Cloud Run GPU + Ollama gemma2 のパフォーマンスを図ってみる
概要
Google Cloud 上で申請することで、Cloud Run GPU が使えるようになったので実行してみます。 申請フォーム
Google Cloud では以下のように、サンプルが載っているので一旦それの通りの沿って、Gemma2 を起動するアプリケーションを作成します。
とはいえ、それだけだとそのままのドキュメントとの差がないので、パフォーマンステストについても行い、どれぐらいの実行速度が出るのかなどの計測までやりたいと思います。
結論
- instance 7台でやっていって response time P95 45s, 6 RPS あたりが妥当
- 当たり前ですが、Gemini の代わりみたいな速度は無理
- gemma2 以外のもっと軽量なものを使ったほうが、実サービスには乗せやすそう
- 毎秒アクセスされるようなものであれば、金銭コスト的には安くすむかもしれない
Cloud Run で GPU が使えるメリット
まず1つ GPU を使う compute リソースには現状 GCE、GKE がありますが、それらに比べて圧倒的に管理が楽というのがあると思います。
インスタンスを常に起動しない場合であれば GKE のスケーリングを行う様にしますが、コントロールプレーンなどを管理することになってしまいます。
Cloud Run(Service) で GPU タスクを作れるば、簡単に、機械学習の推論や Local LLM を扱うこともできます。
ちなみに、Cloud Run Job では現状使えませんが、そもそも、Batch があるので私としては直近必要はないかと思います。
注意点ですが GPU を使う場合 CPU は常に割当をしなければいけません。
そのため、通常の Cloud Run と比べ、アクセス時にコストがかかるのではなく、インスタンスが起動している間コストがかかるので、少し計算が異なるのだけ気をつける必要があります。
アプリケーション作成
Project IDX で設定します。
IDX 上で Docker を使うため、また Google Cloud の Project 設定のために .idx/dev.nix を設定します。
{ pkgs, ... }: {
channel = "stable-23.11"; # or "unstable"
packages = [
pkgs.docker
];
env = {
REPOSITORY="us-central1-docker.pkg.dev/****/gemma2-app";
APP_NAME="app";
GOOGLE_PROJECT="****";
};
services = {
docker = {
enable = true;
};
};
}
Google Cloud 側の設定
ドキュメントに沿って Artifact Registory のレポジトリを作成します。
Cloud Run で GPU を使うためには、us-central1 でないといけないので、Artifact Registory もそちらに配置します。
$ gcloud artifacts repositories create $REPOSITORY \
--repository-format=docker \
--location=us-central1
--project=$GOOGLE_PROJECT
Docker Image の設定
ドキュメントには以下のようになっております。
Cloud Run では、リクエストのレイテンシを最小限に抑えるため、コンテナ インスタンスの高速起動が重要です。コンテナ インスタンスの起動に時間がかかると、サービスが 0 から 1 インスタンスにスケーリングする時間もかかります。また、トラフィックの急増時のスケールアウトにもさらに時間がかかります。
起動を高速化するには、モデルファイルをコンテナ イメージ自体に保存します。これは、起動時にリモートからファイルをダウンロードする場合よりも高速で、信頼性が高い方法です。Cloud Run の内部コンテナ イメージ ストレージは、トラフィックの急増に対応するように最適化されています。インスタンスの起動時にコンテナのファイル システムをすばやくセットアップできます。
ということで、Image に weight を入れている想定です。
そのため、Ollama を使って LLM を serve するということなので、それを設定していきます。
ちなみに、weight をどこに入れたほうが良いかについては以下にまとまっております。
FROM ollama/ollama:0.3.6
# Listen on all interfaces, port 8080
ENV OLLAMA_HOST 0.0.0.0:8080
# Store model weight files in /models
ENV OLLAMA_MODELS /models
# Reduce logging verbosity
ENV OLLAMA_DEBUG false
# Never unload model weights from the GPU
ENV OLLAMA_KEEP_ALIVE -1
# Store the model weights in the container image
ENV MODEL gemma2:9b
RUN ollama serve & sleep 5 && ollama pull $MODEL
# Start Ollama
ENTRYPOINT ["ollama", "serve"]
次に、Build と Push をしていきます。
$ docker build -t $REPOSITORY/$APP_NAME .
