徳丸本を読んでみる
3章:HTTPとセッション管理
パーセントエンコーディングとapplication/x-www-form-urlencoded
パーセントエンコーディングはURIの規約で、application/x-www-form-urlencodedはHTMLの規約だから微妙に違うらしい
具体的には、パーセントエンコーディングではスペースが%20となるのに対して、application/x-www-form-urlencodedでは+になるらしい
こういうめんどくさい差異って、ブラウザとかプログラミング言語のなかで勝手に改変されて処理されてそうだけど、実際の実装はどうなってるんだろう
仕様
仕様を調べてみる
HTML4では、x-www-form-urlencodedの項に、+にしろと書いてる
living standardでは、application/x-www-form-urlencoded serializingっていうのがあって、そこに符号化の仕様が書いてある。
serializerの項からたどっていくと、
If spaceAsPlus is true and byte is 0x20 (SP), then append U+002B (+) to output and continue.
とある。どうやら、spaceAsPlusという変数がtrueならspaceをplusに変換するらしい。spaceAsPlusはデフォルトではfalseになっているらしい(参考)ので、スペースは普通に%20で表現することに統一されていそう
スペースは普通に%20で表現することに統一されていそう
と思ったら、URLSearchParams classでは、+に変換されるらしい。内部的にはapplication/x-www-form-urlencodedのフォーマットを使うって書いてあるから、spaceAsPlusをtrueにするってことかな
URLオブジェクトのほうは、変なことしないくせに、URL SearchParamsのほうはいろいろといじるから、ビックリするよねって書いてある。たとえば、こんな感じになるらしい
const url = new URL('https://example.com/?a=b ~');
console.log(url.href); // "https://example.com/?a=b%20~"
url.searchParams.sort();
console.log(url.href); // "https://example.com/?a=b+%7E"
ブラウザでの実装
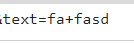
chrome,firefox,Egge,IEで試してみたけど、すべて+に変換されてた。x-www-form-urlencodedを使うと、serializerにspaceAsPlusが渡されるみたい?
サーバーサイドでの実装
こちらはやると際限が無くなるので、記事を貼るだけ
古めだけど、node,python3,goについて書かれてる
メンテナンスされてそう。解説とPHP,Javaについての記述がある
結局、URLとかで使うパーセントエンコーディングと、x-www-form-urlencodedのときに使うパーセントエンコーディングが違うという事実はわかった。
なんでそうなったかっていう発端の理由と、このよくわからない仕様がそのままになっている理由はわからなかった。
parserのほうをそのままにしておけば、serializerのほうは+に変換しないようにしても問題なさそう。
それをしてない理由は、後方互換性しか思いつかない
具体的には、サーバー側のparserで、+を直接spaceに変換してて、%20に対する処理がない実装が壊れちゃうからとか?(そんなのあるのか?)
POSTとGETの使いどころ
秘密情報をPOSTで送信するべきという理由として、以下が挙げられている
- ブラウザのクエリ文字列のデータ量上限に引っかかる
- URL上に指定されたパラメータがReferer経由で外部に漏洩する
- URL上に指定されたパラメータがアクセスログに残る
- URL上のパラメータがブラウザのアドレスバーに表示され他人にのぞかれる
- パラメータつきのURLを利用者がソーシャルネットワークなどで共有してしまう
ブラウザのクエリ文字列のデータ量上限に引っかかる
各ブラウザの上限はどれくらい?amazonとかだと結構長いURLになっちゃうけど
自分で調べなきゃって思ったら、いい感じ更新日の記事があった
RFC上では8000文字までは対応できることが望ましい的なことが書かれているわけですね。(そして相変わらず上限は設けられてない)
らしくて、主要ブラウザでは大体対応しているとのこと
また、以下のことにも注意が必要
URLの長さ上限という要素にはサーバ側アプリケーションやNW機器の対応といった要素もある
たとえばnodejsで調べてみると、80KBらしい。つまり8万文字くらいが上限だから、困ることはなさそう
#ifndef HTTP_MAX_HEADER_SIZE
# define HTTP_MAX_HEADER_SIZE (80*1024)
#endif
ネットワーク機器については調べ方がよくわからなかった。送信元ホストでパケット分割してるはずだから、引っかかることってあるのか?
