YOLOをチューニングして錠剤を数えてみた
YOLOをチューニングして錠剤を数えてみた
錠剤を数えるとてもシンプルな課題です。
でもAIでやってみると思った以上に学びが多い実験になりました。
今回は物体検出モデル YOLO (You Only Look Once) を使って「錠剤カウントモデル」を作ってみた記録です。
きっかけ
YOLO(You Only Look Once)は画像を一度見るだけで複数の物体を同時に検出できる 物体検出アルゴリズム です。
他のモデルに比べて 推論が速く精度と処理速度のバランスが良いので現場の利用例も多く実装もシンプルなのが特徴です。
深層学習には分類・セグメンテーション・生成など様々な手法がありますが
今回の課題は「錠剤を数える」ことなので
位置と数を同時に扱える YOLOの物体検出タスクが一番フィットすると考えました。
この点、YOLOは元々80種類の一般物体で学習されていますが
今回の目標は「pill(錠剤)」という1種類のみです。
そこで 転移学習 (transfer learning) を使いYOLOを錠剤専用にチューニングすることにしました。
今回利用したのは Ultralytics YOLO です。
これは PyTorch のラッパーでdata.yaml にクラスを定義するだけで自動的に出力層を切り替え学習を実行してくれます。
通常であれば PyTorch の nn.Linear を書き換えたり出力ノード数をラベル数に合わせたりする必要がありますが
Ultralytics ではほぼコード不要で完結できます。
一方でより深く踏み込むなら PyTorch で直接操作して
-
出力層のカスタマイズ
-
損失関数の設計
-
勾配計算や学習率調整
といった部分に手を入れることになります。
その際には線形代数・微分・確率統計などの数学的な知識があるとディープラーニングをより柔軟かつ深く操作できるようになります。
つまりUltralytics は「PoCや小規模実験を素早く回す」には最適なツールですが
一方でモデルを自分の課題に合わせて改良・拡張していきたい場合には
PyTorchを直接触り数学的な知識を活かして設計を工夫することが必要になります。
YOLOモデルの読み込み
まずは事前学習済みモデルをロードします。
Ultralytics YOLO では数行のコードで準備が完了します。
from ultralytics import YOLO
# 学習済みモデルをロード
yolo8 = YOLO("yolov8s.pt")
yolo11 = YOLO("yolov11s.pt")
データ準備
学習用に自前作成の写真を15枚ほど用意し、
LabelImgでpillというラベルを付けました。
対象を余白なく囲むことで検出精度の向上を狙っています。
その後trainとvalに分割しdata.yaml を準備します。
# data.yaml
path: /Users/ss/pill-counter/ml/dataset
train: images/train
val: images/val
names:
0: pill

モデルを学習
今回は YOLOv8s と YOLOv11s の両方を試してみました。
(11が上位版というわけではないので比較する価値があります。)
yolo detect train data=dataset/data.yaml model=yolov11s.pt epochs=50 imgsz=640 project=runs/detect name=yolo11_pill
Mac M2で数分ほどで学習がすみました。
結果の比較
出力を比較すると同じ画像でもカウント結果が大きく違いました。
YOLO8sそのままの出力

