はじめに
こんにちは!株式会社Sapeetのソリューション事業部でアルゴリズムエンジニアとして働いている堀ノ内です。ソリューション事業部では受託開発を行なっており、近年は生成AIを活用したプロジェクトが非常に増えています。
弊社では開発を迅速に進めるため、PoCの段階ではノーコードツールであるDifyを活用しており、多くのプロジェクトに導入してきました。これまではDifyを単体で使うことが多かったのですが、ノーコードツールであるが故、少し凝った処理をしようとしたり、UIをリッチにしようとすると実現が難しいという課題があります。
こちらの解決策の1つとして、AI周りのワークフローはDifyで構築、それをPythonからAPI呼び出しするという方法が考えられます。これにより頻繁に発生する生成AIのプロンプト、モデル種類やアルゴリズムなどはDify上でスピーディに修正でき、Python側でデータのDB保存、複雑なロジックの実装やWebサーバの構築を行い、任意のUIにAIが処理した結果を表示することができます。
PoCを開発するプロジェクトで実際にこの構成にトライし、多くの学びを得ることができましたので、本ブログではそれらをご紹介したいと思います。これからDifyを活用していきたいと考えている方々の参考になれば幸いです!
なお、Difyの基本的な操作についてはWebに多くの記事があるため割愛させて頂きます。また今回はDify version 1.7.1を対象とします。
Dify導入のキッカケ
私の関わったプロジェクトでは元々AIワークフローを含むバックエンド全般をPython + LangChainで実装していました。しかし、お客様のニーズに合わせてプロンプトやAI関連の処理フローを頻繁に変更する必要があり、その都度Pythonのコードを修正するのが非常に手間という課題がありました。また、Sapeetではプロジェクトマネージャ(以降PMと記載)とエンジニアがタッグを組んでプロジェクトを進めるのですが、PMもプロンプトを修正できた方がより良いサービスが出来るのでは?との発想からDifyの導入を検討し始めました。
Difyを導入してみよう!
ここからはDify + Pythonでサービスを開発するにあたり、検討したことや学びを実際の開発の流れに沿ってご紹介します。是非、開発を追体験するようなイメージでご覧ください!
環境構築
クラウド版 vs セルフホスト版
開発するにあたりまず必要になるのがDifyを動かす環境です。Difyを使う場合、実行環境を丸ごと提供している「クラウド版」と、実行環境となるサーバを用意しそこに自前でホストする「セルフホスト版」の2つの手段があります。一般的なメリットデメリットは他のWebサイトでも言及されているため割愛し、ここではプロジェクトで使う場合に実際どちらが良いのか?について紹介します。
プロジェクトでは当初クラウド版を使っていました。しかし、稀にワークフローの実行が不安定になり失敗したり(サーバ側の負荷の影響と予想)、後述するPythonからのAPI呼び出しにおいてDifyのサーバの入り口に設置されているCloudflareにブロックされたりと安定したワークフローの実行ができないことがありました。後者に関してはサポートへの問い合わせを行うも明確な解決策を得ることができず、最終的にセルフホスト版に移行することでこれらの問題は解消しました。
Please enable cookies.
Sorry, you have been blocked
You are unable to access dify.ai
Why have I been blocked?
This website is using a security service to protect itself from online attacks. The action you just performed triggered the security solution. There are several actions that could trigger this block including submitting a certain word or phrase, a SQL command or malformed data.
What can I do to resolve this?
You can email the site owner to let them know you were blocked. Please include what you were doing when this page came up and the Cloudflare Ray ID found at the bottom of this page.
まずは環境が用意されているクラウド版で感触を掴み、その後セルフホストに移行することをオススメします。
実際の構築と費用感
それでは実際にセルフホストで構築してみましょう。弊社ではインフラとしてAWSを使用しており、AWS上に手っ取り早く環境を構築するにはAWSの公式ブログが参考になります。こちらのページにCloudFormationのテンプレートが紹介されており、必要なリソースの作成からDifyの立ち上げまで一気に行い、最終的にEC2上で動作する環境が完成します。ただし、ブログ中にも言及されている通りセキュリティや可用性について考慮されていない構成となっていますので、この辺りは適宜カスタマイズして利用しましょう。
テンプレートにはDifyのバージョンが記載されており、変更することで任意のバージョンで立ち上げることができます。今回はここを当時の最新版であった1.7.1としました。
sudo git checkout 1.1.3
sudo git pull origin 1.1.3
また気になる費用感ですが、これは基本的にEC2で立ち上げるインスタンスタイプに依存しており、テンプレートではt3.medium(vCPU2/メモリ4.0GiB)となっています。
実際にこのタイプで立ち上げて数人で開発を行いましたが特に問題無く利用できていますので、小規模の開発であればこのタイプで問題無さそうです。価格は執筆時点(2025年9月)で一時間あたり0.0418USDですので、月間30USD(=4500円)程度となります。クラウド版における小規模チーム向けのProfessionalプランは59USDですので、セルフホスト版の方が割安かつ安定した環境を手にいれることができます。
ワークフローの開発
環境が立ち上がったら、いよいよDifyでワークフローを構築します!今回はサンプルとして、Geminiを使った飲食店レシート文字起こし処理を作成しました。