$ gcloud auth configure-docker us-central1-docker.pkg.dev
$ docker push $REPOSITORY/$APP_NAME;
アプリケーションの deploy に使う gcloud command は以下になります。
私の方で申請して利用できる GPU の最大数が 7 だったので max-instances は 7 にします。
$ gcloud beta run deploy $SERVICE_NAME \
--image $REPOSITORY/$APP_NAME \
--concurrency 4 \
--cpu 8 \
--set-env-vars OLLAMA_NUM_PARALLEL=4 \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 7 \
--memory 32Gi \
--no-allow-unauthenticated \
--no-cpu-throttling \
--timeout=600 \
--region=us-central1 \
--project=$GOOGLE_PROJECT
しかし gcloud beta run での gpu、gpu-type のコマンドは idx では、まだ使えません。
ERROR: (gcloud.beta.run.deploy) unrecognized arguments:
--gpu (did you mean '--cpu'?)
1
--gpu-type (did you mean '--log-http'?)
nvidia-l4
To search the help text of gcloud commands, run:
gcloud help -- SEARCH_TERMS
idx の gcloud command のバージョンが 452.0.1 で gpu フラグが入ったのが 488.0.0 だからです。
$ gcloud -v
Google Cloud SDK 452.0.1
bq 2.0.98
bundled-python3-unix 3.9.17
core 2023.10.25
gcloud-crc32c 1.0.0
gsutil 5.27
となるとバージョンを上げる必要がありますが nix のパッケージにある google-cloud-sdk は unstable でも最高 485.0.0 までしか上がらないようです。
9月5日時点で API を確認しても GPUフラグがあるようには見えません。(API には GA のものしか乗らないっぽい?)
なので一回だけという認識で、gcloud cli を download します。
$ curl https://dl.google.com/dl/cloudsdk/channels/rapid/downloads/google-cloud-cli-490.0.0-linux-x86_64.tar.gz?hl=ja -O
$ tar -xvzf google-cloud-cli-490.0.0-linux-x86_64.tar.gz
$ ./google-cloud-sdk/install.sh
$ source ~/.bashrc
一応バージョンを確認すると問題なく利用できていると思われます。
$ gcloud version
Google Cloud SDK 490.0.0
bq 2.1.8
bundled-python3-unix 3.11.9
core 2024.08.23
gcloud-crc32c 1.0.0
gsutil 5.30
プロジェクト直下においているのでですが、他のワークスペースではコンテナとして別に起動することになるので、気にしなくても良いと思われます。
これで、先程のコマンドを叩いてみると、途中で beta の機能の download が走り、実行できます。
Service [ollama-gemma] revision [ollama-gemma-xxxxxxxx] has been deployed and is serving 100 percent of traffic.
Service URL: https://ollama-gemma-xxxxxx.us-central1.run.app
認証が必要な形で設定しているので、以下のようにして動作確認します。gcloud が異なるので、 gcloud auth login で再ログインすることは忘れず。
curl -X get -H "Authorization: Bearer $(gcloud auth print-identity-token)" https://ollama-gemma-xxxxxx.us-central1.run.app/api/generate -d '{
"model": "gemma2:9b",
"prompt": "Why is the sky blue?"
}'
または、proxy を設定してからアクセスします
$ gcloud run services proxy $SERVICE_NAME --port=9090 --region=us-central1 --project=$GOOGLE_PROJECT &
$ curl http://localhost:9090/api/generate -d '{
"model": "gemma2:9b",
"prompt": "Why is the sky blue?"
}'
{"model":"gemma2:9b","created_at":"2024-09-05T05:26:08.378316867Z","response":"The","done":false}
{"model":"gemma2:9b","created_at":"2024-09-05T05:26:08.40488024Z","response":" sky","done":false}
{"model":"gemma2:9b","created_at":"2024-09-05T05:26:08.435194834Z","response":" appears","done":false}
...
