動画生成モデル AnimateDiff・Animate Anyone 論文完全解説
はじめに
ほとんど破綻なく一貫性を保って動作するAnimate Anyoneが登場し,大きな話題になっています.
Stable Diffusionベースの動画生成モデルとしては,AnimateDiffが注目を集めて以降様々な拡張が登場していますがいずれもチラつきが存在するというのが常識でした.それが今回のモデルの登場で覆った形になります.何度も見ても驚異的な一貫性です.
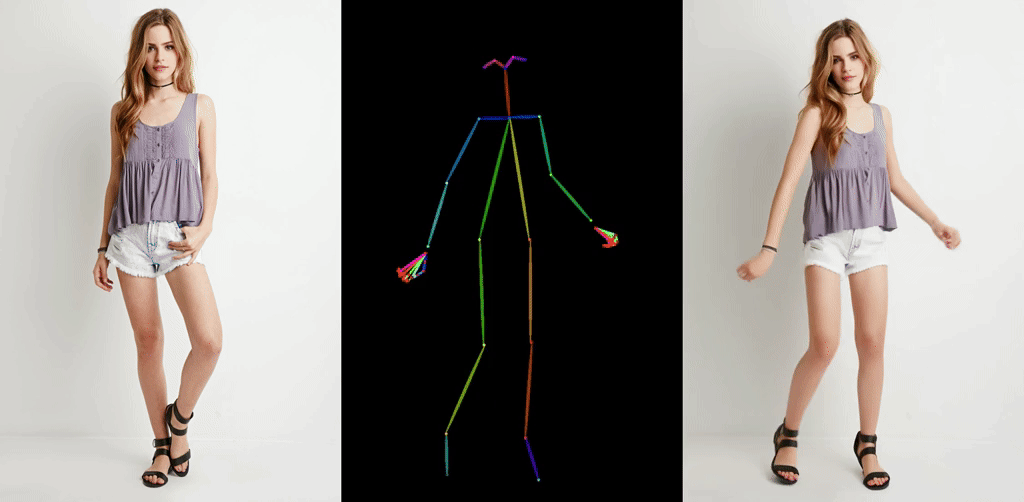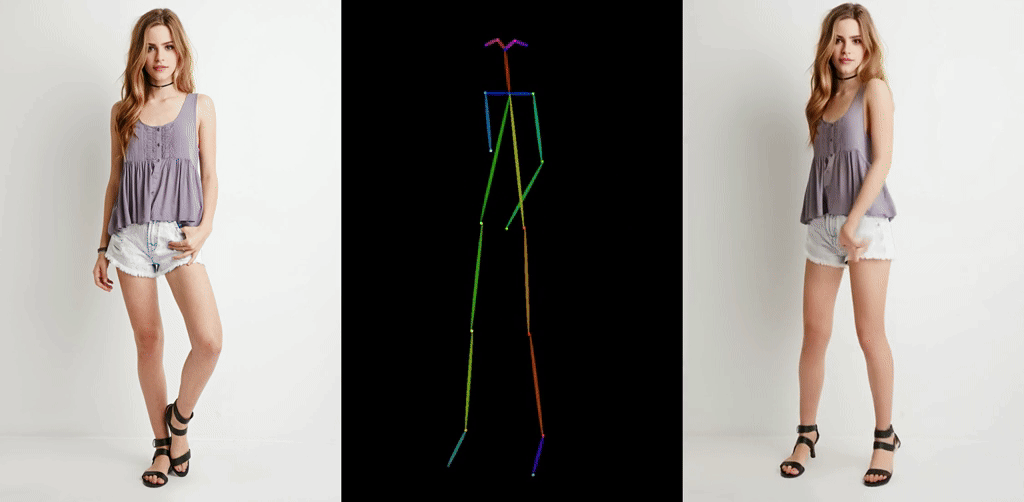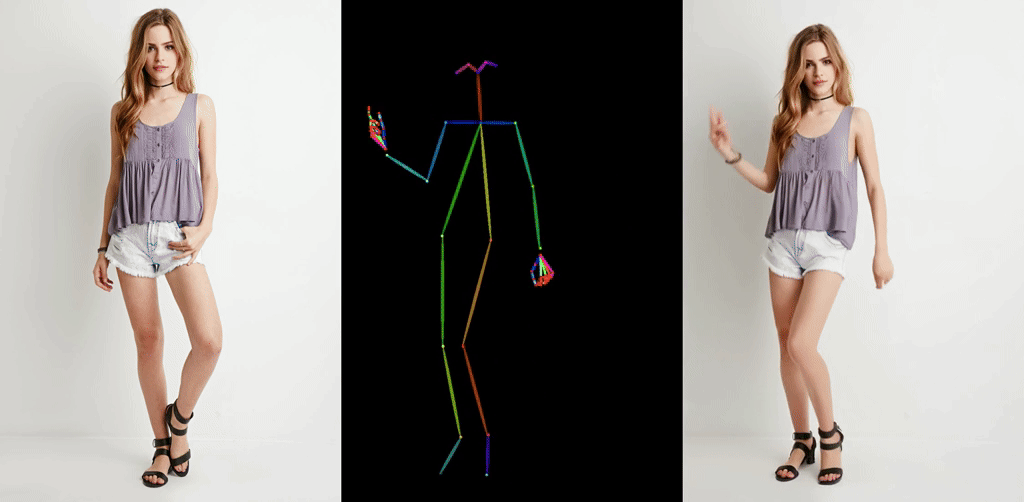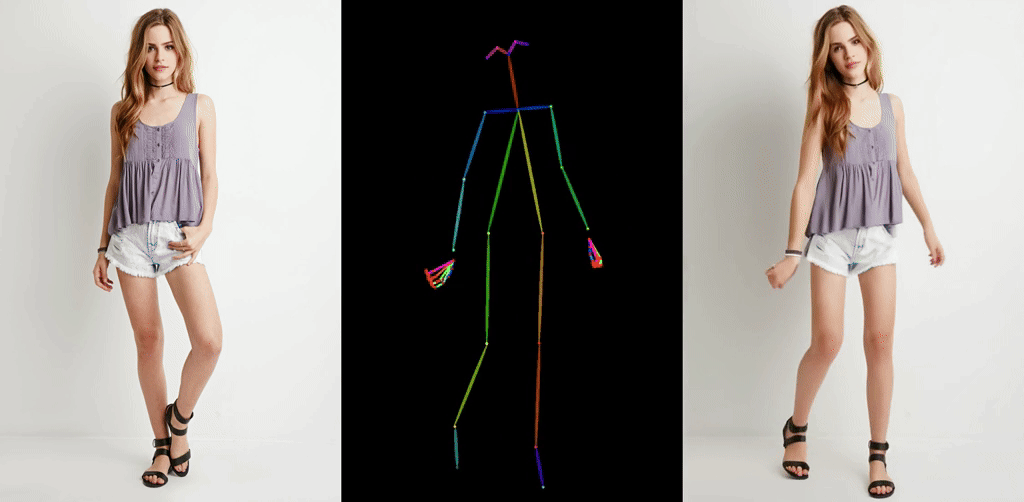

出典: https://humanaigc.github.io/animate-anyone/
Animate AnyoneはAnimateDiffの拡張となっています.AnimateDiffはベースアーキテクチャとして今後もより重要になっていくと考えられますが,意外にも論文解説に触れる機会が少ないです.
そこで、本記事では、AnimateDiffに焦点を当て、その論文解説に加えて、AnimateDiff+ControlNetについても紹介します。さらに、記事の最終章では、Animate Anyoneの詳細な論文解説に進みます。この記事を通じて、Animate Anyoneのアーキテクチャ全体を理解しながら,Stable Diffusionベースの動画生成技術のパラダイムを俯瞰していきたいと思います.
本記事はwebuiに馴染み深い人,あるいはStable Diffusionの構造をある程度理解している人向けの記事になっています.
【論文解説】AnimateDiff

出典: https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved
概要
AnimateDiffは,Stable DiffusionにMotion Moduleと呼ばれる機構を付加することで,Text2ImageをText2Videoに拡張する手法です.以下のような特徴があります.
- ControlNetのように,Stable Diffusionの再学習なしで利用可能.Motion Moduleの重みのみを更新すれば良い.
- Stable Diffusionの再学習が必要ないので,画像生成用のLoRAなどをそのまま用いて動画生成ができる.
