駆け出しスタートアップの2023年下半期データ基盤やったことまとめ
これは何か
30人規模のスタートアップの一人データ組織の人間が、2023年下半期でデータ基盤整備をガシガシ進めたログ。
データモデルは100を超えてきたが、一人でもなんとか回せてきたので、同規模のスタートアップで孤軍奮闘されているデータ組織の人たちにとって、少しでも参考になれば幸いと思い、本記事を書いてみる。
概要
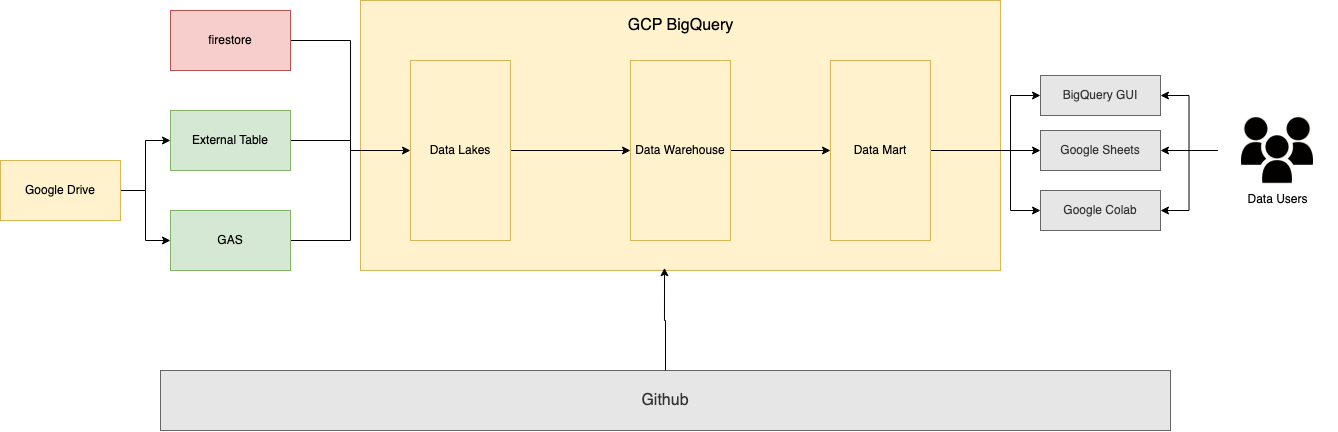
2023年上半期の図
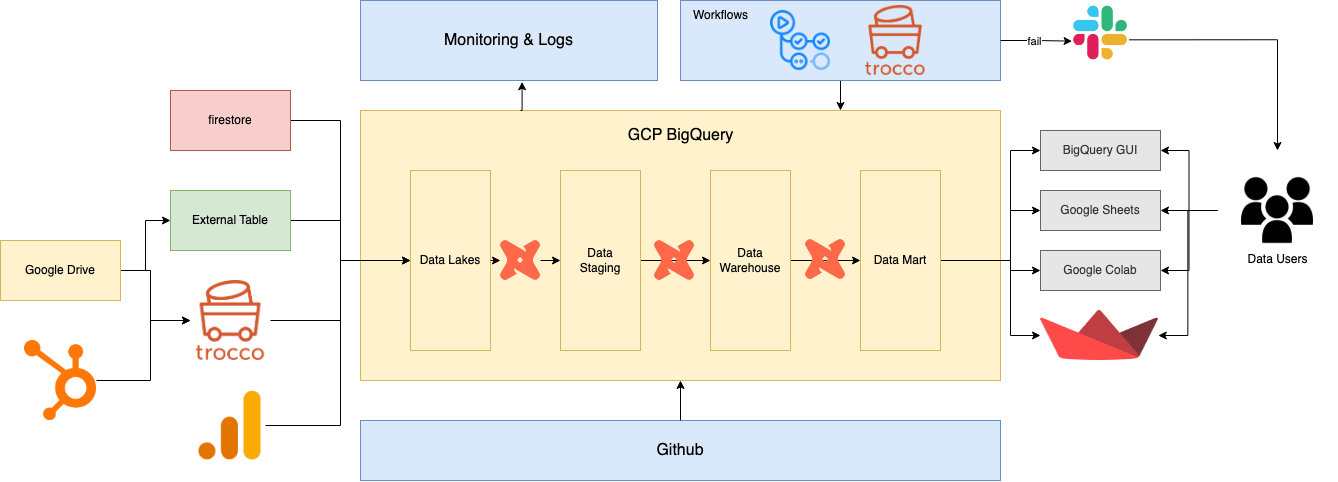
2023年下半期の図
当初の課題
1. ビューの多段構成
- データ量がさほど多くなかったので、ビューで構成していたが、だんだんとロジックが積み重なってくるにつれて、クエリのパフォーマンスが悪くなっていった
- クエリのスケジューリングは依存関係を暗黙的に定義してしまうので、バグの温床となり、できるだけ使いたくなかった
2. 開発生産性の悪化
- データモデルの増加に従って、依存関係の管理が大変になってきた
- どこを修正したら、下流モデルにどのような影響が発生するのか検知しづらくなってきた。また、それを一々テストしている余裕はなかった
- デプロイをシェルで自動化していた
- 100行を超えたくらいでメンテがしんどくなった
3. データ品質の悪化
- ローデータに意図しない異常データが入ってしまったときに、後続のバグとなるが、検知する術がなかった
- 異常に気づかないまま、データが意思決定に使われてしまっていることがあった
4. 権限の未整備
- 業務委託含め、個人単位でデータ基盤内のすべてのリソースに閲覧権限がついていたため、セキュリティリスクが高くなっていた
5. 利用状況が不明
- 誰が、いつ、どのビューにアクセスしているのか不明なため、資材の除却を安全に実行できなかった
何をしたか
1. DWHの整備
- layerの分割
- The informed companyに従って、source, staging, warehouse, martの4レイヤーを作成した。(実際はephemeralの中間テーブルがあるのでもっとあるが)
- ここらへんは他社でもっといい事例があると思うので、詳細は割愛。
- ディメンジョナルモデリングの整備、マスターのsnapshot化など、まだまだ改良の余地はあるので、来年も引き続き取り組んでいきたい。
- dbtの導入
- 既存SQLをすべてdbtモデルに刷新した
- testが書けて便利
- メタデータ・リネージが確認できるため、新しくジョインした開発者へのオンボーディングコストがほぼゼロになった
- dbt-osmosisでメタデータの管理
- すべてのローデータにメタデータ付与を行なっているため、コマンド一発で下流モデルは全更新できる
- 便利な外部パッケージの利用
- GA4のモデリングは、dbt-ga4を使っている
- 少しの設定でいい感じのデータモデルを作ってくれるのは一人データ組織の強い味方
- 既存SQLをすべてdbtモデルに刷新した
dbtを導入してから開発が楽になりすぎて気づいたらコミット数も爆伸びしてました。

2. ELTツールの導入
従来使用していたGASのパイプラインをやめ、troccoへの移行をした。
troccoは二種のコネクタ(転送元・転送先)なら無料で使用できるので、かなり便利。もっと早く使えばよかった。
内製するか外部SaaSか、troccoかfivetranかなど、色々検討したが、長くなるのでここでは割愛。
ただ、国内の駆け出しスタートアップ&データエンジニアの採用難易度を考えたときに、自分がいなくなってもメンテできるかがかなり大きな選定要素にはなった。
3. ワークフローの導入
- Github Actions
- dbtでtagを指定してbuild
- tagは、daily・ weekly・monthlyを用意しており、それぞれのactionsからdeploy用のymlを呼び出す形で実装
name: scheduled_run_daily
on:
schedule:
- cron: '0 20 * * *'
jobs:
daily_deploy:
uses: ./.github/workflows/_deploy.yml
with:
dbt_tag: daily
dbt_deploy_target: prod
secrets:
DBT_GOOGLE_BIGQUERY_KEYFILE: ${{ secrets.DBT_GOOGLE_BIGQUERY_KEYFILE_PROD }}
SLACK_WEBHOOK_URL_NOTIF: ${{ secrets.SLACK_WEBHOOK_URL_NOTIF }}
name: Deploy
on:
workflow_call:
inputs:
dbt_tag:
description: 'dbtタグ'
type: string
required: true
default: 'daily'
dbt_deploy_target:
description: 'dbtのデプロイターゲット'
type: string
required: true
default: 'dev'
secrets:
DBT_GOOGLE_BIGQUERY_KEYFILE:
description: 'DBT Bigquery Keyfile'
required: true
SLACK_WEBHOOK_URL_NOTIF:
description: 'Slack webhook url'
required: true
env:
DBT_TAG: ${{ inputs.dbt_tag }}
DBT_DEPLOY_TARGET: ${{ inputs.dbt_deploy_target }}
DBT_USER_NAME: gh
jobs:
deploy:
name: Deploy(再利用ワークフロー)
runs-on: ubuntu-latest
steps:
- name: Check out
uses: actions/checkout@master
- name: Set up Cloud SDK
uses: google-github-actions/setup-gcloud@v0
with:
service_account_key: ${{ secrets.DBT_GOOGLE_BIGQUERY_KEYFILE }}
export_default_credentials: true
- name: Set up Python
uses: "actions/setup-python@v2"
with:
python-version: "3.11"
- name: Install dependencies
run: |
pip install -r requirements.txt
dbt deps
- name: dbt build
run: dbt build --target=${{ env.DBT_DEPLOY_TARGET }} --select tag:${{ env.DBT_TAG }}
- name: send notification on slack in case of failure
if: ${{ failure() }}
uses: slackapi/slack-github-action@v1.24.0
with:
payload: |
{
"text": "fail ${{github.server_url}}/${{github.repository}}/actions/runs/${{github.run_id}}"
}
env:
SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL_NOTIF }}
- trocco
- troccoからもdbtを実行できる
- データ連携→dbtでモデル更新を同じワークフロー内で実現
設定も簡単

いずれにしても、失敗時にslackに通知が飛ぶようになっているので、早期検知・リカバリーができている。
ただ、ワークフローが分かれているのも後々見通しが悪くなるので、いずれは別のワークフローを立てて、troccoはAPIとして利用していきたい。