ログとして Cloud Run にて以下のように出力されています。
2024/09/05 05:08:24 routes.go:1125: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_HOST:http://0.0.0.0:8080 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE:2562047h47m16.854775807s OLLAMA_LLM_LIBRARY: OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:/models OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:4 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://*] OLLAMA_RUNNERS_DIR: OLLAMA_SCHED_SPREAD:false OLLAMA_TMPDIR: ROCR_VISIBLE_DEVICES:]"
time=2024-09-05T05:08:29.741Z level=INFO source=payload.go:44 msg="Dynamic LLM libraries [cpu cpu_avx cpu_avx2 cuda_v11 rocm_v60102]"
time=2024-09-05T05:08:29.741Z level=INFO source=gpu.go:204 msg="looking for compatible GPUs"
time=2024-09-05T05:08:30.254Z level=INFO source=types.go:105 msg="inference compute" id=GPU-5599506b-afaf-31ac-4e53-2f0db3c3d614 library=cuda compute=8.9 driver=12.2 name="NVIDIA L4" total="22.2 GiB" available="22.0 GiB"
ちなみに "stream": false をつけると stream なしでいけます。
curl http://localhost:9090/api/generate -d '{
"model": "gemma2:9b",
"prompt": "Google の LLM GEMINI について教えて下さい",
"stream": false
}'