作成したワークフロー
このワークフローをエクスポートしたファイルも添付しておきます。
ワークフローをエクスポートしたもの
app:
description: ''
icon: 🤖
icon_background: '#FFEAD5'
mode: workflow
name: レシート文字起こし
use_icon_as_answer_icon: false
dependencies:
- current_identifier: null
type: marketplace
value:
marketplace_plugin_unique_identifier: langgenius/gemini:0.2.4@1dc8cd4a3198584fd7639023951f388fff023caa234a4bdb8bba69d6091c2e64
kind: app
version: 0.3.1
workflow:
conversation_variables: []
environment_variables: []
features:
file_upload:
allowed_file_extensions:
- .JPG
- .JPEG
- .PNG
- .GIF
- .WEBP
- .SVG
allowed_file_types:
- image
allowed_file_upload_methods:
- local_file
- remote_url
enabled: false
fileUploadConfig:
audio_file_size_limit: 50
batch_count_limit: 5
file_size_limit: 15
image_file_size_limit: 10
video_file_size_limit: 100
workflow_file_upload_limit: 10
image:
enabled: false
number_limits: 3
transfer_methods:
- local_file
- remote_url
number_limits: 3
opening_statement: ''
retriever_resource:
enabled: true
sensitive_word_avoidance:
enabled: false
speech_to_text:
enabled: false
suggested_questions: []
suggested_questions_after_answer:
enabled: false
text_to_speech:
enabled: false
language: ''
voice: ''
graph:
edges:
- data:
isInIteration: false
isInLoop: false
sourceType: start
targetType: if-else
id: 1757664485803-source-1757664829041-target
selected: false
source: '1757664485803'
sourceHandle: source
target: '1757664829041'
targetHandle: target
type: custom
zIndex: 0
- data:
isInLoop: false
sourceType: if-else
targetType: llm
id: 1757664829041-true-1757664518411-target
selected: false
source: '1757664829041'
sourceHandle: 'true'
target: '1757664518411'
targetHandle: target
type: custom
zIndex: 0
- data:
isInIteration: false
isInLoop: false
sourceType: if-else
targetType: llm
id: 1757664829041-false-1757664863920-target
selected: false
source: '1757664829041'
sourceHandle: 'false'
target: '1757664863920'
targetHandle: target
type: custom
zIndex: 0
- data:
isInLoop: false
sourceType: llm
targetType: end
id: 1757664518411-source-1757664637426-target
source: '1757664518411'
sourceHandle: source
target: '1757664637426'
targetHandle: target
type: custom
zIndex: 0
- data:
isInLoop: false
sourceType: llm
targetType: end
id: 1757664863920-source-1757664908241-target
source: '1757664863920'
sourceHandle: source
target: '1757664908241'
targetHandle: target
type: custom
zIndex: 0
nodes:
- data:
desc: ''
selected: false
title: 開始
type: start
variables:
- allowed_file_extensions: []
allowed_file_types:
- image
allowed_file_upload_methods:
- local_file
label: file
max_length: 48
options: []
required: true
type: file
variable: file
- label: function
max_length: 48
options:
- オーダー抽出
- 店名抽出
required: true
type: select
variable: function
height: 116
id: '1757664485803'
position:
x: 30
y: 373
positionAbsolute:
x: 30
y: 373
selected: false
sourcePosition: right
targetPosition: left
type: custom
width: 244
- data:
context:
enabled: false
variable_selector: []
desc: ''
model:
completion_params:
temperature: 0.7
mode: chat
name: gemini-2.5-flash-preview-05-20
provider: langgenius/gemini/google
prompt_template:
- id: 7f8dd5bf-5f36-415e-8ec3-a3a9042d3efc
role: system
