主成分分析について
次元削減とは
次元削減とは多次元のデータを要約することにより次元数を減らすことです。
次元削減をすることによるメリットは主に以下の2点です。
・計算資源の節約
・データの可視化ができるようになる場合がある
例えば、身長、体重、ベンチプレス、デッドリフト、スクワットの記録のデータを与えられたとします。(ベンチプレス、デットリフト、スクワットはウエイトトレーニングの種目)
このままこのデータを扱うと、5次元のデータになってしまうので可視化できません。そこで、身長と体重を合わせて体格として、ベンチプレス、デッドリフト、スクワットの記録をまとめてBIG3(一般的に単純に3種目の記録を合算した値をBIG3と言う)とすると、2次元まで次元を削減できます。
上の例とは異なり現実の問題では、より多次元かつどのようにデータをまとめるかが直感的にわからないことがほとんどです。
そこで、次元削減の方法として様々な手法が考案されました。今回はその代表的な手法として主成分分析を扱います。
主成分分析(PCA)について
主成分分析(principal component analysis)は、多次元のデータを分散の大きい順に軸を取って特徴量を集約する方法です。二次元の場合、第一主成分にデータを集約すると以下のようになります。

次に第一主成分軸に直行かつデータの分散を最大にする第二主成分軸を取ります。

基本的にM次元のデータは第M主成分まで定めることができます。
主成分分析では、分散が大きいほど情報(データ)としての価値があると考えます。
そのため、分散最大となる軸を探してデータを集約しているのだと考えられます。(厳密に言えば、データの分散共分散行列の固有ベクトルを求めている事になる)
簡単な実装
sklearnのデータセット(load_iris)を使って簡単に実装してみます。
このデータはアヤメという花を分類するために用いられるToy datasetsです。
花弁、萼片の幅と長さがデータとして与えられて、それらを基に3種類のアヤメを分類します。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
#データ
iris_data = load_iris()
X = iris_data['data']#花弁、萼片の長さと幅のリスト
feature_names = iris_data['feature_names']#花弁、萼片
target_names = iris_data['target_names']#分類するアヤメの種類
#データを正規化する
X_scaled = StandardScaler().fit_transform(X)
#PCA
pca = PCA()
X_pca = pca.fit_transform(X_scaled)
df = pd.DataFrame(pca.components_, columns=feature_names)
pca.explained_variance_ratio_#寄与率
#以下出力
array([0.72962445, 0.22850762, 0.03668922, 0.00517871])
pca.components_について(sklearnのドキュメントより引用)
Principal axes in feature space, representing the directions of maximum variance in the data. Equivalently, the right singular vectors of the centered input data, parallel to its eigenvectors. The components are sorted by explained_variance_.
*要するに分散最大となる軸(主成分)を取るということ
ここでの寄与率は、第M主成分軸に対する分散を指します。
つまり、第M主成分軸が全体の中でどのくらいの情報量を持っているかを示すものとなります。
ここでは、第二主成分までで95%近くの情報を持っているので、第二主成分までを分類に用いれば良いと考えられます。
以下に第二主成分までを可視化します。
fig, ax = plt.subplots()
X0 = X_pca[y==0]#三種類に分ける
X1 = X_pca[y==1]
X2 = X_pca[y==2]
ax.scatter(X0[:, 0], X0[:, 1])#第一主成分と第二主成分を用いる
ax.scatter(X1[:, 0], X1[:, 1])
ax.scatter(X2[:, 0], X2[:, 1])
ax.set_xlabel("Component-1")
ax.set_ylabel("Component-2")
plt.show()
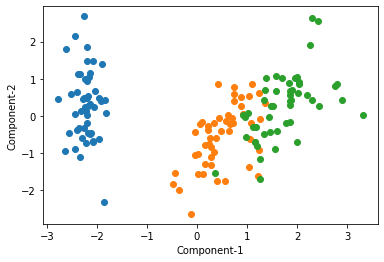
そこそこ綺麗に分類できているのではないかと思います。
長くなったので数式については割愛します。(軸がデータの分散共分散行列の固有ベクトルであることを数式で表したかった)
参考にしたもの
[主成分分析とは何なのか、とにかく全力でわかりやすく解説する] (https://recruit.cct-inc.co.jp/tecblog/machine-learning/pca-kaisetsu/)
Miidas Research
統計科学研究所
TauStation
30分でわかる機械学習用語「次元削減(Dimensionality Reduction)」
門脇、阪田、保坂、平松 「Kaggleで勝つデータ分析の技術」 技術評論社 (2019/10/9)
Discussion