最小権限の原則に従ってください
role = aws_iam_role.github_actions.name
}
2.4. infra_base/variables.tfファイルの内容:
# infra_base/variables.tf
variable "aws_region" {
description = "使用するAWSリージョン"
type = string
}
variable "project_name" {
description = "プロジェクト名"
type = string
}
variable "github_repo" {
description = "GitHub ActionsのOIDC認証を許可するリポジトリ"
type = string
}
2.5. infra_base/terraform.tfvarsファイルの内容:
# infra_base/terraform.tfvars
aws_region = "ap-northeast-1"
project_name = "aws-terraform"
github_repo = "<USER_NAME>/aws-terraform" # <USER_NAME>は適切な値(例: sbk0716)に置き換えること。
2.6. infra_base/outputs.tfファイルの内容:
# infra_base/outputs.tf
output "terraform_state_bucket" {
description = "Terraform状態ファイルを保存するS3バケットの名前"
value = aws_s3_bucket.terraform_state.id
}
output "terraform_state_lock_table" {
description = "Terraform状態ロック用のDynamoDBテーブルの名前"
value = aws_dynamodb_table.terraform_state_lock.name
}
output "github_actions_role_arn" {
description = "GitHub Actions用IAMロールのARN"
value = aws_iam_role.github_actions.arn
}
2.7. Terraformの初期化と適用
infra_baseディレクトリで以下のコマンドを実行します:
terraform init
terraform plan
terraform apply
-
terraform initコマンドは、必要なプロバイダーをダウンロードし、作業ディレクトリを初期化します。 -
terraform planコマンドは、実行計画を生成し表示します。これにより、Terraformが何を作成、変更、または削除しようとしているかを事前に確認できます。 -
terraform applyコマンドを実行すると、詳細な実行計画が表示されます。内容を慎重に確認し、問題がなければyesと入力して実行してください。
これにより、以下のリソースが作成されます:
- Terraformの状態を保存するためのS3バケット
- 状態のロックを管理するDynamoDBテーブル
- GitHub Actions用のOIDC (OpenID Connect) プロバイダー
- GitHub ActionsがAWSリソースにアクセスするためのIAMロール
これらのリソースは、Terraformの状態管理とGitHub ActionsによるCI/CDパイプラインの基盤となります。S3バケットとDynamoDBテーブルはTerraformの状態管理に使用され、OIDCプロバイダーとIAMロールはGitHub ActionsからAWSリソースへのセキュアなアクセスを可能にします。
注意: IAMロールには現在AdministratorAccessポリシーが付与されていますが、本番環境では必要最小限の権限を持つカスタムポリシーを作成し、それを使用することを強く推奨します。
3. モジュールの作成
3.1. ネットワークモジュールの作成
mkdir -p modules/network
cd modules/network
touch main.tf variables.tf outputs.tf
cd ../../
modules/network/main.tfファイルに以下の内容を追加します:
# modules/network/main.tf
# このファイルでは、VPC、サブネット、インターネットゲートウェイ、NATゲートウェイなどのネットワークリソースを定義します。
# VPCの作成
# VPC(Virtual Private Cloud)は、AWSクラウド内の仮想ネットワークです
resource "aws_vpc" "main" {
cidr_block = var.vpc_cidr # VPCのIPアドレス範囲を指定します
enable_dns_hostnames = true # VPC内のインスタンスがパブリックDNSホスト名を取得できるようにします
enable_dns_support = true # VPCのDNS解決をサポートします
tags = merge(
var.common_tags,
{
Name = "${var.network_identifier}-vpc" # VPCに名前タグを付けます
}
)
}
# パブリックサブネットの作成
# パブリックサブネットは、インターネットからアクセス可能なサブネットです
resource "aws_subnet" "public" {
count = length(var.public_subnet_cidrs) # 指定されたCIDRブロックの数だけサブネットを作成します
vpc_id = aws_vpc.main.id # 作成したVPCにサブネットを関連付けます
cidr_block = var.public_subnet_cidrs[count.index] # サブネットのIPアドレス範囲を指定します
availability_zone = var.availability_zones[count.index] # サブネットを配置するAZを指定します
tags = merge(
var.common_tags,
{
Name = "${var.network_identifier}-public-subnet-${substr(var.availability_zones[count.index], -2, 2)}" # サブネットに名前タグを付けます
}
)
}
# プライベートサブネットの作成
# プライベートサブネットは、インターネットから直接アクセスできないサブネットです
resource "aws_subnet" "private" {
count = length(var.private_subnet_cidrs) # 指定されたCIDRブロックの数だけサブネットを作成します
vpc_id = aws_vpc.main.id # 作成したVPCにサブネットを関連付けます
cidr_block = var.private_subnet_cidrs[count.index] # サブネットのIPアドレス範囲を指定します
availability_zone = var.availability_zones[count.index] # サブネットを配置するAZを指定します
tags = merge(
var.common_tags,
{
Name = "${var.network_identifier}-private-subnet-${substr(var.availability_zones[count.index], -2, 2)}" # サブネットに名前タグを付けます
}
)
}
# インターネットゲートウェイの作成
# インターネットゲートウェイは、VPCとインターネットの間の通信を可能にします
resource "aws_internet_gateway" "main" {
vpc_id = aws_vpc.main.id # 作成したVPCにインターネットゲートウェイを関連付けます
tags = merge(
var.common_tags,
{
Name = "${var.network_identifier}-igw" # インターネットゲートウェイに名前タグを付けます
}
)
}
# Elastic IP (EIP) の作成
# EIPは、インターネットからアクセス可能な固定のパブリックIPアドレスです
resource "aws_eip" "nat" {
count = var.environment == "dev" ? 1 : length(var.availability_zones) # 開発環境では1つ、その他の環境では各AZに1つずつ作成します
tags = merge(
var.common_tags,
{
Name = "${var.network_identifier}-nat-eip-${substr(var.availability_zones[count.index], -2, 2)}" # EIPに名前タグを付けます
}
)
}
# NAT Gatewayの作成
# NAT Gatewayは、プライベートサブネット内のリソースがインターネットにアクセスできるようにします
resource "aws_nat_gateway" "main" {
