Kubernetes モニタリング用メトリクスまとめ
概要
Kubernetesのモニタリング対象のメトリクスについてまとめていきいます。
参考
Kubernetesの主要オブジェクト
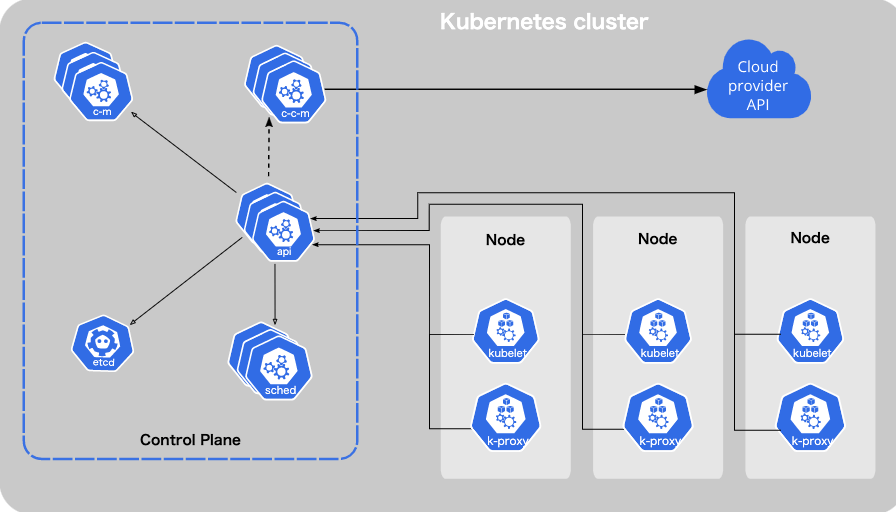
Kubernetesクラスターのコンポーネント
主要な二つのNodeタイプ
- Control Plane Node: クラスターの管理をする。クラスターのステートをetcdキーバリューストアに記録する。
- Worker Node: ホストVM。それぞれがkubeletと呼ばれるプロセスを持つ。kubeletはworker nodeを監視して、worker nodeとControl Planeの通信の窓口として振る舞います。kubeleteがControl Planeからのリクエストを受け取りworker nodeのruntime環境に指示してpodの作成や管理をします
Pod: 1つまたは複数からなるコンテナでストレージとネットワークリソースとコンテナの起動方法に関する仕様を共有します。
Kubernetesのメトリクスの取得場所
Kubernetesエコシステムでは2つのアドオンによりメトリクス収集をする方法が提供されています。
- Metrics Server: それぞれのNode上のkubeletからMetrics APIを経由してリソース使用メトリクスを収集して提供します。Metrics Serverはニアリアルタイムメトリクスのみをメモリに保持します。
- kube-state-metrics: 容易に扱い可能なクラスタのstate情報を提供してくれるサービスです。Metrics ServerがpodやNodeのメトリクスを提供するのに対して、kube-state-metricsはKubernetesオブジェクト全体(nodeやpod,Deploymentなど)のメトリクスをControl Plane APIから取得して提供します。
Kubernetes監視用の主要なパフォーマンスメトリクス
監視対象メトリクスとして三つのカテゴリのメトリクスがKubernetesではあります。
- クラスターStateメトリクス
- nodeやpodのリソースメトリクス
- Control Planeからのworkメトリクス
その他:Kubernetesのイベント
監視・アラート用メトリクスまとめ
▼クラスターStateメトリクス
| 項目 | メトリクスタイプ | 内容 |
|---|---|---|
| Nodeステータス | アラート用 | Nodeの実行可能状態の検知のため |
| 期待数に対する現在のPod数 | アラート用 | リソース不足のために新規にPodをスケジュールできないというようなボトルネックを検知できるようにこの値をアラートします |
| 実行可能と実行不可なPod数 | 監視用 | readiness probesなどの設定の見直しのチェックなどに利用します |
▼リソースメトリクス
| 項目 | メトリクスタイプ | 内容 |
|---|---|---|
| Pod毎の最大メモリ量に対するメモリ使用量 | アラート用 | Nodeの実行可能状態の検知のため |
| メモリ使用量 | アラート用 | OOMによるPodのkillの防止やリソース不足の際の見直しなどに利用 |
| ディスク使用量 | アラート用 | Disk容量低下がPodのスケジューリングに影響があるため |
| ノード毎のCPU最小容量(request)に対するNode毎の割り当て可能なCPU量 | 監視用 | クラスタのキャパシティプランニングなどに活用 |
| Pod毎のCPU最大容量(limit)に対するPod毎のCPU使用量 | 監視用 | 十分なCPUリソースが割り当てられているかを確認します |
| CPU使用量 | 監視用 | クラスターのパフォーマンスの把握に利用します |
▼Control Planeメトリクス
| 項目 | メトリクスタイプ |
|---|---|
etcd_server_has_leader |
アラート用 |
etcd_server_leader_changes_seen_total |
監視用 |
apiserver_request_latencies_countとapiserver_request_latencies_sum
|
監視用 |
workqueue_queue_duration_secondsとworkqueue_work_duration_seconds
|
監視用 |
scheduler_schedule_attempts_totalとend-to-endのスケジューラーのlatency |
監視用 |
以降ではそれぞれのメトリクスの詳細について記載していきます。
クラスターStateメトリクス