{"model":"gemma2:9b","created_at":"2024-09-05T07:03:57.580842877Z","response":"GEMINI は Google が開発したオープンソースの大規模言語モデル(LLM)です。\n\n**特徴:**\n\n* **多用途性:** テキスト生成、翻訳、要約、質問応答など、様々なタスクに対応できます。\n* **軽量化:** 比較的小さいサイズのため、少ないリソースで動作することが可能であり、デバイス展開に適しています。\n* **オープンソース:** コードとモデルが公開されており、誰でも自由に利用・改変することができます。\n\n**用途例:**\n\n* **チャットボット:** 自然な会話ができるチャットボットの開発に使用できます。\n* **テキスト生成:** 記事、物語、詩などの文章作成に役立ちます。\n* **翻訳:** 異なる言語間での翻訳を支援します。\n* **教育:** 学習教材の作成や生徒への個別指導に活用できます。\n\n**注意点:**\n\n* GEMINI はまだ開発中であり、常に進化しています。そのため、使用時の挙動が予測できない場合があることを理解しておく必要があります。\n* 生成されたテキストは必ずしも正確・完全であるとは限らないため、信頼性を考慮して使用することが重要です。\n\n**詳細情報:**\n\n* Google AI Blog: [https://ai.googleblog.com/2023/07/introducing-gemini-our-open-and.html](https://ai.googleblog.com/2023/07/introducing-gemini-our-open-and.html)\n* GitHub リポジトリ: [https://github.com/google/gemnini](https://github.com/google/gemnini)\n\n\n\nGEMINI は、オープンソースの LLMs の発展に貢献する可能性を秘めたモデルです。今後さらに機能が充実し、様々な分野で活用されることが期待されます。","done":true,"done_reason":"stop","context":[106,1645,108,12583,1823,629,18622,106998,33299,96157,68383,37683,107,108,106,2516,108,78077,33299,10375,6238,9655,52606,2404,75188,66456,61562,94315,84644,40047,235538,1650,235296,235536,2297,235362,109,688,38914,66058,109,235287,5231,235626,84525,235753,66058,23622,235717,5622,40970,235394,134556,235394,235556,236517,235394,