- 単体の使用においては,テキストプロンプトを入力として取り,それに応じた一般的に見られるモーションが生成される.(つまり,プロンプトのシーケンスで時系列的に動きを制御できるわけではない)
手法
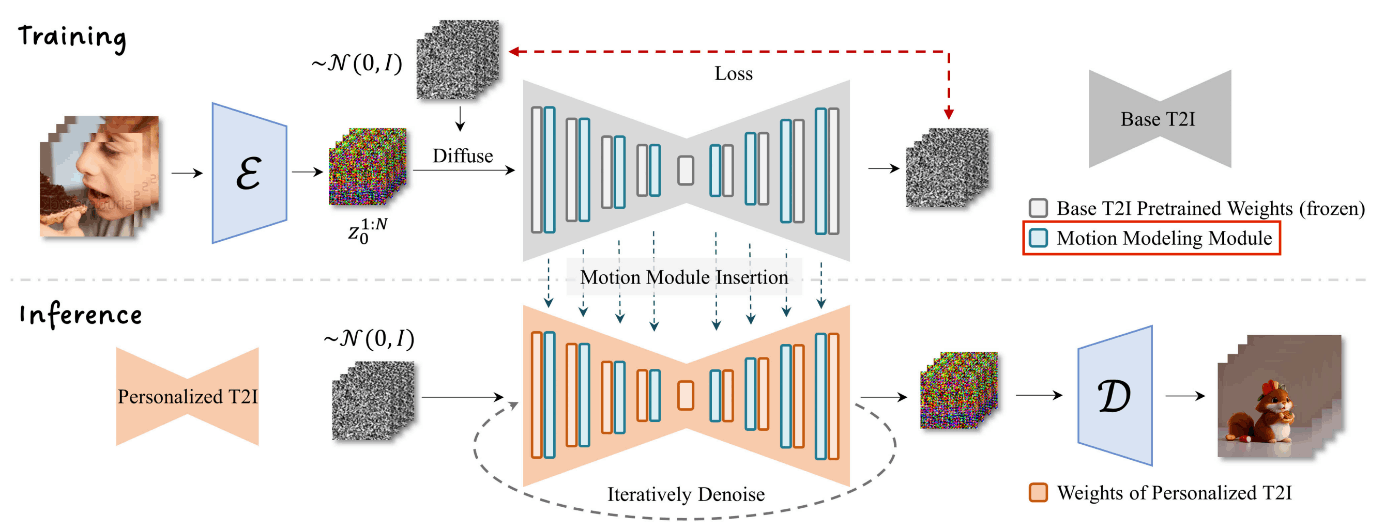
AnimateDiffの全体像
非常にシンプルな方策で構成されています.前提としてText2ImageのStable Diffusionモデルをベースモデルとして利用しています.まず,Stable Diffusionの重みを変えないで動画モデルに拡張するために,バッチ軸をフレーム軸に変更して利用します.さらに,Motion moduleと名付けられた(ただの)Transformerを用いて時系列的な特徴を抽出します(Transformerが元々時系列データを扱うために考案されたことを思い出してください).
以下各要素について概要を見ていきます.
a. batch軸をframe軸に再形成
Stable Diffusionは画像生成モデルですが,このネットワークをそのまま用いて動画を扱えるようにするために,batch軸をframe軸(時間軸)に再形成します.
b. Motion Moduleの導入
Motion moduleは基本的にただのバニラTransformerです.すなわち,self-attentionがframe軸(時間軸)方向の特徴づけを行うというシンプルな機構です.この機構はStable DiffusionのUNetの全ての解像度レベルに挿入されます.本節最初のAnimateDiffの全体像を見ると青い長方形がMotion Moduleを表しており,Stable Diffusion denoising UNetの各層ごとに付加されています.