ちなみにIEは2083文字までだったらしい
amazonで適当に開いた商品ページの文字列長が644文字だったから、まあ普通にブラウジングするには問題なかったっぽい?
URL上に指定されたパラメータがReferer経由で外部に漏洩する
この外部ってどこのことだろう
盗聴された場合第三者に漏洩する…って思ったけど、HTTPSなら問題ないはずだし、盗聴されたら秘密情報が分かるのはPOST通信のBODYに入れるのでも同じ
機密情報をRefererに持つのは、機密情報を持つページからリクエストを送信するとき。だから、そのページから外部へリクエストを送るような実装をしていたら、相手先のサーバーにその情報が残ってしまうというシナリオが考えられるかな
たとえば、画像とかをクラウドサービス上に保持している場合は多そう。あるいは広告とかを出してる場合もそう
あとは、他の脆弱性を使って強制的に遷移させる場合とか?
そういうのができそうなのは、XSSしか知らないけど、XSSできるならReferer使わなくてもそのまま現在のURLを送信すればよさそう。
まあ、ほかにも強制遷移させる脆弱性はありそう
URL上に指定されたパラメータがアクセスログに残る
これは、ひとつ前のReferer経由と違って、サーバー管理者側が利用者のプライバシーを侵害できる、という話?アクセスログをみれば好きなようにユーザーとしてアクセスできたりするから、管理ポリシー的によくないっていう話だと理解した
あとは、サーバーに侵入されたときとかのリスク管理?
URL上のパラメータがブラウザのアドレスバーに表示され他人にのぞかれる
socail hacking
URLに表示させるな、ってはなしではあるけど、セキュアなブラウザとかだとURL表示をしない設定とかができたりする?のかな?
パラメータつきのURLを利用者がソーシャルネットワークなどで共有してしまう
全然ありそう
hiddenパラメータ
すぐに書き換えられちゃうよっていうはなし
proxyとか使わなくても直接開発者ツールでHTMLを書き換えちゃうのでもよさそう
ここで言ってるのは、多分悪意を持った登録者が変なデータを送る、という攻撃のことだと思う。たとえばXSSとか。
hiddenパラメータを処理する部分に脆弱性がある場合
というのは、最初に送られてhiddenパラメータを伴った確認画面を返すときにHTMLエスケープとかのバリデーションを実行したから、hiddenパラメータが送られてきたときには処理しなくていいや、みたいな場合のことかな
hiddenパラメータの使いどころ
hiddenパラメータと対比されるものとして、クッキーやセッション変数を挙げている。この二つは、クッキーモンスターバグにより、セッション変数の漏洩に対する効果的な対策がない。
そのため、利用者自身によっても書き換えらえては困る情報(セッションIDとか?)以外は、hiddenパラメータに保存して、サーバーサイドで利用者が不正な値を入力していないか検証する方式のほうがよいらしい
SPAとhiddenパラメータ
SPAについて特に記述があったわけではないけど、ちょっと考えてみる
自分はSPAでしか開発をしたことがないから、hiddenパラメータなんて使ったことがない。SPAは、(疑似)ページ遷移を跨いだデータ共有ができるため、hiddenパラメータとかを使わなくても確認画面の表示ができる。
一方で、UX向上のために入力内容に対して細かいリクエストを送信してフロント側でバリデーションをする場合が多いから、サーバーサイドでのバリデーションを忘れてしまうことはありそう(hiddenパラメータでのバリデーションを忘れるように)
Basic Auth
Basic認証ってHTTPの機能だったんだ
認証後Authorizationヘッダが自動で付与される条件
認証後、Authorizationヘッダが自動で付与される場合とされない場合の差が気になる
本によると、認証したpath以下のディレクトリへのリクエストには自動で付与されると書いてある。
が、自分が利用しているサービスで試してみたところ、/auth/auth2にアクセスした後に、/auth/にアクセスしても付与されていた
RFCを見る
どうやら、認証した際のpath部分を見て、最後の/以降の文字列を取り除いたpathに含まれるディレクトリを認証スコープとして、authorizationヘッダを再利用するらしい
実際に、/auth/auth2/で認証したあとに、/auth/にアクセスしてもAuthorizationヘッダがついていないことが確認できた(Chrome)
ヘッダがなくても認証される
ただ、上の条件でやると、Authorizationヘッダがついていなくても、/auth/ページが表示できてしまっている。普通にやったときはきちんと認証がかかるはずなのに…
考えられる可能性としては、
- 検証画面には表示されていないだけで、ブラウザがリクエスト時にAuthorizationヘッダを付与してるor
- Basic認証も、Authorizationヘッダ以外のヘッダとか、なんらかの方法でセッション管理をしている
二つ目はさすがになさそう。baisc-auth系のライブラリ見てみても、そんな処理は無かった。(見てみたのは、nodeのやつ)
一つ目の可能性が濃厚だけど、ちょっと気軽に検証できる方法が思いつかないので、また今度…
と思ってたら、/auth/auth2/で認証したあとに、/auth/にアクセスしたらAuthorizationヘッダがついてる例を見つけてしまった。んー、ということはブラウザ側の処理じゃなくて、サーバー側の処理が影響しているのか?