text: レシート画像に含まれるメニューの名前と金額と注文個数を抽出してください。
selected: false
structured_output:
schema:
properties:
items:
items:
properties:
amount:
minimum: 0
type: number
menu_name:
type: string
quantity:
minimum: 1
type: integer
required:
- menu_name
- amount
- quantity
type: object
type: array
required:
- items
type: object
structured_output_enabled: true
title: メニュー抽出LLM
type: llm
variables: []
vision:
configs:
detail: high
variable_selector:
- '1757664485803'
- file
enabled: true
height: 90
id: '1757664518411'
position:
x: 789
y: 258
positionAbsolute:
x: 789
y: 258
selected: false
sourcePosition: right
targetPosition: left
type: custom
width: 244
- data:
desc: ''
outputs:
- value_selector:
- '1757664518411'
- structured_output
value_type: object
variable: structured_output
- value_selector:
- '1757664518411'
- usage
value_type: object
variable: usage
selected: false
title: 終了
type: end
height: 116
id: '1757664637426'
position:
x: 1171.463804654296
y: 258
positionAbsolute:
x: 1171.463804654296
y: 258
selected: true
sourcePosition: right
targetPosition: left
type: custom
width: 244
- data:
cases:
- case_id: 'true'
conditions:
- comparison_operator: is
id: 81ace52c-8e28-4352-815f-f89aa6979a18
value: オーダー抽出
varType: string
variable_selector:
- '1757664485803'
- function
- comparison_operator: is not
id: e855abbf-744b-4376-95ad-504bf88d778a
value: 店名抽出
varType: string
variable_selector:
- '1757664485803'
- function
id: 'true'
logical_operator: and
desc: ''
selected: false
title: IF/ELSE
type: if-else
height: 152
id: '1757664829041'
position:
x: 364
y: 373
positionAbsolute:
x: 364
y: 373
selected: false
sourcePosition: right
targetPosition: left
type: custom
width: 244
- data:
context:
enabled: false
variable_selector: []
desc: ''
model:
completion_params:
temperature: 0.7
mode: chat
name: gemini-2.5-flash-preview-05-20
provider: langgenius/gemini/google
prompt_template:
- id: 1675d249-af78-420d-bffb-67bc715a25a5
role: system
text: レシート画像に含まれる店名を抽出してください。
selected: false
structured_output:
schema:
properties:
store_name:
type: string
required:
- store_name
type: object
structured_output_enabled: true
title: 店名抽出LLM
type: llm
variables: []
vision:
configs:
detail: high
variable_selector:
- '1757664485803'
- file
enabled: true
height: 90
id: '1757664863920'
position:
x: 789
y: 574.5311517897978
positionAbsolute:
x: 789
y: 574.5311517897978
selected: false
sourcePosition: right
targetPosition: left
type: custom
width: 244
- data:
desc: ''
outputs:
- value_selector:
- '1757664863920'
- structured_output
value_type: object
variable: structured_output
- value_selector:
- '1757664863920'
- usage
value_type: object
variable: usage
selected: false
title: 終了 2
type: end
height: 116
id: '1757664908241'
position:
x: 1171.463804654296
y: 574.5311517897978
positionAbsolute:
x: 1171.463804654296
y: 574.5311517897978
selected: false
sourcePosition: right
targetPosition: left
type: custom
width: 244
viewport:
x: 151.4389728877689
y: 76.96942079324572
zoom: 0.5918689215403616
このワークフローでは、ユーザがレシート画像をアップロード、functionのドロップダウンメニューで「オーダー抽出」を選択した場合、レシートから注文したメニュー名、単価、注文個数を抽出、「店名抽出」を選択した場合、店名のみを抽出します。オーダー抽出と店名抽出は同時に行うこともできますが、今回は1つのワークフローで複数機能を実装する例としてあえて処理を分けています。

