GCP Professional Data Engineer試験メモ
感想
- 公式の模擬試験の内容とほぼ同じ問題が混ざっていたので、事前に解いておくとよい。
- 模擬試験 25 問だけでは不足しているので、udemy 講座(【最短攻略】Google Cloud 認定 Professional Data Engineer 模擬問題集 )で学習した。
- 主要サービスはハンズオンしておいた方が分かりやすい。
受験について
- 市ヶ谷テストセンターで受験
- 制限時間 2h でかなり余裕をもって見直せる
- 試験会場で解答を提出ボタンを押すとその場で合否が分かる(後日正式な結果が届く)
勉強内容メモ(※自分用)
BigQuery
- 準リアルタイムである程度複雑な SQL クエリが可能
- 破損の検出が 7 日以内の場合、過去の時点のテーブルに対してクエリを行い、スナップショット デコレータを使ったクエリで破損前のテーブルからクエリして復元
- オンライン分析処理(OLAP)システムでのインタラクティブなクエリが必要な場合は、BigQuery を検討。
BigQuery のオーソライズドビュー
- 承認済みビュー。通常のビューではソースとなるテーブルへのアクセス権限も付与する必要があるが、承認済みビューではソーステーブルへの権限なしで特定のユーザーやグループと共有できる。
アクセス制御リスト(ACL)
- 細かく設定したい場合。ほとんどの場合は IAM で事足りる
BigQuery テーブル ACL では、テーブルやビューなどのリソースにテーブルレベルの権限を設定できます。 テーブルレベルの権限により、データまたはビューにアクセスできるユーザー、グループ、サービス アカウントが決まります。 ユーザーに完全なデータセットへのアクセス権を与えることなく、特定のテーブルまたはビューへのアクセス権を付与できます。
スロット
- BigQuery スロットは、BigQuery で SQL クエリを実行するために使用される仮想 CPU 。BigQuery では、クエリのサイズと複雑さに応じて、クエリに必要なスロット数が自動的に計算。
- オンデマンド料金モデルまたはフラットレート料金モデルのいずれかを選択
フラットレート料金モデルのお客様は、予約するスロットの数を明示的に選択します。クエリはその容量内で実行され、デプロイされる 1 秒ごとに容量に対して継続的に支払います。たとえば、BigQuery スロットを 2,000 購入した場合、集計したクエリはいつでも 2,000 仮想 CPU のみに制限されます。この容量はそれを解除するまで保持され、集計したクエリを削除するまで 2,000 スロットに対して支払います。
オンデマンド料金モデルのプロジェクトには、一時的なバースト容量を備えたプロジェクトごとのスロットの割り当てが適用されます。オンデマンド モデルを使用するほとんどのユーザーにとって、デフォルトで割り当てられるスロットの容量は十分です。ワークロードによっては、より多くのスロットにアクセスできるようにすることでクエリ パフォーマンスが向上します。アカウントで使用しているスロットの数を確認するには、BigQuery のモニタリングをご覧ください。
⇒ 要するに CPU スロットのこと。あらかじめ決まったスロットの上限内で CPU リソースを使って、クエリが実行される
多くのスロットを予約すると、BigQuery スロットの可用性は確保されますがパフォーマンスは向上しません。
⇒ スロット増やしてもパフォーマンス上がるわけではない!
定額制
- 一定数のスロットがお客様のプロジェクトに割り当てられ、プロジェクト間で階層的な優先順位モデルを確立する。
- 定額制は、複数の事業部門があり、優先順位や予算が異なるワークロードを抱える大企業に特に適している。
BigQuery のカスタム割り当て
- BigQuery プロジェクトとユーザーが複数ある場合は、1 日あたりに処理されるクエリデータの量に上限を指定するカスタム割り当てをリクエストして、コストを管理できます。
BigQuery のマテリアライズドビューは頻繁に更新される小さなデータセットに向いている
- マテリアライズド ビューは、パフォーマンスを向上させるためにクエリの結果を定期的にキャッシュ保存します。マテリアライズド ビューは、頻繁にクエリされる小さなデータセットに適しています。基盤となるテーブルデータが変更されると、影響を受ける部分をマテリアライズド ビューが無効化して再度読み込みます。
⇒ 自動で、対象の箇所だけ更新される!
