Colab上でローカルLLMの簡易APIサーバーを構築する【Colab × FastAPI × ngrok】
ああ〜、ローカル LLM のデモアプリを手軽に動かせるような環境を用意したいんじゃ〜
0. 想定読者 & 本記事ハイライト
本記事では、Google Colab 上で GPU リソースを活用し、FastAPI と ngrok を用いてローカル LLM デモアプリを外部からアクセス可能な API サーバーとして構築する方法をご紹介します。
対象とする読者は、
- LLM を用いた簡易 API サーバーを構築したい方
- ローカル LLM のデモアプリを作成したいが、オンプレやクラウドサーバー環境整備に悩んでいる初心者〜中級者
- 簡易なプロトタイプを短時間で立ち上げたいエンジニア
です。
1. 本記事のモチベーション
大学院に通う修士学生の satosho と申します。
昨今の大規模言語モデル(LLM)研究の盛り上がりもあり、所属する研究室内でも LLM に関する研究を行う学生が増えてきた印象があります。
主に自然言語処理を扱う研究室なので、毎年の大学オープンキャンパスでも自然言語処理を組み込んだ体験型の研究室紹介も行っており、例えば研究で使用されたチャットシステムを使って見学に訪れた高校生の方や一般の方が操作可能なデモアプリも用意しています。
しかし、ローカル環境で動作・学習が可能なオープンソース LLM も多く公開されている現在では、「もしかして LLM を使って何か面白いデモを用意できるのでは...?」とも想像しています。
そこで本記事では、ローカル LLM を用いたデモアプリを作りたい〜LLM の動作環境ってどうやって用意するの編〜 として、私が実際にデモを作成した際の学びを共有することを目指します。
具体的に以下のようなケースを想定しています:
- 研究室内で使う簡易なローカル LLM デモアプリを(一時的に)ユーザーアクセス可能な形で共有したいケース
- GPU 付きマシンが手元にないけど短期間で LLM を動かして確認したいケース
2. なぜ Google Colab を選ぶのか
まず前提として、今回想定するシナリオをご説明します。
- ローカル LLM を用いた、ユーザー操作が可能なチャットアプリ(デモ)を作成する
- ユーザー入力をプロンプトとして、LLM 推論を実行する
- ユーザー操作に関する UI は、別途フロントエンドフレームワークなどで独立して構築する
そのため、今回のシナリオで求める主な要件は以下のようになります。
| 優先度 | 各要件の内容 | 必要度 |
|---|---|---|
| 1 | API サーバーとして HTTP リクエストを受け付ける機能 └ LLM への入力 |
必須 |
| 2 | LLM 推論のための GPU リソースへのアクセス | 必須 |
| 3 | LLM を Python で扱う都合上、API サーバーも Python ベースで 構築可能な環境が望ましい |
希望 |
以上を踏まえ、先に結論を述べると、デモ的な LLM アプリケーションを手軽に実行する環境としてはGoogle Colabが有力な手段と言えそうです。
いくつか不便な点もありますが、デモ用途であれば大きな問題とはなりにくいという結論です。
以下の比較は、GPU リソース利用と API サーバー構築が可能なサービスを、約 40 時間の短期的デモ利用という前提で比較した一例です。
(料金はドル為替やプランにより変動します)
他サービスの比較・検討
今回はローカル LLM のサンプルとして、 ELYZA 社が提供する Llama-3-ELYZA-JP-8B を使用します。
コスト目安は、このモデルを動作させるために必要な GPU メモリをベースとして選出・試算しています(量子化等必要メモリの削減のための工夫は考えません)。
| サービス | デモ用途での適性 | コスト目安 |
|---|---|---|
| Google Colab | GPU 対応ノートブック環境 外部公開は ngrok などで可能 一時的デモには十分 |
約 1,200 円/100 Unit L4 GPU: 約 2.4 Unit/hr (→ 約 30 円/hr) 40 hr 利用で約 1,200 円程度 |
| AWS (EC2) | IaaS 型で柔軟性が高く本格運用向け 初期設定、権限管理、コスト管理が比較的複雑 |
P3 インスタンス例: 約 480 円/hr 40 hr で約 19,200 円 |
| GCP | 同上(IaaS 型で柔軟性が高い) 設定は AWS 同様に手間がかかる |
T4(32GB)例: 約 170 円/hr 40 hr で約 6,800 円 |
| Paperspace | Colab 類似の DaaS 型環境 手軽だが環境カスタマイズ幅は限定的 |
V100(32GB)例: 約 360 円/hr 40 hr で約 14,400 円 |
AWS や GCP は機能が豊富で柔軟性が高いのですが、GPU インスタンスのコストや初期設定の手間が大きくなりそうです。慣れていない人がデモで敢えて選択するメリットは小さいと感じます。
Paperspace は Colab 同様にノートブック形式で比較的簡易なようなのですが、料金面・柔軟性の点で Colab より有利とは言い難いかもしれません(使ったことがないため、実際の使用面は見聞きした程度です)。
総合すると、短期的なデモ用途であれば、
- GPU が手軽に使えて、
- Python ベースの API サーバーを素早く起動・公開できる
という点で、Google Colab は他のサービスに比べて導入障壁やコスト面で有利だと判断しました。
それでは、実際に LLM サーバーのデモを作って試してみましょう!