実行画面
また入力データとして以下の画像を用います。

娘二人と行った思い出のサイゼリア
ここからはワークフローのポイントを解説します。
ポイント1: 似た処理は1つのワークフローにまとめる
最終的にこのワークフローをPythonからAPI呼び出しすることが目標なのですが、1ワークフローにつき、APIキーを1つ発行する必要があります。ワークフローが増えてくるとその分APIキーも増えてしまい、管理が煩雑となるため、似た処理は1つのワークフローにまとめ、実行時のパラメータでどの処理を実行するか指定できるようにしました。
開始ノードの必須入力フィールドは画像ファイルと実行する処理を指定するfunctionで構成されており、functionの入力フィールドのオプションに「オーダー抽出」と「店名抽出」を設定しています。このfunctionの値を受け取り、IF/ELSEノードで処理の分岐を行います。

開始ノードの入力に画像ファイルと処理分岐用の選択肢を設定

処理分岐用の選択肢に「オーダー抽出」と「店名抽出」を設定
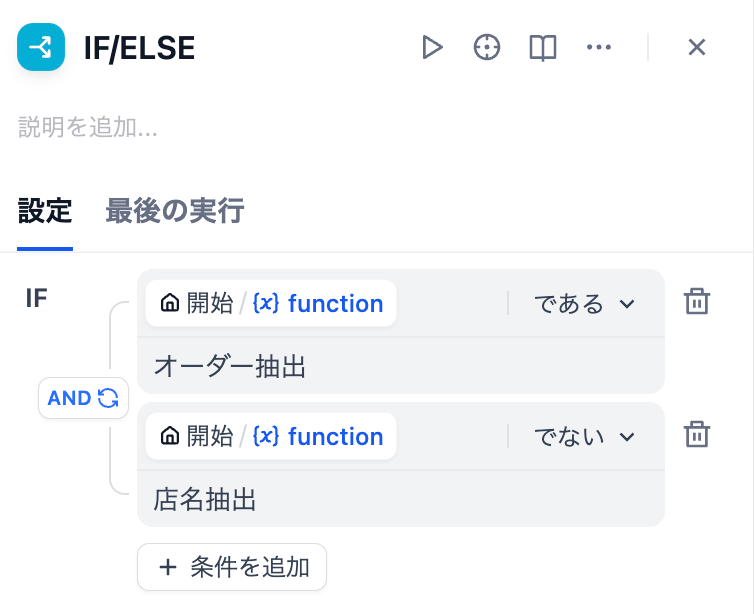
処理分岐の設定
ポイント2: LLMの構造化出力を使おう
実際に画像を解析するLLMは以下のような設定にしました。モデルはGemini 2.5 Flash Preview 05-20です。

LLMノードの設定
単純にシステムプロンプトだけを書いてもメニューの名前などを抽出してくれるのですが、実行する度に微妙に出力の形式が変わったり、余計な文字列が付いてきたりします。
レシート画像から抽出したメニュー、金額、注文個数は以下の通りです。
メニュー名: 小エビのサラダ, 金額: ¥350, 注文個数: 1
メニュー名: 辛味チキン, 金額: ¥300, 注文個数: 1
最終的にこの出力をPythonで扱うことを考えるとプログラムで扱いやすいjson形式が望ましいため、構造化出力を使います。出力変数の右にある構造化出力のトグルをONにし、structured_outputの右の設定ボタンを押します。すると構造化データスキーマという出力のデータ構造を指定する画面が表示されます。

構造化出力の設定をONに

出力する構造を設定するための画面
この画面ではGUIでフィールドを追加したり、JSONで構造を作成して読み込ませたりすることができるのですが、この作業は煩雑でかつ失敗しやすいのが難点です。しかし、なんとDifyにはAIサポート機能が付随しており、以下のように自然言語で指示するとスキーマを生成してくれます!

