Cloud RunのSidecarでJVMのmetricsの取得してみた
概要
Cloud Runのmetricsをデフォルトで取得している指標(metrics)以外の指標が他に欲しい場合、どうするのが良いのかを考えてみました。
ちょうどCloud RunのSidecar機能がでたので、それを使います。
他の指標を、ここではJVMのmetricsとします。
Cloud Run上のJVMのmetricsが取れて何が嬉しいのかについては、一旦考えません。後にCloud Runの最大起動時間が増えた場合は、意味があるかもしれません。
構成
図にすると以下のような感じになります。
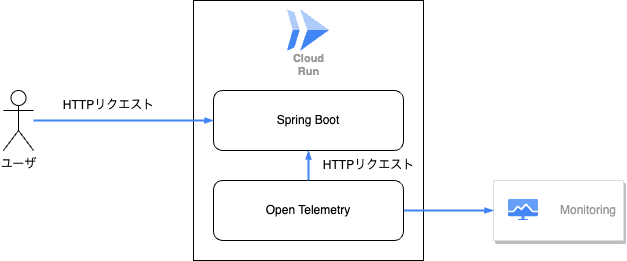
- Cloud RunでSpring Bootアプリケーションを立ち上げCloud Runを動かします
- Cloud RunのSidecarにOpen Telemetryを入れ、Spring Bootに対してリクエストします
- リクエストのmetrics結果をCloud Monitoringに送信してGoogle Cloud上でモニタリングできるようにします
前準備
Spring Bootの設定
| ツール | version |
|---|---|
| Kotlin | 1.7.22 |
| Spring Boot | 3.0.4 |
| Gradle | 7.6.1 |
Open TelemetryがJVMのmetricsを取得できるように、micrometer-registry-prometheusを利用します。
micrometerはobservabilityのためのツールとなっており、今回使うmicrometer-registry-prometheusはSpring Bootのactuatorに対してのpluginだと考えてもらえれば良いです。
dependencies {
// 他のライブラリ
implementation 'org.springframework.boot:spring-boot-starter-actuator'
implementation 'io.micrometer:micrometer-registry-prometheus'
}
そして、以下のようにapplication.propertiesを記載しておきます
management.endpoints.web.exposure.include=health,info,prometheus
上記までの設定で/actuator/prometheusの口が作成されます。
こちらにGETアクセスすると以下のように、metricsが吐き出されます。
こちらは量が多いので、かなり抜粋しています
# HELP jvm_info JVM version info
# TYPE jvm_info gauge
jvm_info{runtime="OpenJDK Runtime Environment",vendor="Oracle Corporation",version="17.0.2+8-86",} 1.0
...
# HELP jvm_memory_used_bytes The amount of used memory
# TYPE jvm_memory_used_bytes gauge
jvm_memory_used_bytes{area="heap",id="Tenured Gen",} 1.7062368E7
jvm_memory_used_bytes{area="nonheap",id="CodeHeap 'profiled nmethods'",} 8964608.0
jvm_memory_used_bytes{area="heap",id="Eden Space",} 1.0121256E7
jvm_memory_used_bytes{area="nonheap",id="Metaspace",} 4.20392E7
jvm_memory_used_bytes{area="nonheap",id="CodeHeap 'non-nmethods'",} 1314816.0
jvm_memory_used_bytes{area="heap",id="Survivor Space",} 1115520.0
jvm_memory_used_bytes{area="nonheap",id="Compressed Class Space",} 5537712.0
jvm_memory_used_bytes{area="nonheap",id="CodeHeap 'non-profiled nmethods'",} 1976064.0
また、上記に足りないものに対して、以下をbuild.gradleに追加し、アプリケーション内でBeanを登録すると
dependencies {
implementation 'io.github.mweirauch:micrometer-jvm-extras:0.2.2'
}
@Bean
fun processMemoryMetrics(): MeterBinder {
return ProcessMemoryMetrics()
}
@Bean
fun processThreadMetrics(): MeterBinder {
return ProcessThreadMetrics()
}
以下のようなデータが追加で取れるようになってきます。
process_threads -1.0
process_memory_vss_bytes -1.0
process_memory_swap_bytes -1.0
process_memory_rss_bytes -1.0
これでアプリケーションの準備が完了です。
設定方法
Open Telemetryの設定
Sidecarで動かすコンテナはopentelemetry-collector-contribになります。
設定については以下のとおりです。merticsの取得だけ行う場合の設定になります。
receivers:
prometheus:
config:
scrape_configs:
- job_name: app
scrape_interval: 5s
