Vertex AI Pipelinesで社内初のMLOpsのためのワークフロー構築を行いました
はじめに
こんにちは。ファイディ株式会社で機械学習エンジニアをしています、笹野です。
主に機械学習に関する事全般を業務範囲としていて、最近では新規技術開発を中心にソフトウェアエンジニアリングやデータ分析業務を中心に行なっています。
今回は社内でまだ進められていなかったMLOpsの為のワークフロー構築(以下ワークフロー構築)を進めました。MLOpsファインディパターンとして記事を書いてみましたので、一読頂ければと思います。
書くこと
- ワークフロー構築のモチベーション
- どんな構成にしたか
- 構築時の苦労
書かない事
- MLOpsとは
- Vertex AI Pipelinesとは
ワークフロー構築のモチベーション
ワークフロー構築に至った背景として社内で動いているレコメンデーションモデルがあるのですが、
- このモデルの更新が不定期だった事
- 追跡している指標をこまめにチェックしながら「そろそろ更新するか」と感じたタイミングで更新を行なっていた
- 更新を行うモデルは、コード管理しているレポジトリ内に存在するノートブックをポチポチ叩いて行われていた
- 使っているライブラリのバージョン管理はpoetry等でできているものの、半属人化しつつある状況
- 引き継ぎや保守運用を考えると、コストが肥大化していきそう
- 使っているライブラリのバージョン管理はpoetry等でできているものの、半属人化しつつある状況
- 運用しているレコメンデーションモデルの事業KPIに対する貢献度がそれなりにあった
以上の状況であった事から、ワークフロー構築に踏み切りました。
ワークフロー構成
今回は、GCPのVertex AI Pipelinesを用いてモデル学習のワークフローを構築する事にしました。
こうしたMLOpsを構築する技術はVertex AI Pipelines以外にもあると思いますが、著者の所属するチームではBigQuery上に必要なデータを配置している関係で、GCPが提供している機能で構築するのが都合が良いことが多かった為、Vertex AI Pipelinesを選択しました。
ただ、Vertex AI Pipelinesのみではまだ完全に属人化から解放されないので、Github ActionsによるCI/CD構築も行い、構築したワークフローを定期実行ジョブ化する事を目指しました。
また、実装するにあたり公式のGithubレポジトリを参考にさせて頂きました。
全体のワークフロー構成
先ず、結果的に今回構築した全体のワークフロー構成図を示しておきます。CI/CDも含め、このようなフローになりました。
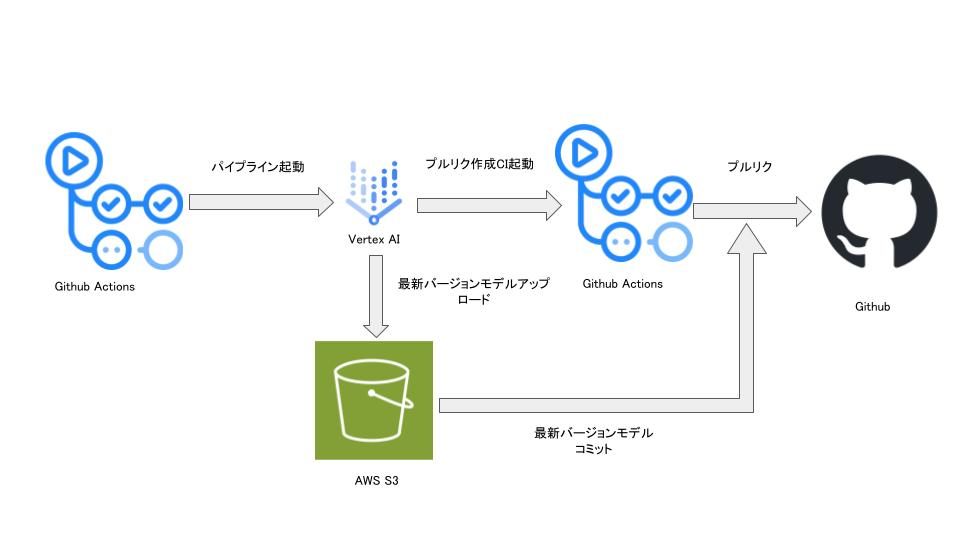
ワークフローで学習したモデルを一度S3に保存しているフローがあり、GCSにすると綺麗になりそうではありますが、社内のシステムインフラの都合上S3を選択しています。
さらに、上図内のVertex AI部分は、以下ような構成になりました。
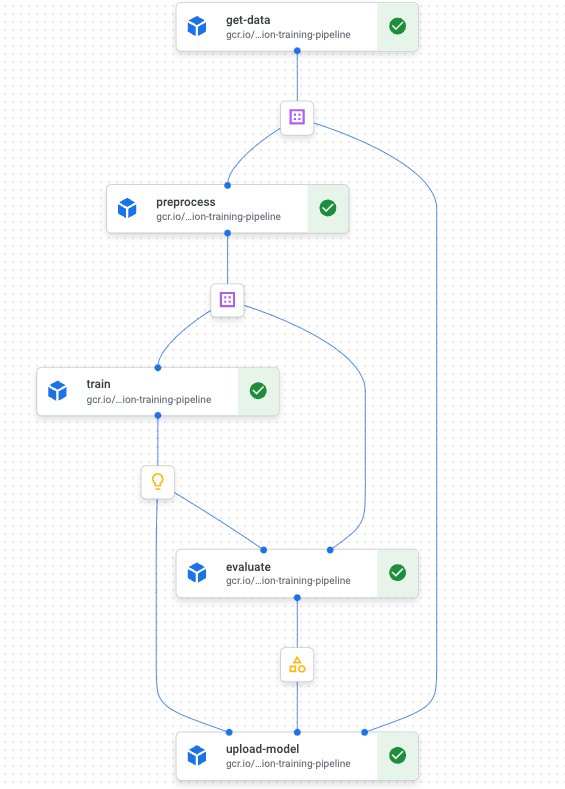
実際に今回構築したワークフローを導入し、レコメンデーションモデルの定期的な学習による運用コストの削減を実現しました。
構築時の苦労
「Vertex AI Pipelinesは運用において都合が良い」と上で書いており、実際その通りではあるのですが、実装する上で、認証情報をどのように管理するかという点で苦労しました。
認証情報をどのように管理するか
今回構築したフローを実行する為に、通さなければいけない認証が3箇所ありました。
- Github Actions(ワークフロー起動CI/CD) → Vertex AI Pipelinesの起動
- Vertex AI Pipelines → S3へのファイル書き込み
- Vertex AI Pipelines → Github Actions(リリースプルリク作成CI/CD)