count = var.environment == "dev" ? 1 : length(var.availability_zones) # 開発環境では1つ、その他の環境では各AZに1つずつ作成します
allocation_id = aws_eip.nat[count.index].id # 作成したEIPをNAT Gatewayに関連付けます
subnet_id = aws_subnet.public[count.index].id # NAT GatewayをパブリックサブネットAに配置します
tags = merge(
var.common_tags,
{
Name = "${var.network_identifier}-nat-gateway-${substr(var.availability_zones[count.index], -2, 2)}" # NAT Gatewayに名前タグを付けます
}
)
}
# パブリックルートテーブルの作成
# ルートテーブルは、ネットワークトラフィックの経路を定義します
resource "aws_route_table" "public" {
vpc_id = aws_vpc.main.id # 作成したVPCにルートテーブルを関連付けます
route {
cidr_block = "0.0.0.0/0" # すべてのトラフィック(0.0.0.0/0)に対して
gateway_id = aws_internet_gateway.main.id # インターネットゲートウェイへルーティングします
}
tags = merge(
var.common_tags,
{
Name = "${var.network_identifier}-public-route-table" # パブリックルートテーブルに名前タグを付けます
}
)
}
# プライベートルートテーブルの作成
resource "aws_route_table" "private" {
count = length(var.private_subnet_cidrs) # プライベートサブネットの数だけルートテーブルを作成します
vpc_id = aws_vpc.main.id # 作成したVPCにルートテーブルを関連付けます
tags = merge(
var.common_tags,
{
Name = "${var.network_identifier}-private-route-table-${substr(var.availability_zones[count.index], -2, 2)}" # プライベートルートテーブルに名前タグを付けます
}
)
}
# プライベートルートテーブルへのルート追加
resource "aws_route" "private_nat_gateway" {
count = length(var.private_subnet_cidrs) # プライベートサブネットの数だけルートを作成します
route_table_id = aws_route_table.private[count.index].id # 対応するプライベートルートテーブルを指定します
destination_cidr_block = "0.0.0.0/0" # すべてのトラフィック(0.0.0.0/0)に対して
nat_gateway_id = var.environment == "dev" ? aws_nat_gateway.main[0].id : aws_nat_gateway.main[count.index].id
# 開発環境では最初のNAT Gateway、その他の環境では対応するAZのNAT Gatewayを使用します
}
# パブリックサブネットとルートテーブルの関連付け
# これにより、パブリックサブネット内のリソースがインターネットゲートウェイを使用してインターネットにアクセスできるようになります
resource "aws_route_table_association" "public" {
count = length(aws_subnet.public) # パブリックサブネットの数だけ関連付けを作成します
subnet_id = aws_subnet.public[count.index].id # 関連付けるパブリックサブネットを指定します
route_table_id = aws_route_table.public.id # 関連付けるパブリックルートテーブルを指定します
}
# プライベートサブネットとルートテーブルの関連付け
# これにより、プライベートサブネット内のリソースがNAT Gatewayを使用してインターネットにアクセスできるようになります
resource "aws_route_table_association" "private" {
count = length(aws_subnet.private) # プライベートサブネットの数だけ関連付けを作成します
subnet_id = aws_subnet.private[count.index].id # 関連付けるプライベートサブネットを指定します
route_table_id = aws_route_table.private[count.index].id # 関連付けるプライベートルートテーブルを指定します
}
modules/network/variables.tfファイルに以下の内容を追加します:
# modules/network/variables.tf
variable "network_identifier" {
description = "ネットワークリソースの識別子"
type = string
}
variable "vpc_cidr" {
description = "VPCのCIDRブロック"
type = string
}
variable "public_subnet_cidrs" {
description = "パブリックサブネットのCIDRブロックのリスト"
type = list(string)
}
variable "private_subnet_cidrs" {
description = "プライベートサブネットのCIDRブロックのリスト"
type = list(string)
}
variable "availability_zones" {
description = "使用するアベイラビリティーゾーンのリスト"
type = list(string)
}
variable "environment" {
description = "環境名(dev, staging, prod)"
type = string
}
variable "common_tags" {
description = "すべてのリソースに適用する共通タグ"
type = map(string)
default = {}
}
modules/network/outputs.tfファイルに以下の内容を追加します:
# modules/network/outputs.tf
output "vpc_id" {
description = "作成されたVPCのID"
value = aws_vpc.main.id
}
output "public_subnet_ids" {
description = "作成されたパブリックサブネットのIDのリスト"
value = aws_subnet.public[*].id
}
output "private_subnet_ids" {
description = "作成されたプライベートサブネットのIDのリスト"
value = aws_subnet.private[*].id
}
output "nat_gateway_ids" {
description = "作成されたNAT GatewayのIDのリスト"
value = aws_nat_gateway.main[*].id
}
3.2. 非同期処理モジュールの作成
mkdir -p modules/async_processing/lambda
cd modules/async_processing
touch main.tf variables.tf outputs.tf
cd lambda
touch index.js package.json
cd ../../../
modules/async_processing/main.tfファイルに以下の内容を追加します:
# modules/async_processing/main.tf
# このファイルでは、SQSキューとLambda関数を作成し、それらを連携させます。
# 非同期処理を実現するための基本的なインフラストラクチャを構築します。
# SQSキューの作成
# SQS(Simple Queue Service)は、マイクロサービス、分散システム、サーバーレスアプリケーション間のメッセージの送受信を可能にするフルマネージドメッセージキューイングサービスです。
resource "aws_sqs_queue" "main" {
name = "${var.client_code}-worker-queue" # クライアントコードを使用してユニークな名前を生成します
visibility_timeout_seconds = var.visibility_timeout # メッセージが他のコンシューマーから見えなくなる時間
message_retention_seconds = var.message_retention # メッセージがキューに残る最大時間