BigQuery では GeoJson 形式をサポートしている
- インタラクティブな可視化も簡単。地理空間分析では、地理データ型と標準の SQL 地理関数を使用して、BigQuery で地理空間データを分析し、可視化できます。
BigTable
- NoSQL
- key-value
- リアルタイムだが、SQL クエリは実行できない
- 低レイテンシでスケーラブル
- GoogleMap, Gmail, IoT..etc
- Goolgle のコアサービスを支える大規模分散データベース
- 並列処理が求められる大規模データが得意
- ACID トランザクションのサポートが不要な場合、またはデータが高度に構造化されていない場合は、Cloud Bigtable を検討。
主キーを選択する上で重要な点は、ホットスポットを回避するという点
- 単調増加する値やエポックタイムなどは、ホットスポットを発生させる可能性があるため不適切。 代わりに、キーのハッシュ値や UUID などのランダムな値を用いることは、ベストプラクティス。
⇒ Bigtable などでも、ホットスポットは処理を集中させ、パフォーマンス低下させるらしい。分散処理なので、多くのノードを効率よく使わないといけないのだろう。なので、処理する行はテーブル全体に分散していた方がいい。
Bigtable で最高の書き込みパフォーマンスを実現するには、書き込み操作をノード間でできる限り均等に分散させることが重要です。この目標を達成する方法として、予測可能な順番に従わない行キーを使用する方法があります。また、関連する行をグループ化して、近くにまとまるようにすると便利です。これにより、複数の行を同時に読み取る処理が効率的になります。たとえば、時間の経過に伴いさまざまな種類の天気情報データを格納する場合、データを収集した場所とタイムスタンプを連結したものを行キーとして使用できます(例: WashingtonDC#201803061617)
⇒ つまり、似たものを近くにして凝集度は高くする一方で、あまり関係ないものがホットスポットを作らないように分散させるようなキーを設計する。
Bigtable のアーキテクチャ
- ストレージ モデル テーブルは Key-Value マップ
- 各行は単一の行キーでインデックスに登録
- 関連する列は通常、列ファミリーとしてグループ化される
- 各列は列ファミリーと列修飾子(特定の列ファミリー内で一意の名前)の組み合わせによって識別される
- column family
Bigtable ではテーブルに対してまずカラムファミリーを作成し、そのカラムファミリーにカラム(キー)と値を入力する、という順番で操作を行います。 cbt では、データの読み出しを行う read コマンドに指定できるのは、 row の prefix と start 、 end 取得するデータの数である count くらいで、複雑なクエリを投げることはできません。集計処理といった複雑なデータ処理を行う際は、 API を使うか、 Cloud Dataproc を利用することになります
- column family
- 行と列が交差する場所に複数のセルを含めることができ、タイムスタンプ付きの一意のバージョンが格納される。
- 複数のセルを列に格納すると、その行と列に対して保存されたデータの経時変化を記録できる
- Bigtable テーブルはスパース。つまり、特定の行で使用されていない列が領域を消費することはない
Bigtable テーブルは連続する行ブロック(タブレット)として共有され、クエリの負荷分散を実現します(タブレットは HBase リージョンに相当します)。タブレットは、Google のファイル システムである Colossus に SSTable 形式で格納されます。 重要なことは、データは Bigtable ノード自体に格納されるのではないという点です。各ノードはタブレットのセット(Colossus に格納されている)に対するポインタを保持しています。これにより、以下が実現されます。
- ノード間のタブレット移動(再調整)が高速になります(実際のデータはコピーされないため)。Bigtable は、各ノードのポインタを更新するだけです。
- Bigtable ノードの障害復旧が極めて高速に実行されます。これは、置換先の新しいノードにメタデータのみを移動すれば済むためです。 Bigtable ノードで障害が発生してもデータが失われることはありません。
BigTable の負荷分散
- 各 Bigtable ゾーンはプライマリ プロセスによって管理され、アクセス数の多い大容量のタブレットを半分に分割し、アクセス数の少ない小さなタブレットを結合して、それらのタブレットを必要に応じてノード間で再配置します。Bigtable は分割、結合、再配置を自動的に管理するため、タブレットを手動で管理する手間が省けます。
- クラスタに保存されるデータ量が増加すると、Bigtable はクラスタ内のすべてのノードにデータを分散してストレージを最適化。データを継続的に保存し続けるためには、使用率が増大していることはいち早く検知する必要がある。
⇒ Bigtable の場合、データ使用率の増大がパファーマンス低下を招く!
