🙆♀️
Notion × Streamlitで読書リストを視覚化するアプリ



はじめに
最近はインターネット上で情報収集するのが簡単になっています。しかし読んだ記事をどう整理するかは案外難しいものです。そこで今回は、Notionで管理している読書リストを、PythonのStreamlitとNotion APIを使って視覚化する方法をご紹介します。これを使えば、読んだ記事を一目で振り返ることができ、さらにどんなジャンルに偏っているかなど、自分の読書傾向も分析できるようになります。

必要なもの
- Streamlit: Webアプリをサクッと作れるPythonのライブラリです。
- Pandas
- WordCloud, Matplotlib, Plotly: データをキレイに見せるための視覚化ツール。
- Janome: 日本語のテキストデータを扱うためのもの。
- dotenv: 環境変数をコードに簡単に埋め込むためのもの。
- Notion Client: NotionのAPIを使用するための公式クライアント。
アプリの見どころ
このアプリでできることをざっと紹介します。
- ワードクラウド: 読んだ本のタイトルから、どんなキーワードが多いかを視覚的に表示します。
- ステータス別の円グラフ: 本をどれくらい読み終えているか、進行状況を円グラフでチェック。
- 大分類・小分類別の棒グラフ: 読んだ本がどのジャンルに属しているかを分析し、棒グラフで表示します。
始めよう
1. Notionの設定
まずは、NotionのAPIキーとデータベースIDを.envファイルに設定しておきましょう。これで、アプリがNotionのデータにアクセスできるようになります。Pythonでapiを使ってデータベースを操作する場合は以下を参考にすると良いでしょう。
また、Notionに以下のような形式でタイトル、 フォーマット、大分類、小分類のプロパティを含むデータベースを作成しておきましょう。
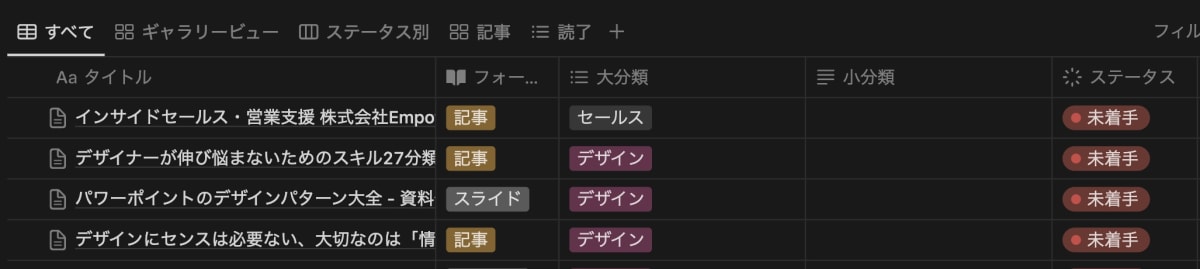
読書リストを視覚化するアプリケーション
レイアウトはともかく、データを視覚化するアプリケーションは以下の通りです。必要に応じて様々な分析を入れることができます。
コード
import streamlit as st
import pandas as pd
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import japanize_matplotlib # 日本語表示のため
from janome.tokenizer import Tokenizer
import os
from dotenv import load_dotenv
from notion_client import Client
import plotly.express as px
# 環境変数のロード
load_dotenv()
NOTION_API_KEY = os.environ.get("NOTION_API_KEY")
DATABASE_ID = os.environ.get("DATABASE_ID")
# Notion APIクライアントを初期化
notion = Client(auth=NOTION_API_KEY)
# クエリを作成してデータを取得、データフレームに変換
query = notion.databases.query(database_id=DATABASE_ID)
df = pd.DataFrame(query["results"])
# データ加工用の関数定義
def extract_property_value(row, property_name, sub_property=None):
prop = row["properties"].get(property_name, {})
if sub_property and isinstance(prop, dict):
return prop.get(sub_property, {}).get("name", None)
return None
# Plotlyのダークテーマを設定
px.defaults.template = "plotly_dark"
# アプリケーションのタイトル設定とスタイル調整
st.title("Notion Reading List Visualization")
