クラウドデータカタログCOMETAとdbt Cloudを連携する
はじめに
primeNumberが開発しているクラウドデータカタログCOMETAは、2024年10月にdbtメタデータ連携機能をリリースしました。
この記事では同機能を利用して、COMETAとdbt Cloudを連携する手順を見ていきます。
COMETAとdbt Cloudの連携でできること
COMETAは、クラウドベースのデータカタログサービスで、dbtと連携することによりDWHに格納されているテーブルなどのデーアアセットについて様々なメタデータを紐付け、管理することができます。
COMETAとdbt Cloudを連携することで、COMETA上で
- カラムレベルリネージの参照
- テーブルやビューなどを生成するSQLの参照
- dbt projectで管理しているdescriptionなどのメタデータの参照
ができ、dbt Cloudを利用していない社内ユーザーにも簡単にdbt projectで管理している情報を共有することができるようになります。
連携方法
COMETAのdbt連携は、manifest.json や catalog.json のようなdbtのartifacts(dbt build実行時の成果物)をS3にアップロードしたものをCOMETAが日次で参照することで連携します。
連携の大きな流れは、dbt Coreを利用している場合の連携と変わりませんので、詳細は下記プログ記事をご参照ください。
ここでは、AWS Lambdaを使って、dbt CloudのAPIを叩いてdbtのartifactsを取得、それをS3に保存する処理を実装することで、連携の自動化を行います。
以下に、設定手順について説明していきます。
dbt Cloudの設定
まずは、COMETAに連携するartifactsを生成するdbt Cloudのジョブを作成し、job_idを取得します。すでにそのようなジョブが作成されている場合は、そのjob_idをご参照ください。
ここでは、
dbt build
dbt docs generate
を実行するjobを作成しました。
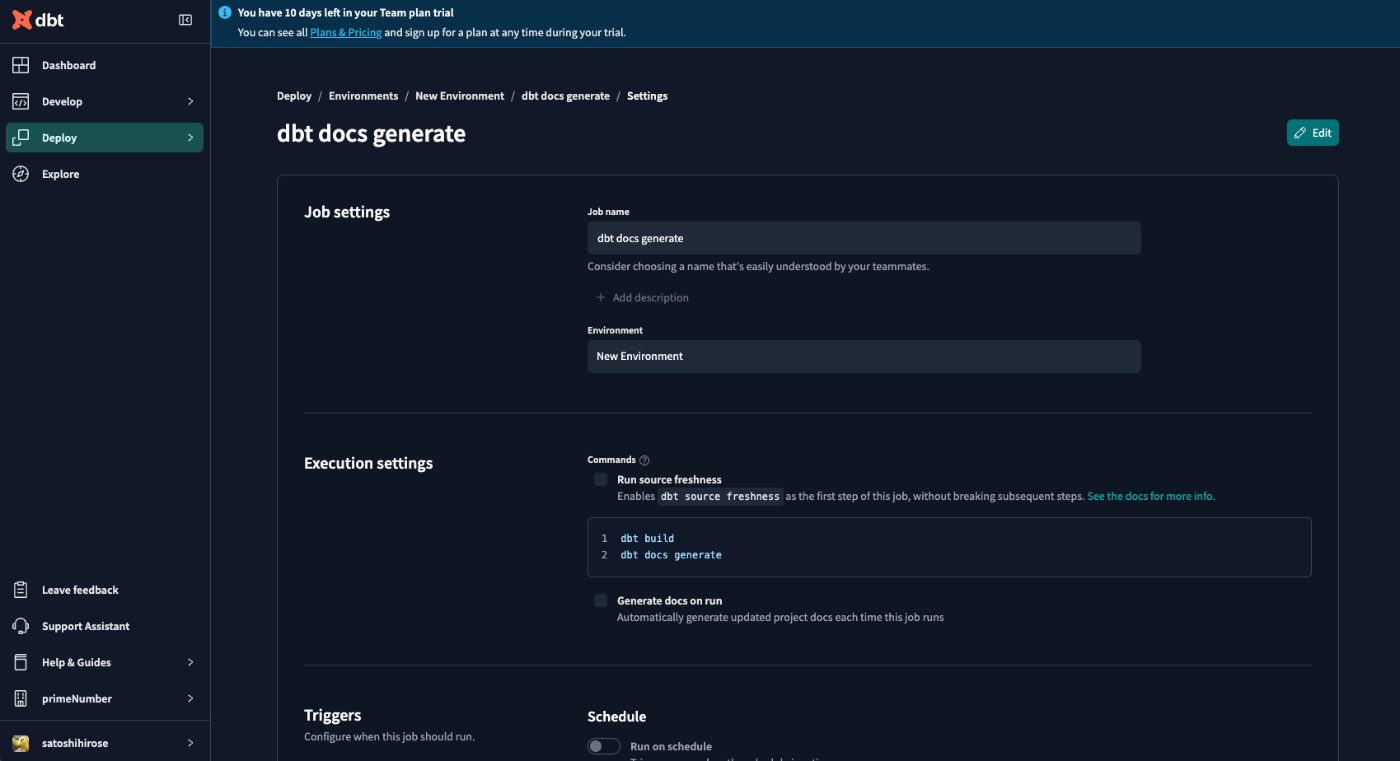
実際のそのjobを実行し成功すると、そのrunの詳細画面からそのrunで生成されたartifactsをダウンロードすることができます。

以下では、このartifactsをAPI経由で取得する方法を設定します。
Lambda関数の作成