突っ込んでいくとまじで沼りそうなので、ここで撤退
Cookieとsession id
セッションIDの要件として
- 第三者がセッションIDを推測できないこと
- 第三者からセッションIDを強制されないこと
- 第三者にセッションIDが漏洩しないこと
第三者がセッションIDを推測できないこと
わかる。どれくらい質のいい乱数にできるかが問題
フレームワーク謹製の生成器、管理機構を使うが吉
第三者からセッションIDを強制されないこと
セッションIDの固定化ってこういうことか。本に書いてある例がわかりやすかった
認証前にSessionIDを指定しておくというのは、具体的にはクッキーモンスターバグなどで入れておくとか?
第三者にセッションIDが漏洩しないこと
主な原因として
- クッキー発行の際の属性に不備がある(domain, secure, HttpOnlyを確認)
- ネットワーク的にセッションIDが盗聴される
- XSSなどのアプリケーションの脆弱性により漏洩する
- PHPやブラウザなどプラットフォームの脆弱性により漏洩する
- セッションIDをURLに保持している場合はReefererヘッダから漏洩する
Cookie の属性について
Domain
domain属性を指定しない場合、どういう風に保存されているのかが気になった
手元でdomain属性を指定するものと指定しないものを作って試してみると、どちらも開発者ツール上では、domain=localhostと表示されていた。
google analyticsで使ってるcookieだと、.example.comというように、先頭に.がついているから、それで判断しているのかと予想していたが、どうやら内部的に値をもっているよう
先頭の.について
もう少し調べてみた
歴史的な理由から、domain=.site.com (ドット開始)もこのように機能します。非常に古いブラウザをサポートするにはドットを追加しておくのがよいでしょう。
https://ja.javascript.info/cookie
というサイトがある一方で、MDNは以下のように言っている
初期の仕様書とは逆に、ドメイン名の前のドット (.example.com) は無視されます。
https://developer.mozilla.org/ja/docs/Web/HTTP/Headers/Set-Cookie#属性
また、手元でSet-Cookieを使って.localhostをセットしようと試してみたら、
Chrome: セットされない(開発者ツールでは、Responseヘッダの横に黄色三角の警告マークがでる)
Firefox: セットされるが、最初の`.`は削除される(MDNのいう通り)
という結果になった。
さらに、コンソール上からdocument.cookie="wow=wos; doamin=.localhost"を実行すると
Chrome: `.`が削除されて`localhost`でセットされる
Firefox: `.localhost`で登録される
という結果になった
んー、ChromeでGoogle Analyticsがドット付きのパラメタを登録してるんだけど、どうやってるんだろう。
一応結論
ドメイン属性が指定されているかどうかは、内部的に値が保存されているっぽい
.はつけなくていい。逆につけるほうが難しい?