スキーマの生成をAIに依頼
生成されたスキーマは以下のようになりました。

生成されたスキーマ
ワークフローを実行するとstructured_outputのキーの箇所に構造化されたデータが出力されるようになります。メニュー名、単価、注文個数が正しく抽出されていますね!
ちなみにOpenAIのgpt-4oを使うと精度が悪く一部期待したデータが抽出されませんでした。簡単にモデルを切り替えて評価ができるのもDifyの強みですね。
構造化された出力データ
{
"text": "{\"items\": [{\"menu_name\": \"小エビのサラダ\", \"amount\": 350, \"quantity\": 1}, {\"menu_name\": \"辛味チキン\", \"amount\": 300, \"quantity\": 1}, {\"menu_name\": \"ポップコーンシュリンプ\", \"amount\": 300, \"quantity\": 1}, {\"menu_name\": \"小エビのカクテル\", \"amount\": 280, \"quantity\": 1}, {\"menu_name\": \"ソーセージピザ\", \"amount\": 400, \"quantity\": 1}, {\"menu_name\": \"若鶏のディアボラ風\", \"amount\": 500, \"quantity\": 1}, {\"menu_name\": \"チョコレートケーキ\", \"amount\": 300, \"quantity\": 2}]}",
"usage": {
"prompt_tokens": 1460,
"prompt_unit_price": "0.15",
"prompt_price_unit": "0.000001",
"prompt_price": "0.000219",
"completion_tokens": 621,
"completion_unit_price": "0.6",
"completion_price_unit": "0.000001",
"completion_price": "0.0003726",
"total_tokens": 2081,
"total_price": "0.0005916",
"currency": "USD",
"latency": 4.830918299034238
},
"finish_reason": "STOP",
"structured_output": {
"items": [
{
"menu_name": "小エビのサラダ",
"amount": 350,
"quantity": 1
},
{
"menu_name": "辛味チキン",
"amount": 300,
"quantity": 1
},
{
"menu_name": "ポップコーンシュリンプ",
"amount": 300,
"quantity": 1
},
{
"menu_name": "小エビのカクテル",
"amount": 280,
"quantity": 1
},
{
"menu_name": "ソーセージピザ",
"amount": 400,
"quantity": 1
},
{
"menu_name": "若鶏のディアボラ風",
"amount": 500,
"quantity": 1
},
{
"menu_name": "チョコレートケーキ",
"amount": 300,
"quantity": 2
}
]
},
"files": []
}
ポイント3: 実行コストを取得しよう
生成AIを使うサービスを構築するにあたりコストの把握はとても重要です。PythonからこのワークフローをAPI呼び出しすることを考えた場合、Python側でコストも取得しDBに入れて集計したいというケースがあります。LLMノードの出力にはusageという項目があり、ここにtotal_priceという名前でコストが格納されています。抽出結果であるstructured_outputに加えて、usageも終了ノードに追加してあげることで、Python側でコストを得ることができます。

抽出したデータに加えてusageも一緒に返す
Pythonからの呼び出し
Dify上でワークフローの作成が完了しましたので、次はこのワークフローをPythonからAPI呼び出しします。このためにエンドポイントの把握とAPIキーの発行を行う必要があるのですが、こちらに関してはDify上のサイドバーにある「APIアクセス」のページを開くことでドキュメントを見ることができ、またWeb上に情報も多いため割愛します。