Kubernetesの内部プロセスはKubernetes APIサーバが出しているデータ(podのようなKubernetesオブジェクトの数やヘルス、実行可能性など)を利用してPodが正常に期待通り起動しているかどうかをトラックしたり新規にPodをスケジュールしたりしています。
加えてクラスタStateメトリクスはクラスタとクラスタのStateの高レベルの情報を提供します。
kube-state-metricsアドオンはkubectl cliよりもより扱いやすい形で次のようなメトリクスを提供してくれます
| メトリクス | kube-state-metricsでのメトリクス名 | 内容 | メトリクスタイプ |
|---|---|---|---|
| Nodeステータス | kube_node_status_condition |
Nodeの現在のステータス(true,false又はunknown) |
Resource:Availability |
| Podの期待数 |
kube_deployment_spec_replicas又はkube_daemonset_status_desired_number_scheduled
|
Deployment又はDaemonSetで指定されたPod数 | Other |
| 現在のPod起動数 |
kube_deployment_status_replicas又はkube_daemonset_status_current_number_scheduled
|
Deployment又はDaemonSetで実行中のPod数 | Other |
| 実行可能Pod数 |
kube_deployment_status_replicas_available又はkube_daemonset_status_number_available
|
Deployment又はDaemonSetにおける現在利用可能なPod数 | Resource:Availability |
| 実行不可なPod数 |
kube_deployment_status_replicas_unavailable又はkube_daemonset_status_number_unavailable
|
Deployment又はDaemonSetにおける現在利用不可なPod数 | Resource:availability |
アラート対象メトリクス
Nodeステータス
Kubernetes Nodeには次のようなステータスが定義されています。
OutOfDiskReadyMemoryPressurePIDPressureDiskPressureNetworkUnavilable
それぞれの項目はtrue,false又はunknown(グレースperiodの間Control PlaneとWorker Nodeが通信ができない状態)のいずれかを返します。
特にReadyとNetworkUnavailableの項目はNodeが実行可能かどうかを示すのでアラートすべきメトリクスになります。
MemoryPressureとDiskPressureの項目がtrueを返す場合、kubeletはリソースを再利用しようとします。
期待数に対する現在のPod数
マニフェストで定義した期待するPodの実行数に対して、
現在実際どれくらいの数のPodが起動できているのかをアラートするようにします。
Pod数低下の際にリソース不足でリクエストがさばけなくなるなどの事態に備えるようにします。
監視対象メトリクス
実行可能と実行不可なPod数
この値を監視することで readiness probsのようなPodの実行可能チェックに利用するヘルスチェックの設定に不備があれば修正するようにします。

リソースメトリクス
マニフェストで定義したリソースrequestやlimit量と実際のリソース使用量を比較することでクラスターが不可に対して適切なリソースを割り当てられているかを確認します。
NodeやPodなど複数の異なるレイヤーごとのリソースを監視することが重要です。
| メトリクス | kube-state-metricsでのメトリクス名 | 内容 | メトリクスタイプ |
|---|---|---|---|
| 最低メモリ量(memory request) | kube_pod_container_resource_requests_memory_bytes |
podの合計の最低メモリ量(byte) | Resource:Utilization |
| 最大メモリ量(memory limit) | kube_pod_container_resource_limits_memory_bytes |
podの合計の最大メモリ量(byte) | Resource:Utilization |
| 割り当て可能メモリ量 | kube_node_status_allocatable_memory_bytes |