BigTable のレプリケーション
- クラスターの追加 Cloud Bigtable のレプリケーションにより、データを複数のリージョンまたは同じリージョン内の複数のゾーンにコピーすると、データの可用性と耐久性を向上できます。さらに、異なるタイプのリクエストを異なるクラスタにルーティングすることで、ワークロードを分離できます。Bigtable インスタンスでレプリケーションを使用するには、複数のクラスタを持つ新しいインスタンス作成するか、既存のインスタンスに複数のクラスタを追加します。複数のクラスタを持つインスタンスを作成すると、Bigtable はすぐにクラスタ間でデータの同期を開始し、インスタンスにクラスタが含まれる各ゾーンに個別の独立したデータのコピーを作成します。同様に、既存のインスタンスに新しいクラスタを追加すると、Bigtable は既存のデータを元のクラスタのゾーンから新しいクラスタのゾーンにコピーし、ゾーン間でデータへの変更を同期します。 レプリケーションでは、単一クラスタ ルーティングのアプリ プロファイルを使用してバッチ分析ジョブとアプリケーション トラフィックを異なるクラスタにルーティングできるため、バッチジョブがアプリケーションのユーザーに影響を与えることはありません。
⇒ バッチジョブによるパフォーマンス低下を防止。結果整合性ではあるが、ほぼリアルタイムのバックアップが、リージョナルあるいはグローバルでも作られて、可用性が増す - クラスターではなく、ノードの追加の場合 Bigtable では、クラスタにノードを追加することで、スループットを高めることができます。
⇒ ノードはデータの実体へのポインタをもち、データを振り分ける負荷分散機能をもつプロキシサーバみたいなもの
CloudSQL
- SQL を完全にサポートするオンライン トランザクション処理(OLTP)システム向けのリレーショナル データベースが必要な場合は、Cloud SQL を検討。
OLAP キューブ (⇔ OLTP)
- データの多次元配列。Online Analytical Processing(OLAP)は、洞察のためにデータを分析するコンピューターベースの手法。
- キューブとは、多次元データセットを指し、次元数が 3 より大きい場合、ハイパーキューブとも呼ばれる。
- OLAP 用の DB の代表が BigQuery、OLTP の DB が CloudSQL。※ AlloyDB for PostgreSQL はどっちも狙っている。
- Max30TB
- 自動スケールアップ ※スケールアウトではない!