以下は、dbt CloudのAPIを叩いてdbtのartifactsを取得、それをS3に保存する処理をPythonで実装した例です。
dbt Cloudのaccount idやaccount prefixはAccount settings画面から確認ができます。また、API TokenはAccount settings画面から発行が可能です。job idの箇所には、上記で確認したartifactsを生成するjobのidを指定してください。
from urllib import request, error
import boto3
import json
from datetime import datetime
# dbt Cloud APIの設定
DBT_CLOUD_API_TOKEN = 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX'
DBT_CLOUD_ACCOUNT_ID = 'XXXXXXXXXXXXXXXXXXXXX'
DBT_CLOUD_ACCOUNT_PREFIX = 'XXXXXXXXXXXXXXXXX'
DBT_CLOUD_JOB_ID = 'XXXXXXXXXXXXXXXXXXXXX'
# S3の設定
S3_BUCKET_NAME = 'XXXXXXXXXXXXXXXXXX'
S3_KEY_PREFIX = 'dbt_cloud/job_runs/'
def get_latest_artifact(reminder):
url = f'https://{DBT_CLOUD_ACCOUNT_PREFIX}.us1.dbt.com/api/v2/accounts/{DBT_CLOUD_ACCOUNT_ID}/jobs/{DBT_CLOUD_JOB_ID}/artifacts/{reminder}'
headers = {
'Content-Type': 'application/json',
'Authorization': f'Token {DBT_CLOUD_API_TOKEN}'
}
req = request.Request(url, headers=headers)
try:
with request.urlopen(req) as response:
return json.loads(response.read().decode())
except error.HTTPError as e:
print(f'HTTPError: {e.code} {e.reason}')
raise
except error.URLError as e:
print(f'URLError: {e.reason}')
raise
def save_to_s3(data, bucket, key):
s3 = boto3.client('s3')
s3.put_object(Bucket=bucket, Key=key, Body=json.dumps(data))
def lambda_handler(event, context):
reminders = ['catalog.json', 'manifest.json']
for reminder in reminders:
artifacts = get_latest_artifact(reminder)
s3_key = f'{S3_KEY_PREFIX}{reminder}'
save_to_s3(artifacts, S3_BUCKET_NAME, s3_key)
return {
'statusCode': 200,
'body': json.dumps('Artifacts saved to S3 successfully')
}
# ローカルでのテスト用
if __name__ == "__main__":
print(lambda_handler(None, None))
実際にLambdaの管理画面からテスト実行してみます。
Artifacts saved to S3 successfully がコンソールに表示され成功したことがわかります。
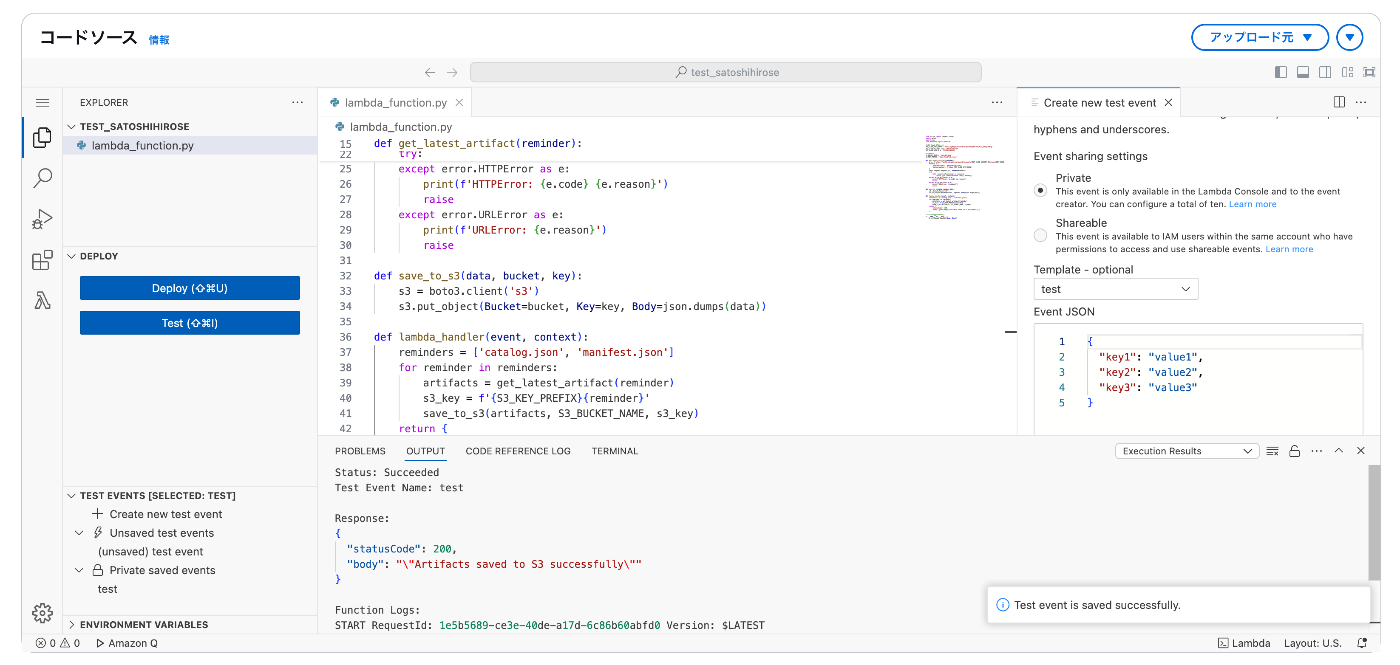
コード内で指定したS3バケットのパスに、 catalog.json と manifest.json が保存されていることが確認できます。

定期実行の設定
今回は、TROCCOのワークフロー機能を使って上記で作成したLambda関数を定期的に実行します。
ここでは簡単のため、Lambda 関数 URLを 認証なし で発行し、HTTPリクエストを行うことで実行しています。Lambda関数はAWS Eventbridge Schedulerなどでもスケジュール実行ができますので、要件に応じて実行方法を選択ください。
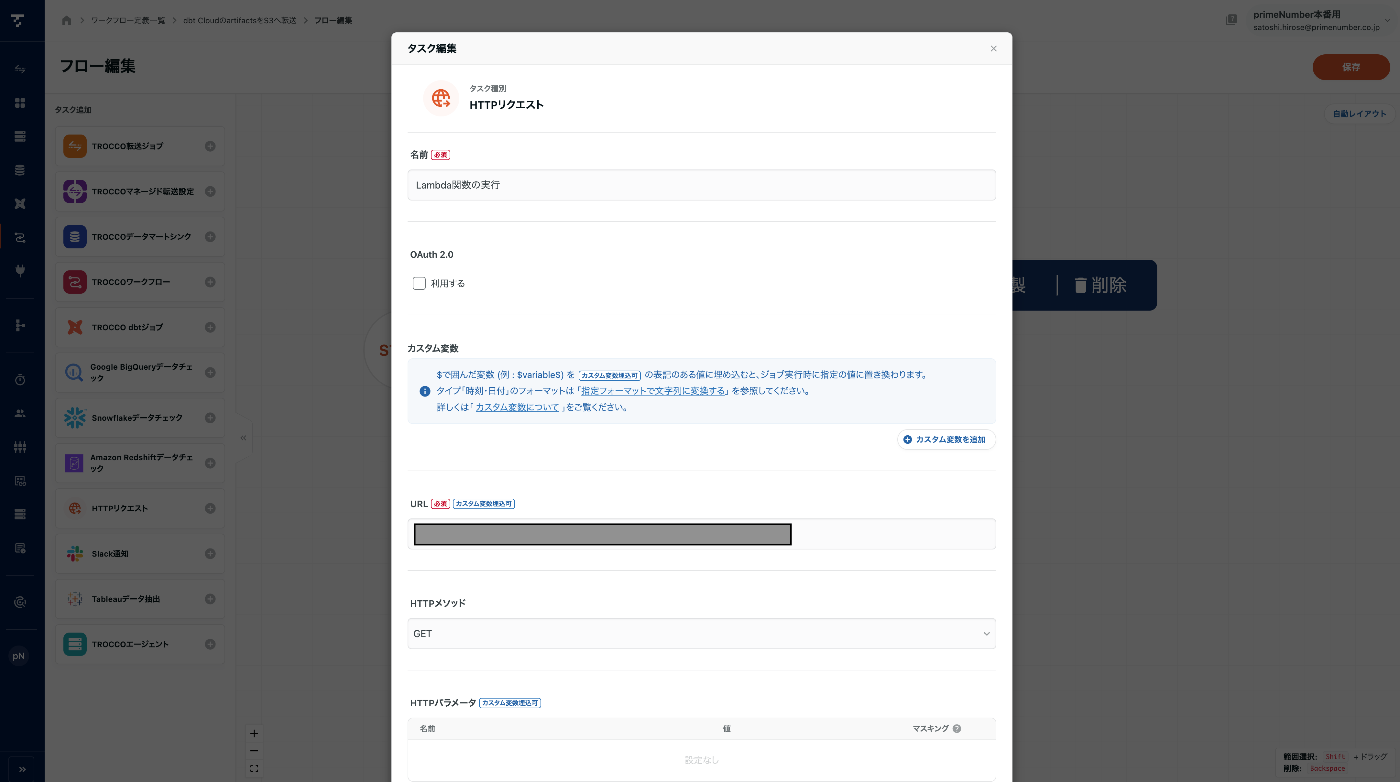
TROCCOのワークフローを新規作成して、下記画像のような HTTP リクエスト タスクを一つ追加します。

そのタスクに、上記で作成したLambda関数の、Lambda 関数 URLを追加して保存します。
作成したワークフローを実行し、成功するか確認します。