55237,236861,236661,9567,235394,73497,235569,19665,119402,25843,235362,108,235287,5231,118770,235816,66058,127312,25289,9812,24117,46052,235394,66732,235505,66456,235398,66187,52966,8900,55460,235394,172049,61212,235400,237148,22031,235362,108,235287,5231,75188,66456,66058,161077,235410,40047,235425,46424,163518,235394,222786,184822,18152,235537,236199,236436,139220,235362,109,688,84525,236155,66058,109,235287,5231,14488,4028,236033,4028,66058,96708,235414,99560,92385,14488,4028,236033,4028,235372,52606,222227,25843,235362,108,235287,5231,141972,40970,66058,35263,235394,67130,235394,238373,38493,23886,62370,235400,237136,41452,2286,235362,108,235287,5231,134556,66058,235248,106063,84644,235842,24436,134556,235432,55401,9178,235362,108,235287,5231,21615,66058,209881,138480,211435,235674,88784,27785,208037,79023,235400,73408,25843,235362,109,688,153936,66058,109,235287,106998,33299,10375,24148,52606,235493,55460,235394,99115,114060,22031,235362,117121,235394,7060,40391,239084,235915,235425,205560,43853,17180,16852,22563,29430,172351,126830,235362,108,235287,114188,17722,141972,235418,68255,144735,100991,235537,19873,16962,15592,236262,26011,12784,235394,119049,97037,99338,2603,7060,52966,17479,2297,235362,109,688