YOLO11sそのままの出力
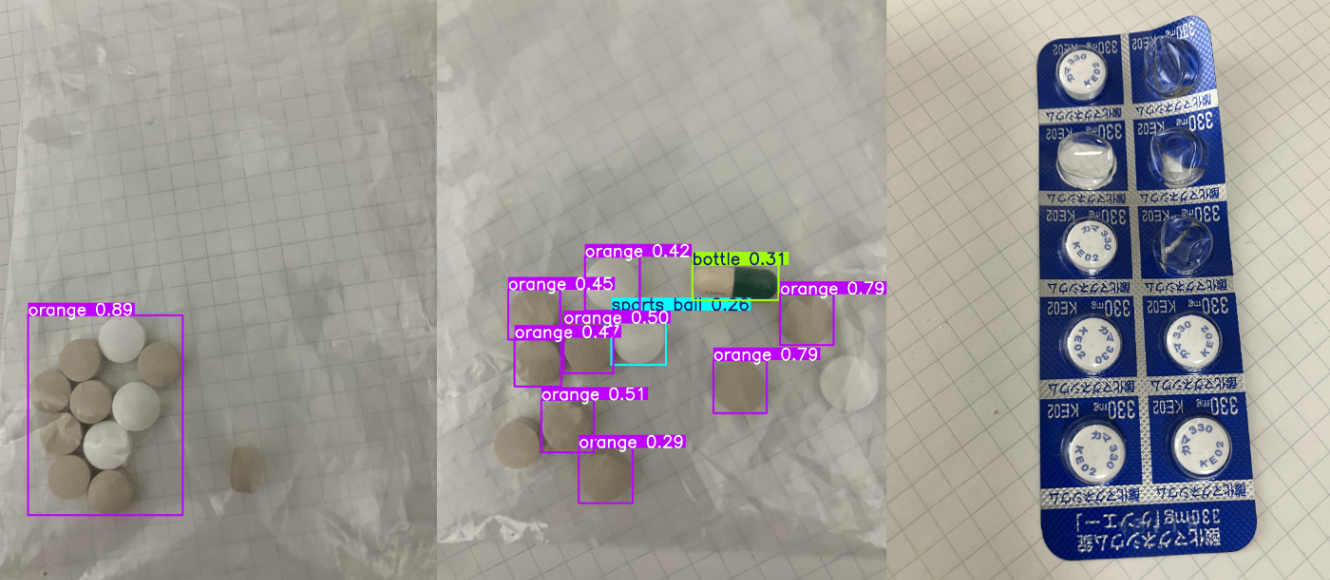
YOLO8s をチューニングしたモデル(左から個数は16, 23, 37)

YOLO11s をチューニングしたモデル(左から個数は11, 15, 11)

今回のデータセットでは YOLO11s の方が有望 という印象です。
考察
この実験を通じて見えたこと:
-
転移学習とファインチューニングだけでも業務課題に近いモデルが比較的短期間で作れる。
-
最新モデル・大きなモデルを盲目的に使うより小さな実験を回して比較する姿勢が重要。
そして将来的には、
損失関数の調整、データの多様性の拡充(形状・照明・背景など)、複数種類の錠剤・カプセル検出といった拡張が期待できます。
その際には数学的な理解が確実に役立ちます。
例えば
線形代数 → 畳み込み層やAttentionの行列演算を深く理解するため
微分・最適化 → 損失関数の設計や勾配消失/爆発の回避に直結
確率・統計 → データ拡張や正則化、ベイズ的アプローチに必要
実務では「まずは既存モデルを動かす」で十分に価値が出ますが理論を押さえることで改善の切り口を自分で作れるのもAI開発の醍醐味だと思います。
まとめ
少数の画像とシンプルなラベルでもYOLO を使えば錠剤カウントのような実用課題に挑戦できる。
「まず試す → 比較する → 改善する」という実験的アプローチがAIを現場に取り込む際には有効だと思います。
この経験が「自分の分野でもAIを使ってみたい」と思っている方にとって背中をそっと押すものになれば嬉しいです。
参考資料/文献
赤石雅典『最短コースでわかる PyTorch & 深層学習プログラミング』 — プログラムの書き方、構成の整理など実用的な入門として最適。
YouTube: DL実装(https://www.youtube.com/watch?v=TrRHMjhlq_w)
小川雄太郎『つくりながら学ぶ! PyTorchによる発展ディープラーニング』 — 応用技術のアイディア源として豊富。
『機械学習エンジニアのためのTransformers ―最先端の自然言語処理ライブラリによるモデル開発』
斎藤康毅『ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装』
Discussion