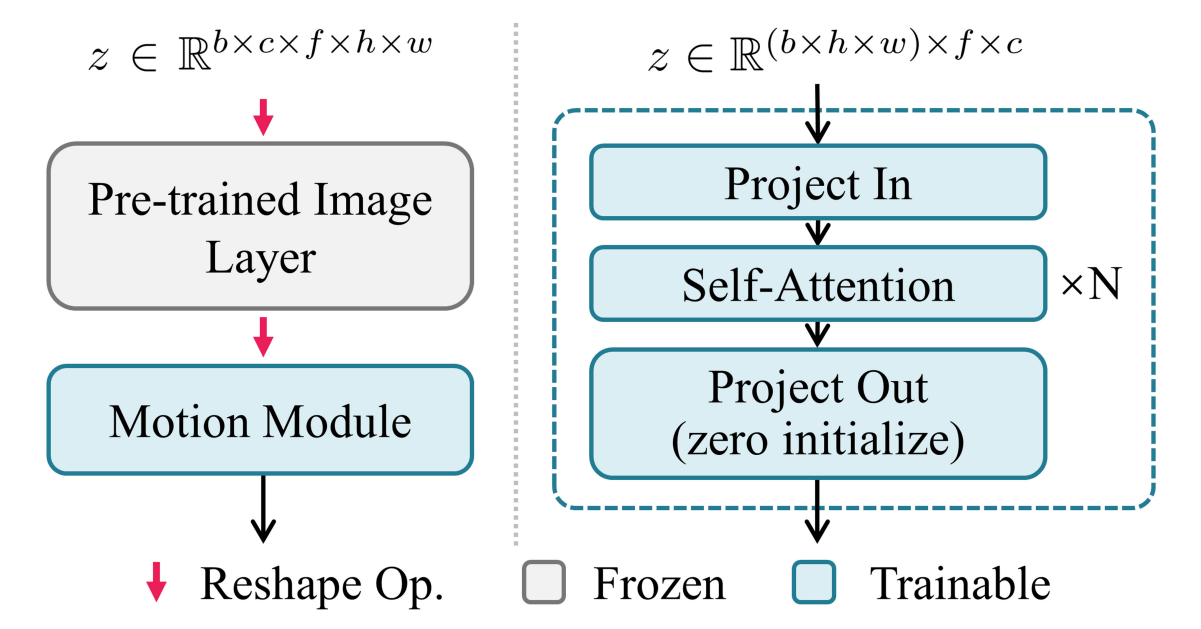
Motion Moduleのアーキテクチャ
現在モーションモジュールはいくつか公開されていますが,有名なものを二つ紹介します.
- mm_sd_v14.ckpt
417Mパラメータ・1.6GB.ダイナミックな動きが特徴

- mm_sd_v15_v2.ckpt
453Mパラメータ・1.7GB.安定した動きが特徴

学習戦略
サンプリングされたビデオデータ
この際,Motion Module内の重みのみが学習され,他は凍結されます.
- ベースモデル:Stable Diffusion v1.
なお,論文ではv1を使用していますが,現在webuiが提供するAnimateDiffはStable Diffusion XLに対応しています. - 訓練データ:WebVid-10M(テキストとビデオのペアデータセット)
フレームを256x256にリサイズして学習されています.最終的には16フレーム(約2秒)を1ビデオクリップと設定.
AnimateDiff + ControlNet
AnimateDiffはControlNetと組み合わせることができます.例えばOpenposeの骨格モーション画像とテキストプロンプトを入力として以下のような動画を生成することができます.
