【GPT Crawler】URLのみでGPTsを作成!
🌐 GPT Crawler: Create GPTs with Just a URL! : URLのみでGPTを作成!
こんにちは、皆さん!今回はGPT Crawlerを使ってURLのみでGPTsを作成する方法を紹介します。
リポジトリのリンクはこちらです。
私が改変したものはこちらです。アップデートしたら記事も更新します。
🎓 はじめに: Introduction
GPTsって革命的なんですけど、GPT Plusに登録していてもファイルの数が10個までと制限されていたり、まだまだ使いづらい部分がありますよね。
少ないファイル数で効率的に狙った質問を返してもらうには、データを加工した上でアップロードする必要があります。
このGPT Crawlerでは、指定したURLの情報をクローリングして、GPTsにアップロードするための加工されたデータを作成します。
オープンソースでMITライセンスなので、自由に改変できます。
なので、今回私がより使いやすくするために作成したものも、同時に紹介します。
早速使ってみましょう!
🛠️ How to Use: 使い方
まずはリポジトリをクローンします。
公式:
git clone https://github.com/builderio/gpt-crawler
私の改変版:
git clone https://github.com/yuyuyu2118/gpt-crawler-y
次に、プロジェクトのディレクトリに移動します。
cd gpt-crawler
改変版の場合は
cd gpt-crawler-y
次に、下記のコマンドで必要なパッケージをインストールします。
npm i
もしくは
npm install
また、プロジェクト内のconfig.tsを開くと、下記のようになっています。
import { Config } from "./src/config";
export const defaultConfig: Config = {
url: "https://www.builder.io/c/docs/developers",
match: "https://www.builder.io/c/docs/**",
maxPagesToCrawl: 50,
outputFileName: "output.json",
};
上記の内容は必須ですが、他の項目も設定できます。
各項目について、下記に説明します。
type Config = {
// クロールを開始するURL
url: string;
// このパターンに一致するリンクのみをクロール対象とする
match: string | string[];
// このセレクタで指定された要素からインナーテキストを取得する
selector: string;
// 最大でこの数のページをクロールする
maxPagesToCrawl: number;
// クロール結果を保存するファイル名
outputFileName: string;
// 必要に応じて設定されるクッキー
cookie?: { name: string; value: string };
// 各ページ訪問時に実行されるオプショナルな関数
onVisitPage?: (options: {
page: Page;
pushData: (data: any) => Promise<void>;
visitPageWaitTime?: number;
}) => Promise<void>;
// セレクタが表示されるまで待機するオプショナルなタイムアウト
waitForSelectorTimeout?: number;
};
私の改変版では、11/22現在、下記のような項目を追加しています。
type Config = {
// 省略
// 使用するオプショナルなユーザーエージェント
userAgent?: string;
// 各ページの読み込み間のオプショナルな待ち時間
waitTime?: number;
};
実際の設定では、下記のように書きます。
import { Config } from "./src/config";
export const defaultConfig: Config = {
url: "https://www.builder.io/c/docs/developers",
match: "https://www.builder.io/c/docs/**",
maxPagesToCrawl: 50,
outputFileName: "output.json",
};
改変版では、デフォルトでこのようになっています。
import { Config } from "./src/config";
export const defaultConfig: Config = {
url: "http://www.nikkei.com/",
match: "http://www.nikkei.com/**",
maxPagesToCrawl: 50,
outputFileName: "output.json",
// ここから下は任意
waitTime: 1000,
onVisitPage: async ({visitPageWaitTime }) => {
// ここでのカスタム処理を記述
await new Promise(resolve => setTimeout(resolve, visitPageWaitTime ?? 1000));
},
// userAgentを設定するなら、下記のように記述
// userAgent: "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
};
これで事前準備は完了です。
▶️ How to Run: 実行方法
事前準備が完了したら、アプリケーションを起動します。以下のコマンドは start:dev スクリプトを呼び出し、build スクリプトを実行してTypeScriptのコンパイルを行った後、開発者モードでアプリケーションを起動します。
npm start
改変後の場合は、上記のコマンドか下記のコマンドで起動します。
npm run start:cross-env
起動してしばらく待つと、output.jsonにデータが出力されます。
もう一回実行すると、output.jsonが上書きされますのでご注意ください。
📊 Reviewing the Output Data: 出力されたデータの確認
こんな感じで出力されていればOK!