3. LLM API サーバーのデモ / 全体構成
ここから実際に LLM API サーバーを構築していきます。
まずは、全体構成を共有します。
アウトライン
まず最初に、API サーバーの全体構成をご説明します。
次に、実装例・動作例をコードベースでご紹介するので、ご参考にしてください。
今回はローカル LLM が既に用意されている状態を想定します。
具体的には、ローカル LLM のサンプルとして、 ELYZA 社が提供する Llama-3-ELYZA-JP-8B を使用しました。
処理の全体像と LLM API サーバーの役割
少し難しいと感じる方は、ここを飛ばしていただいても問題ありません 🙆♂️
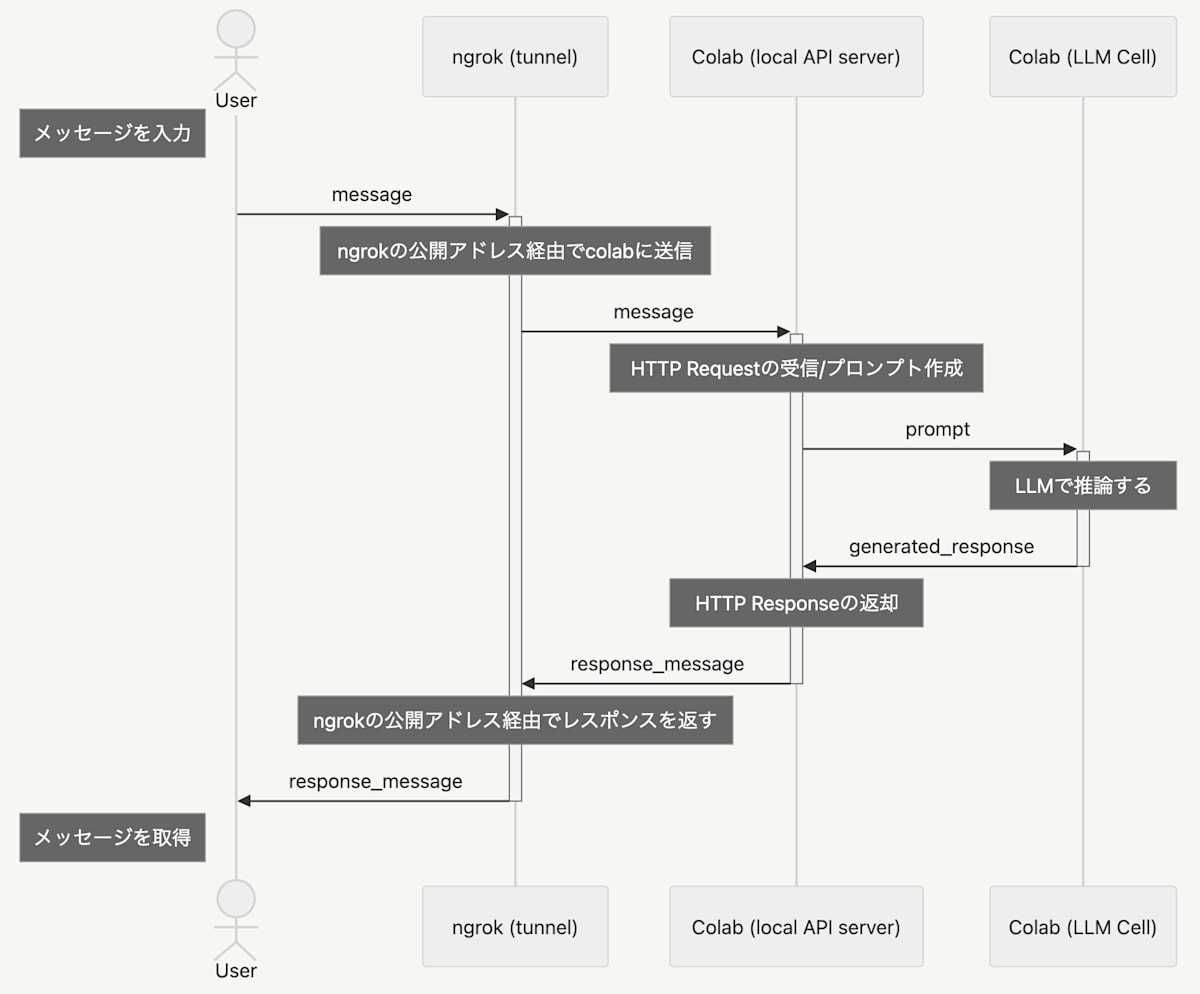
想定シナリオのシーケンス図
処理の流れは以下の通りです!
