イベントトリガーでCloud Data FusionのETLを実行する
これは何か
DataFusionの試していたところ、データパイプラインをスケジューリング実行することはできそうだったが、イベントトリガーで動かす機能についてはパッと見当たらなかった。
以下の記事でCloud Functionで動かしている人がいたので、自分でも試してみつつ、本番稼働を想定するとリソースをコード管理する必要があると思うので、terraformで各種リソースを設定する上でハマった部分など残しておく。
Data Fusionとは何か
GCPで提供されているフルマネージドのETLツール
実行内容
よくあるユースケースとしてGCSにCSVファイルをアップロードしたことをトリガーに、Data Fusionで変換し、DWHであるBigQueryにデータを取り込むケースを試して見た。
概要
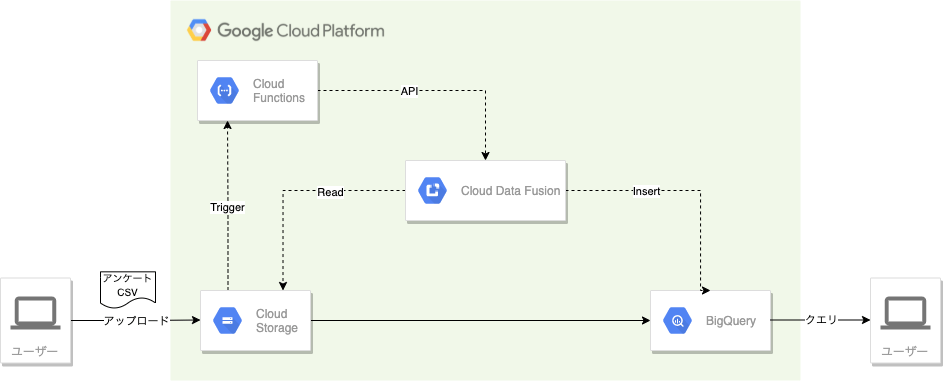
GCSへのアップロードをトリガーにData Fusionを動かすのは、Cloud FunctionでData FusionのAPIを叩く形で実装した。
Data FusionではアップロードしたCSVファイルをJSONに変換して、BigQueryにinsertし、BigQuery上でparseする。
実装
Data Fusionの設定
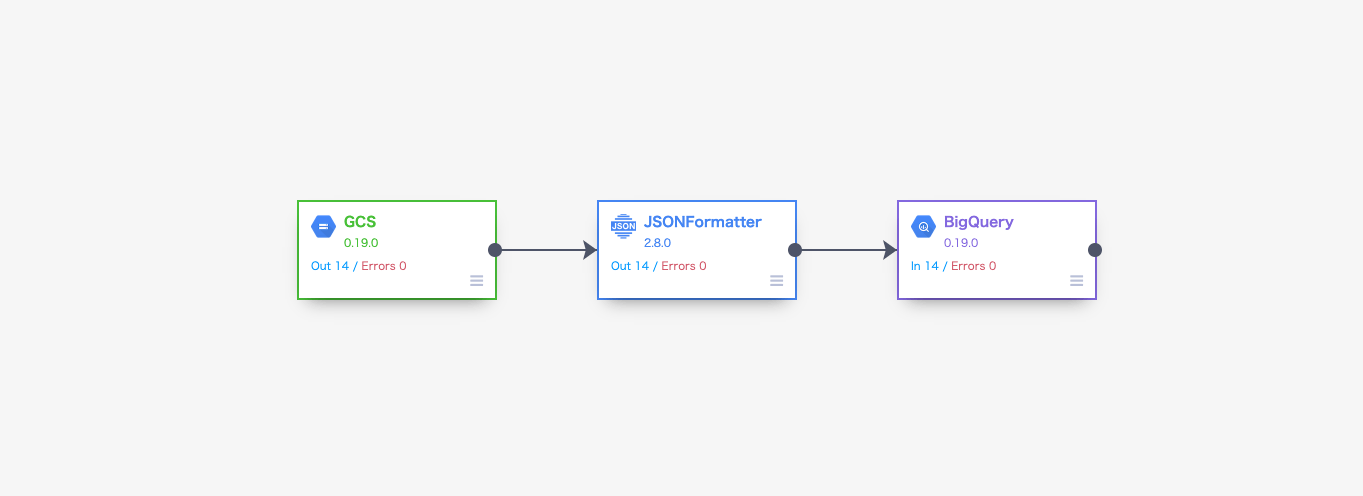
以下のJSON形式で定義されたData Fusionのパイプラインは上記のようになる。
JSONコード
{
"name": "weekly_survey_etl",
"description": "Data Pipeline Application",
"artifact": {
"name": "cdap-data-pipeline",
"version": "6.6.0",
"scope": "SYSTEM"
},
"config": {
"resources": {
"memoryMB": 2048,
"virtualCores": 1
},
"driverResources": {
"memoryMB": 2048,
"virtualCores": 1
},
"connections": [
{
"from": "GCS",
"to": "JSONFormatter"
},
{
"from": "JSONFormatter",
"to": "BigQuery"
}
],
"comments": [],
"postActions": [],
"properties": {},
"processTimingEnabled": true,
"stageLoggingEnabled": false,
"stages": [
{
"name": "GCS",
"plugin": {
"name": "GCSFile",
"type": "batchsource",
"label": "GCS",
"artifact": {
"name": "google-cloud",
"version": "0.19.0",
"scope": "SYSTEM"
},
"properties": {
"useConnection": "false",
"referenceName": "weekly_survey_csv",
"path": "gs://{PROJECT_ID}-input/${my-file}", # {PROJECT_ID}の部分は自分で差し替える
"format": "csv",
"sampleSize": "1000",
"delimiter": ",",
"skipHeader": "true",
"filenameOnly": "false",
"recursive": "false",
"encrypted": "false",
"fileEncoding": "UTF-8",
"schema": "{\"type\":\"record\",\"name\":\"etlSchemaBody\",\"fields\":[{\"name\":\"questionaire_id\",\"type\":\"string\"},{\"name\":\"respondent_id\",\"type\":\"int\"},{\"name\":\"timestamp\",\"type\":\"string\"},{\"name\":\"q1\",\"type\":\"string\"},{\"name\":\"q2\",\"type\":\"string\"},{\"name\":\"q3\",\"type\":\"string\"},{\"name\":\"q4\",\"type\":\"string\"},{\"name\":\"q5\",\"type\":\"string\"}]}",
"project": "auto-detect",
"serviceAccountType": "filePath",
"serviceFilePath": "auto-detect"
}
},
"outputSchema": [
{
"name": "etlSchemaBody",
"schema": "{\"type\":\"record\",\"name\":\"etlSchemaBody\",\"fields\":[{\"name\":\"questionaire_id\",\"type\":\"string\"},{\"name\":\"respondent_id\",\"type\":\"int\"},{\"name\":\"timestamp\",\"type\":\"string\"},{\"name\":\"q1\",\"type\":\"string\"},{\"name\":\"q2\",\"type\":\"string\"},{\"name\":\"q3\",\"type\":\"string\"},{\"name\":\"q4\",\"type\":\"string\"},{\"name\":\"q5\",\"type\":\"string\"}]}"
}
],
"id": "GCS"
},
{
"name": "JSONFormatter",
"plugin": {
"name": "JSONFormatter",
"type": "transform",
"label": "JSONFormatter",
"artifact": {
"name": "transform-plugins",
"version": "2.8.0",
"scope": "SYSTEM"
},
"properties": {