- リージョナル ⇔ Spanner はグローバル
- Cloud SQL のオプションはリージョナルで、Cloud Spanner に比べてスケーラビリティが小さい。
- Cloud SQL は確約利用割引(CUD)が使える。
- 特定のリージョンで、データベース インスタンスの 1 年間または 3 年間にわたる継続的な使用の確約と引き換えに適用される、大幅な割引料金。
- HA 構成をとれる。HA 構成はクラスタとも呼ばれる。HA 構成の CloudSQL インスタンスは「リージョンインスタンス」といい、プライマリゾーンとセカンダリゾーンにプライマリインスタンスとスタンバイインスタンスとして配置される。ゾーン障害時にはフェイルオーバーされる。
CloudSQL の同期/非同期レプリケーション 、HA 構成とフェイルオーバ
- Cloud SQL インスタンスは高可用性(HA)構成をとることができる。
- HA 構成は「クラスタ」とも呼ばれ、データの冗長性を確保。HA 向けに構成された Cloud SQL インスタンスは「リージョン インスタンス」とも呼ばれ、構成されたリージョン内のプライマリ ゾーンとセカンダリ ゾーンに配置される。
- リージョン インスタンスはプライマリ インスタンス(プライマリゾーン)とスタンバイ インスタンス(セカンダリゾーン)で構成。各ゾーンの永続ディスクへ同期レプリケーション複製される。
高可用性のためにレプリケーションを使っているときに、マスタでデータを更新した直後にマスタがダウンしたとすると、そのトランザクションの commit データがスレーブに複製されておらず、データ更新自体が失われてしまうこともあるかもしれません。
非同期レプリケーションでは、マスタの更新内容は速やかにスレーブに反映されますが、タイミングによってはマスタとスレーブでデータの内容が異なりますし、また、マスタがデータ更新の直後にダウンすると、データ更新が失われる可能性もあります。
一方で、同期レプリケーションでは、スレーブにデータ更新が反映されるのをマスタが待つので、更新性能がややダウンすることになりますが、マスタとスレーブのデータの内容は常に同じになりますし、マスタがダウンしてもデータ更新が失われることはありません。 - インスタンスまたはゾーンで障害が発生した場合、永続ディスクはスタンバイ インスタンスにアタッチされ、新しいプライマリ インスタンスになります。ユーザーは新しいプライマリに再転送されます。このプロセスは、フェイルオーバーと呼ばれます。
Cloud SQL Auth Proxy
- Cloud SQL Auth Proxy では、Identity and Access Management(IAM)権限を使用して接続を承認し、保護できます。Cloud SQL Auth Proxy は、ユーザーまたはサービス アカウントの認証情報を使用して接続を検証し、Cloud SQL インスタンスに対して承認された SSL / TLS レイヤに接続をラップします。(Google 推奨)
- Cloud SQL Auth Proxy バイナリは、コマンドラインで指定された 1 つ以上の Cloud SQL インスタンスに接続し、TCP または Unix ソケットとしてローカル接続をオープンします。アプリケーション コードやデータベース管理クライアント ツールなど、他のアプリケーションやサービスは、これらの TCP または Unix ソケットの接続を介して Cloud SQL インスタンスに接続できます。
⇒ Identity Aware Proxy(IAP) の一種
DataStore
- DataStore モードの FireStore(将来的に統合)
- NoSQL に分類されるが、SQL が使える。
- 高可用性が求められる大規模な構造化データが得意
- ACID トランザクション
- インデックスも使える
- 最大の特徴は、アプリケーション負荷に応じてシームレスに自動スケーリングする
⇒ スケールアウト!トランザクションが必要で、かつユーザーが増えそうなアプリとか
⇔ CloudSQL はスケールアップのみ! - シャーディング(データの複数サーバへの分散)、レプリケーション(複数サーバでのコピー)も自動
- 強整合性と結果整合性のバランス
Cloud Spannar はリレーショナル!グローバルスケールで、インターリーブによるパフォーマンス向上をサポート
- リレーショナル データベースでは、非正規化は好ましい手法ではない。繰り返しデータにより複数の行が発生するため。
- Cloud Spanner ではインターリーブと呼ばれる、あるテーブルのレコードの物理的な配置を別のテーブルのレコードの配下に置ける仕組みがあります。この仕組みを使ってテーブル間に親子関係を作ることで、複数のテーブル間に参照整合性制約を持たせたり、パフォーマンスを向上させることができます。
- Cloud Spanner では SELECT AS STRUCT 構文をサブクエリに使うことで、親のテーブルとインターリーブされたテーブルのレコードを一発で高速に取得することができます。更に Cloud Spanner の CPU 使用率も抑えることができるので非常に効率的にクエリできます。
- Cloud Spanner は、リレーショナル データをサポートする、グローバル スケールで高可用性のデータベースを提供します。
⇔ Cloud SQL のオプションはリージョナルで、Cloud Spanner に比べてスケーラビリティが小さい。 ※BigQuery もグローバルスケールではない。
CloudStorage
-
大容量の画像やムービーなど、大規模な不変 blob を格納する必要がある場合は、Cloud Storage を検討。
-
GCS の IAM パーミッションはどのレベルまで?