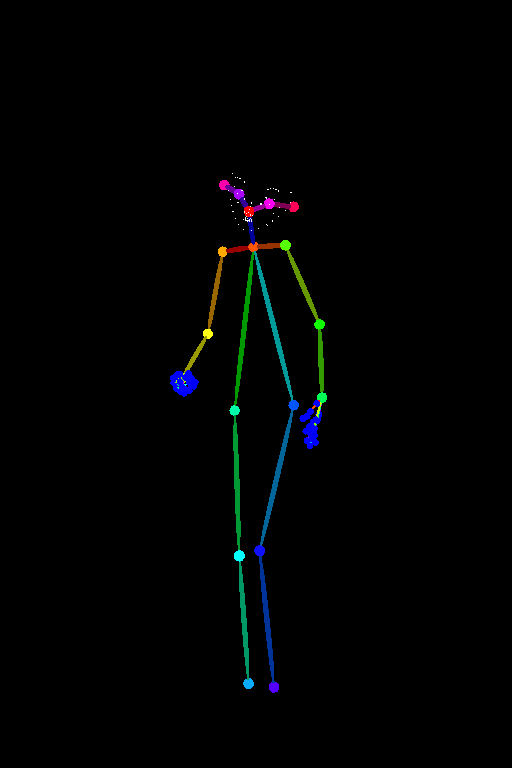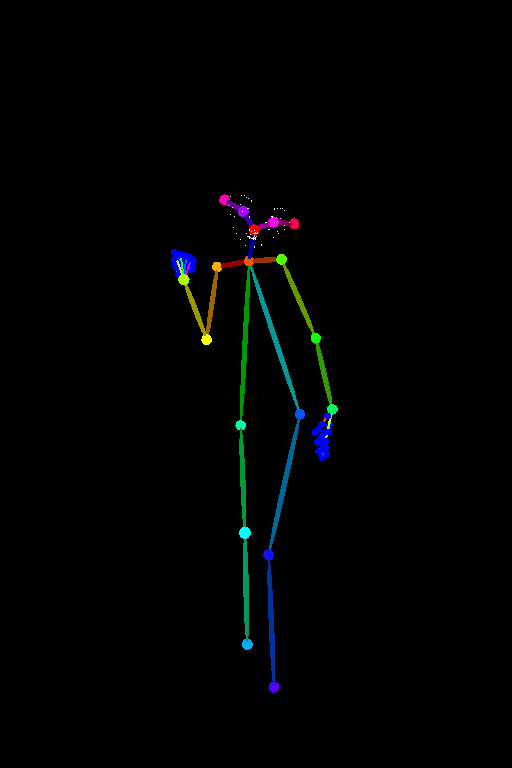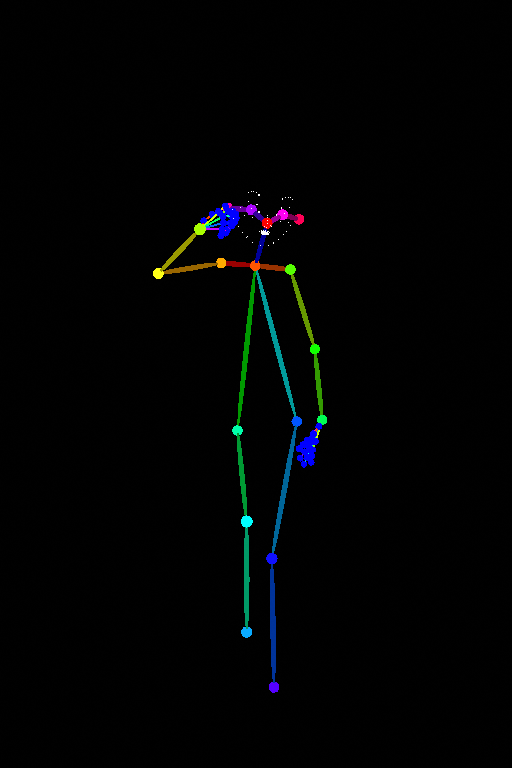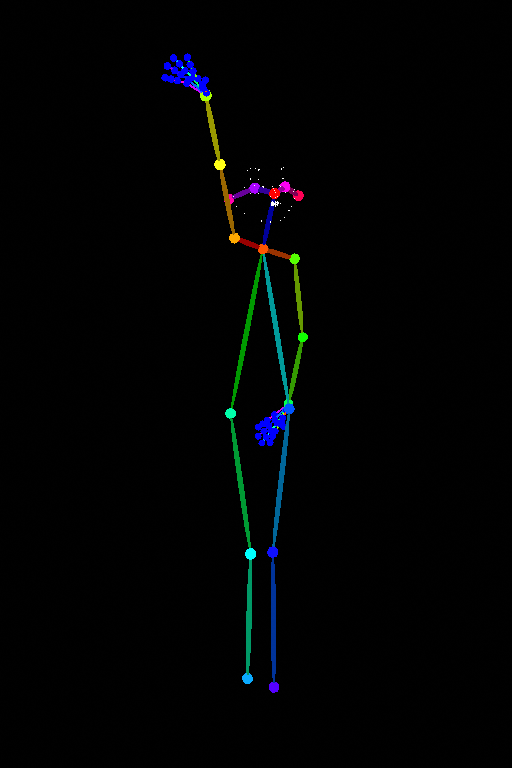

出典: https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved
もちろん話題になったAnimateDiffなだけあって,上記の動画は非常に完成度が高いですが,チラつきが存在することがわかります.さらにIP Adapter(後述)を用いて参照画像をプロンプトとして与えることで参照画像を骨格モーションに合わせて動かすこともできますが,同様のチラつきが存在します.この問題設定において,圧倒的な性能を実現したのが,次に紹介するAnimate Anyoneです.