"schema": "{\"type\":\"record\",\"name\":\"etlSchemaBody\",\"fields\":[{\"name\":\"answer\",\"type\":\"string\"}]}"
}
},
"outputSchema": "{\"type\":\"record\",\"name\":\"etlSchemaBody\",\"fields\":[{\"name\":\"answer\",\"type\":\"string\"}]}",
"inputSchema": [
{
"name": "GCS",
"schema": "{\"type\":\"record\",\"name\":\"etlSchemaBody\",\"fields\":[{\"name\":\"questionaire_id\",\"type\":\"string\"},{\"name\":\"respondent_id\",\"type\":\"int\"},{\"name\":\"timestamp\",\"type\":\"string\"},{\"name\":\"q1\",\"type\":\"string\"},{\"name\":\"q2\",\"type\":\"string\"},{\"name\":\"q3\",\"type\":\"string\"},{\"name\":\"q4\",\"type\":\"string\"},{\"name\":\"q5\",\"type\":\"string\"}]}"
}
],
"id": "JSONFormatter",
"type": "transform",
"label": "JSONFormatter",
"icon": "icon-jsonformatter"
},
{
"name": "BigQuery",
"plugin": {
"name": "BigQueryTable",
"type": "batchsink",
"label": "BigQuery",
"artifact": {
"name": "google-cloud",
"version": "0.19.0",
"scope": "SYSTEM"
},
"properties": {
"referenceName": "BigQuery",
"project": "{PROJECT_ID}", # {PROJECT_ID}の部分は自分で差し替える
"dataset": "dataset",
"table": "survey",
"serviceAccountType": "filePath",
"operation": "insert",
"truncateTable": "false",
"allowSchemaRelaxation": "false",
"location": "US",
"createPartitionedTable": "false",
"partitioningType": "TIME",
"partitionFilterRequired": "false",
"schema": "{\"name\":\"etlSchemaBody\",\"type\":\"record\",\"fields\":[{\"name\":\"answer\",\"type\":\"string\"}]}",
"serviceFilePath": "auto-detect"
}
},
"outputSchema": "{\"name\":\"etlSchemaBody\",\"type\":\"record\",\"fields\":[{\"name\":\"answer\",\"type\":\"string\"}]}",
"inputSchema": [
{
"name": "JSONFormatter",
"schema": "{\"type\":\"record\",\"name\":\"etlSchemaBody\",\"fields\":[{\"name\":\"answer\",\"type\":\"string\"}]}"
}
],
"id": "BigQuery",
"type": "batchsink",
"label": "BigQuery",
"icon": "fa-plug"
}
],
"schedule": "0 1 */1 * *",
"engine": "spark",
"numOfRecordsPreview": 100,
"rangeRecordsPreview": {
"min": 1,
"max": "5000"
},
"description": "Data Pipeline Application",
"maxConcurrentRuns": 1
}
}
Cloud Functionの設定
# Cloud Functinosのソースファイル
import subprocess
import requests
import json
import os
import time
def get_access_token():
scopes='https://www.googleapis.com/auth/cloud-platform'
headers={'Metadata-Flavor': 'Google'}
api="http://metadata.google.internal/computeMetadata/v1/instance/service-accounts/default/token?scopes=" + scopes
r = requests.get(api,headers=headers).json()
return r['access_token']
def run_job(data, context):
PROJECT_ID=os.environ.get('PROJECT_ID', 'Specified environment variable is not set.')
PIPELINE_NAME=os.environ.get('PIPELINE_NAME', 'Specified environment variable is not set.')
INSTANCE_ID=os.environ.get('INSTANCE_ID', 'Specified environment variable is not set.')
REGION=os.environ.get('REGION', 'Specified environment variable is not set.')