bucket level まで。オブジェクト毎には設定できないらしい。
→ 細かいアクセス制御には ACL を使う。が、推奨はされない。

-
GCS のストレージクラスのオプションと、最小保存期間を挙げよ。
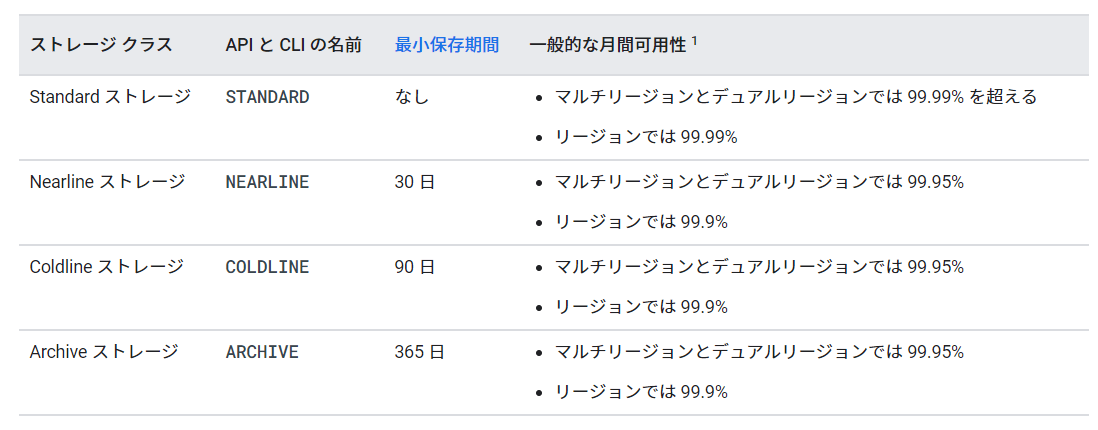
Summary:
Cloud Storage lets you use storage classes that are less expensive than standard storage. These storage classes use low-performance HDDs compared to standard SDDs. The cost-performance trade-off lets you build low-cost, resilient applications that still have the fastest read access and lowest latency in the cloud space. Cloud Storage object lifecycle rules let you change storage classes or set expiration rules to further reduce storage costs.
Transfer Appliance
- 大容量のストレージ デバイス
- 大容量データのクラウド移行で、アウトバウンドネットワーク帯域が少ない場合
- 小さいデータの場合、gsutil cp
Storage Transfer Service
- 他クラウド(S3 とか)、オンプレ、etc から GCS への転送サービス
gsutil vs Storage Transfer Service
- 別クラウドの時: Storage Transfer Service
- <1TB on-pre: gsutil
- 1TB on-pre: Transfer Service for on-premises data
- 大きいデータや、クラウドを跨ぐ転送の場合、Storage Transfer Service
- 好みの言語で Storage Transfer API やクライアント ライブラリを使用して、転送ジョブの作成と管理を自動化できる。gsutil と比較すると、Storage Transfer Service は再試行を処理し、詳細な転送ロギングを提供するマネージド ソリューション
DataPrep / DataProp / DataFlow / CloudComposer
- DataPrep は探索的なデータ探索、加工、ロードを可能にするデータプレパレーションサービス。GUI 操作でデータクレンジングを直観的に行う。処理エンジンには DataFlow、Python、BigQuery が利用される。
- DataProc はマネージド Hadoop/Spark クラスタ
- DataFusion は GUI 操作できるデータ統合プラットフォームサービス。 DataProc クラスタが一時的リソースとして立ち上がり、ジョブが終了すると削除される。
- DataFlow は ApacheBeam をベースにしたストリーム/バッチの分散データ処理パイプラインのマネージド版。オートスケール対応で重い処理や複雑な処理に向いている
- PCollection
- パイプライン データとして機能する複数要素のデータセット
- Transform
- 1 つ以上の PCollection を入力として受け取り、そのコレクションの各要素に対して指定したオペレーション(=ParDo)を実行して、1 つ以上の PCollection を出力
- ParDo - 入力 PCollection の [各要素] に対してユーザー指定の関数を呼び出し、0 個以上の出力要素を 1 つの出力 PCollection に収集
- Apache Beam SDK のコア並列処理オペレーション
※Spark 同様、分散ストリーム処理エンジンだが、Beam は 2016 年で、Spark の 2014 年より後発。Google Cloud Dataflow のモデルを OSS 化したもの。ストリーム処理とバッチ処理の両モードに対応する。バックエンドとして、Flink、Spark、Google Cloud Dataflow を利用できる。Google が、ストリーム処理エンジンの統合を狙ったものを考えられる。
- Apache Beam SDK のコア並列処理オペレーション
- PCollection