max_message_size = var.max_message_size # メッセージの最大サイズ(バイト)
delay_seconds = var.delay_seconds # 新しく追加されたメッセージを非表示にする時間
tags = merge(
var.common_tags,
{
Name = "${var.client_code}-worker-queue"
Environment = var.environment
ClientCode = var.client_code
}
)
}
# Lambda関数のコードをZIPファイルにパッケージ化します
# Lambda関数のデプロイには、コードをZIPファイルにパッケージ化する必要があります
data "archive_file" "lambda_zip" {
type = "zip"
source_dir = "${path.module}/lambda" # Lambdaのソースコードがあるディレクトリ
output_path = "${path.module}/function.zip" # 生成されるZIPファイルの場所
}
# Lambda関数の作成
# Lambda関数は、サーバーレスでコードを実行するためのコンピューティングサービスです
resource "aws_lambda_function" "main" {
function_name = "${var.client_code}-worker-function" # 関数名
role = aws_iam_role.lambda_exec.arn # Lambda関数が使用するIAMロール
handler = var.lambda_handler # Lambda関数のエントリーポイント
runtime = var.lambda_runtime # 実行環境(例:nodejs14.x)
timeout = var.lambda_timeout # 関数のタイムアウト時間(秒)
memory_size = var.lambda_memory_size # 関数に割り当てるメモリ量(MB)
filename = data.archive_file.lambda_zip.output_path # デプロイするZIPファイル
source_code_hash = data.archive_file.lambda_zip.output_base64sha256 # コードが変更された場合に関数を更新するためのハッシュ
# 環境変数の設定
environment {
variables = merge(
var.lambda_environment_variables,
{
QUEUE_URL = aws_sqs_queue.main.id # SQSキューのURLを環境変数として設定
}
)
}
tags = merge(
var.common_tags,
{
Name = "${var.client_code}-worker-function"
Environment = var.environment
ClientCode = var.client_code
}
)
}
# Lambda実行ロールの作成
# このIAMロールは、Lambda関数がAWSリソースにアクセスするために必要な権限を定義します
resource "aws_iam_role" "lambda_exec" {
name = "${var.client_code}-lambda-exec-role"
# 信頼ポリシー:Lambda サービスがこのロールを引き受けることを許可します
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Action = "sts:AssumeRole"
Effect = "Allow"
Principal = {
Service = "lambda.amazonaws.com"
}
}
]
})
tags = merge(
var.common_tags,
{
Name = "${var.client_code}-lambda-exec-role"
Environment = var.environment
ClientCode = var.client_code
}
)
}
# Lambda関数にSQSの読み取り権限を付与
# これにより、Lambda関数がSQSキューからメッセージを読み取ることができるようになります
resource "aws_iam_role_policy_attachment" "lambda_sqs" {
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaSQSQueueExecutionRole"
role = aws_iam_role.lambda_exec.name
}
# SQSトリガーの設定
# これにより、SQSキューにメッセージが到着したときにLambda関数が自動的に呼び出されるようになります
resource "aws_lambda_event_source_mapping" "sqs_trigger" {
event_source_arn = aws_sqs_queue.main.arn # トリガーとなるSQSキューのARN
function_name = aws_lambda_function.main.arn # 呼び出されるLambda関数のARN
batch_size = var.lambda_batch_size # 一度に処理するメッセージの数
}
modules/async_processing/variables.tfファイルに以下の内容を追加します:
# modules/async_processing/variables.tf
variable "client_code" {
description = "クライアントコード"
type = string
}
variable "environment" {
description = "環境名(dev, staging, prod)"
type = string
}
variable "visibility_timeout" {
description = "SQSメッセージの可視性タイムアウト(秒)"
type = number
default = 30
}
variable "message_retention" {
description = "SQSメッセージの保持期間(秒)"
type = number
default = 345600 # 4日間
}
variable "max_message_size" {
description = "SQSメッセージの最大サイズ(バイト)"
type = number
default = 262144 # 256 KB
}
variable "delay_seconds" {
description = "SQSメッセージの遅延配信時間(秒)"
type = number
default = 0
}
variable "lambda_handler" {
description = "Lambda関数のハンドラー"
type = string
default = "index.handler"
}
variable "lambda_runtime" {
description = "Lambda関数のランタイム"
type = string
default = "nodejs18.x"
}
variable "lambda_timeout" {
description = "Lambda関数のタイムアウト(秒)"
type = number
default = 3
}
variable "lambda_memory_size" {
description = "Lambda関数のメモリサイズ(MB)"
type = number
default = 128
}
variable "lambda_environment_variables" {
description = "Lambda関数の環境変数"
type = map(string)
default = {}
}
variable "lambda_batch_size" {
description = "Lambda関数が一度に処理するSQSメッセージの数"
type = number
default = 10
}
variable "common_tags" {
description = "すべてのリソースに適用する共通タグ"
type = map(string)
default = {}
}
modules/async_processing/outputs.tfファイルに以下の内容を追加します:
# modules/async_processing/outputs.tf
output "sqs_queue_arn" {
description = "作成されたSQSキューのARN"
value = aws_sqs_queue.main.arn
}
output "sqs_queue_url" {
description = "作成されたSQSキューのURL"
value = aws_sqs_queue.main.id
}
output "lambda_function_arn" {
description = "作成されたLambda関数のARN"
value = aws_lambda_function.main.arn
}
output "lambda_function_name" {