,15681,17941,66058,109,235287,6238,16481,16204,235292,892,2468,1336,1515,235265,5996,10173,235265,872,235283,235284,235276,235284,235304,235283,235276,235324,235283,192478,235290,175608,235290,642,235290,4141,235290,639,235265,2527,13687,2468,1336,1515,235265,5996,10173,235265,872,235283,235284,235276,235284,235304,235283,235276,235324,235283,192478,235290,175608,235290,642,235290,4141,235290,639,235265,2527,235275,108,235287,47933,17024,115337,43143,235292,892,2468,1336,8384,235265,872,235283,5996,235283,541,11383,1904,13687,2468,1336,8384,235265,872,235283,5996,235283,541,11383,1904,235275,111,78077,33299,10375,235394,75188,66456,235372,25599,14816,1823,181071,235400,182256,3902,48922,235432,237331,38368,40047,2297,235362,82266,36942,35157,235425,107046,235399,235394,73497,144973,235398,73408,22750,13378,33590,51308,235362],"total_duration":12120238766,"load_duration":39895411,"prompt_eval_count":18,"prompt_eval_duration":31646000,"eval_count":377,"eval_duration":12006701000}
大体良さそうです。とはいえ URL は全く当てになりません。。。
パフォーマンステスト
テストは k6 でやってみます。
.idx/dev.nix に pkgs.k6 を追加します。
次に k6 ディレクトリを作成して、その中に script.js を配置し以下の内容で配置します。
import http from 'k6/http';
import { sleep } from 'k6';
export const options = {
vus: 10,
