Remix+CloudflareでWebサイトを作る 39(クエリの同一キーで複数の値を扱う、Tursoを調査、D1→Tursoに移行、@prisma/adapter-libsqlの依存関係エラー)
自分も2017年からプロダクトのアイデアをためるスプシを運用しているんだけど、なかなか着手できていないものも多い。
頑張ろう。
【2024-10-27】URLのクエリパラメーターで、同じキーに対して複数のバリューを渡したい
背景
現在DataTableのフィルタリング処理を実装中。
あるstatusカラムはA,B,Cという状態を持っていて、Aだけでフィルタリングすることもできれば「AかつB」というフィルタリングをすることも可能になっている(MultiSelect)。
また、フィルタリングを更新するとクエリパラメーターが更新されloaderが発火してDBからデータを取ってくるようになっている。
疑問
statusというキーに対して「AかつB」という値をクエリパラメーターで渡したい場合、どのようにするのが適切なのか?
?status=A&statusB?
?status=[A,B]?
調査
-
GET /user?id=1,2,3
- ものによってはこの形式がそのまま対応していないものも
-
GET /user?id=1&id=2&id=3&id=.
- 一般的らしい
-
GET /user?id[]=1&id[]=2&id[]=3&...
iOS としては元々 3 のパターンを前提としてクエリパラメータをデコードしていたのですが、どうやら iOS 側で利用してるメジャーなライブラリ(現職の iOS チームが使っていたもの)が RFC 3986 に対応したことで 3 のパターンが使えなくなり、結果としては 2 のパターンで実装する事になりました。
参考2
shadcn+tanstackのサンプル
1つ前のScrapでも書いたこのExampleプロダクトではカンマ区切りのクエリになっていた。
https://table.sadmn.com/?status=todo,in-progress
結論
パターン2の GET /user?id=1&id=2&id=3&id=. 形式にする。
ということでここで作成した関数に更新を加えた。
valueが配列でもあるのだいぶ気持ち悪いけどまずは動くものを...。
/**
* クエリを追加・更新する
*/
const upsertQuery = ({
key,
value,
}: { key: Query["key"]; value: Query["value"] | Query["value"][] }) => {
const newQuery = new URLSearchParams(query);
if (Array.isArray(value)) {
// ここで削除しないと、`status=A` のあとに更にBというフィルタリングを追加すると
// `status=A&status=A&status=B` というクエリになってしまう
newQuery.delete(key);
for (const val of value) {
newQuery.append(key, val);
}
} else {
newQuery.set(key, value);
}
setQueryState(newQuery);
navigate(`${location.pathname}?${newQuery.toString()}`, { replace: true });
};
loaderでは getAll() を使って配列形式で扱える。
export async function loader({ request }: LoaderFunctionArgs) {
const url = new URL(request.url);
const query = url.searchParams;
- const status = query.get("status")
+ const statuses = query.getAll("status")
...
}
【2024-10-28】D1からTursoに移行する?
背景
移行記事を見た
D1の最大サイズは10GBまでしかなく、ある程度の規模になるとマルチDB運用にしないといけない
Worker以外からのアクセスは遅い
10GBというのも有料版の場合の最大値であり、無料版は500MB。
10GBっていう制限が将来しんどくならないか心配なんだよな。
詳しくは Limits | Cloudflare D1 docs を参照。
記事2
画像URLがなくなっているけどローカルでもダッシュボード使えるのかな?

Prisma公式
Prisma公式もPrisma OptimizeにTursoを選んでますよ、と。
【2024-10-28】Hello, Turso!