description = "作成されたLambda関数の名前"
value = aws_lambda_function.main.function_name
}
output "lambda_role_arn" {
description = "作成されたLambda実行ロールのARN"
value = aws_iam_role.lambda_exec.arn
}
modules/async_processing/lambda/index.jsファイルに以下の内容を追加します:
// このファイルは、SQSメッセージを処理するLambda関数を定義する
exports.handler = async (event) => {
// イベントから受け取ったSQSメッセージを処理する
for (const record of event.Records) {
console.log('受信したメッセージ:', record.body);
// ここで実際のメッセージ処理ロジックを実装する
// 例: データベースへの書き込み、他のAWSサービスの呼び出しなど
}
// 処理が成功したことを示す応答を返す
return {
statusCode: 200,
body: JSON.stringify('メッセージの処理が完了しました'),
};
};
modules/async_processing/lambda/package.jsonファイルに以下の内容を追加します:
{
"name": "async-processing-lambda",
"version": "1.0.0",
"description": "Lambda function to process SQS messages",
"main": "index.js",
"dependencies": {}
}
4. 環境ごとの設定ファイルの作成
開発環境(dev)の例を示します。
mkdir -p environments/dev/clients
cd environments/dev
touch main.tf variables.tf terraform.tfvars backend.tf versions.tf
cd ../../
environments/dev/backend.tfファイルに以下の内容を追加します:
terraform {
backend "s3" {
bucket = "terraform-state-<ACCOUNT_ID>" # <ACCOUNT_ID>は適切な値(例: 123456789012)に置き換えること。
key = "environments/dev/terraform.tfstate"
region = "ap-northeast-1"
dynamodb_table = "terraform-state-lock"
encrypt = true
}
}
environments/dev/main.tfファイルに以下の内容を追加します:
# environments/dev/main.tf
# AWSプロバイダーの設定
# これにより、AWSのリソースを操作できるようになります。
provider "aws" {
region = "ap-northeast-1"
}
# ネットワークモジュールの呼び出し
module "network" {
source = "../../modules/network"
network_identifier = var.network_identifier
vpc_cidr = var.vpc_cidr
public_subnet_cidrs = var.public_subnet_cidrs
private_subnet_cidrs = var.private_subnet_cidrs
availability_zones = var.availability_zones
environment = var.environment
common_tags = merge(var.common_tags, {
Environment = "dev"
})
}
# 各クライアントのモジュールを静的に呼び出します
module "client_pikachu" {
source = "./clients/pikachu"
environment = "dev"
vpc_id = module.network.vpc_id
subnet_ids = module.network.private_subnet_ids
client_code = "pikachu"
common_tags = merge(var.common_tags, {
Environment = "dev"
ClientCode = "pikachu"
})
}
module "client_mew" {
source = "./clients/mew"
environment = "dev"
vpc_id = module.network.vpc_id
subnet_ids = module.network.private_subnet_ids
client_code = "mew"
common_tags = merge(var.common_tags, {
Environment = "dev"
ClientCode = "mew"
})
}
environments/dev/variables.tfファイルに以下の内容を追加します:
# environments/dev/variables.tf
variable "network_identifier" {
description = "ネットワークリソースの識別子"
type = string
}
variable "vpc_cidr" {
description = "VPCのCIDRブロック"
type = string
}
variable "public_subnet_cidrs" {
description = "パブリックサブネットのCIDRブロックのリスト"
type = list(string)
}
variable "private_subnet_cidrs" {
description = "プライベートサブネットのCIDRブロックのリスト"
type = list(string)
}
variable "availability_zones" {
description = "使用するアベイラビリティーゾーンのリスト"
type = list(string)
}
variable "environment" {
description = "環境名(dev, staging, prod)"
type = string
}
variable "common_tags" {
description = "すべてのリソースに適用する共通タグ"
type = map(string)
default = {}
}
environments/dev/terraform.tfvarsファイルに以下の内容を追加します:
# environments/dev/terraform.tfvars
network_identifier = "core"
vpc_cidr = "10.0.0.0/16"
public_subnet_cidrs = ["10.0.1.0/24", "10.0.2.0/24", "10.0.3.0/24"]
private_subnet_cidrs = ["10.0.4.0/24", "10.0.5.0/24", "10.0.6.0/24"]
availability_zones = ["ap-northeast-1a", "ap-northeast-1c", "ap-northeast-1d"]
environment = "dev"
common_tags = {
Project = "aws-terraform"
Environment = "dev"
ManagedBy = "Terraform"
}
environments/dev/versions.tfファイルに以下の内容を追加します:
# environments/dev/versions.tf
# Terraformの設定
# ここでは、Terraformのバージョンと使用するプロバイダーを指定します。
terraform {
# 必要なTerraformのバージョンを指定します。
# これにより、異なるバージョンでの予期せぬ動作を防ぎます。
required_version = ">= 0.13"
# 必要なプロバイダーとそのバージョンを指定します。
# プロバイダーは、特定のサービス(この場合はAWS)とTerraformの間のインターフェースです。
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 4.0"
}
}
}
5. クライアント固有の設定ファイルの作成
「pikachu」クライアントの例を示します。
mkdir -p environments/dev/clients/pikachu
cd environments/dev/clients/pikachu
touch main.tf variables.tf
cd ../../../../
environments/dev/clients/pikachu/main.tfファイルに以下の内容を追加します:
# environments/dev/clients/pikachu/main.tf
# このファイルでは、pikachuクライアント固有のリソースを定義します。
# 非同期処理モジュールの呼び出し
module "async_processing" {
source = "../../../../modules/async_processing"
client_code = var.client_code
environment = var.environment
lambda_environment_variables = {
CLIENT_CODE = var.client_code
}
common_tags = var.common_tags
}
# クライアント固有のその他のリソースを定義
# リソースグループの作成(クライアント固有のリソースをグループ化)
resource "aws_resourcegroups_group" "client_group" {
name = "${var.client_code}-resources"
resource_query {
query = jsonencode({
ResourceTypeFilters = ["AWS::AllSupported"]
TagFilters = [
{
Key = "ClientCode"
Values = [var.client_code]
},
{
Key = "Environment"
Values = [var.environment]
}
]
})
}
tags = var.common_tags
}
environments/dev/clients/pikachu/variables.tfファイルに以下の内容を追加します:
# environments/dev/clients/pikachu/variables.tf
variable "client_code" {
description = "クライアントコード"
type = string
default = "pikachu"
}
variable "environment" {
description = "環境名(dev, staging, prod)"
type = string
}
variable "vpc_id" {
description = "使用するVPCのID"
type = string
}
variable "subnet_ids" {
description = "使用するサブネットのIDのリスト"
type = list(string)
}
variable "common_tags" {
description = "すべてのリソースに適用する共通タグ"
type = map(string)
default = {}
}
6. スクリプトの作成
6.1. Lambda関数のパッケージングスクリプトの作成
mkdir scripts
touch scripts/package-lambda.sh
chmod +x scripts/package-lambda.sh
scripts/package-lambda.shファイルに以下の内容を追加します:
#!/bin/bash
# 使用方法を表示する関数
show_usage() {
echo "使用方法: $0 <lambda_function_directory>"
echo " <lambda_function_directory>: Lambda関数のソースコードが含まれるディレクトリ"
}
# 引数のチェック
if [ $# -ne 1 ]; then
show_usage
exit 1
fi
LAMBDA_DIR=$1
# ディレクトリの存在確認
if [ ! -d "$LAMBDA_DIR" ]; then
echo "エラー: 指定されたディレクトリが存在しません: $LAMBDA_DIR"
exit 1
fi
# 現在のディレクトリを保存
CURRENT_DIR=$(pwd)
# Lambda関数のディレクトリに移動
cd "$LAMBDA_DIR" || exit
# 依存関係のインストール(package.jsonが存在する場合)
if [ -f "package.json" ]; then
npm install --production
fi
# Zipファイルの作成
zip -r "../function.zip" .
# 元のディレクトリに戻る
cd "$CURRENT_DIR" || exit
echo "Lambda関数のパッケージが正常に作成されました: $LAMBDA_DIR/../function.zip"
6.2. Terraform操作スクリプトの作成
touch scripts/terraform-ops.sh
chmod +x scripts/terraform-ops.sh
scripts/terraform-ops.shファイルに以下の内容を追加します:
#!/bin/bash
# このスクリプトは、指定された環境(dev, staging, prod)に対してTerraformの操作を実行します。
# 使用方法を表示する関数
show_usage() {
echo "使用方法: $0 <command> <environment> [account_id]"
echo " <command>: 実行するコマンド(init, fmt, plan, apply, destroy, show)"
echo " <environment>: 対象の環境(dev, staging, prod)"
echo " [account_id]: (オプション) AWSアカウントID(省略時はデフォルト値)"
echo "例:"
echo " $0 init dev # 開発環境を初期化"
echo " $0 plan staging # ステージング環境のプラン作成"
}
# 引数のチェック
if [ $# -lt 2 ] || [ $# -gt 3 ]; then
show_usage
exit 1
fi
# 引数を変数に代入
COMMAND=$1 # 1つ目の引数(必須):実行するコマンド
ENVIRONMENT=$2 # 2つ目の引数(必須):対象の環境
ACCOUNT_ID=${3:-<ACCOUNT_ID>} # 3つ目の引数(オプション):AWSアカウントID(デフォルト値)
# 環境ごとのディレクトリを設定
ENV_DIR="environments/$ENVIRONMENT"
# AWSリージョンを設定
AWS_REGION="ap-northeast-1"
# Terraformの初期化
init() {
echo "Initializing Terraform for environment: $ENVIRONMENT"
cd "$ENV_DIR" && terraform init -backend-config="bucket=terraform-state-$ACCOUNT_ID" -backend-config="key=$ENVIRONMENT/terraform.tfstate" -backend-config="region=$AWS_REGION" -backend-config="dynamodb_table=terraform-state-lock" -backend-config="encrypt=true"
}
# Terraformのフォーマットチェック
fmt() {
echo "Formatting Terraform files for environment: $ENVIRONMENT"
cd "$ENV_DIR" && terraform fmt -check -recursive
}
# Terraformのプラン作成
plan() {
echo "Creating Terraform plan for environment: $ENVIRONMENT"
cd "$ENV_DIR" && terraform plan -var-file="terraform.tfvars" -out=tfplan
}
# Terraformの適用
apply() {
echo "Applying Terraform plan for environment: $ENVIRONMENT"
cd "$ENV_DIR" && terraform apply -auto-approve tfplan
}
# Terraformの破棄
destroy() {
echo "Destroying Terraform resources for environment: $ENVIRONMENT"
cd "$ENV_DIR" && terraform destroy -var-file="terraform.tfvars" -auto-approve
}
# Terraformの状態表示
show() {
echo "Showing Terraform state for environment: $ENVIRONMENT"
cd "$ENV_DIR" && terraform show
}
# コマンドの実行
case $COMMAND in
init)
init
;;
fmt)
fmt
;;
plan)
plan
;;
apply)
apply
;;
destroy)
destroy
;;
show)
show
;;
*)
echo "エラー: 無効なコマンド '$COMMAND'"
show_usage
exit 1
;;
esac
echo "スクリプトの実行が完了しました。"
7. GitHub Actionsワークフローの作成