Nodeでの割り当て可能なメモリ量(byte) | Resource:Utilization |
| メモリ使用量 | N/A | Node又はPodの合計メモリ使用量 | Resource:Utilization |
| CPU request | kube_pod_container_resource_requests_cpu_cores |
podの合計CPU request量 | Resource:Utilization |
| CPU limit | kube_pod_container_resource_limits_cpu_cores |
podの合計CPU request(cores)量 | Resource:Utilization |
| 割り当て可能CPU | kube_node_status_allocatable_cpu_cores |
Node上での割り当て可能な合計CPU (cores)量 | Resource:Utilization |
| CPU utilization | N/A | 1つのNode又はpodにおけるの合計CPU使用量 | Resource:Utilization |
| Disk utilization | N/A | 1つのNode又はpodにおけるの合計Disk使用量 | Resource:Utilization |
アラート用メトリクス
pod毎の最大メモリ量とpod毎のメモリ使用量
- Node上で実行されているPodの制限の合計値がNodeの割り当て可能なメモリ合計値を超えているケースもありえます。
- K8sではPodのメモリ使用量がメモリ制限量を超えると(Out of memory)Podがkillされます。これを防ぐために、十分な容量のメモリをPodに割り当てる必要があります。
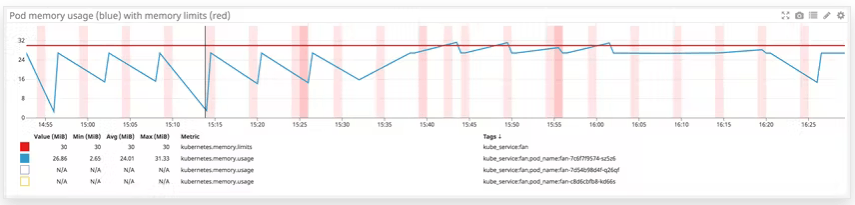
maxメモリ量に対するメモリ使用量のグラフ。メモリ使用量がmemory limitに近づくにつれ、OOM killedが発生
メモリ使用量
▼理由
メモリ使用量が低下するとkubeletは対象のPodをevictして、Control Plance容量に余裕がある他のNode上にPodを新規に作成します
加えて定常的なメモリ不足はPodのリソース設定が正しく行われていないことを示唆します
(補足:Nodeレベルでメモリ使用量が多い場合は、クラスターに新規にNodeを追加する必要があります)
ディスク使用量
▼理由
メモリと同様に非圧縮生のリソースであるため
- Disk容量が低下するとPodのスケジューリングに影響が出ます
-
Node Statusに使用量低下とフラグ表示されます
▼Nodeにおけるディスク空き容量低下に対するデフォルトのリソース閾値
| ディスクプレッシャーシグナル | 閾値 | 内容 |
|---|---|---|
| imagefs.available | 15% | ファイルシステムimagefsの利用可能な空き容量。イメージとcontainer-writableレイヤーに使用される。 |
| imagefs.inodesFree | 5% | ファイルシステムimagefs用の利用可能なインデックスNode |
| nodefs.available | 10% | ルートファイルシステムの利用可能なディスク空き容量 |
| nodefs.inodesFree | 5% | ルートファイルシステムの利用可能なインデックスNode |
監視対象メトリクス
ノード毎のCPU request量に対するNode毎の割り当て可能なCPU量
メモリと同様に、割り当て可能なCPU量はPodのスケジュールに使われるNodeのCPUリソースを反映します。
クラスタのキャパシティプランニングに有用でクラスタがより多くのPodをサポートできるかどうかの判断に参考にできます。
Pod毎のCPU limit量に対するPod毎のCPU使用量
メモリと違ってCPU limitを超えてもpodは削除されず起動し続けることができますが、高CPU使用はパフォーマンスの劣化につながっている可能性があるので、負荷に対して十分なCPUを割り当てられているかのチェックのためにこのメトリクスを監視するようにします。
CPU使用量
NodeレベルでのCPU使用量のトラッキングはクラスターのパフォーマンスの把握に重要です。
Control Planeメトリクス
マネージドKubernetes環境(ex: GKEやEKSクラスターなど)ではこれらのメトリクスにアクセスできなかったり、違うメトリクス名で使用されていたりするので注意が必要です。
| メトリクス | 内容 | メトリクスタイプ |
|---|---|---|
etcd_server_has_leader |