1. CLIをインストール、GitHubアカウント連携
brew install tursodatabase/tap/turso
確認する。
turso --version
# turso version v0.97.2
GitHubアカウントの認証を行う。
turso auth login
2. DBの作成
DBの作成を行う。
turso db create db-name
この時、自動的に最も近い地域を自動的に検出してそこをDBのデフォルトの「グループ」として扱うとのこと(グループも作成される)。
じゃあ東京か〜とか思ってダッシュボード見に行ったらシドニーになってるじゃないか。
DBを作成したときに出たCreated group default at syd in 13.817s. の sydって何かと思ったらシドニーのことか。
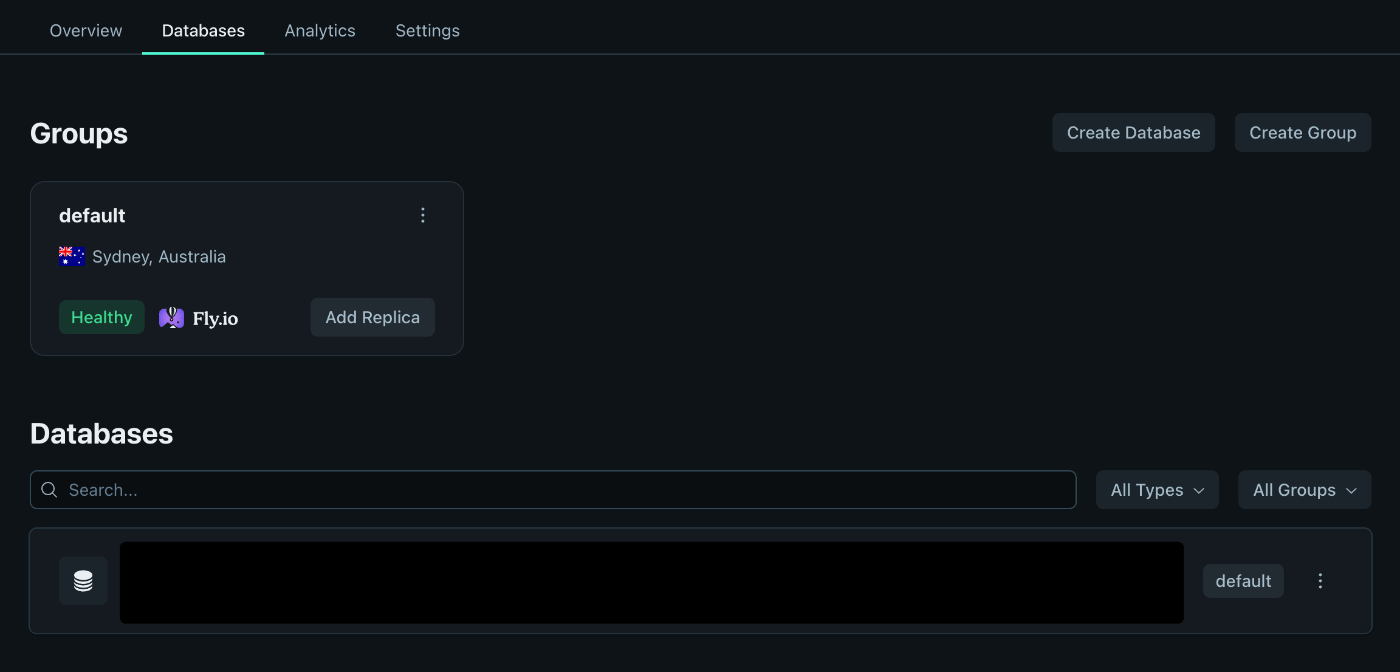
デフォルトのグループを東京にする(失敗)
さすがに東京がないことは無いよな?と思ったので調べる。
公式サイトによると以下のコマンドで確認できる。
turso db locations
# nrt Tokyo, Japan
あった!