NAMESPACE_ID=os.environ.get('NAMESPACE_ID', 'Specified environment variable is not set.')
CDAP_ENDPOINT=os.environ.get('CDAP_ENDPOINT', 'Specified environment variable is not set.')
default_file_name = data['name']
bucket_name = data['bucket']
auth_token=get_access_token()
post_endpoint = CDAP_ENDPOINT + "/v3/namespaces/" + NAMESPACE_ID + "/apps/" + PIPELINE_NAME + "/workflows/DataPipelineWorkflow/start"
data = "{'my-file':'" + default_file_name +"'}"
post_headers = {"Authorization": "Bearer " + auth_token,"Accept": "application/json"}
r1 = requests.post(post_endpoint,data=data,headers=post_headers)
インフラの設定
各リソースは次のように設定した。
Data Fusion
Data Fusionではインスタンス・名前空間・パイプラインの作成が必要になる。パイプラインでは、Data Fusionの設定を記載したJSONファイルを読み込み、デプロイしている。
# data fusionの設定
resource "google_data_fusion_instance" "instance" {
name = "sasakky-datafusion-instance"
project = var.GCP_PROJECT_ID
region = var.REGION
type = "BASIC"
dataproc_service_account = google_service_account.develop.email
}
resource "cdap_namespace" "namespace" {
name = "sandbox"
}
resource "cdap_application" "pipeline" {
name = "weekly_survey_etl"
namespace = cdap_namespace.namespace.name
spec = file("../src/data_fusion/weekly_survey_etl-cdap-data-pipeline.json")
depends_on = [
cdap_namespace.namespace
]
}
Cloud Function・Cloud Storageの設定
Cloud Functionをデプロイするバケット({GCP_PROJECT_ID}-function)と、Cloud Functionがトリガーとするバケット({GCP_PROJECT_ID}-input)を作成する。inputバケットの方にCSVファイルをアップロードする。
resource "google_storage_bucket" "function_bucket" {
name = "${var.GCP_PROJECT_ID}-function"
location = var.REGION
}
resource "google_storage_bucket" "input_bucket" {
name = "${var.GCP_PROJECT_ID}-input"
location = var.REGION
}
data "archive_file" "source" {
type = "zip"
source_dir = "../src/cloud_function"
output_path = "/tmp/function.zip"
}
resource "google_storage_bucket_object" "zip" {
source = data.archive_file.source.output_path
content_type = "application/zip"
name = "src-${data.archive_file.source.output_md5}.zip"
bucket = google_storage_bucket.function_bucket.name
depends_on = [
google_storage_bucket.function_bucket,
data.archive_file.source
]
}
resource "google_cloudfunctions_function" "function" {
name = "weekly_survey_etl_function"
runtime = "python37" # of course changeable
source_archive_bucket = google_storage_bucket.function_bucket.name
source_archive_object = google_storage_bucket_object.zip.name
entry_point = "run_job"
service_account_email = google_service_account.develop.email
environment_variables = {
INSTANCE_ID = google_data_fusion_instance.instance.name,
REGION = var.REGION,
PIPELINE_NAME = cdap_application.pipeline.name,
PROJECT_ID = var.GCP_PROJECT_ID,
NAMESPACE_ID = cdap_namespace.namespace.name,
CDAP_ENDPOINT = "https://${google_data_fusion_instance.instance.name}-${var.GCP_PROJECT_ID}-dot-usc1.datafusion.googleusercontent.com/api"
}
event_trigger {
event_type = "google.storage.object.finalize"
resource = "${var.GCP_PROJECT_ID}-input"