Dataflow ジョブは、二つの方法で停止可能
- ジョブをキャンセルする:ストリーミング パイプラインとバッチ パイプラインの両方に適用される。ジョブをキャンセルすると、Dataflow サービスはバッファデータなどのデータの処理を停止。
- ジョブをドレインする:ストリーミング パイプラインにのみ適用される。ジョブをドレインすると、Dataflow サービスはバッファ内のデータの処理を完了すると同時に、新しいデータの取り込みを中止できる。
⇒ DataProc の高度な柔軟性モード(EFM)と似ている
ウォーターマーク/トリガー/非グローバルウィンドウ
- ウォーターマーク
- ウィンドウにつけるタイムスタンプを基にした目印
- データの遅延などを見つける
- パイプラインに到着したとシステムが見なすタイミングのこと
- ウォーターマークを超えて到着したデータは遅延データとして扱われる
- Dataflow は最適なウォータマークを学習
- トリガー
- データが到着したときに集計結果をいつ出力するかを決定する デフォルトでは、ウォーターマークを基に決定される
- 非グローバルウィンドウ
- Beam’s default windowing behavior is to assign all elements of a PCollection to a single, global window and discard late data, even for unbounded PCollections.
⇒ デフォルトでグローバルウィンドウなので、Pcollection が無制限(=window によって区切られていない、ストリーミングデータなど)の場合、デフォルトでは無限にデータの到着を待ち続ける!!そこで非グローバルウィンドウの設計が必須になる。
※グローバルウィンドウ+非デフォルトトリガーを設定することで、永遠に待ち続ける前に、グローバルウィンドウから後続処理にデータを emit させることもできる
- Beam’s default windowing behavior is to assign all elements of a PCollection to a single, global window and discard late data, even for unbounded PCollections.
Dataproc
- プリエンプティブル VM Dataproc クラスタは、標準的な Compute Engine VM を Dataproc ワーカー(「プライマリ」ワーカーと呼ぶ)として使用するだけでなく、「セカンダリ」ワーカーも使用できる。プリエンプティブル VM(セカンダリワーカーのデフォルト) は、通常のインスタンスよりはるかに低価格で作成、実行できるインスタンス。ただし、他のタスクがリソースへのアクセスを必要とする場合、Compute Engine がこのインスタンスを停止(プリエンプト)する可能性がある。プリエンプティブル インスタンスは Compute Engine の余剰のキャパシティを利用する機能であり、使用できるかどうかは利用状況に応じて異なる。
- Dataproc はストレージに Hadoop 分散ファイル システム(HDFS)を使用する また、HDFS 互換の Cloud Storage コネクタが自動的にインストールされるため、HDFS と並行して Cloud Storage も使用できる。 クラスタに対してデータの移動を行うには、HDFS や Cloud Storage へのアップロードとダウンロードを使用する。
⇒ ホットデータは HDFS に残して、、とかでなく、すべて CloudStorage に移すとコスト低い。Dataproc と GCS を Google Cloud Storage のコネクタで接続すると、クラスタの寿命が来た後もデータを保存することができる! - 水平スケーリング
- Dataproc のようなバッチの場合は、コンピューティングリソースが時間課金という特性を活かして、水平スケーリングを積極的に活用するべき
- サイドインプットパターン
- Apache Beam では、データ分析のためのエンリッチメントを行う際には、「サイドインプットパターン」が推奨されている
- 高度な柔軟性モード(EFM)
- スケールダウンやプリエンプションのためにワーカーノードを削除すると、ノードに保存されているシャッフル(中間データ)が失われる可能性がある。 プリエンプティブル VM を使用したり、自動スケーリングの安定性を改善したい場合は、高度な柔軟性モードを有効にすることが推奨される。