- ユーザーが入力したメッセージを、ngrok 上の Public な API エンドポイントに送信する
- API サーバーでメッセージを受け付け、LLM 推論結果を返却する
- ngrok(後述)で公開する Public URL を経由して、localhost の API エンドポイントにユーザーメッセージを含んだ HTTP Request が届く
- FastAPI(後述)によって、届いたリクエストを処理する
- Colab 上で LLM 推論を実行する
- 推論が完了したら、実行結果を HTTP Response としてリクエスト元に返却する
- 推論結果が無事にユーザーに届く 🙌
ngrok や FastAPI といったツールが出てきましたので、以下で選定理由をご説明します。
ツール選定理由
先ほど示した要件を整理すると、ユーザー入力の受付・LLM 推論を担うバックエンド側では、LLM へのユーザー入力を HTTP リクエストとして受け付け、推論結果を HTTP レスポンスとして返却する API サーバーとしての機能が必要です。
最小限の設計を行い、今回は以下のような技術構成としました。
API サーバー(ローカルサーバー)
-
- Python 製の軽量かつ直感的な Web フレームワーク
- 非同期処理や Swagger UI を標準でサポートしていて、プロトタイプ段階での開発効率が高い
- 自分(未経験ユーザー)の学習も兼ねて、導入のしやすさと実用性を重視して選定しました
-
- FastAPI をはじめとする ASGI フレームワーク向けの軽量かつ高パフォーマンスなサーバー
- 非同期 I/O に対応、大量のリクエストを効率的に処理可能
- 簡単なコマンドで FastAPI アプリを起動できるため、デモ環境での立ち上げが容易
トンネリング(ポートフォワーディング)
-
ngrok
- ローカル環境を外部公開するためのトンネリングツール
-
localhost:ポート番号で起動中のローカル API サーバーを、ngrok のサーバーを介して外部からアクセス可能な URL として公開することができる - 無料アカウントでも一通りの機能が利用でき、すぐに Public URL を生成してデモを共有できるという手軽さ
- 今回のケースでは無料枠で無問題ですが、ngrok 独特の制限が気になる場合は代替としてlocaltunnelやCloudflare Tunnelなども存在するようです
なんで ngrok を利用する必要があるの?イメージが湧かない人向けに...
o1 >>
ローカルサーバー(今回は Colab インスタンス上で起動)に外部からアクセスするには、基本的にポート開放やグローバル IP の割り当てなどが必要です。
しかし、Colab などの一時的な環境ではネットワーク設定を自由に変更できない場合があり、外部アクセスが不可能なケースが多々あります。
ngrok はこうした制約に対処する手段として有効で、ポートフォワーディングを介してローカルサーバーを外部に公開し、HTTP リクエストを通せるようにします。このように、FastAPI + uvicorn でローカル Web サーバーを起動し、ngrok でトンネリングして外部に公開という構成を取ることで、Colab 上の LLM 推論を外部からアクセス可能なデモアプリとして整備できます。
4. LLM API サーバーの具体的なコードと検証内容
それでは実際に LLM API サーバーの検証を行います。
LLM を実行する API サーバーを構築し、エンドポイントへリクエストを投げてみます。
以下の手順で行いますので、気になる地点からご覧ください!
- ■□□□□ Colab インスタンス(GPU)の作成と LLM の起動準備
- ■■□□□ LLM 推論に必要な処理系の定義
- ■■■□□ FastAPI による API・スキーマ定義
- ■■■■□ ngrok のトンネリング設定と API サーバーの起動
- ■■■■■ POSTMAN による API テスト
■□□□□ Colab インスタンス(GPU)の作成と LLM の起動準備
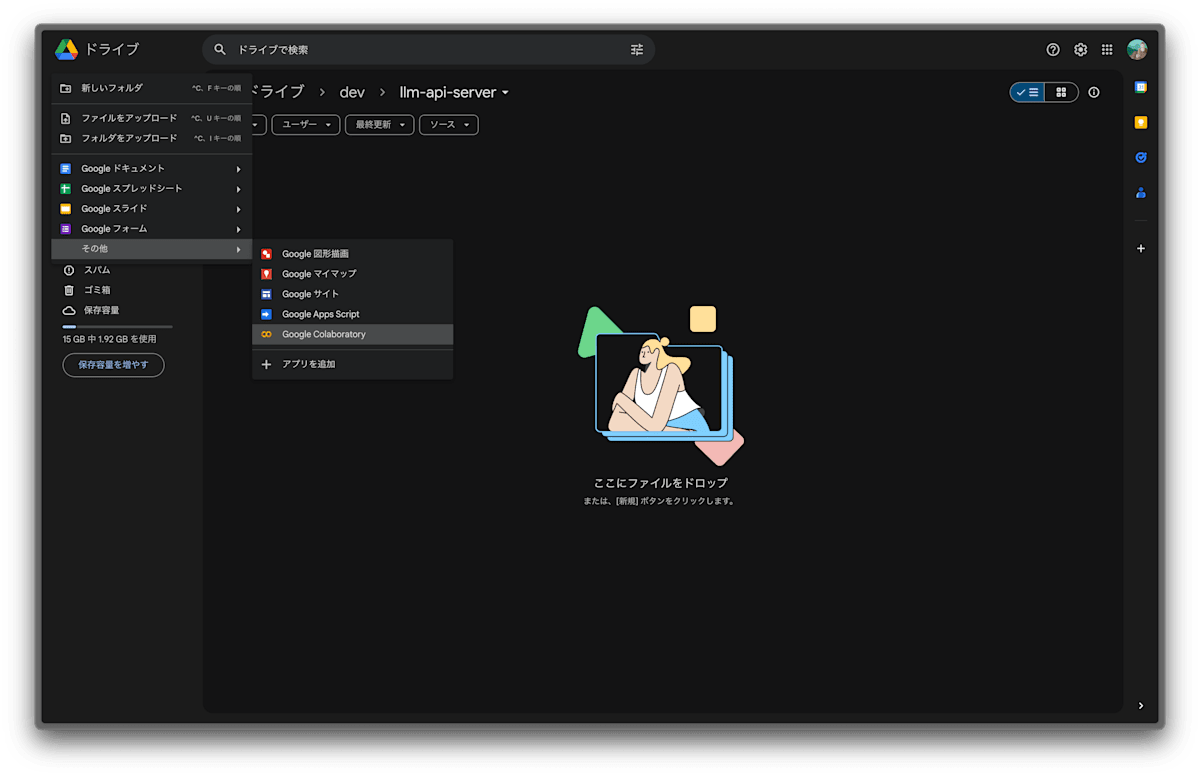
Google Drive または Google Colaboratory 上でノートブックを作成します。
今回は Google Drive 上で作成します.