duration: '30s',
cloud: {
projectID: xxxx,
name: 'Ollama-gemma2'
}
};
export default function() {
http.post('https://ollama-gemma-xxxxxx.us-central1.run.app/api/generate', JSON.stringify({
"model": "gemma2:9b",
"prompt": "Google の LLM GEMINI について教えて下さい",
"stream": false
}), {
headers: {
"Content-Type": "application/json",
"Authorization": `Bearer ${__ENV.GOOGLE_CLOUD_ID_TOKEN}`
}
});
sleep(1);
}
proxy である localhost:9090 の場合 127.0.0.1 に対してはアクセスができないような旨のログがでてしまうため、
k6、実行してみます
k6 login cloud --token xxxxxxxxxxxxxxxxx
k6 cloud -e GOOGLE_CLOUD_ID_TOKEN=$(gcloud auth print-identity-token) ./k6/script.js
concurrency、OLLAMA_NUM_PARALLEL = 4
10 VUS


コンテナ数は 4つ程度立ち上がりました。

50 VUS
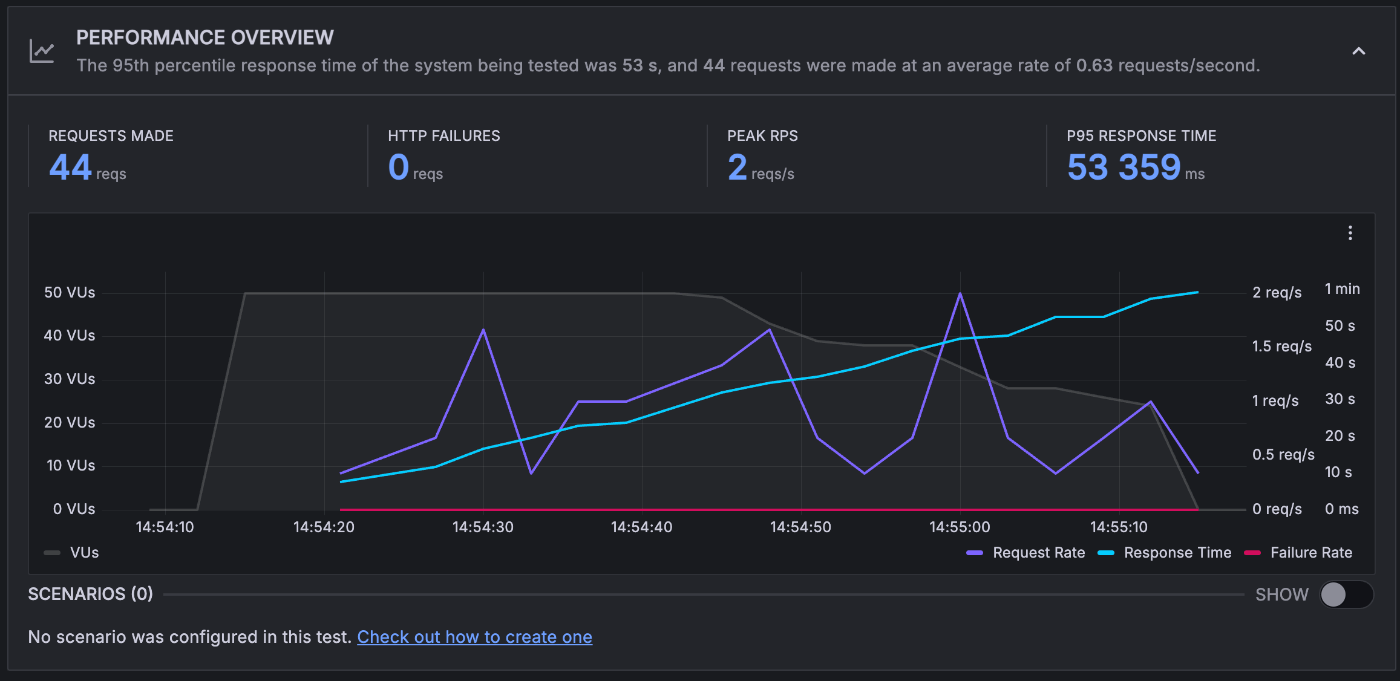
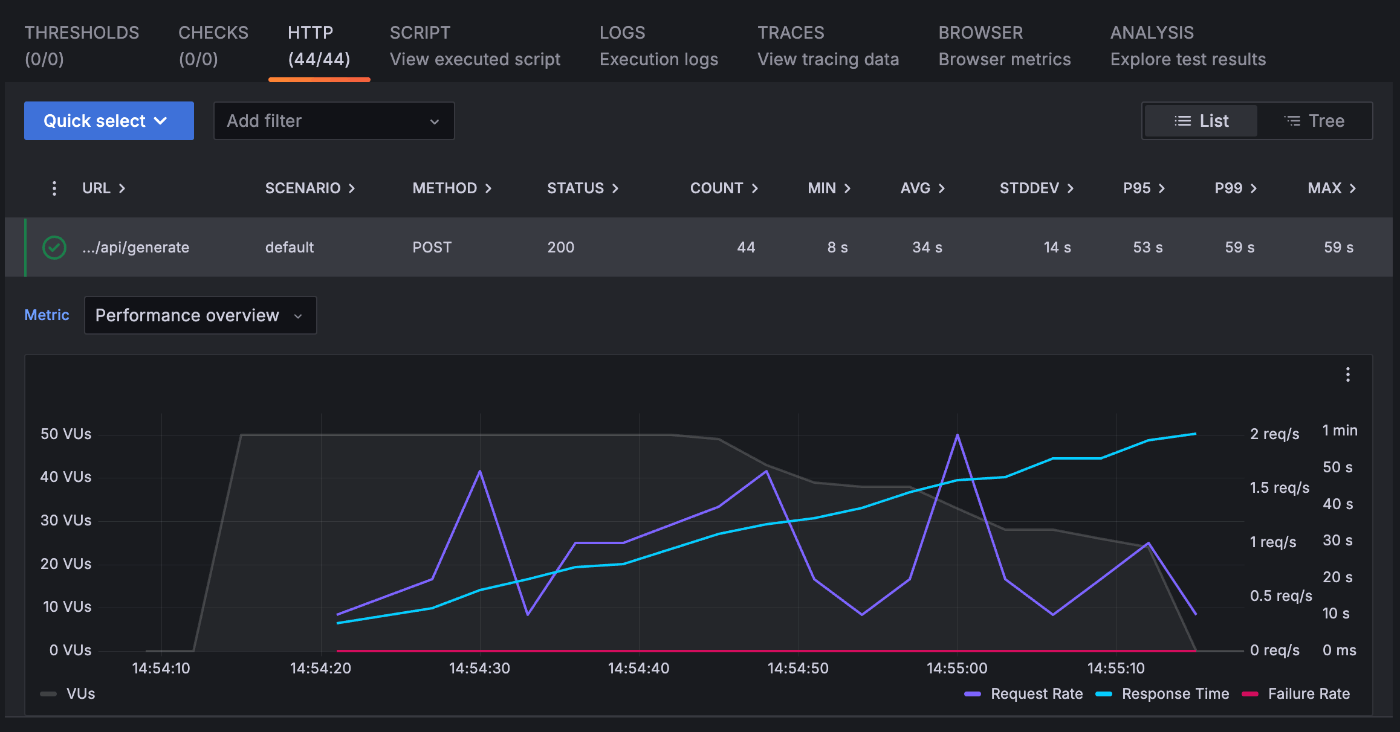
5インスタンス程度でさばけているようです。

concurrency、OLLAMA_NUM_PARALLEL = 10
10 VUS
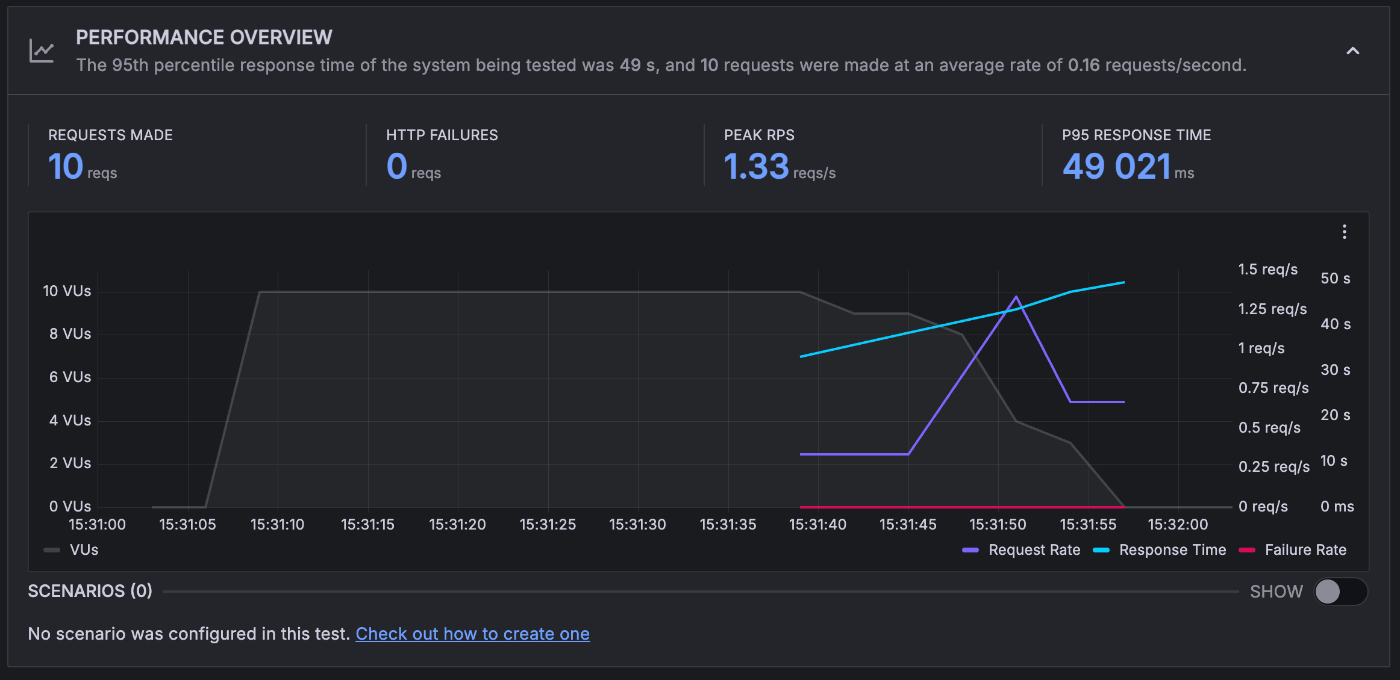

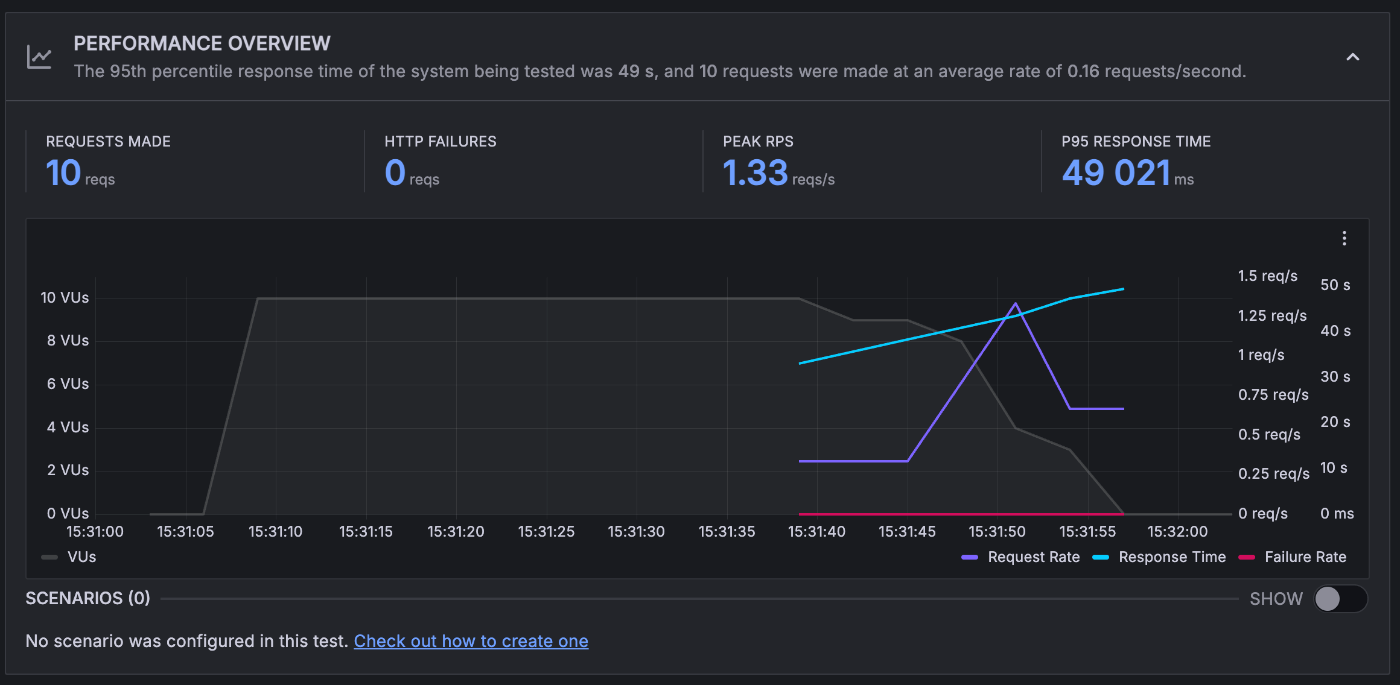
3 インスタンス程度でさばけているそうです

50 VUS
6 RPS 程度になっていますが、リクエストが失敗しています。
メッセージとしては The request was aborted because there was no available instance. Additional troubleshooting documentation can be found at: https://cloud.google.com/run/docs/troubleshooting#abort-request のようになっておりました。


同じ様に5~6インスタンス程度でさばけているようですが、それ以上はなさそうです。