⇒ DataFlow のドレインと似ている
- スケールダウンやプリエンプションのためにワーカーノードを削除すると、ノードに保存されているシャッフル(中間データ)が失われる可能性がある。 プリエンプティブル VM を使用したり、自動スケーリングの安定性を改善したい場合は、高度な柔軟性モードを有効にすることが推奨される。
HBase
- HBase は、大量データに対応した分散ストレージシステム。Cassandra、Redis、MongoDB などと同じで、NoSQL データベース
- オープンソースの、列指向、分散データベースであり、Google の BigTable をモデルとし、Java により書かれている。
- HBase は、Google の BigTable に似た NoSQL データモデルで、膨大な量の構造化データへの迅速なランダムアクセスを実現するために設計されました。
- Hadoop File System (HDFS)が提供するフォールトトレランスを利用しています。
- データ消費者は、HBase を使用して HDFS のデータをランダムに読み取り、アクセスする。HBase は Hadoop File System の上に置かれ、読み取りと書き込みのアクセスを提供する。
Apache casandra
- Cassandra は 2007 年 Facebook 社のエンジニアによって開発されました。
- その後 Apache Software Foundation のプロジェクトとなり、成長を続け 2017 年 2 月にバージョン 3.10 がリリースされました。
- NoSQL というと、少し取りつきにくいイメージもありますが、Cassandra は テーブルにデータを格納し CQL という SQL のようなクエリ言語を利用してデータのやりとりをすることができるため、直観的にはリレーショナル DB を使っているかのように操作ができます。
- Cassandra は、複数台でクラスターを組んで分散 DB を作成し、スケールアウトすることが容易にできる構造になっています。また処理性能も構成するノード数に比例します。そのためサーバー管理者としては、比較的安価にスケーラビリティを確保できます。
Pig と Hive は、共に SQL ライクな記法で MapReduce を書ける DSL である
- Pig: 手軽に使えて複雑な処理も可能であり柔軟性が高い、パフォーマンスは低め
- Hive: SQL ライクな文法が使用可能で Pig よりパフォーマンスが高
どちらも、裏側では MapReduce(大量のデータを高速に処理するための分散処理フレームワーク)の処理が実行されます。
MapReduce/YARN/Tez は Hadoop 内のアルゴリズム
- YARN は MR より明らかに優れる。Tez は YARN における並列処理エンジンについて、MR の代わりを目指している
強整合性と結果整合性
- 強整合性 の場合、データの更新の際にデータベースをロックすることによってデータの一貫性(Consistency)を担保するが、ロックされる期間が長いほどその間のデータベース・アクセスがブロックされ、可用性(Availability)を犠牲にすることになる
- 結果整合性 はデータの更新でデータベースがロックされることはないため、可用性とスケーラビリティを維持することができる。その代わりノード間でのデータの一貫性は必ずしも担保されない
Pub/Sub の配信モデル
- at-least once 配信モデルなので、メッセージ重複を考慮する必要がある。サブスクライバーとなるアプリケーションでは冪等性が保証される設計・実装を行う必要がある。exactly once 配信モデルは CloudDataFlow などを利用して重複排除の仕組みを実装することで実現可能。
- 順序制御は順序指定オプションを有効化
- テッドレタートピックを設定すると、正しく配信できずにリトライ上限に達したメッセージをデッドレタートピックに転送できる
pub/sub のメッセージ確認応答
- 確認応答期限が切れる前にメッセージの確認応答を行わないと、Pub/Sub によってメッセージが再送信される。その結果、Pub/Sub によって重複するメッセージが送信されることがある。 Google Cloud のオペレーション スイートを使用して、expired レスポンス コードで確認応答オペレーションをモニタリングし、この状態を検出する。
RPC は同期呼び出し
- Pub/sub はそれを分離する。非同期呼び出し(Pull 型の場合)
DataLossPrevention(DLP)