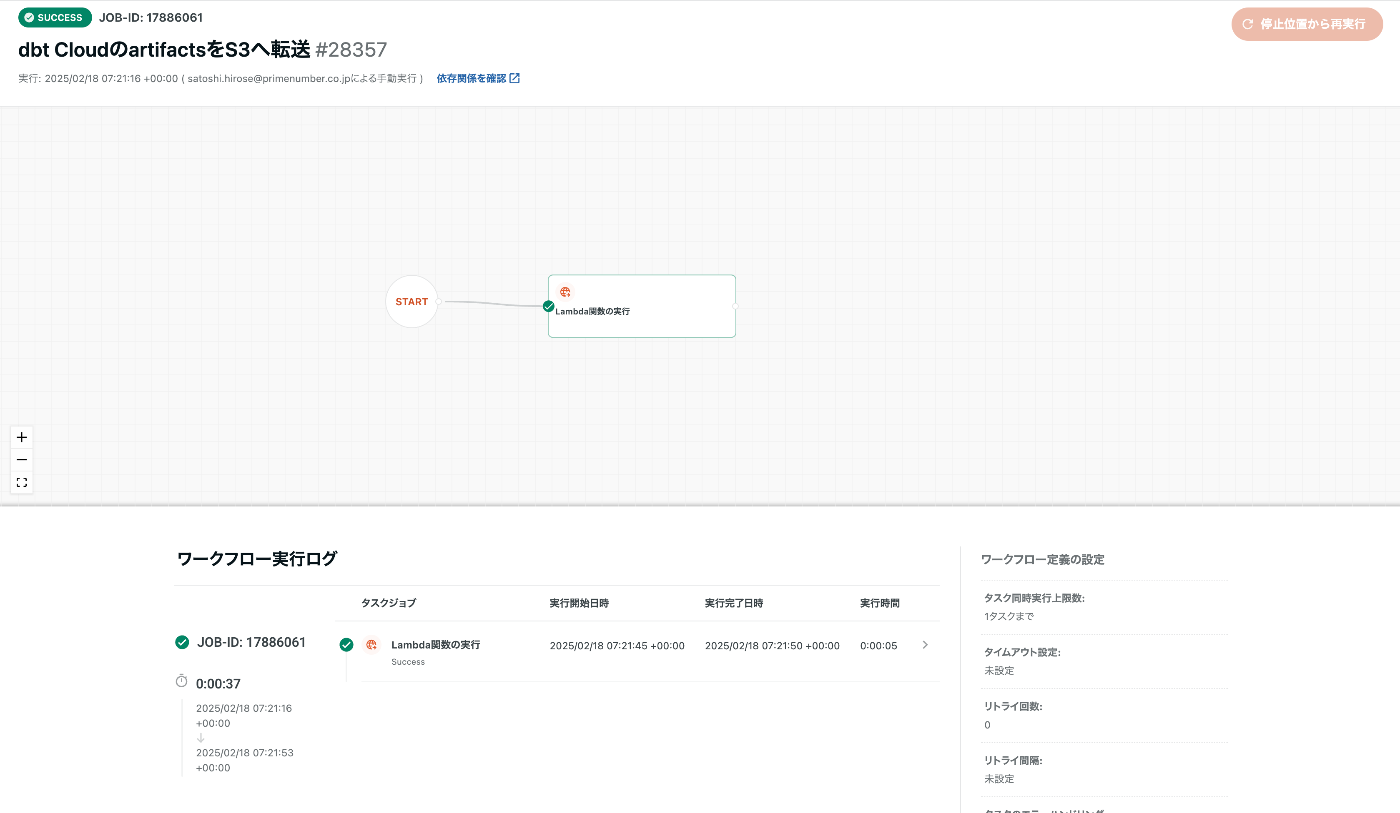
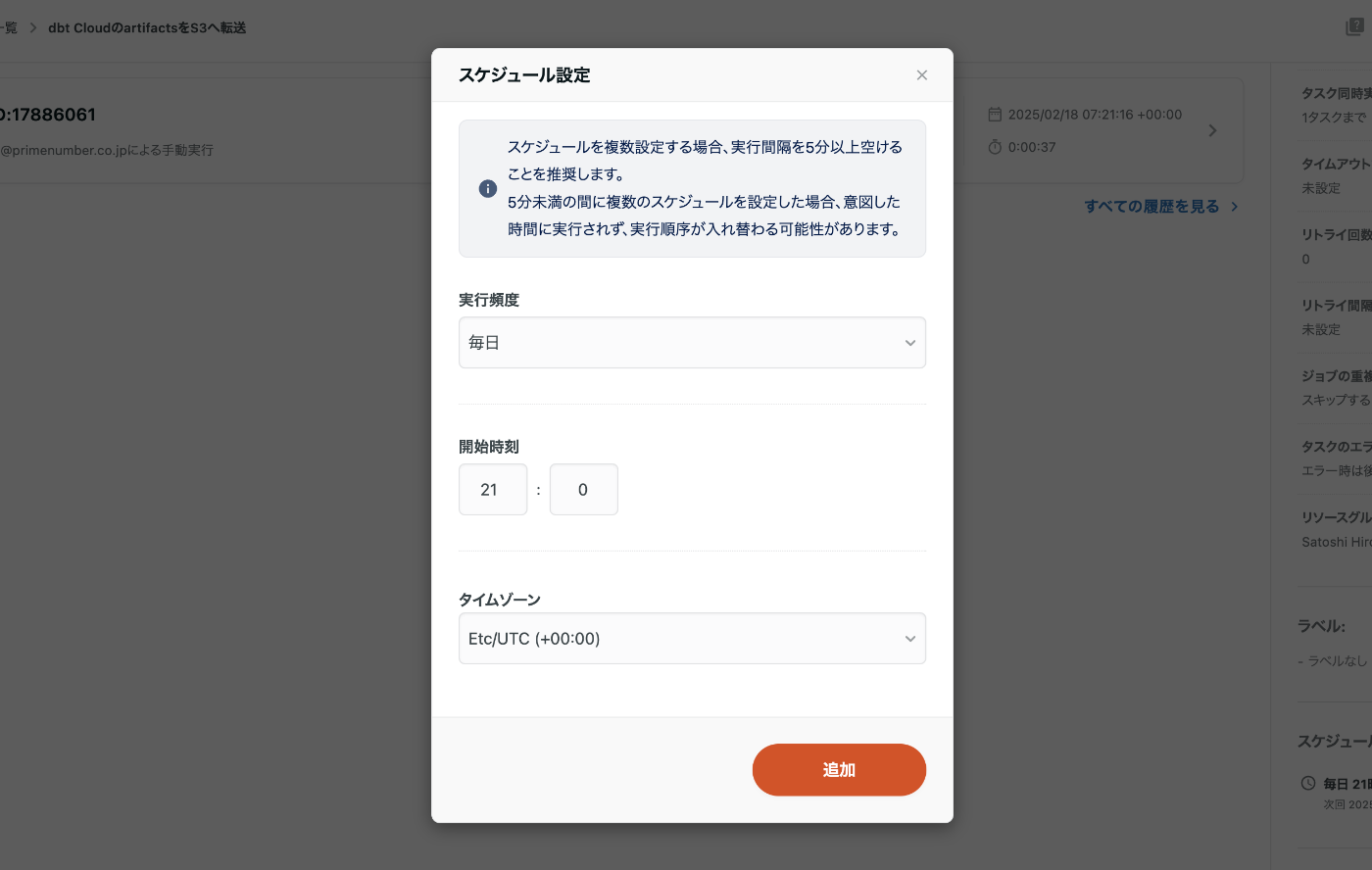
成功したら、定期実行のためのスケジュールを設定しましょう。
COMETAのdbt連携では、毎日夜中ごろにS3のファイルを参照する仕組みになっているため、その前の21時ごろにartifactsを最新にすることで、最新の情報を毎日COMETAに連携することができます。
COMETAの設定
COMETA上の設定方法は、dbt Coreの場合との設定方法と同様なので、詳細は下記ブログ記事をご参照ください。
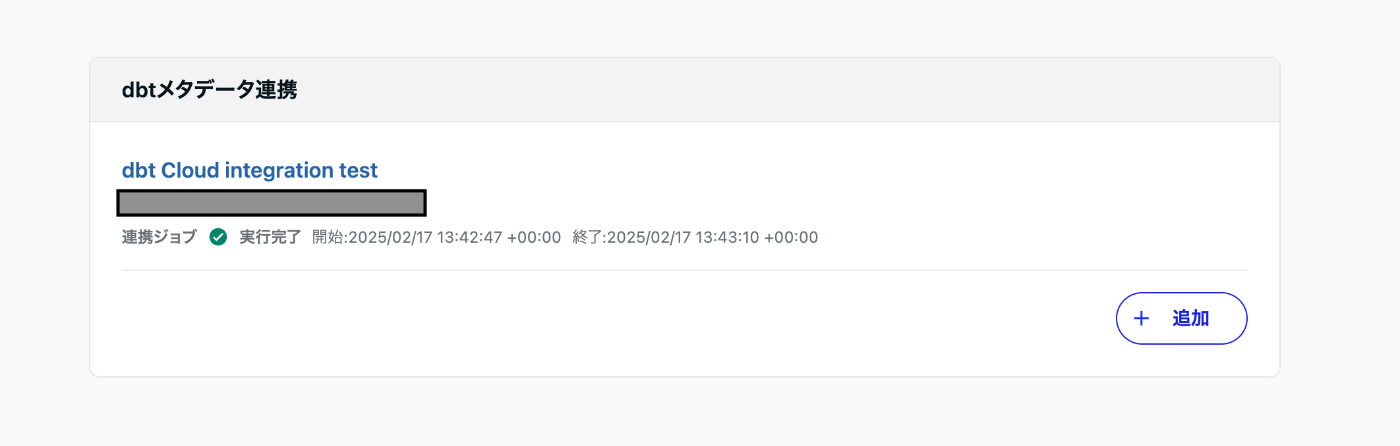
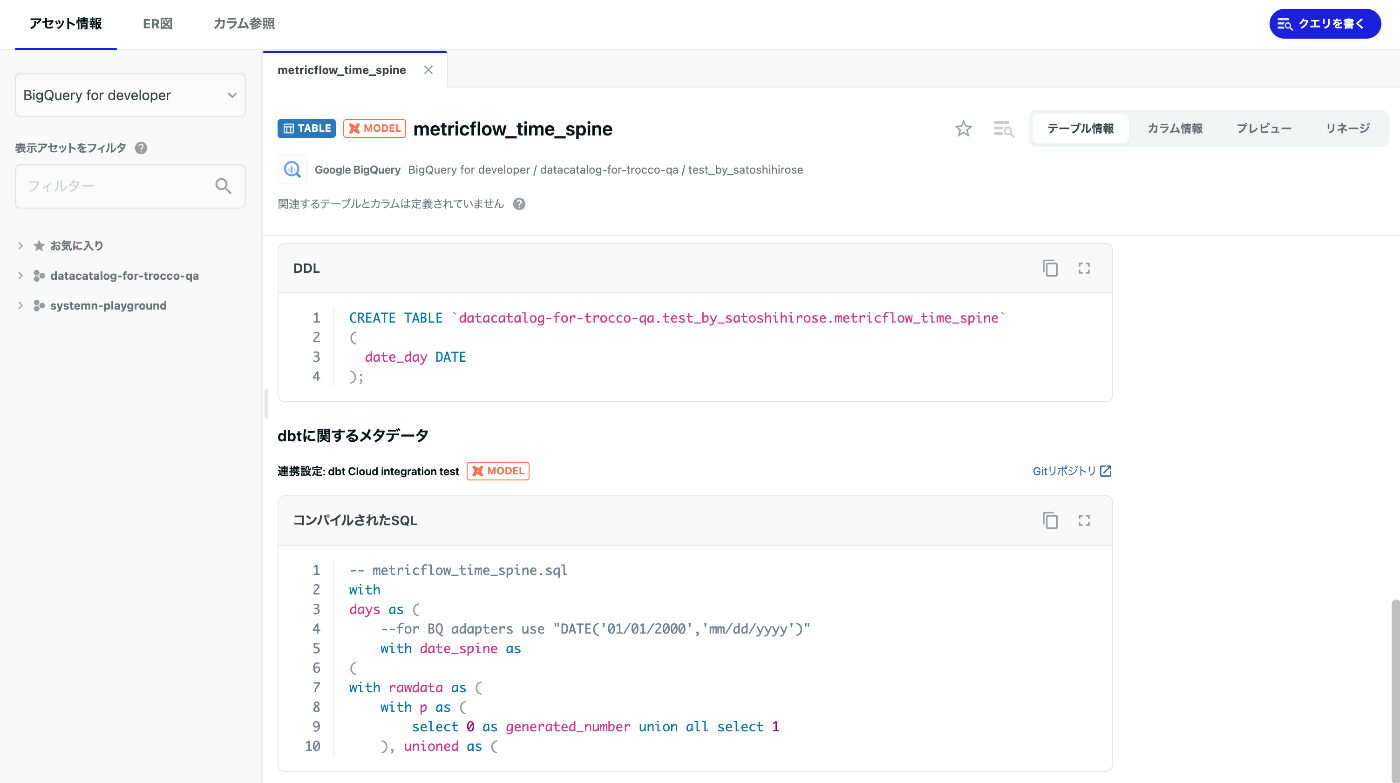
dbt連携ジョブが成功し、dbtで管理しているテーブルにdbtの情報が連携されていることを確認したら、設定完了です。
まとめ
本記事では、COMETAとdbt Cloudを連携する方法について説明しました。COMETAを試しに利用してみたい方、お客様に提案してみたい方など、お気軽にお問い合わせフォームからお問い合わせください。
Discussion