mkdir -p .github/workflows
touch .github/workflows/terraform.yml
touch .github/workflows/lambda.yml
.github/workflows/terraform.ymlファイルに以下の内容を追加します:
name: 'Terraform CI/CD'
# ワークフローのトリガーを定義
on:
push:
branches:
- 'feat/**' # feat/で始まるブランチへのプッシュ時
tags:
- 'v*' # vで始まるタグが作成された時
pull_request:
branches: [ "main" ] # mainブランチへのプルリクエスト時
permissions:
id-token: write
contents: read
# ジョブの定義
jobs:
# 開発環境用のジョブ
terraform-dev:
name: 'Terraform Dev'
if: startsWith(github.ref, 'refs/heads/feat/')
runs-on: ubuntu-latest # Ubuntu最新版で実行
env:
WORKING_DIR: ./environments/dev # 作業ディレクトリを環境変数として設定
steps:
- name: Checkout # リポジトリのチェックアウト
uses: actions/checkout@v3
- name: Configure AWS Credentials # AWS認証情報の設定
uses: aws-actions/configure-aws-credentials@v4
with:
role-to-assume: ${{ secrets.AWS_ROLE_ARN }}
aws-region: ap-northeast-1
- name: Setup Terraform # Terraformのセットアップ
uses: hashicorp/setup-terraform@v2
with:
terraform_version: 1.0.0
- name: Terraform Init # Terraformの初期化
run: terraform init
working-directory: ${{ env.WORKING_DIR }}
- name: Terraform Format # Terraformのフォーマットチェック
run: terraform fmt -check --recursive
working-directory: ${{ env.WORKING_DIR }}
- name: Terraform Plan # Terraformのプラン作成
run: terraform plan -no-color -lock=false
working-directory: ${{ env.WORKING_DIR }}
# - name: Terraform Apply # Terraformの適用
# run: terraform apply -auto-approve -lock=false
# working-directory: ${{ env.WORKING_DIR }}
# - name: Terraform Destroy # Terraformによるリソース削除
# run: terraform destroy -auto-approve -lock=false
# working-directory: ${{ env.WORKING_DIR }}
# ステージング環境用のジョブ
terraform-staging:
name: 'Terraform Staging'
if: github.event.pull_request.merged == true # プルリクエストがマージされた場合のみ実行
runs-on: ubuntu-latest
env:
WORKING_DIR: ./environments/staging
steps:
- name: Checkout
uses: actions/checkout@v3
- name: Configure AWS Credentials
uses: aws-actions/configure-aws-credentials@v4
with:
role-to-assume: ${{ secrets.AWS_ROLE_ARN }}
aws-region: ap-northeast-1
- name: Setup Terraform
uses: hashicorp/setup-terraform@v2
with:
terraform_version: 1.0.0
- name: Terraform Init
run: terraform init
working-directory: ${{ env.WORKING_DIR }}
- name: Terraform Format
run: terraform fmt -check --recursive
working-directory: ${{ env.WORKING_DIR }}
- name: Terraform Plan
run: terraform plan -no-color -lock=false
working-directory: ${{ env.WORKING_DIR }}
# - name: Terraform Apply
# run: terraform apply -auto-approve -lock=false
# working-directory: ${{ env.WORKING_DIR }}
# - name: Terraform Destroy # Terraformによるリソース削除
# run: terraform destroy -auto-approve -lock=false
# working-directory: ${{ env.WORKING_DIR }}
# 本番環境用のジョブ
terraform-prod:
name: 'Terraform Prod'
if: startsWith(github.ref, 'refs/tags/v') # vで始まるタグが作成された場合のみ実行
runs-on: ubuntu-latest
env:
WORKING_DIR: ./environments/prod
steps:
- name: Checkout
uses: actions/checkout@v3
- name: Configure AWS Credentials
uses: aws-actions/configure-aws-credentials@v4
with:
role-to-assume: ${{ secrets.AWS_ROLE_ARN }}
aws-region: ap-northeast-1
- name: Setup Terraform
uses: hashicorp/setup-terraform@v2
with:
terraform_version: 1.0.0
- name: Terraform Init
run: terraform init
working-directory: ${{ env.WORKING_DIR }}
- name: Terraform Format
run: terraform fmt -check --recursive
working-directory: ${{ env.WORKING_DIR }}
# - name: Terraform Plan
# run: terraform plan -no-color
# working-directory: ${{ env.WORKING_DIR }}
# - name: Terraform Apply
# run: terraform apply -auto-approve
# working-directory: ${{ env.WORKING_DIR }}
.github/workflows/lambda.ymlファイルに以下の内容を追加します:
name: 'Lambda Deployment'
on:
push:
paths:
- 'modules/async_processing/lambda/**'
pull_request:
paths:
- 'modules/async_processing/lambda/**'
permissions:
id-token: write
contents: read
jobs:
deploy-lambda:
name: 'Deploy Lambda'
runs-on: ubuntu-latest
steps:
# リポジトリのチェックアウト
- name: Checkout
uses: actions/checkout@v3
# AWS認証
- name: Configure AWS Credentials
uses: aws-actions/configure-aws-credentials@v4
with:
role-to-assume: ${{ secrets.AWS_ROLE_ARN }}
aws-region: ap-northeast-1
# Lambda関数のビルドとデプロイ
- name: Build and deploy Lambda
run: |
cd modules/async_processing/lambda
npm install
zip -r function.zip .