- Cloud DLP は、Cloud Storage、BigQuery、Cloud Datastore の機密データのスキャンと分類をネイティブにサポートし、ストリーミングコンテンツ API により、追加のデータソース、カスタムワークロード、アプリケーションへ適用可能。データセキュリティとプライバシーのレイヤーを追加してデータワークロードに組み込むことにより、機密データを保護することができる。また、Cloud Storage や BigQuery などのストレージリポジトリにあるデータの大規模な検査、発見、分類のためのネイティブサービスも提供。
Cloud Monitoring では、ネットワーク接続、ディスク ID、レプリケーションの状態などのカスタムメトリクスはデフォルトで収集することができない
従って、オーバーヘッドの少ない方法で、VM からカスタムメトリクスを収集するためのツールをインストールする必要がある。 Google Cloud では、OpenCensus を使ったカスタムメトリクスの収集が推奨されている。 OpenCensus は OSS で、次のことが可能。
-
メトリクスおよびトレースデータをさまざまな言語で収集するための、ベンダーに依存しないサポートを提供できます。
-
収集したデータを、Cloud Monitoring を含むさまざまなバックエンド アプリケーションにエクスポートできます。
-
Cloud Logging では、Google Cloud 以外のシステムからもログや指標のデータを収集できる。
Google が提供する Cloud Monitoring エージェントは、AWS EC2 インスタンスにインストール可能。また、オンプレミスのマシンに fluentd や collectd エージェントをインストールして、Cloud Monitoring サービスにデータを書き込める。
Logging Agent や Monitoring Agent を GCE の linux/windows インスタンスにインストールすると、それは fluentd ベースのツールで、勝手に Logging や monitoring のサービスにログやメトリクスを送信して収集してくれる!GCP じゃなくても AWS とかオンプレでもいい!
- Cloud Logging の出し方
アプリから API を叩いてログに入れる。_Default バケットにルーティングされるようなシンクになっていて、30 日間保存される。pubsub や BigQuery、GCS へのカスタムシンクを作れば制限はなくなる。
- Cloud Logging の出し方
Cloud Logging の _Required バケットは、管理アクティビティ監査ログとシステム イベント監査ログを取り込んで保存します。_Required バケットやバケット内のログデータは構成できません。 _Default バケットは、デフォルトで有効なデータアクセス監査ログとポリシー拒否監査ログを取り込んで保存します。データアクセス監査ログが _Default バケットに保存されないようにするには、ログを無効にします。ポリシー拒否監査ログが _Default バケットに保存されないようにするには、シンクのフィルタを変更してポリシー拒否監査ログを除外します。
- 集約されたシンクを使用する方法は?
集約されたシンクを使用するには、Google Cloud の組織またはフォルダーにシンクを作成し、シンクのincludeChildren パラメータを True に設定します。そのシンクは、組織またはフォルダーからのログエントリに加えて、含まれているフォルダー、請求先アカウント、またはクラウドプロジェクトからのログエントリを(再帰的に)ルーティングできます。
⇒ ログをほぼリアルタイムで外部 SIEM にエクスポート- SIEM
Security Information and Event Management
数秒で大量のデータを取り込んで解析し、異常な行動を検出するとただちにアラートを送信する機能により、ユーザーはビジネスを保護するためのインサイトをリアルタイムで得ることができる。
- SIEM
Cloud Trace
- Cloud Trace は分散トレース システムであり、アプリケーションからレイテンシ データを収集し、Google Cloud Console に表示
AutoML は転移学習できるのが強み
- データ量が比較的少なく多様な場合、構築されたモデルの精度は低くなる。AutoML は他の類似データに基づく転移学習を使用するため、適切な選択。
Discussion