もしまだ Colaboratory アプリをインストールしていない場合は,「+ 追加 > その他 > + アプリを追加」から Colaboratory を検索・選択してインストールします.
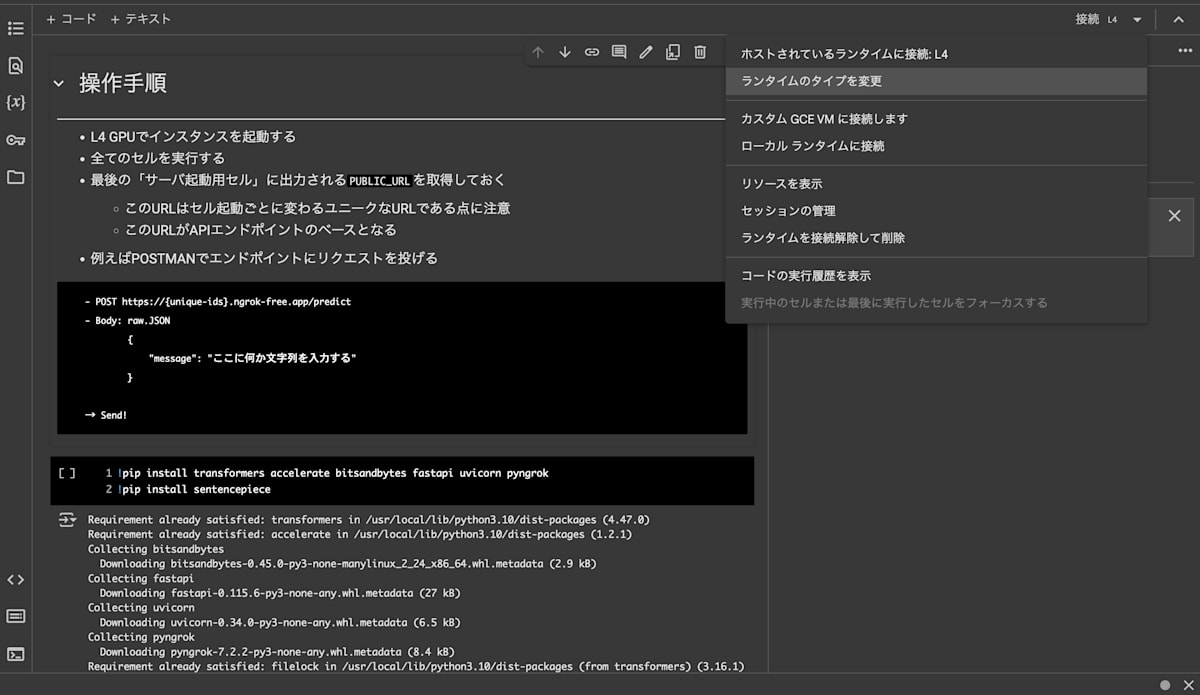
ノートブックを開いたら、右上のドロップダウンメニューから「ランタイムのタイプを変更」を選択します。
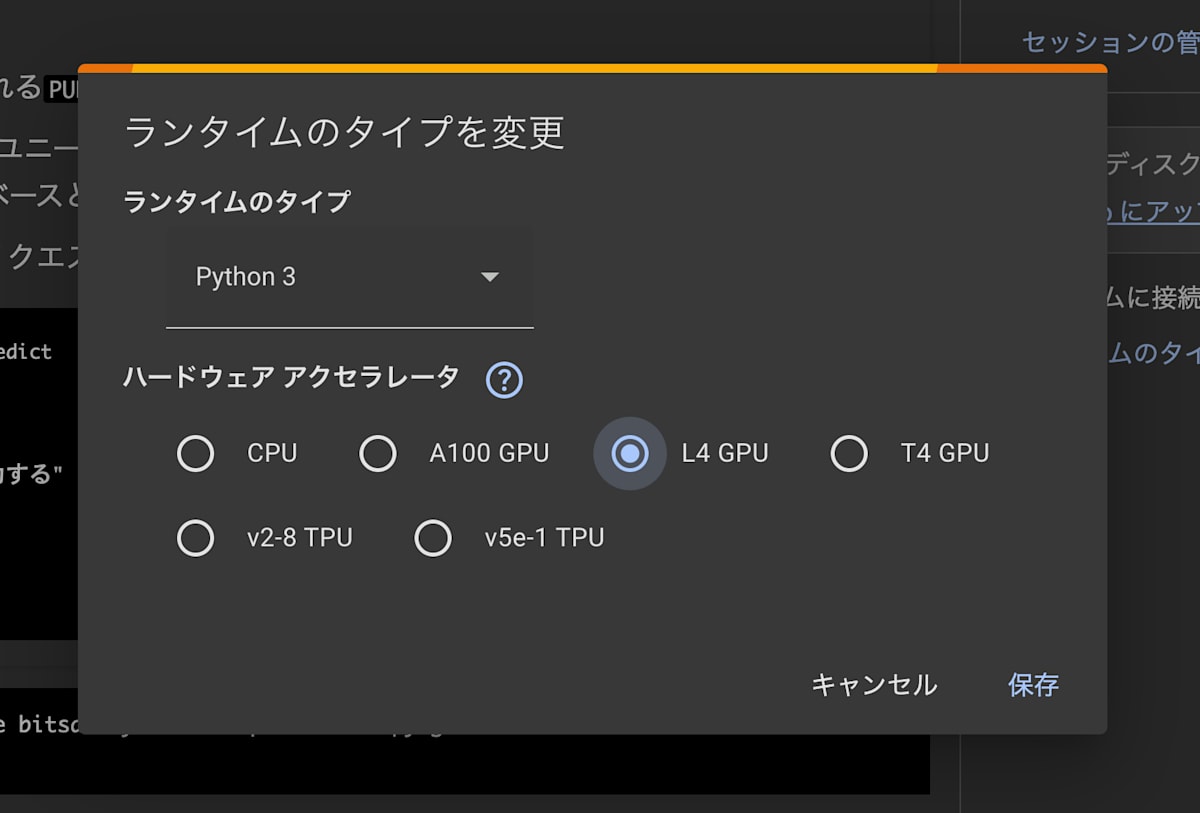
「L4 GPU」 を選択・保存してから、ドロップダウンメニュー付近の「接続」ボタンを押してインスタンスを起動します。
最初に、今回利用する LLM のインストールを行います。
セルを作成して、以下のように記述してセルを実行します。
# ライブラリをインストール
!pip install transformers accelerate bitsandbytes fastapi uvicorn pyngrok
!pip install sentencepiece
# 必要なライブラリをインポート
from pyngrok import ngrok # ngrokでトンネリング
import torch
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
import nest_asyncio
from pydantic import BaseModel
import uvicorn
from transformers import AutoModelForCausalLM, AutoTokenizer
# LLMのモデル(重み)をダウンロードします
# 2.5分×4 くらいの時間がかかりました
# 日本語Llama ELYZAモデル例: "elyza/Llama-3-ELYZA-JP-8B"
model_name = "elyza/Llama-3-ELYZA-JP-8B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
)
model.eval()
■■□□□ LLM 推論に必要な処理系の定義
ユーザーからのリクエストを受け取ると、API サーバーは LLM の推論を実行します。