turso group locations add default nrt
# Group default replicated to nrt in 10 seconds.
13.8から10sになってるけどなんだろう。地理的に近いから早い的なことなのかだろうか。
こうしてみるけどシドニーに加えて東京があるだけ。
東京だけにしたい。
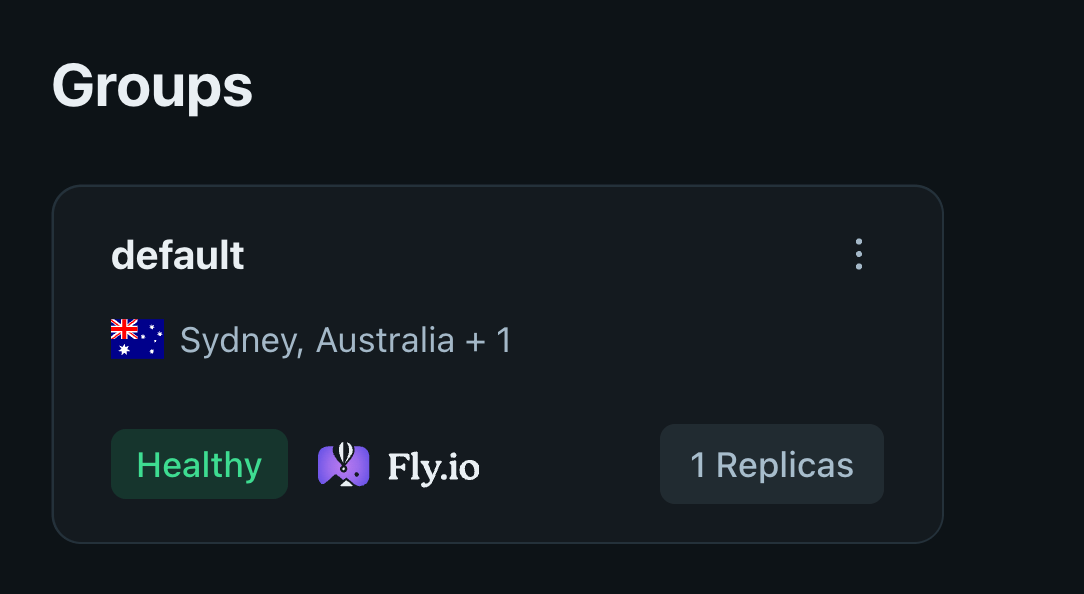
デフォルトのグループを東京にする(成功)
グループを削除してから手動で先にグループを作る。

その後、以下のコマンドを再度実行すると...
turso db create db-name
東京になっている。

確認してみる。
turso db show
# Locations: nrt
あとDBのデータを編集するところにPrisma studioは無い。
3. DBとの接続
turso db shell db-name
適当なSQL文を実行してみる。
CREATE TABLE users (
ID INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT
);
ダッシュボードで見るとテーブルが作成されていることがわかる。
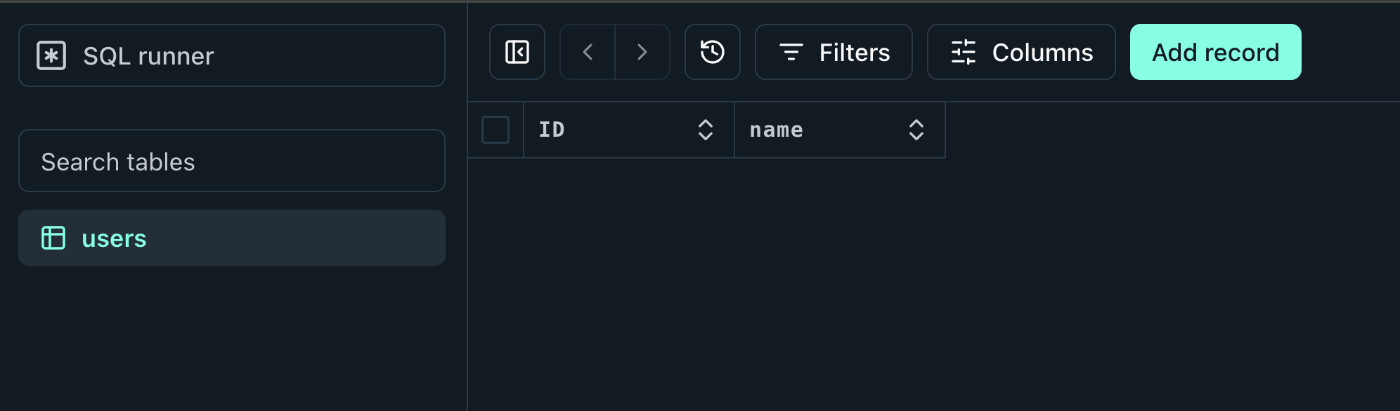
4. Cloudflare側でインテグレーションの追加
ここではCloudflare側のドキュメントを見る。
Workers &Pages > 概要 > インテグレーションでTursoを選択。
ステージング用のDBも作ったら、Cloudflareのプレビュー環境でも同様にインテグレーションの追加を行う必要がある。

TURSO_URL と TURSO_AUTH_TOKEN は以下コマンドで確認。
turso db show --url db-name
# libsql://xxx.turso.io = TURSO_URL
turso db tokens create db-name
# eyJ... = TURSO_AUTH_TOKEN
5. マイグレーションファイルの適用
pnpm add @prisma/adapter-libsql
Prismaで作られているマイグレーションファイルを適用させる。
すでにDBに他のテーブルがあったらエラーになるのかとも思ったけど特に起こらず上書きされる。
ダッシュボードではOuterbaseStudioで閲覧する。
turso db shell db-name < ./prisma/migrations/20230922132717_init/migration.sql
6. 接続
開発環境
以下コマンドで立ち上げる。
prisma/dev.db というPrismaで使用していたDBファイルをそのまま使用できる。
turso dev だけでも立ち上げられるが永続化はされない(止めたら変更が失われる)ので注意。
turso dev --db-file prisma/dev.db
devClient を使ってシードデータを入れる。
import { createClient } from "@libsql/client";
import { PrismaLibSQL } from "@prisma/adapter-libsql";