max instance を超えていないようなので、インスタンス自体がリクエストを受け付けられていないと思われます。
仮説としては、1 インスタンスで 10 以上のリクエストを受け付けてしまっているのかと思います。
10 VUS / 100 iterations
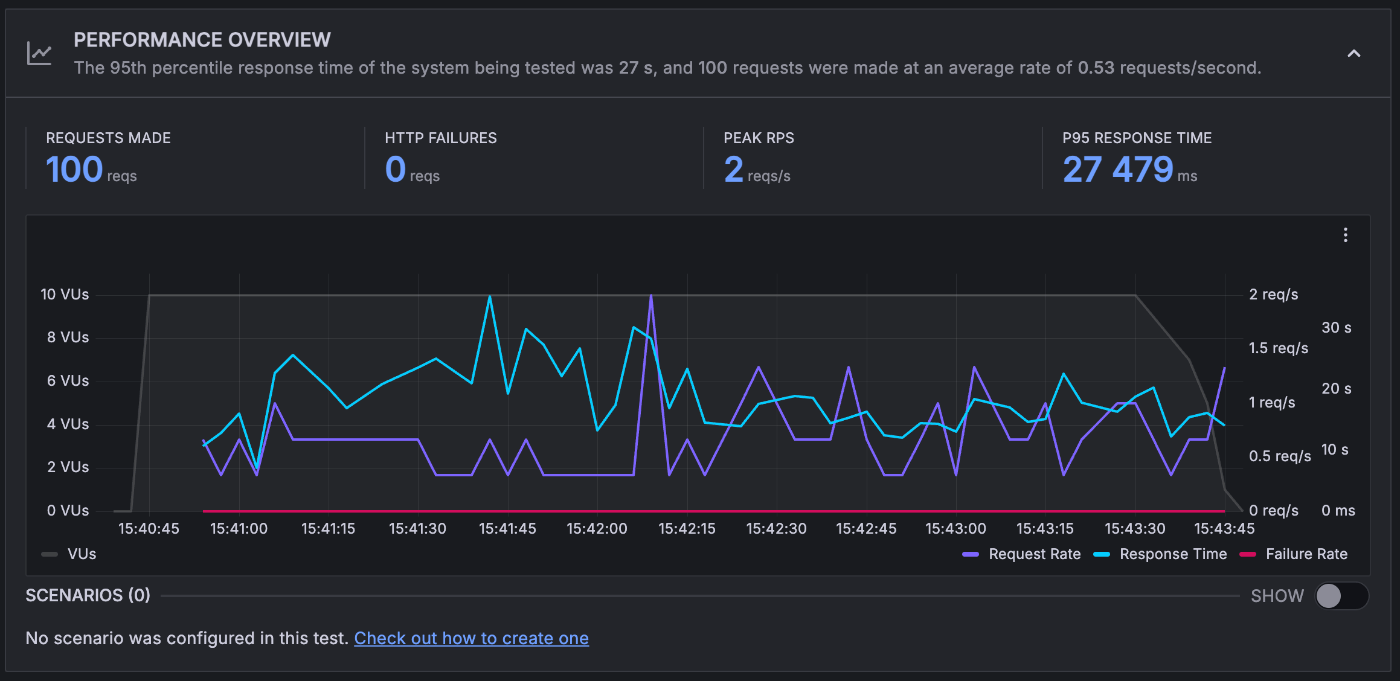

変わらず、3 インスタンス程度でさばけているそうです。

50 VUS / 500 iterations
5 RPS 程度になっていますが、先程の 50 VUS のパターンと同じエラーでリクエストが失敗しています。


7 インスタンスでさばいていました。

コンテナの起動時間 7s 程度、同時リクエストが P95 で 11 程度でした

リクエスト数からすると 1 インスタンスで 10 以上のリクエストを受け付けてしまっています。
CPU やメモリをみている限りは、まだ上限はありそうではありますが、CPU 数を考えると concurrency の値は 現状のvCPU の 8 より多くしてもあまり意味がないようです。
コスト
GPU コストは東京リージョンでは $0.000233 / GPU 秒 になっています。
8 vCPU と 32 GB メモリをあわせて、例えば 1 コンテナを 8 時間動かしたのであれば
($0.00001800 * 8 + 0.00000200 * 32 + $0.000233 * 1) * 8 * 60 * 60 = $12.70
となり、$1=150円 なら 1905.12 円になります。
比較として GPU は NVIDIA T4 を使うことになりますが GCE を使う場合は、878円程度になりそうです。
ちなみに T4 と L4 の違いは以下でまとまっていますが、L4 のほうがスコアリングが良さそうです。
改善案
Cloud Run の GCS の volume mount を利用し、モデルをマウントすると Image サイズを下げられます。
これにより Artifact Registory のコストを下げるなどが可能かと思います。また、image の pull 速度を上げることもできるかとは思います。
まとめ
現状 Cloud Run での GPU は nvidia-l4 しか使えないため、response time P95 45s, 6 RPS が出せるかどうかという形になりそうです。
他の数値も見ながら、計測していきたいと思いますが、Cloud Run + Ollama で生成 AI のアプリケーションを serve するのであれば、より軽量なモデルを利用していくことも検討してもよいかと思います。
とはいえ GPU リソースを自動でスケーリングしてもらうのは、とても便利だと思いますので GA になったら使っていきたいですね。
Discussion