st.markdown(
"""
<style>
.big-font {
font-size:20px !important;
}
</style>
""",
unsafe_allow_html=True,
)
# 2行2列のグリッドレイアウトを作成
grid = [[None, None], [None, None]]
font_path = 'fonts/ヒラギノ明朝 ProN.ttc' # フォントパスを指定
# 単語クラウドの表示
titles = " ".join([row["properties"]["タイトル"]["title"][0]["plain_text"] for _, row in df.iterrows()])
wordcloud = WordCloud(width=400, height=200, background_color='black', font_path=font_path).generate(titles)
fig, ax = plt.subplots(figsize=(5, 3))
ax.imshow(wordcloud, interpolation="bilinear")
ax.axis("off")
grid[0][0] = fig
# ステータス別の円グラフ
status_counts = df.apply(lambda row: extract_property_value(row, "ステータス", "status"), axis=1).value_counts()
fig = px.pie(values=status_counts.values, names=status_counts.index, title="<b>ステータス別分布</b>")
grid[0][1] = fig
# 大分類別の分布
category_counts = df.apply(lambda row: ', '.join([x["name"] for x in row["properties"].get("大分類", {}).get("multi_select", []) if x]), axis=1).value_counts()
fig = px.bar(x=category_counts.index, y=category_counts.values, labels={'x': "<b>大分類</b>", 'y': "<b>件数</b>"}, title="<b>大分類別の件数</b>")
grid[1][0] = fig
# 小分類別の分布
subcategory_counts = df.apply(lambda row: ', '.join([x["name"] for x in row["properties"].get("小分類", {}).get("multi_select", []) if x]), axis=1).value_counts()
fig = px.bar(x=subcategory_counts.index, y=subcategory_counts.values, labels={'x': "<b>小分類</b>", 'y': "<b>件数</b>"}, title="<b>小分類別の件数</b>")
grid[1][1] = fig
# グラフを表示
for row in grid:
cols = st.columns(2)
with cols[0]:
if row[0] is not None:
if isinstance(row[0], plt.Figure):
st.pyplot(row[0])
else:
st.plotly_chart(row[0], use_container_width=True)
with cols[1]:
if row[1] is not None:
st.plotly_chart(row[1], use_container_width=True)
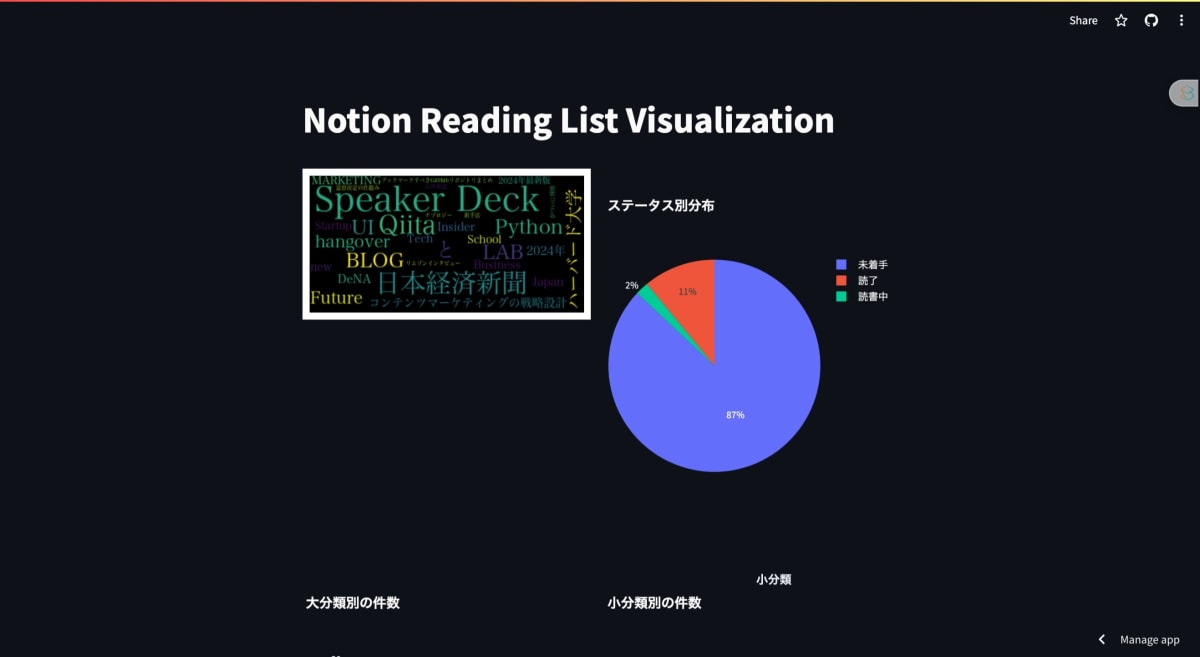
あとは以下を参考にしてこのアプリをStremlit上でデプロイするだけです!
:::note warn
アプリの設定画面で環境変数にNOTION_API_KEYとDATABASE_IDを忘れないように設定しましょう。
:::

最後にStreamlitのurlをNotionの埋め込みで任意の場所に埋め込むと完成です!
Discussion