import { PrismaClient } from "@prisma/client";
const libsql = createClient({
url: "http://127.0.0.1:8080",
});
const adapter = new PrismaLibSQL(libsql);
/**
* 開発環境でシードデータを入れるためのPrismaClient
*/
export const devClient = new PrismaClient({ adapter });
ステージング・本番環境
Cloudflareの環境変数はprocess.envが使えないのでcontext.cloudflare.envの値をloader actionで取得する処理を追加。
import { createClient } from "@libsql/client/web";
import { PrismaLibSQL } from "@prisma/adapter-libsql";
import { PrismaClient } from "@prisma/client";
import type { AppLoadContext } from "@remix-run/cloudflare";
import type { PlatformProxy } from "wrangler";
interface Env {
__STATIC_CONTENT: string;
// .dev.vars にある値
BASIC_AUTH_USERNAME: string;
BASIC_AUTH_PASSWORD: string;
R2_DOMAIN: string;
BASELIME_API_KEY: string;
TURSO_URL: string;
TURSO_AUTH_TOKEN: string;
// wrangler.toml
DB: D1Database;
BUCKET: R2Bucket;
}
type Cloudflare = Omit<PlatformProxy<Env>, "dispose">;
declare module "@remix-run/cloudflare" {
interface AppLoadContext {
cloudflare: Cloudflare;
db: PrismaClient<{ adapter: PrismaLibSQL }>;
}
}
type GetLoadContext = (args: {
request: Request;
context: {
cloudflare: Cloudflare;
}; // load context _before_ augmentation
}) => Promise<AppLoadContext>;
// Shared implementation compatible with Vite, Wrangler, and Cloudflare Pages
export const getLoadContext: GetLoadContext = async ({ context }) => {