ここでやることは、「LLM に渡すプロンプトの生成」と「LLM による推論(応答生成)」の関数の定義です。
# systemメッセージ(モデルキャラクター・行動方針)
DEFAULT_SYSTEM_PROMPT = "あなたは誠実で優秀な日本人のアシスタントです。特に指示が無い場合は、常に日本語で回答してください。"
# Chat形式プロンプト生成用関数
def build_prompt(user_message: str) -> str:
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": user_message}
]
# `apply_chat_template`はELYZAモデル付属のtransformers_llama_japanese拡張で利用可能な仮想メソッド例
# 必要に応じて、適宜 `apply_chat_template` に相当する独自実装またはモデルに対応したフォーマット生成を行う
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
return prompt
# 推論(応答生成)関数
def generate_response(user_message: str) -> str:
prompt = build_prompt(user_message)
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=1024,
do_sample=True,
temperature=0.7,
top_p=0.9,
pad_token_id=tokenizer.eos_token_id,
)
output = tokenizer.decode(output_ids[0][token_ids.size(1):], skip_special_tokens=True)
return output.strip()
def generate_response_dummy(user_message: str) -> str:
"""
APIテスト用ダミー関数(LLM推論を実行しないためCPUインスタンスで起動してテスト可能)
"""
return "dummy: こんにちは!お元気ですか?"