【論文解説】Animate Anyone
概要
Animate Anyoneは,参照画像と骨格モーションを入力とする,Stable Diffusionベースのモデルで,一貫性の高さと破綻のなさから大きな話題を呼んでいます.手法の概要は以下です.
- Image Promptと新規考案のReferenceNetを用いてStableDiffusionを条件付け
- さらに骨格画像を初期値に用いてStable Diffusionのdenoising UNetごと再学習を行うことで参照画像を強く保持するImg2Imgモデルを作成
- その後,このImg2ImgをAnimateDiffと同様の原理で時系列的特徴づけをして動画生成を実行する
上記設計により以下のような特徴をもちます.
- 高度な一貫性と破綻のなさを実現
- 実写風もアニメ風も同一のモデルで実現可能
- Stable Diffusionのdnoising UNetごと再学習しているので,LoRAなどを用いることは現時点では難しい
- 一動画の推論に対してReferenceNetは一回呼べば良いので,AnimateDiffに比べて計算量が大幅に増加することはない
手法
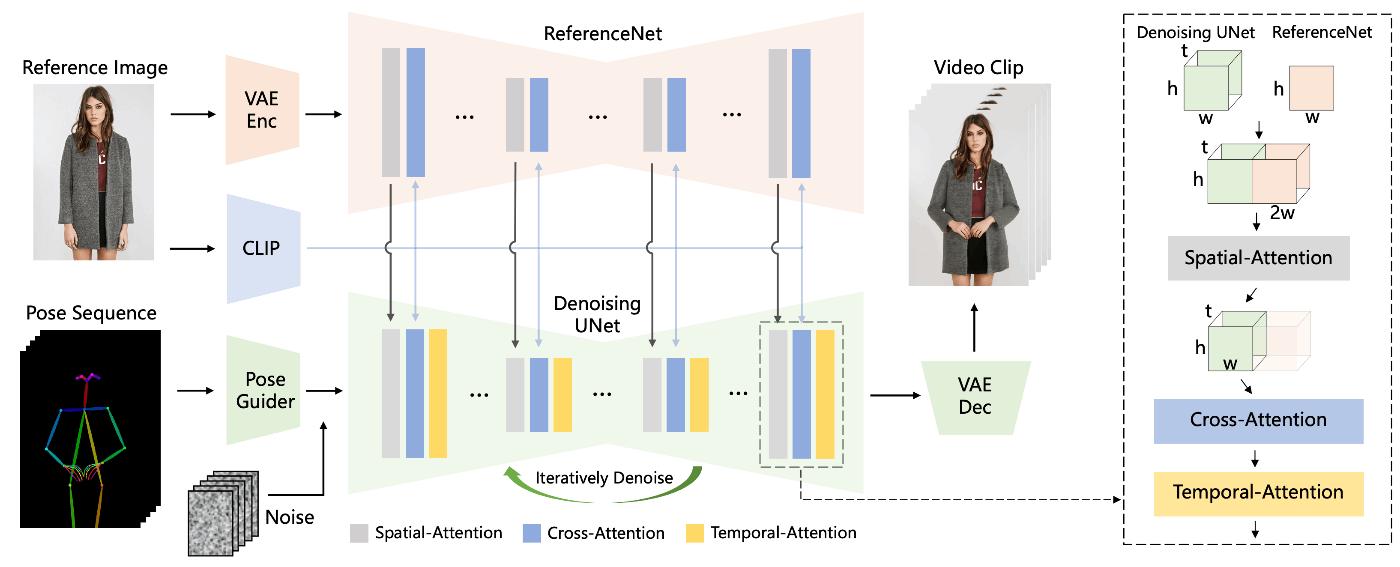
a. Clip Image Encoder
CLIP Image Encoderを使用することで,テキストではなく画像をプロンプトとして与えることができます.参照画像に沿った画像生成を行う際に用いられる手法で,機構自体はIP-Adapterという名前で知られています.