[
{
"title": title,
"url": url,
"html": html,
},
{
"title": title,
"url": url,
"html": html,
}
]
⬆️ Uploading to GPTs: GPTへのアップロード
出力されたデータをGPTsにアップロードします。
-
https://chat.openai.com/ にアクセスしてログインします。
-
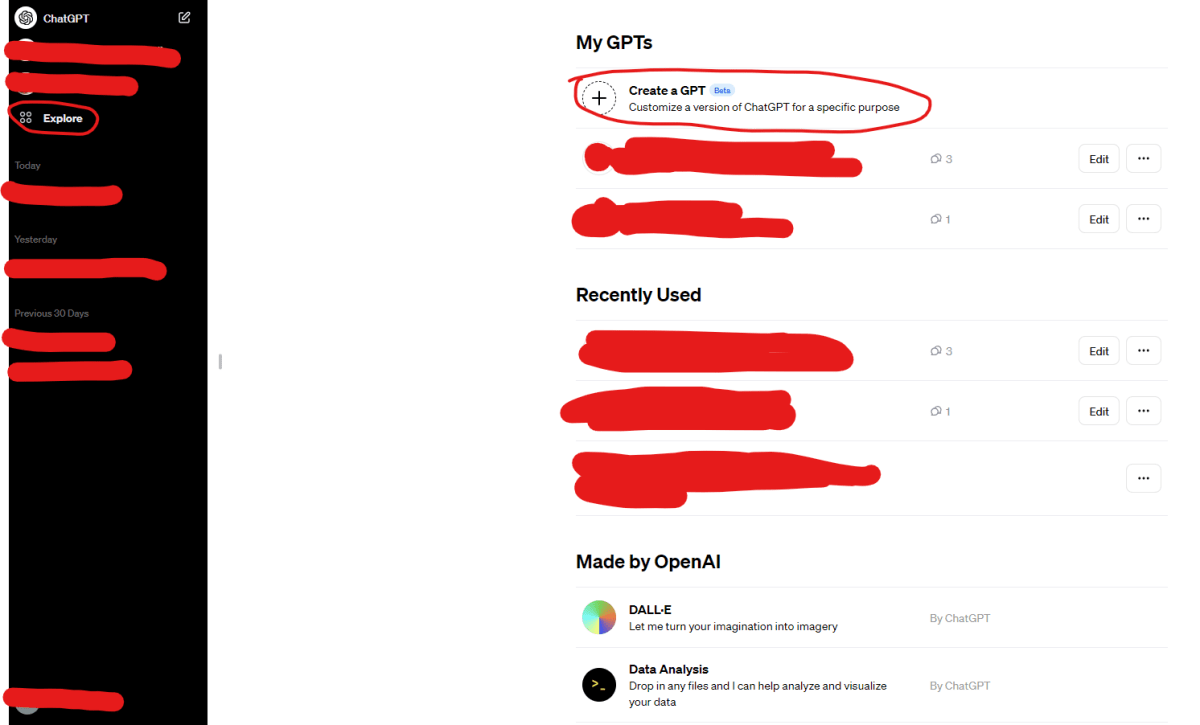
左側のメニューから「Explore」を選択します。
-
真ん中付近の「Create」ボタンをクリックします。
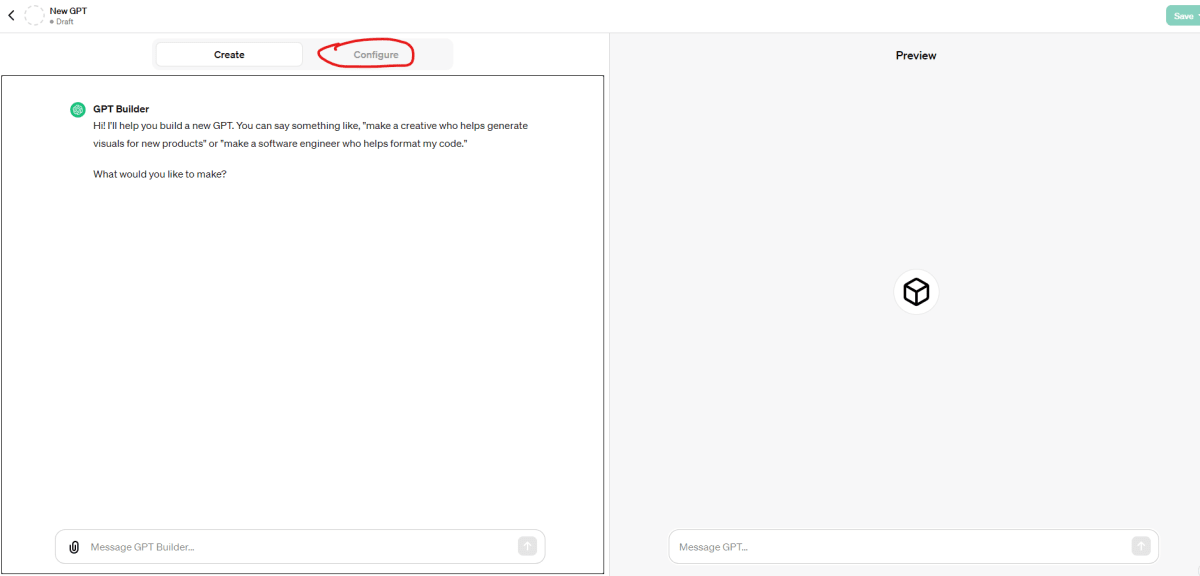
-
「Configure」タブを選択します。
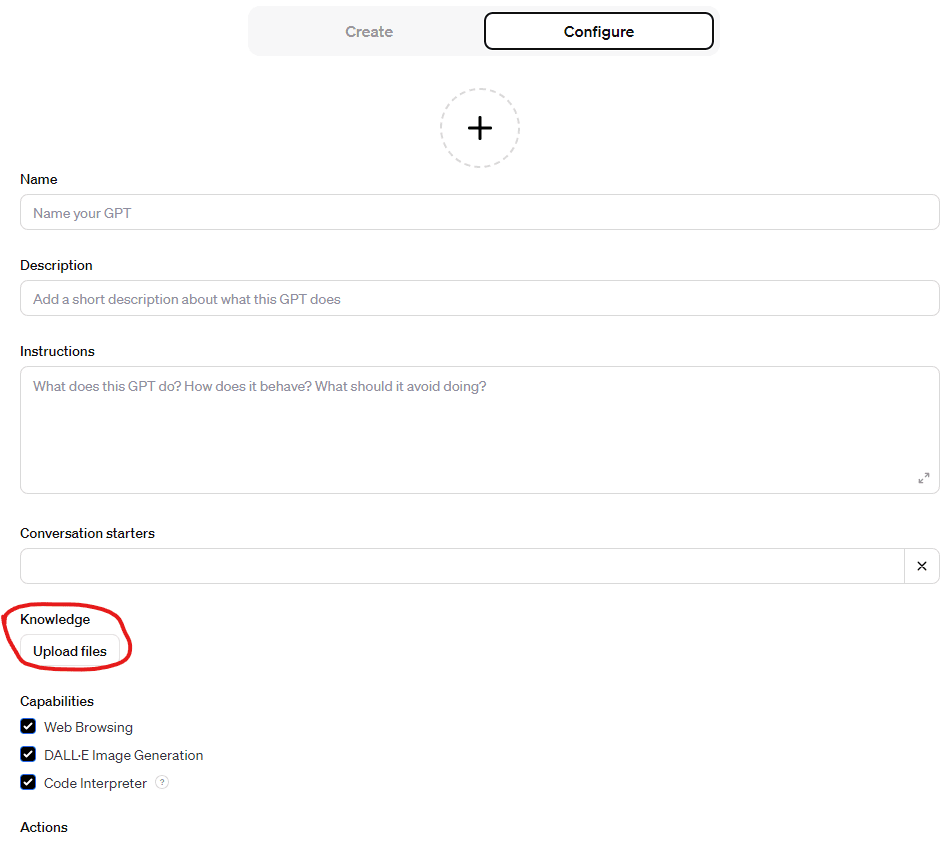
-
「Knowledge」セクションにある「Upload files」ボタンから
output.jsonをアップロードします。
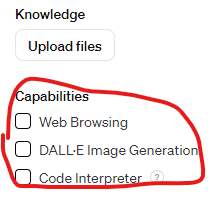
-
必要に応じて、「Capabilities」セクションで「Web search」の設定をオフにすることもできます。
この時点で以下のような質問をすると、回答が返ってきます。

ちょっとoutput.jsonにアクセスするようになっていないので、質問を変えてみます。

以上で、アップロードが完了し、カスタムGPTを使って質問に答えられるようになります。さらに、「Create」タブから自然言語で追加設定を行い、output.jsonから情報を参照するように構成することも可能です。
📝 Summary: まとめ
改変前のリポジトリも、改変後のリポジトリもcloneしてURLを書き換えるだけで簡単に活用することが可能です。英語に不慣れな方のために、日本語で翻訳されたREADMEファイルに差し替えています。
また、リポジトリのフォーク元はこちらになります!!
Builder.io 様、「GPT Crawler」プロジェクトを開発し、オープンソースとして公開していただき、改めて感謝申し上げます。
さ
Discussion