ノートブックでモデルの再学習を行う場合や、ローカルマシンから各ワークフローをマニュアル操作で起動する際は必要な認証ファイルをパス指定し、実行すれば済んでいました。
しかし、全て一連の流れで自動化をするとなると、やはり認証情報の管理は避けては通れません。
加えて、セキュリティの観点で認証ファイルをDockerイメージに含めてビルドする形は避けたかったので、こちらもGCPのSecret Managerに各サービスの認証情報を登録し、上記3箇所の認証を通すタイミングでSecret Managerから取得し、認証をクリアするように実装しました。
構築時の工夫
Vertex AI Pipelinesで実装する上で、以下のような工夫を施しました。
- Dockerfileをフロー毎に用意せず共通化
- Dockerイメージのlatestタグでの運用をやめる
Dockerfileをフロー毎に用意せず共通化
Vertex AI Pipelinesではフローの各ジョブ単位でリソースを個別で用意する事ができるので、必要なリソースのみで運用する事が可能となります。Dockerfileもその内の一つではあるのですが弊チームの場合だと各ジョブで必要になるリソースの差分がほとんどなかった為、参照するDockerfileを共通化し、1つのイメージでジョブを実行させるようにしました。
共通化する事で、
- イメージビルドの時間が短縮
- Dockerfileが1つなのでメンテナンスが楽
というメリットを感じることができました。
以下Dockerfileの共通化によるディレクトリ構成の雰囲気になります。
vertex-ai-pipelines
├── components
│ ├── get_data.yaml
│ ├── preprocess.yaml
│ ├── train.yaml
│ ├── evaluate.yaml
│ └── upload_model.yaml
├── Dockerfile
Dockerイメージのlatestタグでの運用をやめる
Dockerイメージのタグをlatest指定で運用していると、意図しない挙動になったり意図しないイメージのタグを参照したりする事が知られているかと思います。
モデル学習のワークフロー運用においても、実験中やPoC中のイメージが紛れ込んでしまう可能性が0ではない為、CIから起動した際にcommit hashでタグ付けし、イメージを参照する際にタグ付けされたcommit hashを指定する事で事故を防いでいます。
この工夫を、弊チームメンバーの山家(@yamayafumiteru)に実装してもらいました。
その他にも
構築にあたり、全体のレビュワーを弊チームリーダーの志賀(@yush1ga)に担当してもらったり、方針変更に伴うディレクトリ構成の変更・見直し等を、5月よりチームにジョインした真保(@WebY76755963)に担当してもらいながら、チームで構築を進めて全体でノウハウを共有しながら整備を進めるという事を意識しました。
まだまだ改善の余地あり
ここまでで述べたように、MLOpsを構築できた事でモデルの保守・運用コストを軽減させることができ、一旦の満足を得ることは出来ました。
とは言え、まだまだ伸び代はあると考えていて、
- アルゴリズムの更新をスムーズに行えるようにする
- バッチ処理を高速化する
- 一部二重管理になっている部分をやめる
などなど、目立つ改善ではないですが、どれもこれから進めておくと後々楽にできるような改善が軒を連ねているので、引き続き開発を進めていきたいと考えています。
まとめ
以上、MLOpsファインディーパターンとして、どんな構築にしたかを中心に紹介させて頂きました。
まだまだ伸び代のあるものになっていますので、本記事を読んで「こんな改善あるんだけど?」となりましたら、
採用強化中ですので是非カジュアル面談等でお話しましょう。
Discussion