Stanfordの大規模言語モデル Alpaca: "A Strong, Replicable Instruction-Following
概要
今年Stanford大学が発表した、52KのインストラクションチューニングでLLaMA 7Bモデルを微調整したモデルであるAlpaca 7B。本記事では、その詳細について公式に公開されているものを紐解きつつ、わかりやすいようにまとめる。
参考情報
- ブログリンク
- Github
Introduction
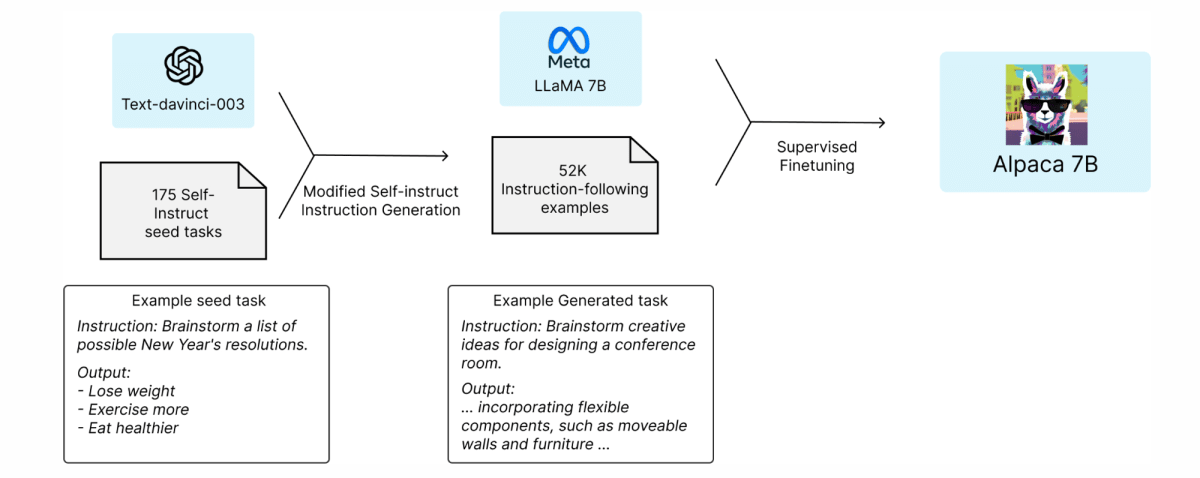
- 52K の命令に従うデモンストレーションで LLaMA 7B モデルを微調整したモデルであるAlpaca 7B
- シングルターン命令の評価では、Alpaca は OpenAI の text-davinci-003 と定性的に同様に動作
- 再現が簡単で、コストが600ドル未満
- On our preliminary evaluation of single-turn instruction following, Alpaca behaves qualitatively similarly to OpenAI’s text-davinci-003, while being surprisingly small and easy/cheap to reproduce (<600$). Checkout our code release on GitHub.
- text-davinch-003を使用して、self-instructのスタイルで生成された52Kのデータでalpacaをトレーニング
- トレーニングレシピとデータを公開しており、将来的にはモデルの重みも公開する予定
- 学術目的のみを想定、商用利用は禁止
Training Recipe
-
Self-Instruct: Aligning Language Models with Self-Generated Instructionsの論文では、既存の強力な言語モデルを使用して指示データを自動的に生成することを提案
-
self-instructシードセットの使用: このプロセスは、self-instructメソッドから得られた175の人間によって書かれた指示と出力のペア(シードセット)から始まります。
-
text-davinci-003の使用: このシードセットをコンテキストの例として使用し、text-davinci-003によりさらなる指示を生成させます。これにより、元のデータセットを拡張し、より多様な指示と出力のペアを作成します。
-
生成プロセスの簡素化: self-instructメソッドを改善するために、生成プロセスを簡素化しました。詳細はGitHubで確認できます
-
データ生成の結果: 最終的に、52,000のユニークな指示とそれに対応する出力が生成され、このプロセスのコストはOpenAI APIを使用して500ドル未満でした。
-
この命令に従うデータセットを装備し、完全シャード データ並列や混合精度トレーニングなどの手法を利用して、Hugging Face のトレーニング フレームワークを使用して LLaMA モデルを微調整しました。最初の実行では、8 台の 80GB A100 で 7B LLaMA モデルの微調整に 3時間
-
これはほとんどのクラウドコンピューティングサービスで100ドル未満
| Hyperparameter | LLaMA-7B | LLaMA-13B |
|---|---|---|
| Batch size | 128 | 128 |
| Learning rate | 2e-5 | 1e-5 |
| Epochs | 3 | 5 |
| Max length | 512 | 512 |
| Weight decay | 0 | 0 |
評価
- 人間による評価を実施。Alpacaの評価は、5人の学生著者によって行われました。彼らは「self-instruct評価セット」からの入力に基づいて評価を行いました。この評価セットは、self-instructの著者によって収集され、メール作成、ソーシャルメディア、生産性ツールなど、ユーザー指向の多様な指示を含んでいます。
- text-davinch-003とalpacaのブラインド評価を実施したところ、alpacaが90:89で勝利
- 静的な評価セットに加えて、著者たちはAlpacaモデルをインタラクティブにテストし、多様な入力に対してAlpacaがtext-davinci-003と同様に振る舞うことを発見
- Alpaca の回答は通常、ChatGPT よりも短くなり、text-davinci-003 の短い出力を反映しています。
注意
- アルパカはまた、幻覚、毒性、固定観念など、言語モデルの一般的な欠陥をいくつか示します。text-davinci-003 と比較しても、特に幻覚は Alpaca の一般的な障害モード
資産
- デモ
- 公開停止
- OpenAI のコンテンツ モデレーション APIでOpenAIの使用ポリシーで制限されている有害な入力を除外
- A Watermark for Large Language Modelsで透かしを入れてalpacaの出力かどうか一定の確率で特定できるようにしている
- データ
- データ生成プロセス
- Huggingfaceを使用してトレーニングするコード
今後
- alpacaをもっと厳密に評価するために、HELMを利用
- Holistic Evaluation of Language Models
引用
- Holistic Evaluation of Language Models
Discussion