const url = context.cloudflare.env.TURSO_URL.trim();
if (url === undefined) {
throw new Error("TURSO_URL という環境変数が定義されていません");
}
const authToken = context.cloudflare.env.TURSO_AUTH_TOKEN.trim();
if (authToken === undefined) {
throw new Error("TURSO_AUTH_TOKEN という環境変数が定義されていません");
}
const libsql = createClient({ url });
const adapter = new PrismaLibSQL(libsql);
const client = new PrismaClient({ adapter });
return {
...context,
db: client,
};
};
こんな感じで使う。
export async function loader({ request, context }: LoaderFunctionArgs) {
const users = getUsers(context.db)
}
【2024-11-04】スキーマ更新時の手順
D1使っているときよりだいぶシンプルになった。
1. スキーマファイルの更新
schema.prismaを更新
2. 型定義ファイルの更新
npx prisma generate
3. マイグレーションファイルを作成
npx prisma migrate dev --name YOUR_MESSAGE
DBが立ち上がったままだと以下のようなエラーが発生するので一旦止める。
Error: SQLite database error
database is locked
0: sql_schema_connector::sql_migration_persistence::initialize
with namespaces=None
at schema-engine/connectors/sql-schema-connector/src/sql_migration_persistence.rs:14
1: schema_core::state::ApplyMigrations
at schema-engine/core/src/state.rs:226
4. マイグレーションを適用
# Develop(これはサーバーが立ち上がった状態で行う)
turso db shell http://127.0.0.1:8080 < prisma/migrations/20241104091415_init/migration.sql
# Staging/Production
turso db shell db-name < prisma/migrations/20241104091415_init/migration.sql
【2024-11-04】Tursoの「Rows Read」について
背景
アクセス数に対して「Rows Read」がどうも多い気がしたので調べる。
Rows Read
SQLiteでは、「行読み取り」という用語は、実際にはステートメント実行中の「行スキャン」を指します。 Turso CLIのメトリクスで覚えておくべきポイント:
- SQLクエリ: 返されるよりも多くの行をスキャンする可能性があります。
- SQLの更新: 各行が更新されるたびに、少なくとも1回の行スキャンが発生する。
Aggregate Function Impact
count、avg、min、max、sumのような関数を使用すると、集計で考慮されるすべての行に対して行スキャンを行うことになる。
集計値を別のテーブルに格納し、ベース・テーブルの変更に合わせてトランザクションで更新することで、クエリの効率を向上させます。
Full Table Scans
インデックスをサポートしていないクエリは、テーブルの各行に対して行スキャンが発生し、テーブルのフルスキャンを実行する。
コストのかかるテーブルスキャンを最小限に抑える戦略を模索する。
Complex Query Costs(複雑なクエリのコスト)
テーブル結合、サブクエリ、複合クエリでは、関係するすべてのテーブルから考慮される各行に対して行スキャンが発生します。
Indexing Costs(インデックスのコスト)
既存のテーブルにインデックスを追加すると、フルテーブルスキャンがトリガーされ、既存の行1つにつき1回の読み取りが行われる。
Reducing Usage(使用量の削減)
Query Excecution(クエリ実行)
SQLiteのクエリプランナーを使いこなすことで、クエリがどのように実行されるかの理解を大幅に深めることができます。 この知識は、クエリの効率を最適化する上で極めて重要です。
Indexing(インデックス作成)
行のフィルタリングにインデックスを利用するようにクエリを設計してください。 適切なインデックスがない場合、SQLiteはフルテーブルスキャンに頼らざるを得なくなり、テーブル内の各行の読み取りカウントが1ずつ増えていきます。
効率的なインデックス作成は、このオーバーヘッドを最小化する鍵です。 テーブル作成段階で必要なインデックスを組み込むことがベストプラクティスです。 すでに行が存在するテーブルにインデックスを追加すると、フルテーブルスキャンがトリガーされ、既存の行ごとに1回の読み取りが必要になります。 最適なデータベース・パフォーマンスを維持するためには、積極的なインデックス管理が重要です。
感想
色々と考えなくてはいけないことはわかった(考えて適切なコードにできるとは言っていない)。
ここらへんCopilot使ってどうにかしたいな。
こんな記事もあった。
「Indexing」で言っているのはこのことなんだろうな。
自分のはここらへんが不十分で1回のprismaのクエリでいろいろなところ読みにいってRows Readが多くなっているような気がする。
読み込みによる料金と、テーブルのストレージ料金がどれくらいだとどうなのか、損益分岐点的なやつのイメージがまったくないな。
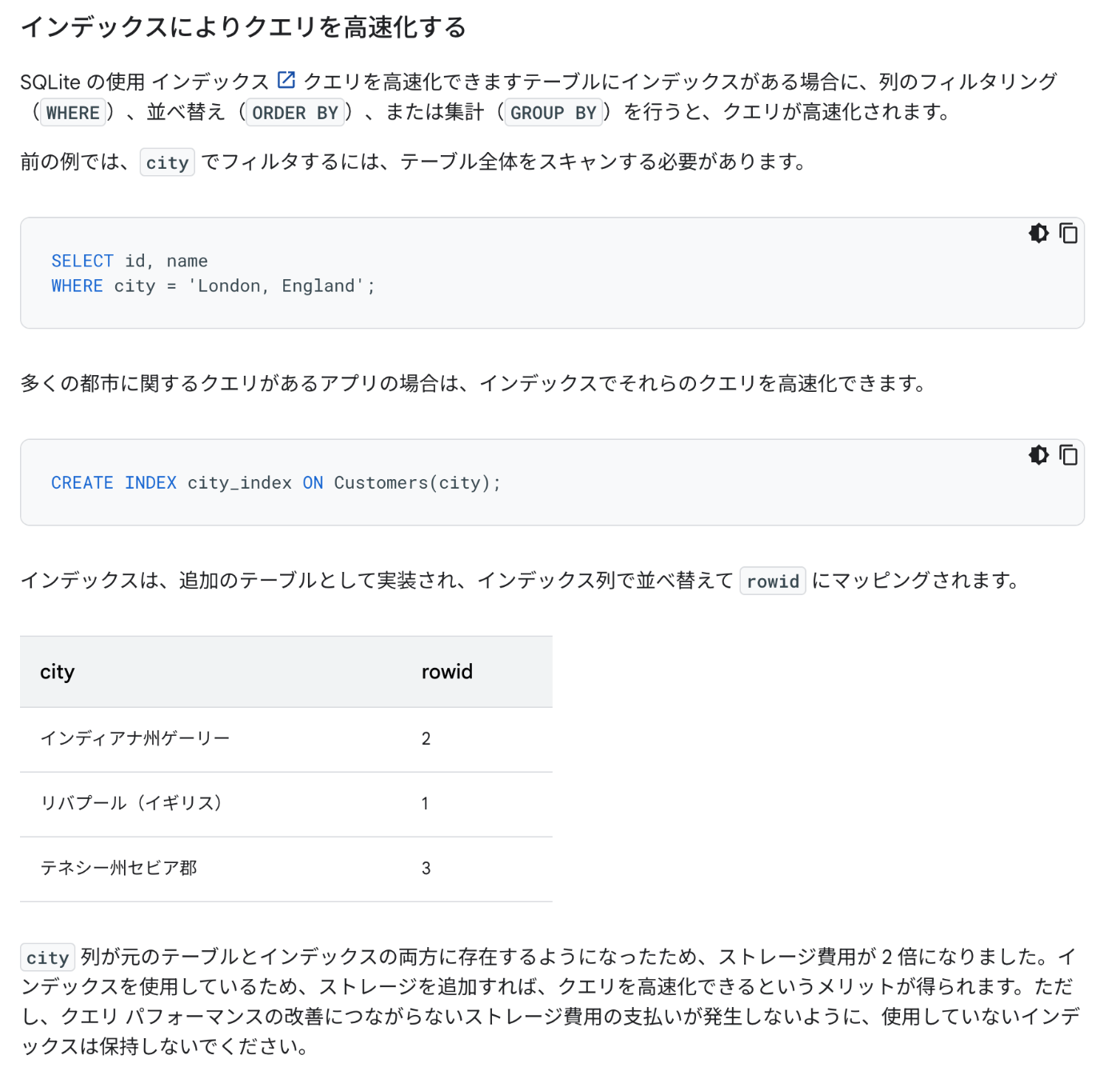
Prismaの prisma.users.count() ってSQL文でいうSelect Count(*) From User;を実行しているから全行を読みにいっているわけではない。
とはいえ、どうやって行の総数を計算しているんだっけ?