API呼び出しのために「APIアクセス」ページを開く
レシート画像をアップロードしてLLMによる解析を行うには、まずファイルアップロードAPIでファイルをアップロードしファイルIDを取得、ファイルIDに対してワークフローを実行するという流れとなります。今回作成したコードは以下です。
サンプルコード
import os
import uuid
from enum import Enum
from typing import Optional, Tuple
import requests
from dotenv import load_dotenv
load_dotenv()
# DIFY_API_KEYとDIFY_BASE_URLを環境変数にセットした状態で実行してください
DIFY_API_KEY = os.getenv("DIFY_API_KEY", "")
DIFY_BASE_URL = os.getenv("DIFY_BASE_URL", "")
WORKFLOW_RUN_URL = f"{DIFY_BASE_URL}/workflows/run"
FILE_UPLOAD_URL = f"{DIFY_BASE_URL}/files/upload"
class WorkflowFunction(Enum):
ORDER_EXTRACTION = "オーダー抽出"
STORE_NAME_EXTRACTION = "店名抽出"
def upload_file(user_id: str, file_path: str) -> Tuple[bool, str]:
headers = {
"Authorization": f"Bearer {DIFY_API_KEY}",
}
try:
with open(file_path, "rb") as f:
files_payload = {
"user": (None, user_id),
"file": (os.path.basename(file_path), f, "image/jpeg"),
}
response = requests.post(
FILE_UPLOAD_URL, headers=headers, files=files_payload
)
response.raise_for_status()
file_info = response.json()
file_id = file_info.get("id")
return True, file_id
except Exception as e:
print(f"Failed to upload file: {e}")
return False, ""
def run_workflow(
user_id: str,
file_id: str,
function: WorkflowFunction,
) -> Tuple[bool, Optional[str], float]:
headers = {
"Authorization": f"Bearer {DIFY_API_KEY}",
"Content-Type": "application/json",
}
json_payload = {
"inputs": {
"file": {
"type": "image",
"transfer_method": "local_file",
"upload_file_id": file_id,
},
"function": function.value,
},
"response_mode": "blocking",
"user": user_id,
}
try:
response = requests.post(WORKFLOW_RUN_URL, headers=headers, json=json_payload)
response.raise_for_status()
response_json = response.json()
status = response_json.get("data", {}).get("status")
error = response_json.get("data", {}).get("error", "")
outputs = response_json.get("data", {}).get("outputs", {})
if status != "succeeded" or error:
print(f"Failed to run workflow: {response_json}")
return False, None, 0.0
structured_output = outputs.get("structured_output", {})
usage = outputs.get("usage", {})
cost = usage.get("total_price", 0.0)
return True, structured_output, cost
except requests.exceptions.RequestException as e:
print(f"Failed to run workflow: {e}")
return False, None, 0.0
def main():
# 画像のファイルパス
file_path = "20250929_205528.jpg"
user_id = str(uuid.uuid4())
# 画像のアップロード
success, file_id = upload_file(user_id, file_path)
if not success:
print(f"Failed to upload file: {file_id}")
return
# ワークフローの実行
success, result, cost = run_workflow(
user_id, file_id, WorkflowFunction.ORDER_EXTRACTION,
# user_id, file_id, WorkflowFunction.STORE_NAME_EXTRACTION
)
if not success:
print("Failed to run workflow")
return
print(f"{cost=}")
print(result)
if __name__ == "__main__":
main()
ポイントは以下の箇所であり、ワークフロー実行時に処理分岐用の文字列を一緒に渡すことでDify上で任意の処理を行うことができます。
class WorkflowFunction(Enum):
ORDER_EXTRACTION = "オーダー抽出"
STORE_NAME_EXTRACTION = "店名抽出"
...
success, result, cost = run_workflow(
user_id, file_id, WorkflowFunction.ORDER_EXTRACTION
# user_id, file_id, WorkflowFunction.STORE_NAME_EXTRACTION
)
以下のような結果が得られました。構造化されたデータやコストが期待通り取得できています!
# メニュー抽出
cost='0.0004176'
{'items': [{'menu_name': '小エビのサラダ', 'amount': 350, 'quantity': 1}, {'menu_name': '辛味 チキン', 'amount': 300, 'quantity': 1}, {'menu_name': 'ポップコーンシュリンプ', 'amount': 300, 'quantity': 1}, {'menu_name': '小エビのカクテル', 'amount': 280, 'quantity': 1}, {'menu_name': 'ソーセージピザ', 'amount': 400, 'quantity': 1}, {'menu_name': '若鶏のディアボラ風', 'amount': 500, 'quantity': 1}, {'menu_name': 'チョコレートケーキ', 'amount': 300, 'quantity': 2}]}
# 店名抽出
cost='0.0000486'
{'store_name': 'サイゼリヤ'}
バージョン管理
PythonからAPI呼び出しすることで、AI周りの処理はDify、それ以外の処理はPythonで実行できるようになりました。
ここで気になるのはDifyのワークフローがGUI上に置かれており、誰かが間違って削除したり意図しない変更をしてしまうことです。サービス開発を行うにあたり、このような不測の事態やデグレが発生した場合にバージョンを戻せるように管理できることが望ましいです。一応Dify上でもバージョン管理の仕組みがあるのですが、今回はPythonのコードとセットで管理したいため、gitを用います。
DifyはワークフローをDSLという形でエクスポートしてローカルに保存したり、ローカルのDSLをインポートする機能があり、ある程度機能の区切りがついたタイミングなどでエクスポートしてDSLをgitで管理しておくと、何かあった際にインポートしてそのバージョンに戻すことができます。

インポートとエクスポート
DLSの実態はymlファイルであり、意外とgit diffで差分が見やすく表示されるため、バージョンごとの差分も把握できます。以下はプロンプト修正前後のdiffです。
@@ -198,8 +198,8 @@ workflow:
prompt_template:
- id: 7f8dd5bf-5f36-415e-8ec3-a3a9042d3efc
role: system
- text: レシート画像に含まれるメニューの名前と金額と注文個数を抽出してください。
+ text: レシート画像に含まれるメニューの名前だけを抽出してください。
structured_output:
schema:
properties:
最後に
Difyの導入検討から環境構築、Dify×Pythonによるハイブリッド開発、バージョン管理まで、開発の一連の流れとそこから得られた知見をご紹介しました。本ブログを通じて、導入のイメージが少しでも膨らんだのであれば幸いです。
この分野はまだ発展途上でベストプラクティスと呼べるものが無く試行錯誤の連続です。そうした状況の中でも、SapeetのメンバーはAIの可能性を信じ、最新の技術をキャッチアップしながら、現場の創意工夫を重ねてお客様に価値のあるサービスを開発しています。
最後までお読みいただきありがとうございました。もしSapeetにご興味をお持ち頂けましたら、ぜひ以下の採用サイトからご連絡ください。今が一番面白いフェーズです!

Discussion