IP-Adapterは再学習なしで簡単に参照画像を与えることができますが,CLIPのImage-Text埋め込みマップ上にマッピングされるので詳細情報は失われてしまいます.
Animate Anyoneではこの機構とReferenceNetを組み合わせることで詳細情報を画像に反映させることに成功しています.
b. Reference Net
ReferenceNetは,参照画像の詳細情報を動画に反映させるために新たに導入された機構です.
-
Structure
denosing UNetを複製した構造を持ち,重みも同じ値で初期化されます.ただし,更新は同期せず独立して行います.ReferenceNetとdenosing UNetの関連付けは以下の図のようにして行われます.t h w c
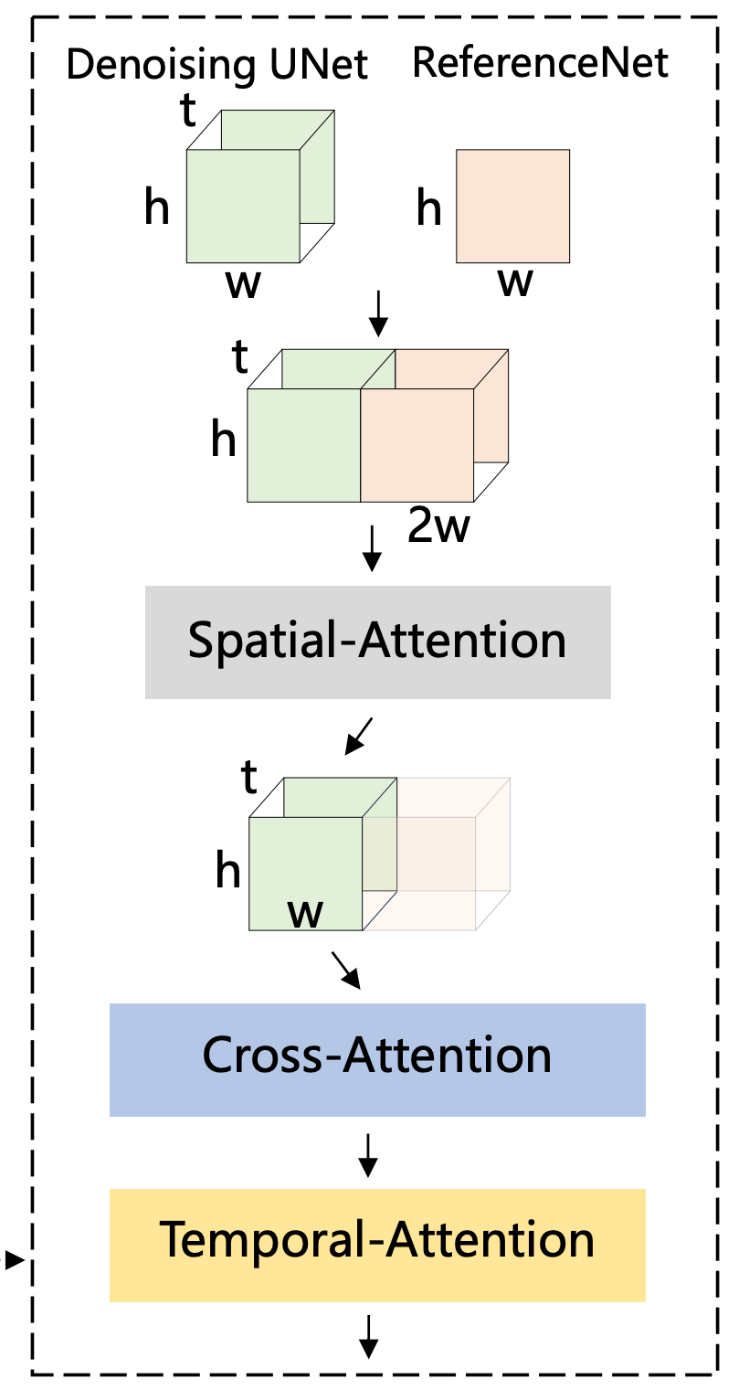
- まず,self-attension layerをspatial-attentnion layer(時間方向ではなく画像方向へのattention)に置き換えます.