ChatGPTに聞いてみる。
SQLiteでは、COUNTクエリを使うことで「行の総数」を効率的に取得できます。SQLiteはテーブルのインデックス(主キーのインデックスなど)を利用して行の総数を計算するため、テーブルのすべてのデータをロードする必要がありません。この方法は、インデックスがある場合に特に高速です。
ただし、テーブルの内容によっては、インデックスを参照するのではなく、すべての行を走査して数えるケースもあります。このため、行数の計算のパフォーマンスは、テーブルにインデックスが存在するかどうかや、データベースの最適化の設定によって異なる場合があります。
SQLiteのCOUNT操作は内部的にデータベースのメタデータも活用しますが、一般的にはインデックスを使用して効率化しています。
インデックスはなぜ高速なのか。
インデックスは、データベース内でデータの検索やソートを効率化するために特定の列に基づいて構築されたデータ構造です。これにより、データの場所を迅速に特定でき、行の総数などの情報を得る際に役立ちます。
具体的に言うと、インデックスは行のデータそのものではなく、行がどこにあるかを示す「参照情報」や「ポインタ」に過ぎません。そのため、SQLiteがCOUNT(*)を実行するとき、インデックスだけを参照することができれば、実際の行のデータにはアクセスせず、行数を効率よく取得できます。このプロセスは、データの参照に必要なディスクやメモリへの負担が少なく、パフォーマンスが向上します。
1万行あるテーブルにCountを実行したらTurso側の「Read Rows」はプラスいくつになるんだろう?
ちなみにCountを使うこともベストプラクティスの1つ。
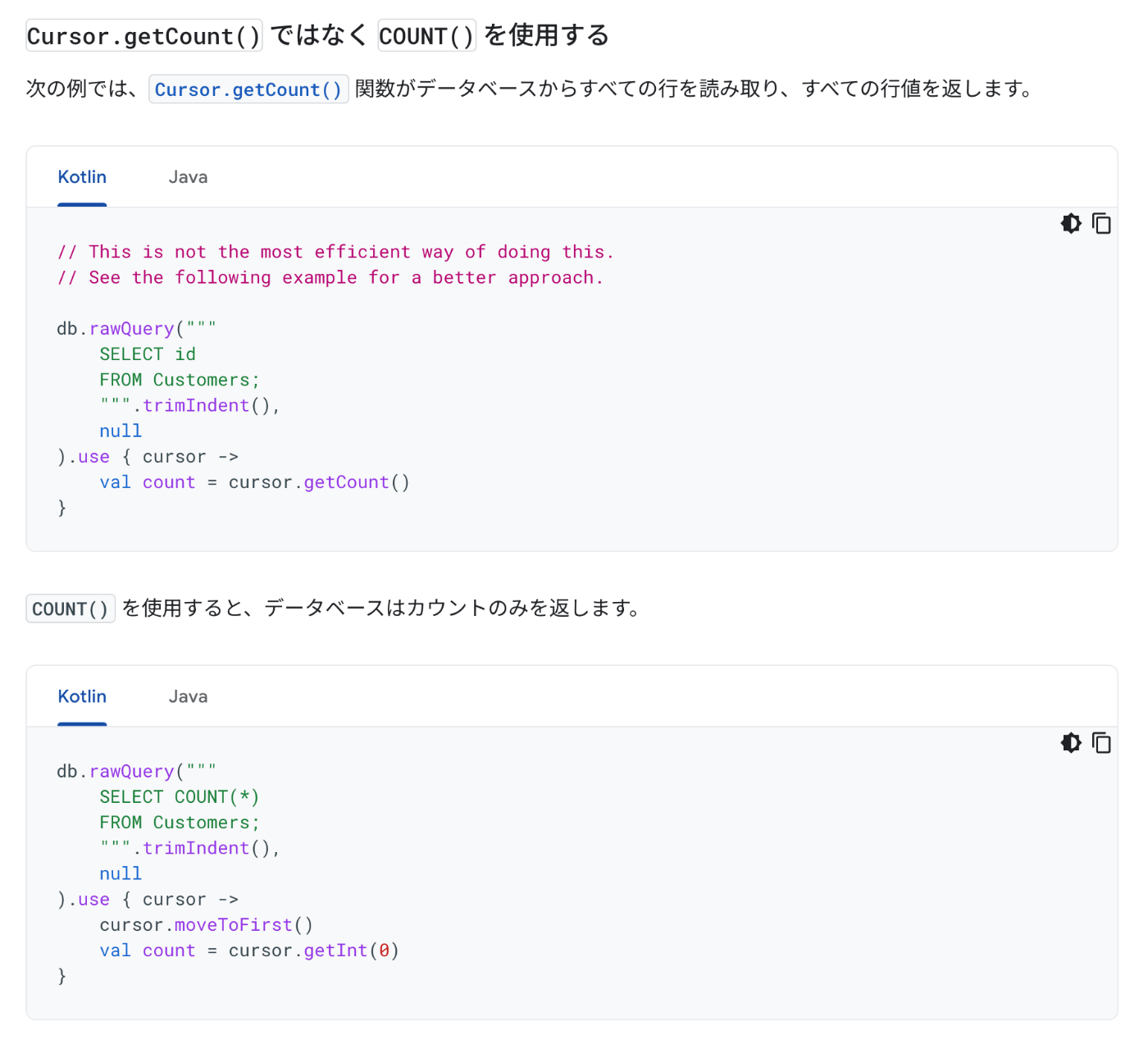
【2024-10-28】ビルド時に @libsql/clientと@prisma/adapter-libsqlの依存関係でエラー
エラー内容
npm error code ERESOLVE
npm error ERESOLVE unable to resolve dependency tree
npm error
npm error While resolving: appname@undefined
npm error Found: @libsql/client@0.14.0
npm error node_modules/@libsql/client
npm error @libsql/client@"^0.14.0" from the root project
npm error
npm error Could not resolve dependency:
npm error peer @libsql/client@"^0.3.5 || ^0.4.0 || ^0.5.0 || ^0.6.0 || ^0.7.0 || ^0.8.0" from @prisma/adapter-libsql@5.21.1
npm error node_modules/@prisma/adapter-libsql
npm error @prisma/adapter-libsql@"^5.21.1" from the root project
npm error
npm error Fix the upstream dependency conflict, or retry
npm error this command with --force or --legacy-peer-deps
npm error to accept an incorrect (and potentially broken) dependency resolution.
npm error
npm error
npm error For a full report see:
npm error /home/runner/.npm/_logs/2024-10-28T13_16_12_656Z-eresolve-report.txt
修正したらまたエラー
Note: Support for Turso is available in Early Access from Prisma versions 5.4.2 and later.
こうしてみる。
"@libsql/client": "^0.3.5",
"@prisma/adapter-libsql": "5.4.2",
次は [ERROR] Could not resolve "util/types" というエラーが出る。
To silence this warning, pass in --commit-dirty=true
✘ [ERROR] Build failed with 1 error:
✘ [ERROR] Could not resolve "util/types"
../node_modules/@prisma/adapter-libsql/dist/index.mjs:7:30:
7 │ import { isArrayBuffer } from "util/types";
╵ ~~~~~~~~~~~~
解決!
@prisma/adapter-libsql は最新にして、@libsql/clientを下げたら解決された。
"@libsql/client": "^0.8.0",
"@prisma/adapter-libsql": "5.21.1",