4. CI/CDの導入
こちらもsqlfluff, dbt, github actionsで実装。
- PRオープン,push時にsqlfuffでSQLファイルのlintを自動でかけるようにした
- 組織で適用ルールをカスタマイズして、使用している
- mainブランチへのマージで、github actionsからdbtを叩いて本番環境への反映
5. 権限の整備
- 個人アカウントへのロールの付与廃止
- Google Groups単位で適切に権限付与を行うことにした
- これにより入社時・退職時の権限管理の手間がなくなった
- 参照テーブルの制限
- 現状大半のユーザーはmartを参照するだけで良いので、ローデータや中間テーブルなどは参照させず、マートのみをクエリできるようにした
- これはGroupにBigQueryジョブユーザーの権限だけを与え、martのデータセットにデータ閲覧者権限を付与することで実現
- これだけだとクエリ対象がビューの場合に権限エラーになるので、承認済みデータセットに追加することで対応した
- データセットが増えるにつれて管理も煩雑になるので、IaCでこの辺りをコード管理したい
6. ロギングの開始
- 監査ログの連携、information_schemaの活用
- テーブルだけならinformation_schemaだけで良いが、ビューの閲覧回数は監査ログでないと確認できない
- 以下記事を読んで、監査ログからビューの参照回数も取得できるようにした
7. 検証環境の構築
それまでは本番環境でクエリ結果のチェックをするだけだったが、dbtの導入をしたこともあり、検証環境でbuild→問題がなければPRを上げてmainブランチにマージ→Github Actionsで本番に反映という手順をとるようになった。
複数人でdbtを触っていると、資材が干渉する問題が発生するようになったので、個人ごとにデータセットを自動で分割するようにした。
project_name:
target: dev
outputs:
dev:
type: bigquery
project: {PROJECT_NAME}
dataset: "{{ env_var('DBT_USER_NAME') }}_data"
開発者は最初に自分で環境変数を設定する。ブランチによって分ける方針もあるらしいが、データセットの削除処理もセットで実装しないといけないので、一旦この構成。
これから何をするか
来期以降は組織の拡大とともに、プロダクトの進化がますます加速していくことが予想される。
それに伴い、アナリティクスだけでなく、データを活用したプロダクトの最適化が進んでいくことになりそう。
- 広告媒体へのオフラインCVのリバースETLと集客の最適化
- オンライン・オフライン広告費用アロケーションの最適化
- 需要予測による発注量の最適化・発注の自動化
こうしたソリューションを乗せていくために、データ基盤としてもより安全かつ高速に変更できるように進化させていきたい。
- モデリングの高度化
- スタースキーマ、dbt vaultなどをもっと勉強したい
- データ品質の計測
- elementaryなどでデータ品質のチェック→データオーナーである事業部に連携して修正をするプロセスを構築し、より品質の高いデータ基盤を構築したい
- データ基盤のIaC
- GUIでポチポチやるのも限界が来るので、コードベースで再現性の担保をしたい
- MLOpsの構築
- データ基盤とは関係ないが、今後MLが事業のコアになっていくことが想定されるので、低工数で運用ができるシステムを構築したい
まとめ
この半年で、一人組織でも最低限QCDを担保できるところまではできた気がする。
dbtやtroccoなどの便利なOSS・SaaSが台頭し、ネットの世界でナレッジをシェアくださる方々のおかげで、この辺りの技術ハードルはグンと下がったなあと感じた。
データ組織の人間としては、技術のキャッチアップもさながら、データ分析・データ基盤を事業にどう活かしていくかというところに頭を働かせ、経営まで染み出していきたい。
Discussion