metrics_path: "/actuator/prometheus"
static_configs:
- targets: [localhost:8080] # Sidecarでアクセスする際はlocalhostでドメイン解決できる
exporters:
googlecloud:
retry_on_failure:
enabled: false
project: xxxxx
service:
pipelines:
metrics:
receivers: [prometheus]
exporters: [googlecloud]
このyamlを使ってImageをbuildします。
FROM otel/opentelemetry-collector-contrib:0.80.0
COPY config.yaml /etc/otelcol-contrib/config.yaml
そして、Artifact Registoryにpushします。
Cloud RunのSidecarの設定
Cloud RunのSidecarの設定は以下のようなファイルを作成することが必要です
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
annotations:
run.googleapis.com/launch-stage: BETA
name: sidecar-test
spec:
template:
metadata:
annotations:
run.googleapis.com/execution-environment: gen2
run.googleapis.com/container-dependencies: "{otl:[app]}" # コンテナの起動順を制御する
spec:
containers:
- image: {アプリケーションのImage}
name: app
ports:
- containerPort: 8080
- image: {上記で作成したotlのImage}
imagePullPolicy: always
name: otl
こちらのファイルを利用して以下のコマンドを叩きます。
gcloud run services replace app.yaml --project xxxxx
するとアプリケーションが立ち上がります。

しかし、ログを見てみると以下のようなエラーがでていることがあります。
2023-06-23T08:28:16.280Z error exporterhelper/queued_retry.go:357 Exporting failed. Try enabling retry_on_failure config option to retry on retryable errors {"kind": "exporter", "data_type": "metrics", "name": "googlecloud", "error": "failed to export time series to GCM: rpc error: code = InvalidArgument desc = One or more TimeSeries could not be written: One or more points were written more frequently than the maximum sampling period configured for the metric.: generic_task{job:app,namespace:,task_id:localhost:8080,location:global} timeSeries[0-96]: workload.googleapis.com/executor_pool_max_threads{service_instance_id:localhost:8080,instrumentation_source:otelcol/prometheusreceiver,instrumentation_version:0.80.0,service_name:app,name:applicationTaskExecutor}"}
こちらは同じタイミングでmetricsが送られているのが問題のようです。
詳しくはわかりませんが、Cloud Runのmetricsを送っているものと被っているのかと推測しています。
Open Telemetryのexporterでprefixを設定することで、エラーを絞ることができます。ので以下のように
exporters:
googlecloud:
# 今までの設定に以下を追加する
metric:
prefix: "workload.googleapis.com/"
Cloud Monitoringでのモニタリングの作成
上記までの設定でmetricsデータが送れているはずです。
次にCloud Monitoringのページで設定を行います。
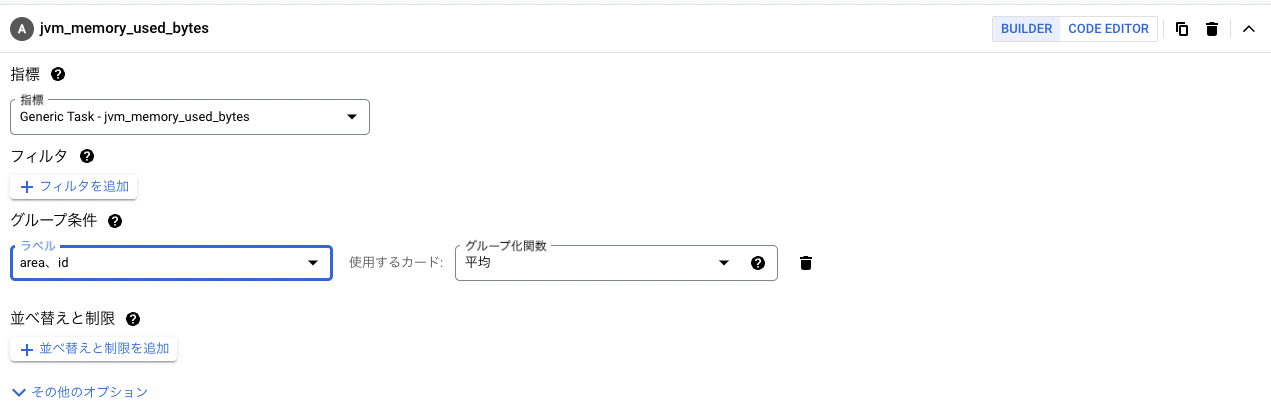
今回metricsの方では、 jvm_memory_used_bytes を選択し、 metric labelsではarea、idを指定します。
その後にグラフの保存を行い、dashboardへの追加をします。

作り方としては以上ですが、複雑な物を作りたいなどがあると思います。 を参考にdashboardを作成していくのが良いかと思います。
まとめ
上記まででJVMのmetricsが取得できるかと思います。
チューニングすんのか?とか、なんの役に立つのかはちょっとまだわかりませんが、誰かの役に立てば幸いです。
ちなみに、以前GCE内のDockerのJVMのmetricsを取得することはやっておりましたが、その際にはGoogle Cloudのopsエージェントを利用していたため、比較的楽に取得することができました。
ただ今回は、結果そんなに難しくはないという感じになったのですが、Open Telemetry設定やSidecarでのドメインはどうなるのか、などが分からなかったので時間がかかってしまいました。ここは勉強し直しです。
参考
Discussion