■■■□□ FastAPI による API・スキーマ定義
# FastAPI定義
app = FastAPI()
# CORS設定
app.add_middleware(
CORSMiddleware,
allow_origins=['*'],
allow_credentials=True,
allow_methods=['*'],
allow_headers=['*'],
)
# スキーマ定義
class RequestBody(BaseModel):
message: str
@app.post("/predict")
async def predict(req: RequestBody):
response_text = generate_response(req.message)
# response_text = generate_response_dummy(req.message) # APIテスト用
return {"response": response_text}
FastAPI では、app オブジェクトを通じてルーティングやミドルウェア設定を行います。
今回はデモ用途を想定しているため、CORS 設定は任意のドメインからのアクセスを許容しています。
また、スキーマ定義として pydantic の機能を利用し、型に基づいたデータバリデーションを行います。
最後に LLM 推論機能を提供する API エンドポイントを定義しています。
CORS 設定はこちらの記事を参考にさせていただきました。
■■■■□ ngrok のトンネリング設定と API サーバーの起動
# ngrokでAPI URLを公開する
from google.colab import userdata
my_token = userdata.get("NGROK_TOKEN")
ngrok.set_auth_token(my_token)
ngrok_tunnel = ngrok.connect(8000)
print('PUBLIC_URL:',ngrok_tunnel.public_url)
nest_asyncio.apply()
uvicorn.run(app,port=8000)