- さらにdenoising UNetからの特徴マップ
x_1\in R^{t×h×w×c} x_2\in R^{h×w×c} x_2 t w x_1 - これに対して,self-attentionを行い,参照画像とターゲット画像合わせたものの特徴マップを取得してその前半を出力として取り出します.
- さらに,Image Promptとcross-attentnionを行い,意味的特徴を反映させます.
-
上記Structureの利点
ReferenceNetをオリジナルのStable Diffusionで事前に初期化できるので,学習が早くなります.また,ReferenceNetとdenoising UNetが同じ構造,同じ初期値を持つため,同じ特徴空間内で相関するReferenceNetを選択的に学習することができます. -
ControlNetとの比較
Stable Diffusionにネットワークを接続して,Attentnion layerを拡張する手法といえば,ControlNetがありますが,本設定では機能しないことを次の節で明らかにします.理由については人物の容姿を規定する参照画像と姿勢を規定する骨格画像で初期化されたターゲット画像は空間的に相関がないので,ナイーブにControlNetを使用しても性能向上に寄与しないと論文中で考察されています.
この問題を解決するためにReferenceNetを導入してdenoising UNetごと再学習することで格段の性能向上を実現しています.ただし,LoRAなどが使用できないという欠点も生じています.
c. Pose Guider
骨格情報を用いてStable Diffusionを条件付けといえば,ControlNetです.ただし,ControlNetはStable Diffusion自体の重みは凍結して学習することを前提にしているので,Stable Diffusion自体の重みを再学習する今回の設定では,より軽量な姿勢の条件付けネットワークを導入しています.
d. Temporal Attention
ネットワーク構造の細部については記述がありませんでしたが,基本的にAnimateDiffのmotion moduleと同じものと思って良さそうです.というのも,Temporal Attentionは訓練時にAnimateDiffの重みで初期化されています.
学習戦略
訓練は以下の2段階で実行されます.
- Temporal Layerを一時的にスキップして,denoising UNet,ReferenceNet,Pose Guiderを学習します.ただし,VAEのencoder,decoder,CLIP Image Encoderは固定です.この時点で,骨格画像と参照画像を紐づけるImg2Imgモデルが作成されます
- Temporal Layerを導入してAnimateDiffの重みで初期化します.そしてTemporal Layer以外の全ての部分を固定して学習します.これによってImg2Imgモデルに時系列的な特徴づけが行われます
上記のような,Img2Imgモデルを作成してから時系列的特徴づけを行う方法はAnimateDiffなどの構成を踏襲した形になります.
データセットとして,5Kのキャラクタービデオクリップ(2~10秒)を収集して,NVIDIA A100を4つ用いて訓練しています.
最初のImg2Imgステップで764x764でバッチサイズ64で30000ステップ学習し,2番目の時系列ステップで24フレームのビデオシーケンスをバッチサイズ4で10000ステップ学習しています.
Ablation Study
以下の画像は骨格情報から参照画像の姿勢を制御するImg2Imgの実験を行った結果です.CLIP Image Prompt+ControlNet(for reference)を用いても細部の詳細情報(服が異なっている)が欠落しているのに対して,今回の提案手法では参照画像の服の模様までがほぼ完璧に反映されています.

感想
動画生成手法としては様々提案されており,Stable Diffusion Deforumなどがありますが,拡張性や実装の容易さと性能を両立したAnimateDiffは一つのブレイクスルーだと感じていたため,これを踏襲してほぼ破綻のない動画を作成する今回の手法には個人的に感動しました.Animate Anyoneも例に漏れず実装が容易なので,重みの学習さえ実行できればwebuiなどに登場する日も近いと思います.また既存のパラダイムから逸脱しないモデルなので,LoRA・LCMなどを使用できる同種の手法が出てきてもおかしくないと感じており,今後に期待です.
最後に
筆者のXのアカウントです.今後も論文解説を挙げていくのでぜひフォローしてください.次回はStable Video Diffusionの論文解説を予定しています.
運営サイト紹介
sayhi2.ai
・検索性に特化したAIツールリスト
・厳選された5,000以上のAIツールから欲しいツールを見つけられる
・独自のスコアリングアルゴリズムによるAIプロダクトの人気度の推定
是非お試しください。
参考文献
Discussion