クラスタのメンバーにleadeがあるかどうか。(存在する場合は1を、存在しない場合は0) |
Resource:Availability |
etcd_server_leader_changes_seen_total |
Text | Other |
アラート対象メトリクス
etcd_server_has_leader
etcdクラスターのメンバーがetcd_server_has_leaderの値を0と返却した場合(大抵はネットワークの問題が原因で)、etcdクラスターのメンバーはleaderを認識できずクエリをサーブすることができません。その結果、全体のetcdクラスターがダウンしてしまいます。
key-valueストアのetcdの失敗によりKubernetesに必要なクラスターオブジェクトのstateに関する情報が奪われて、そしてKubernetesはクラスターのステートを変更することができなくなってしまいます。
クラスタ操作におけるクリティカルな役のため、etcdは障害シナリオを軽減するためのスナップショット及びリカバリ操作を提供しています。
監視対象メトリクス
etcd_server_leader_changes_seen_total
etcd_server_leader_changes_seen_totalはクラスターにおけるleaderのトランジション数をトラックするメトリクスです。
頻繁のleaderの変更はetcdクラスターにおいて接続性やリソース制限の問題の喚起になるため監視するようにします。
apiserver_request_latencies_countとapiserver_request_latencies_sum
Kubernetesはそれぞれリソース(ex:podやDeployment)とAPIメソッド(GET,LIST,POST,DELETE)の組み合わせ毎にAPIサーバーへのリクエスト数とレイテンシに関する指標を提供します。
あるタイプのリクエストに対する合計のレイテンシをそのタイプのリクエスト数で割ることでリクエストあたりの平均のレイテンシを算出することができます。
リクエストの数とレイテンシをトラッキングすることで、クラスタがユーザーの作成や削除、又はリソースに対するクエリなどの初期コマンドの実行に失敗しているかどうかをチェックすることができます。
workqueue_queue_duration_secondsとworkqueue_work_duration_seconds
workqueue_queue_duration_secondsはあるキューでアイテムがどれくらいの時間処理を待っているかのを示すメトリクスです。
workqueue_work_duration_secondsは実際にそれらのアイテムを処理するのにどれくらいの時間を要したかを示すメトリクスです。
コントローラーの自動化されたアクションにレイテンシーの増加が見られ始めたら、その原因の詳細をより集めるためにcontroller managerのログで確認することができます。
scheduler_schedule_attempts_totalとend-to-endのスケジュールのlatency
Nodeにおけるpodのスケジュールの全体の試行数とこれらのスケジュールの実行のend-to-endのlatencyを計測することでKubernetesのスケジューラーの実行をトラッキングすることができます。
scheduler_schedule_attempts_totalはスケジューラーの試行の結果(error,schedulable又はunschedulable)を明らかにするためワーカーNodeに対するPodのマッチングの問題を特定することができます。
unschedulablePodの増加はクラスターが新規Podの起動に必要なリソースを不足していることを示唆します。errorはスケジューラー自身に問題があることを示唆します。
end-to-endのlatencyのメトリクスはNodeに対応するPodの選択にどれくらいの時間を要しているのかをリポートするメトリクスで、さらにクラスターに適用できるようにスケジュールを決定するAPIサーバーへの通知にどれくらいの時間を要しているのかもレポートします。
Podの期待数と現在の実行数とに不一致がある場合、これらのlatencyのメトリクスを確認することでスケジューリングの問題が遅れているかどうかを確認できます。
Kubernetesイベント
Kubernetesやコンテナエンジンからのイベントを収集することで、
Podの作成、削除、開始又は停止がインフラのパフォーマンスにどれくらい影響を与えているかを見ることができます。
例えばKubernetesのPending Podと失敗したPodをトラッキングすることでマニフェストの設定ミスやNodeのリソース飽和問題に気づくことができます。
Discussion