# サーバ起動中はセルが動作し続けます
pyngrok ライブラリで ngrok のサービスを利用するためには、自身の ngrok アカウントに紐づくアクセストークンが必要になります。
事前に ngrok のアカウントを確認してアクセストークンを控えておきましょう。
また、控えたアクセストークンは、セルに直書きするのではなく、Colab ノートブックの環境変数にセットしておくと安全です(シークレット機能を利用)。
例えば、Colab の環境変数(またはユーザーデータ)としてセットしてある ngrok の認証トークン ("NGROK_TOKEN") を取得し、
# 環境変数にセットされたキー・バリューを利用する
from google.colab import userdata
my_token = userdata.get("NGROK_TOKEN")
set_auth_token メソッドで登録しています。
これで ngrok のサービスを利用可能になります。
ngrok.set_auth_token(my_token)
■■■■■ POSTMAN による API テスト
ここまでの操作で、API サーバーを起動するところまで行いました。
以下のようにセルが起動し続ける状態になれば OK です!
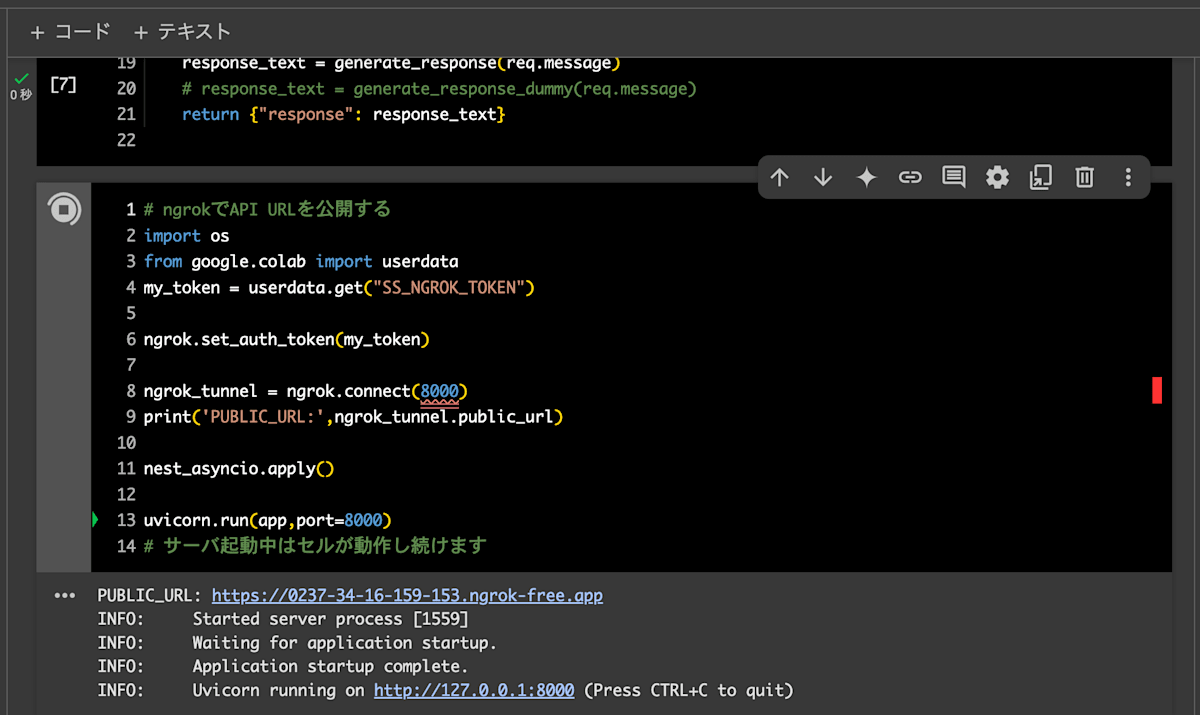
ここでは、Uvicorn が起動している http://127.0.0.1:8000 のローカルサーバーのアドレスを、ngrok の PUBLIC_URL にポートフォワードしています。
次に POSTMAN を開いて、起動している API エンドポイントに実際にリクエストを投げてみます。今回は Web 版の POSTMAN を利用しました。
POSTMAN を開いた画面です。
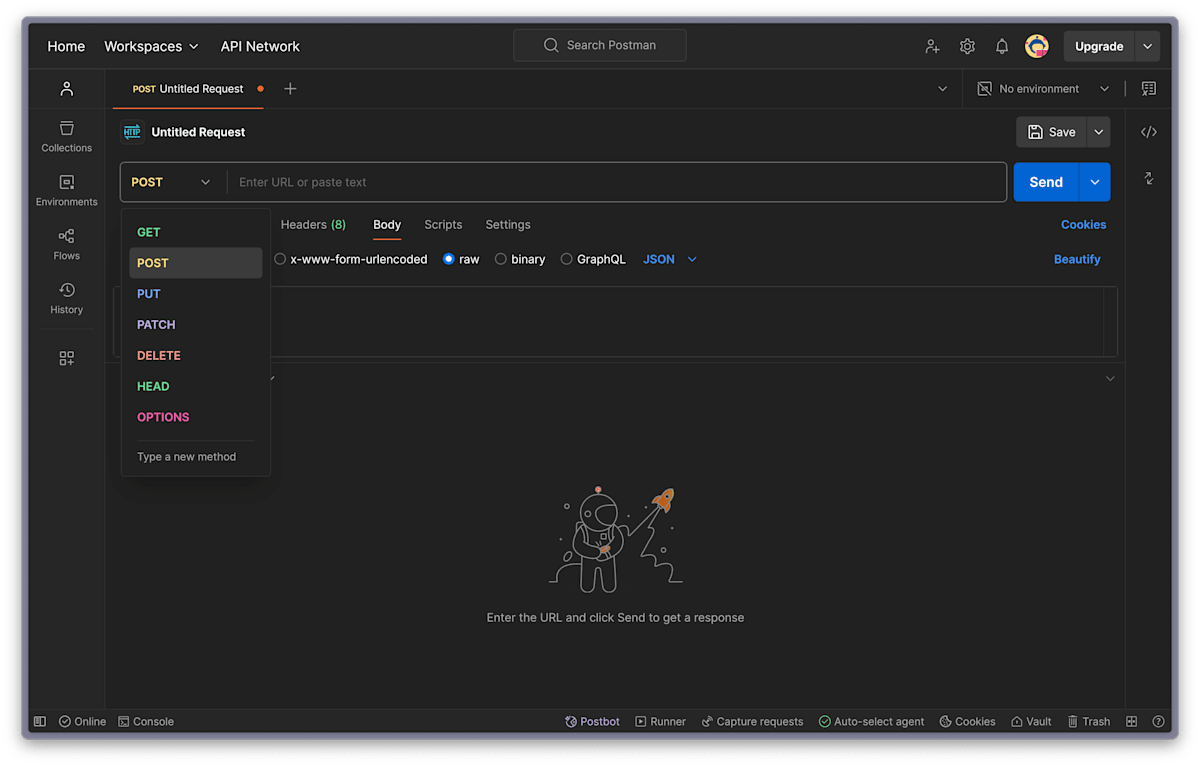
GET メソッドを POST メソッドに変更します。
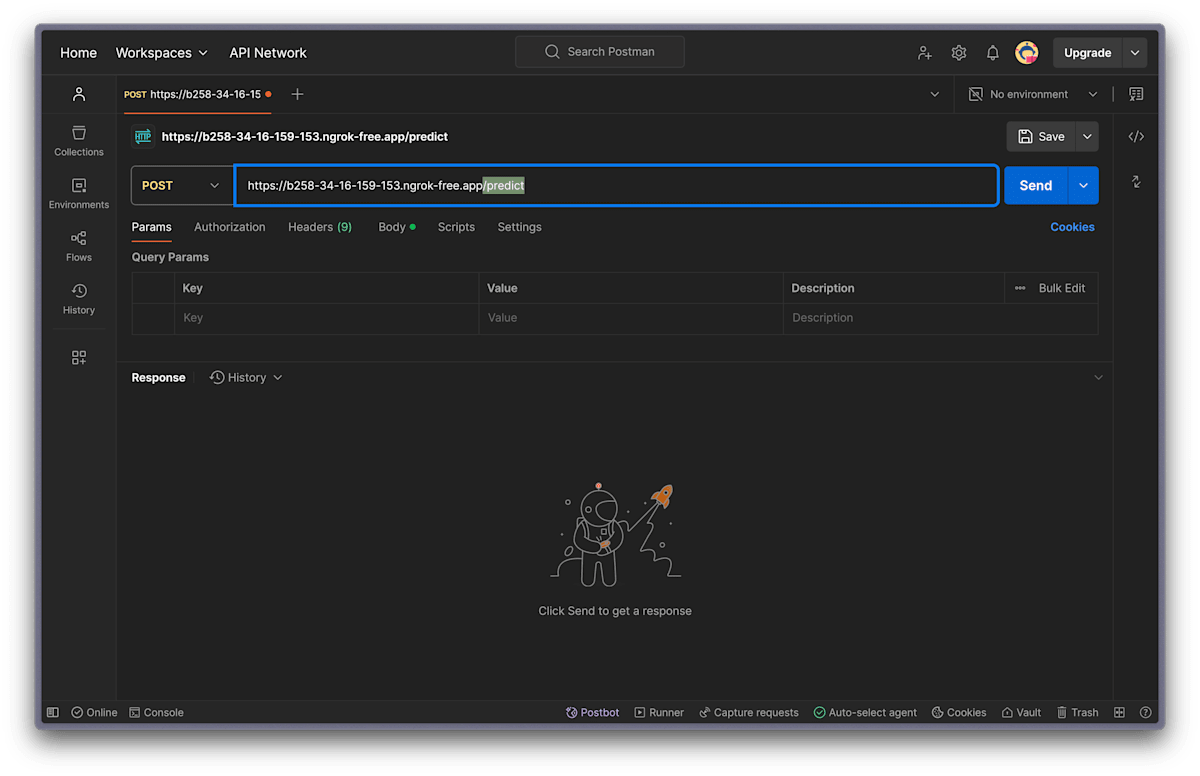
次に、先ほど Colab のセルに出力された PUBLIC_URL の値を POSTMAN の URL の欄に入力します。
エンドポイントは /predict になるので注意!