aws lambda update-function-code --function-name pikachu-worker-function --zip-file fileb://function.zip
aws lambda update-function-code --function-name mew-worker-function --zip-file fileb://function.zip
8. プロジェクトの初期化と適用
開発環境(dev)の例を示します。
- プロジェクトのルートディレクトリに移動します:
cd /path/to/your/project
- スクリプトを使用してTerraformの操作を実行します:
./scripts/terraform-ops.sh init dev
このコマンドは、開発環境のTerraform設定を初期化します。
- Terraformのフォーマットをチェックします:
./scripts/terraform-ops.sh fmt dev
このコマンドは、Terraformファイルのフォーマットが正しいかチェックします。
- Terraformの計画を作成します:
./scripts/terraform-ops.sh plan dev
このコマンドは、開発環境に対するTerraformの実行計画を生成します。
- 計画を適用します:
./scripts/terraform-ops.sh apply dev
このコマンドは、生成された計画を実行し、AWSリソースを作成または更新します。実行前に計画の内容を確認するプロンプトが表示されます。
- デプロイ後の確認:
デプロイが完了したら、以下のコマンドで作成されたリソースの状態を確認できます:
./scripts/terraform-ops.sh show dev
また、AWSマネジメントコンソールにログインして、実際に作成されたリソースを視覚的に確認することをお勧めします。
- クリーンアップ(オプション):
テスト目的でデプロイした場合や、不要になったリソースを削除する場合は、以下のコマンドを使用します:
./scripts/terraform-ops.sh destroy dev
このコマンドを実行すると、作成したすべてのリソースが削除されます。実行前に十分注意してください。
注意:
- 実際の運用では、セキュリティやコスト管理の観点から、より詳細な設定が必要になる場合があります。
- AWSの課金が発生する可能性があるため、不要なリソースは速やかに削除するようにしてください。
- 本番環境への適用前に、Dev環境で十分なテストと検証を行ってください。
- 複数の開発者が同じ環境で作業する場合は、
planとapplyの実行前に必ず最新の状態をgit pullで取得してください。 - 重要な変更を行う前には、必ずチームメンバーと協議し、承認を得るプロセスを設けることをお勧めします。
このプロセスを使用することで、Dev環境に対して安全かつ制御されたデプロイを行うことができます。環境ごとに異なる設定を使用することで、開発、テスト、本番環境の分離が可能になり、リスクを最小限に抑えながらインフラストラクチャの変更を管理できます。
構築したリソース
ネットワークモジュール
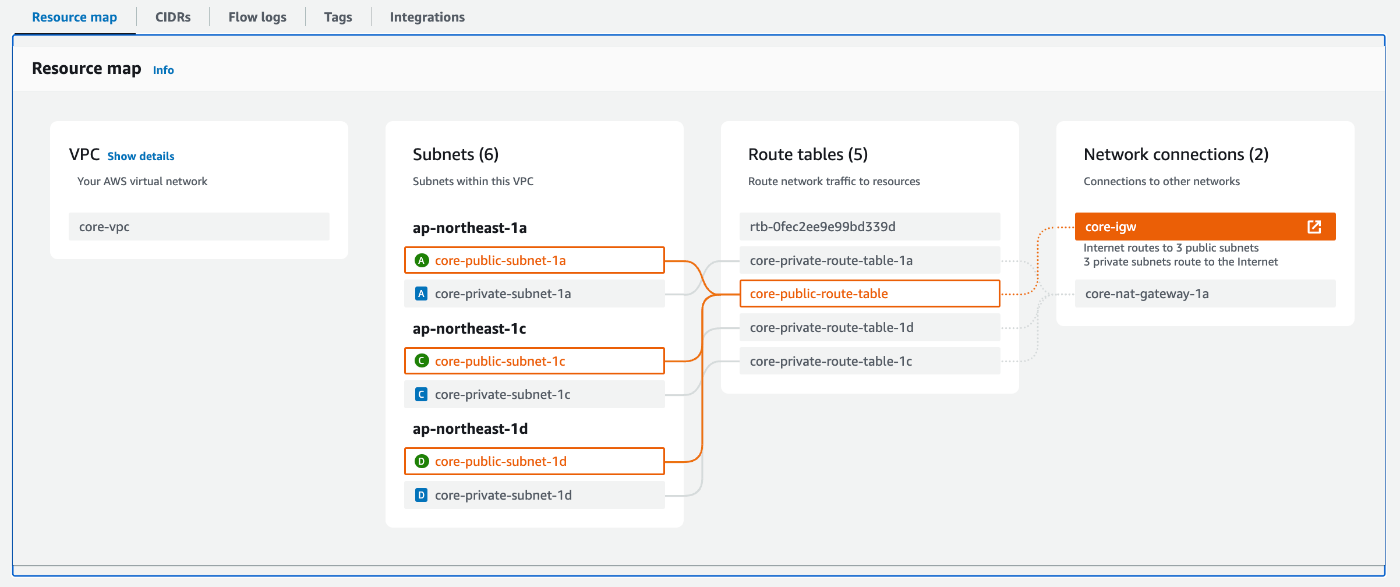

非同期処理モジュール
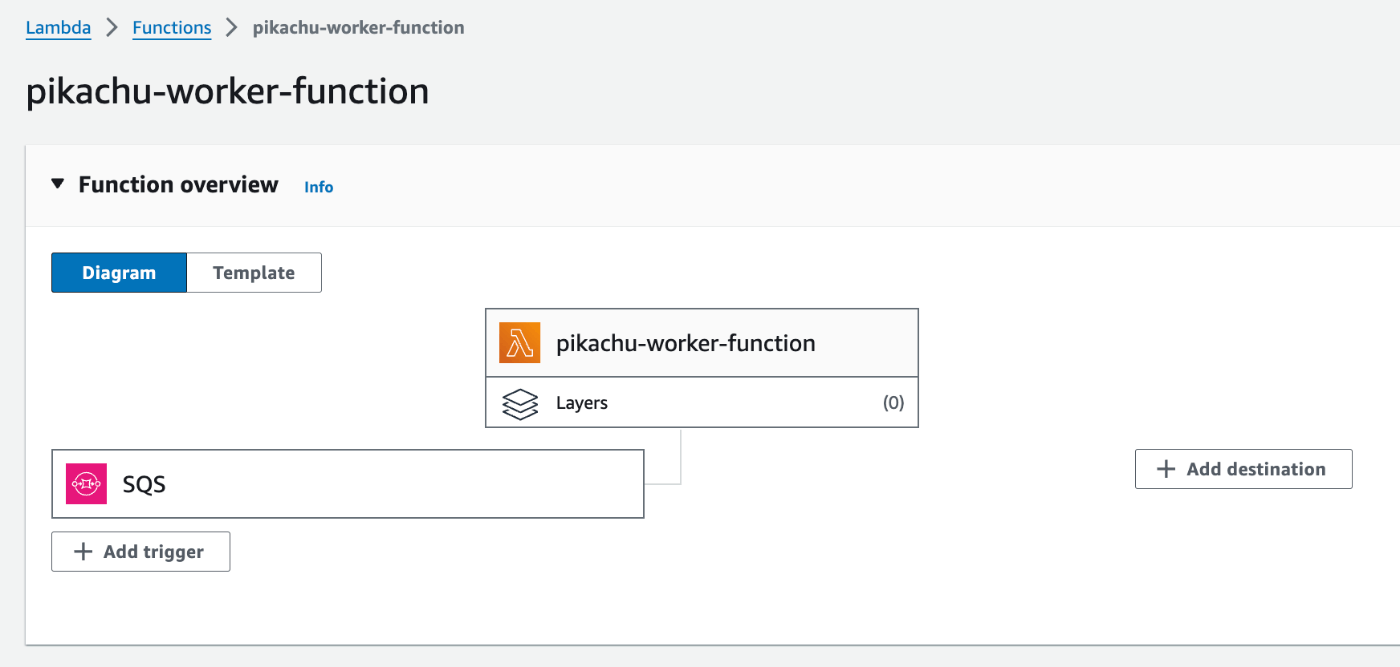
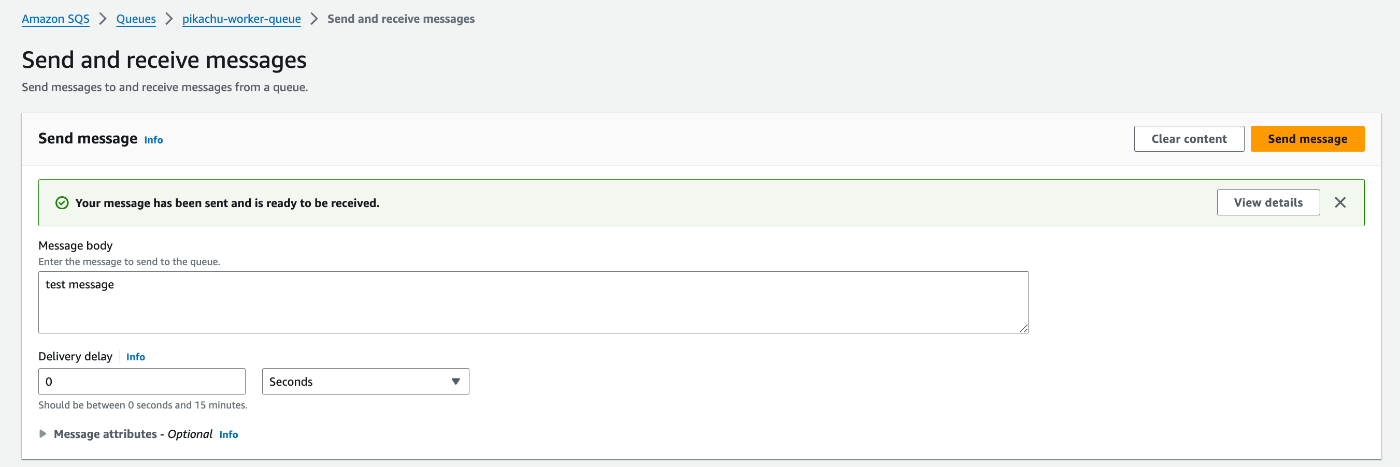
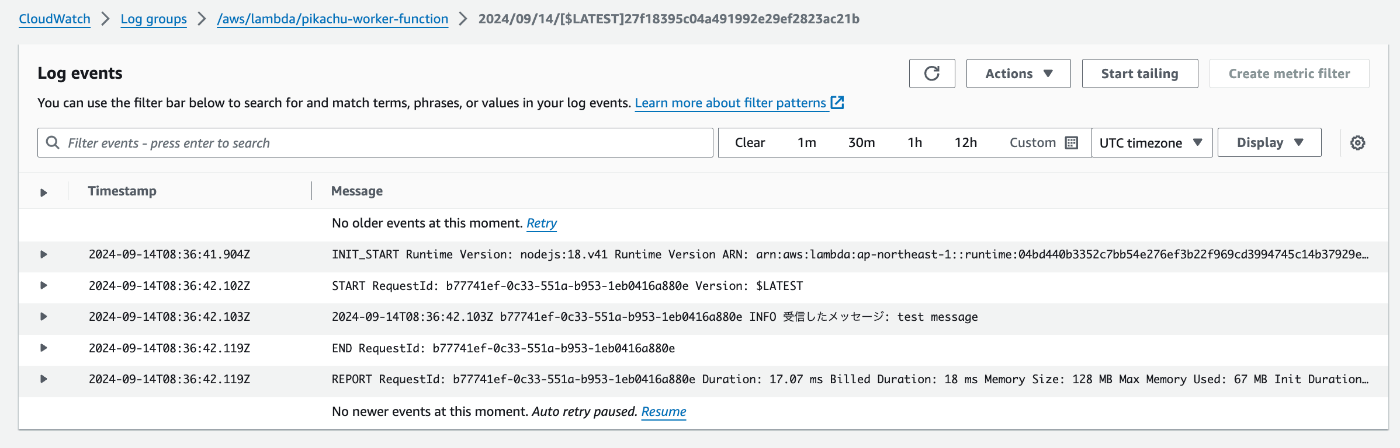
動作確認
Discussion