}
depends_on = [
google_storage_bucket.function_bucket,
google_storage_bucket_object.zip,
google_data_fusion_instance.instance,
cdap_namespace.namespace,
cdap_application.pipeline,
google_service_account.develop
]
}
Cloud Functionを動かすサービスアカウント
次のようなロールを設定した。

IAMのterraform設定
# サービスアカウント作成とロールの付与
resource "google_service_account" "develop" {
project = var.GCP_PROJECT_ID
account_id = "develop"
display_name = "develop"
}
resource "google_project_iam_member" "develop_cloudfunction_invoker" {
project = var.GCP_PROJECT_ID
role = "roles/cloudfunctions.invoker"
member = "serviceAccount:${google_service_account.develop.email}"
}
resource "google_project_iam_member" "develop_datafusion_admin" {
project = var.GCP_PROJECT_ID
role = "roles/datafusion.admin"
member = "serviceAccount:${google_service_account.develop.email}"
}
resource "google_project_iam_member" "develop_storage_admin" {
project = var.GCP_PROJECT_ID
role = "roles/storage.admin"
member = "serviceAccount:${google_service_account.develop.email}"
}
resource "google_project_iam_member" "develop_bigquery_editer" {
project = var.GCP_PROJECT_ID
role = "roles/bigquery.dataEditor"
member = "serviceAccount:${google_service_account.develop.email}"
}
resource "google_project_iam_member" "develop_bigquery_jobUser" {
project = var.GCP_PROJECT_ID
role = "roles/bigquery.jobUser"
member = "serviceAccount:${google_service_account.develop.email}"
}
resource "google_project_iam_member" "develop_serviceAccountUser" {
project = var.GCP_PROJECT_ID
role = "roles/iam.serviceAccountUser"
member = "serviceAccount:${google_service_account.develop.email}"
}
resource "google_project_iam_member" "develop_dataproc_worker" {
project = var.GCP_PROJECT_ID
role = "roles/dataproc.worker"
member = "serviceAccount:${google_service_account.develop.email}"
}
resource "google_project_iam_member" "sa-datafusion_serviceAccountUser" {
project = var.GCP_PROJECT_ID
role = "roles/iam.serviceAccountUser"
member = "serviceAccount:service-{PROJECT_NO}@gcp-sa-datafusion.iam.gserviceaccount.com"
}
考察
イベントトリガー実装の仕組み
Cloud FunctionからData Fusionへのつなぎこみの仕組みとしては、
Cloud FunctionでアップロードされたGCSのディレクトリとファイル名を取得し、引数としてDataFusionのAPIに渡してコールする。
default_file_name = data['name']
bucket_name = data['bucket']
data = "{'my-file':'" + default_file_name +"'}"
r1 = requests.post(post_endpoint,data=data,headers=post_headers)
DataFusion側では、${my-file}としてAPIと一緒に渡された引数を受け取って、READ先のデータの場所を指定する。
"path": "gs://{PROJECT_ID}-input/${my-file}",
IAM権限設定の注意点
terraformでIAMを設定するときは、Data Fusionで指定するサービスアカウントのロールだけでなく、以下のサービスアカウントにも「サービスアカウント ユーザー」のロールを付与しないとエラーになった。
resource "google_project_iam_member" "sa-datafusion_serviceAccountUser" {
project = var.GCP_PROJECT_ID
role = "roles/iam.serviceAccountUser"
member = "serviceAccount:service-{PROJECT_NO}@gcp-sa-datafusion.iam.gserviceaccount.com"
}
こちらのStackOverflowを見る感じ、プロセスを実行しているのは別のサービスアカウントになりそう。
Discussion