訂正
localhostで試すのはよくなさそう
exapmle.comとかの普通のサイトでdocument.cookieをdomain=example.comでセットしたら、.example.comっていうふうに.がついた(Chrome)
実際の環境で試せるようにproxyが使えるツールを入れたほうがよさそうだけど、とりあえず後回し
Secure属性
開発環境では普通http通信で開発をするから、そのままデプロイしてsecureがついていない…ってことがありそう
と思ったら、jsのフレームワークであるexpressでは、リクエストがHTTP通信だったらfalseにして、HTTPS通信だったらtrueに自動でしてくれるらしい
ある程度気が利くフレームワークだったら大体こういうのをやってくれてそう
HttpOnly属性
XSSによるCookieの送信などを難しくするらしい(完全に防ぐことはできないとのこと)
phpでは、php.iniのデフォルト設定だとHttpOnly属性がつかないっぽい
逆にnodejsのフレームワークであるexpressだと、デフォルトでHttpOnlyがつくっぽい
まあ実行環境とフレームワークを比べるのはおかしい気もするけど
HttpOnlyを使わないほうがいい場合
徳丸本では、HttpOnlyをつけて悪影響がでることは通常ない、と言っていたけど、逆に通常じゃない場合はなにがあるのか。
当然思いつくのは、フロント側でcookieを利用したいとき。ただ、Cookieはデータを送信するためのものではないから、jsで使いたいとしたら設計を間違えてる可能性が高そう?
JWTとかだと、Cookieに入れたTokenをフロント側でparseしたりすることもあるんだっけ?これは適当なので、また時間があるときに調べる
cookie monster bug
極端に言えば、ドメイン属性を.comにしてcookieを登録できる。セッション固定化攻撃などに使われる
レンタルサーバーのドメインを使っている場合はどうしようもない。
しかし、.comなどの普通のユーザーが登録できないようなドメインは、ドメイン属性に設定できないようにブラウザがガードしている。
どういう風に管理しているのかと思って調べてみたら、どうやらリスト形式になっているよう
Mozillaが主導しているらしく、サイトの説明によるとFirefox,Chronium,Opera,IEなどで使われていることを把握しているらしい。Safariは?
tokyo.jpなども登録されていた。
徳丸本に載っていたWindows7とかのクッキーモンスターバグは、このリストがハードコードされて更新できなかったから、とか?
CORS
クロスオリジンのリクエストでは、withCredentialをつけないと、Cookieのセットも送信もできない(なんとなくサーバー側からのCookieのセットはできると思ってた)
4章に入ると文字コードについての記述があったが、そこらへんの知識がないのであまりイメージがつかず。6章で詳細に説明するとのことだったので、先に6章を読む
XSS
HTMLのclassを"で囲まなくていいのをはじめてしった
たぶんモダンなフレームワークなら意識しなくてもいいように設計されてる。たとえば、vue は、動的なクラスを指定するときは
:class="value"
として、jsの文字列を代入する。この場合、常にダブルクォーテーションがついた状態になる。また、文字列のなかに"を含めてみても、きちんとエスケープされているようだった。
また、エディターでも基本的に自動補完される。
XST method
HTTP の TRACE メソッドと XSS を組み合わせる方法
現代では、ブラウザでjsを使ったTRACEメソッドのリクエストは禁止されているみたい
living standard でもA forbidden methodとしてエラーを投げるように定められている
HTML escape
&をエスケープする理由
普通の文字列で、<とかが出てきたときに、>とかに変換されてしまうから。普通のバックスラッシュを入力するために、バックスラッシュでエスケープするのと同じノリ。
URLスキーマ
hrefとかには、http、https だけじゃなくて、javascript, vbscript も指定できる。
HTTP Header Injection
node の cookie ライブラリに HTTP Hearder Injection の脆弱性があるかどうかを調べてみた。対象のライブラリは、これで、express とかでも使われてるやつ。
結論としては、改行が入ってるとエラーになるみたい。cookie の value を
var fieldContentRegExp = /^[\u0009\u0020-\u007e\u0080-\u00ff]+$/;
で検証している。改行コードは、\u000A(LF)と\000D(CR)なので、上の正規表現には含まれていない。
また、node 本体の API である、setHeaderメソッドでも、同じようにバリデーションされていた。