Kubernetes DrainとPod Disruption Budget(PDB)
概要
個人の備忘録としてKubernetesのDrainとDisruptionについてまとめていきます。
参考
Drain
kubectl drainコマンドを利用することでノードをメンテナンス(ex:カーネルの更新やハードウェアの更新など)する前に安全にノード上の全てのPodを削除できます。Drainによる安全な削除はPodコンテナをgraceful shutdownやPDB(後述)を考慮した削除をすることができます。
kubectl get nodes
kubectl drain <node name>
上記コマンドがエラーなく実行できた場合、ノードを停止できたことになります。
メンテナンス中にノードをクラスター内に残す場合、次のコマンドを実行する必要があります。
kubectl uncordon <node name>
上記を実行することにより、ノード上の新しいPodにスケジュールを再開するようにKubernetesに指定できます。
Voluntaryとinvoluntary disruptions
Podはユーザーやコントローラーが削除しない限り、又は不可避なハードウェア又はシステムソフトウェアのエラーが発生しない限りPodは消えたりしません。
Kubernetesではこれらの不可避なケースをinvoluntary disruptionsと呼ばれています。例えば次のようなケースがあります。
- ノードをサポートする物理的なマシーンのハードウェア障害
- クラスターの管理者が誤ってVM(インスタンス)を削除した場合
- クラウドプロバイダーの障害によりVMが削除された場合
- カーネルパニック
- クラスタのネットワーク分割によりクラスタからPodが消滅した場合
- ノードのアウトオブリソースによるPodの削除
前述以外のその他のケースをKubernetesではvoluntary disruptionsと呼ばれています。
アプリケーション所有者により設定されたアクションやクラスタ管理者による設定などを含みます。
例えば次のような典型的なアプリケーション管理者のアクションを含みます
- Podを管理するDeploymentやその他コントローラーの削除
- DeploymentのPodテンプレートの更新による再起動
- (アクシデントを含む)Podの直削除
クラスタ管理者のアクションの例は次のようなものを含みます
- 修正又は更新によるノードのドレイン
- クラスターをすケースダウンするためにクラスターからノードをドレインする場合(参考:Cluster Autoscaling)
- ノードからPodを削除することであるリソースがノードに収まるようにする場合
これらのアクションはクラスタ管理者によって直接実行されるか、クラスタ管理者により自動で実行される場合、又はクラスタのホスティングプロバイダーによって実行される場合があります。
もしクラスタ管理者又はクラウドプロバイダーによるvoluntary disruptionsが起こり得ない場合はPod Disruption Budgetsは作成する必要はありません。
退避処理の対応
involuntary disruptionsに対応するために次ような幾つかの方法があります
- Podが必要なリソースを要求していることを確認すること
- より高い可用性を必要とする場合にアプリケーションをReplicateする
- 既にレプリカされた状態でより高い可用性を必要とする場合、ラック間又はゾーン間(マルチゾーンクラスターを使用する場合)にアプリケーションを分散すること
voluntary disruptionは多岐に渡ります。基本的なKubernetesクラスターでは、自動的なdisruptionはなくユーザー起因のもののみしかありません。しかし、クラスタ管理者やホスティングプロバイダーが起動している追加のサービスによりvoluntary disruptionが発生する場合があります。例えば、ノードソフトウェアの更新をロールアウトするとvoluntary disruptionが発生する場合があります。一部のクラスター(ノード)のオートスケーリングの実装により、デフラグとコンパクトノードのvoluntary disruptionが発生する場合があります。
Pod disruption budget(PDB)
頻繁なvoluntary disruptionが発生している場合に、Kubernetesは高可用性を実現するためにいくつかの機能を提供しています。
アプリケーションオーナーとして、アプリケーション毎にPodDisruptionBudget(PDB)を作成することができます。PDBはvoluntary disruptionにより同時にダウンするレプリカされたアプリケーションのPod数を制限します。例えば、クォーラムベースアプリケーションでは、実行中のレプリカ数がクォーラム以下にならないようにする必要があります。Webフロントエンドの場合では、負荷を処理するレプリカ数が特定の割合を下回らないようにする必要があります。
クラスタ管理者とクラウドプロバイダーは、PodやDeploymentを直接削除するのではなく、Eviction APIを利用してPodDisruptionBudgetを考慮したツールを使用する必要があります。
例えば、kubectl drainサブコマンドはノードをサービス停止としてマークできます。kubectl drain実行すると、サービス停止しようとしているノード上の全てのPodを削除しようとします。kubectlコマンドが送った削除リクエストは一時的に拒否される場合があるため、ターゲット上の全てのPodが終了又はタイムアウトに達するまで失敗した削除リクエストを定期的にリトライします。
PDBはアプリケーションが意図した保持数と比較して、アプリケーションが許容できるレプリカ数を指定します。例えば、Deploymentがレプリカ数を5と指定している場合、PDBが4を指定している場合はEviction APIにより許容されるvoluntary disruptionの数は1となります。
Involuntary disruptionはPDBにより制御することはできません。そしてInvoluntary disruptionによる削除数はbudgetにもカウントされません。
ローリングアップデートにより削除又は利用不可になったPodはdisruption budgetにカウントされますが、DeploymentやStatefulSetのようなワークロードリソースはローリングアップデート時はPDBにより制限されません。その代わりに、アプリケーションの更新中の失敗のハンドリングはworkloadリソースのspecに応じて設定されます。
PodがEviction APIにより削除される場合、PodのspecterminationGracePeriodSeconds設定に応じてPodが正常終了します。
PodDisruptionBudgeの例
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: zk-a
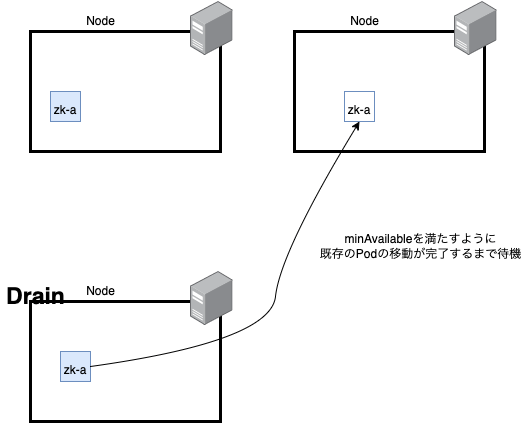
PDBの動作例
Discussion