それでは、実際に LLM にメッセージを送信してみましょう。
リクエスト Body で row→JSON 形式で送信してます。
Body を入力したら、右上の Send ボタンを押してレスポンスを待ちます。
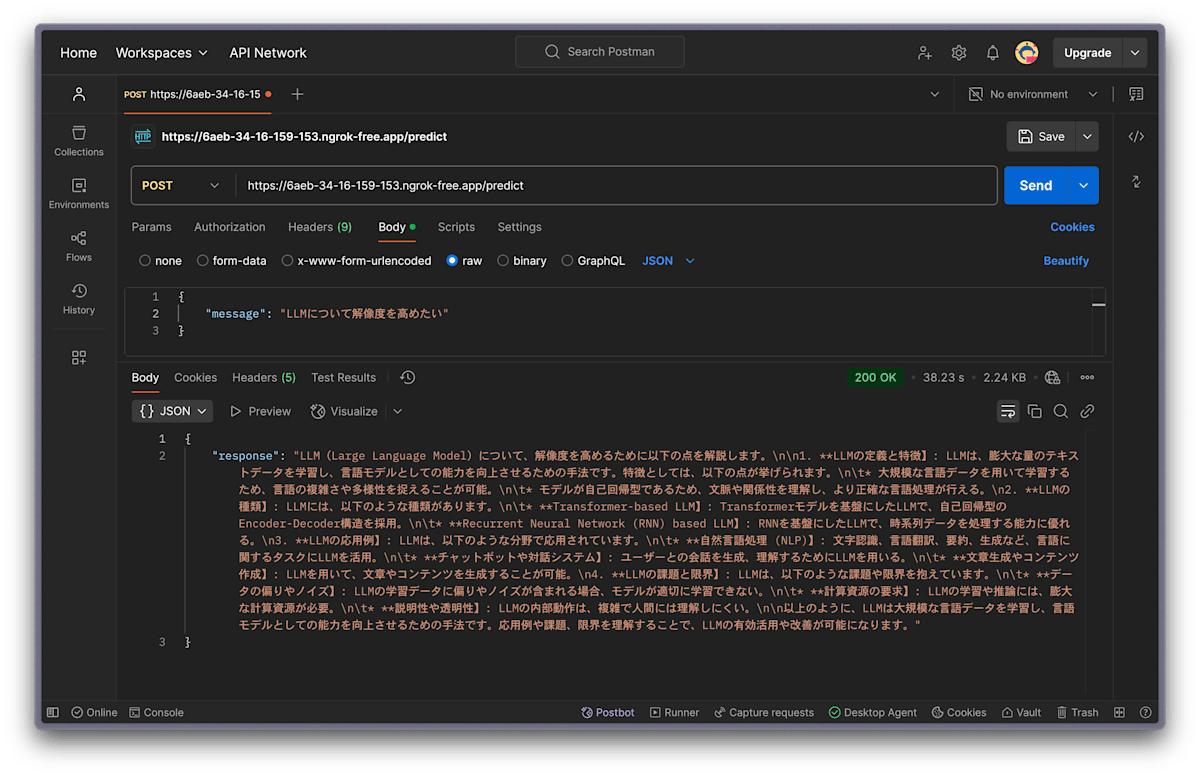
数十秒待っていると、このようなレスポンスが返ってくるかと思います!
うまく推論できていますね。
応用と発展
一般的な使用シーンを考えると、React や Nextjs など UI ライブラリ・フロントエンドフレームワークを使用するケースが多いと思います。
例えば React(Nextjs)でユーザー画面を構築し、ユーザーが入力したメッセージを API エンドポイント(LLM) に投げ、その結果を再びユーザー画面に表示する、という場合です。
エンドポイントにリクエストを投げ、その結果を JSON 形式で受け取る、という処理が一般的でしょうか。
ぜひご参考ください。
// イメージを載せます
export const Home = () => {
...
const handleSend = async () => {
try {
const res = await fetch(endpoint, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({ message }),
});
if (!res.ok) {
throw new Error('Network response was not ok');
}
const data = await res.json();
// dataの構造に応じて変更が必要かもしれない
setResponseText(data?.response ?? 'No response');
} catch (error: unknown) {
if (error instanceof Error) {
setResponseText(`Error: ${error.message}`);
} else {
setResponseText('An unknown error occurred');
}
}
};
return (...)
}
まとめ
本記事で示した方法を用いれば、手軽に Google Colab 上で FastAPI サーバーを起動し、ngrok で外部からアクセスできる環境を構築することが可能です。
ローカル LLM を用いたデモアプリを作成する際には、ぜひご参考にしてください!
最後に
ここまでご覧いただき、誠にありがとうございます。
何かお気づきの点がございましたら、お手数ですがコメントいただけますと嬉しいです。
また参考になりましたら、いいね・ブックマークもお願いします!
Discussion