[入門・CNN]画像から背景を削除するAIを作る方法(単語, 理論をおさらい)
まずはじめに -自己紹介と本記事についてー
初めまして、これが初投稿となります。地方の高専・(当時2年)電子情報工学科に通う「さめまる」と申します。ネットワーク, セキュリティ, Webについて勉強中の身です。
本記事は、「CNN(畳み込みニューラルネットワーク)」の基礎, 用語, 理論等を学びたい方向けの記事となります。高専の授業で、"AI演習"というものがあり、自分で「自作画像切り抜きAIを搭載したWebアプリ」を作ることに挑戦しました。個人的には良い精度のものが作れたと思います。
当方も学び始めた身で、この分野の知識を定着させたいと思い今回の記事を書きました。
一番最後に、GitHubのとQiitaの記事(投稿予定)のリンクを貼っておきました。実際に使用したソースコード等を解説しています。
間違いや改善点等を見つけたらぜひコメントの方よろしくお願いします。
機械学習とディープラーニングの違い
まずはじめに、機械学習とディープラーニング(DL)の違いについて解説しておきます。
機械学習
機械学習にも何種類かありますが、ここではおおまかな概念を解説します。
ずばり、「データをもとに、人間が設定した特徴量を用いて学習し、予測・判断を実現する技術」 です。
特徴量とは、データの本質的な情報(特徴)を数値化したものをいいます。
特徴量をデータから取り出すことを、"特徴抽出"といいます。
例えば、「ある会社の売り上げを過去データから予測する」というのは、広告費, 季節, 競合の影響などの特徴量は人が決めます。よって、少なめなデータでも学習が可能です。
ディープラーニング
DL(Deep Learning), 深層学習は、機械学習の一種です。
「データを判断する特徴量を学習し、より高精度な予測・判断を可能にする技術」 です。
例えば、
「画像を見て犬か猫かを自動判別する」というのは、犬か猫かを判別する特徴量も自動で学習します。
よって、学習には大量なデータが必要です。
まとめると、
| 学習 | 学習対象 | データ量 |
|---|---|---|
| 機械学習 | 人が定義した特徴量の関係性 | 少数のデータでも可能 |
| 深層学習 | 特徴量含む生データ | 大量のデータが必要 |
そもそもニューラルネットワークってなに?
ニューラルネットワーク(NN)とは、「人間の脳の働きを数式で模倣した機械学習モデルの1つ」 です。"機械学習モデル"はプログラムと言い換えていいです。
脳科学の分野で、神経細胞のことをニューロン と呼びますが、これが語源です。
(※本記事では、NNと略させていただきます。)
ニューラルネットワークの基礎
ニューラルネットワークの基礎中の基礎をおさらいしておきましょう。
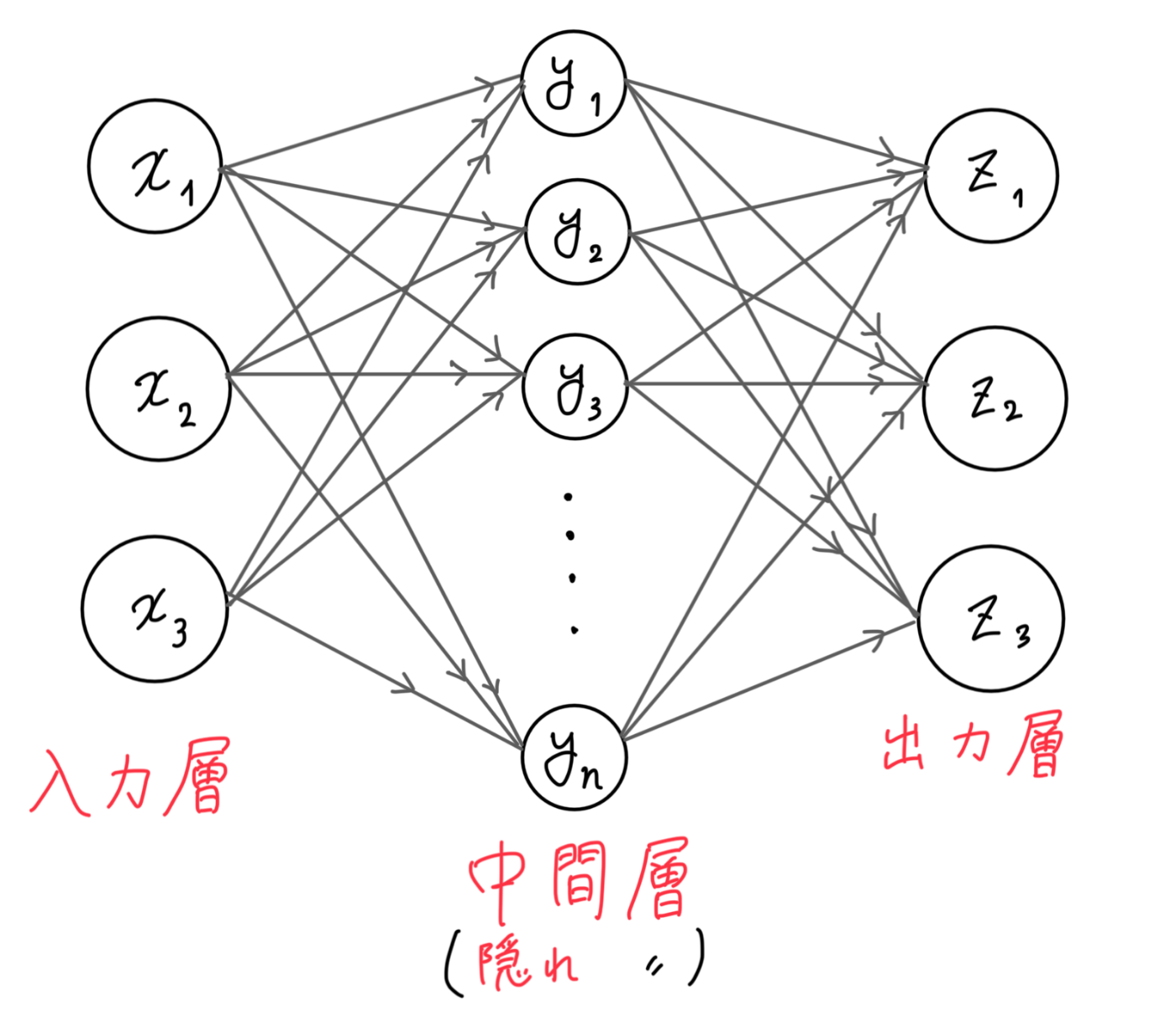
以下の図にある通り、NNは"入力層", "中間(隠れ)層", "出力層"から構成されます。
そして、層の1つ1つの処理部分を"ノード"といい、それらが"エッジ"で繋がっています。
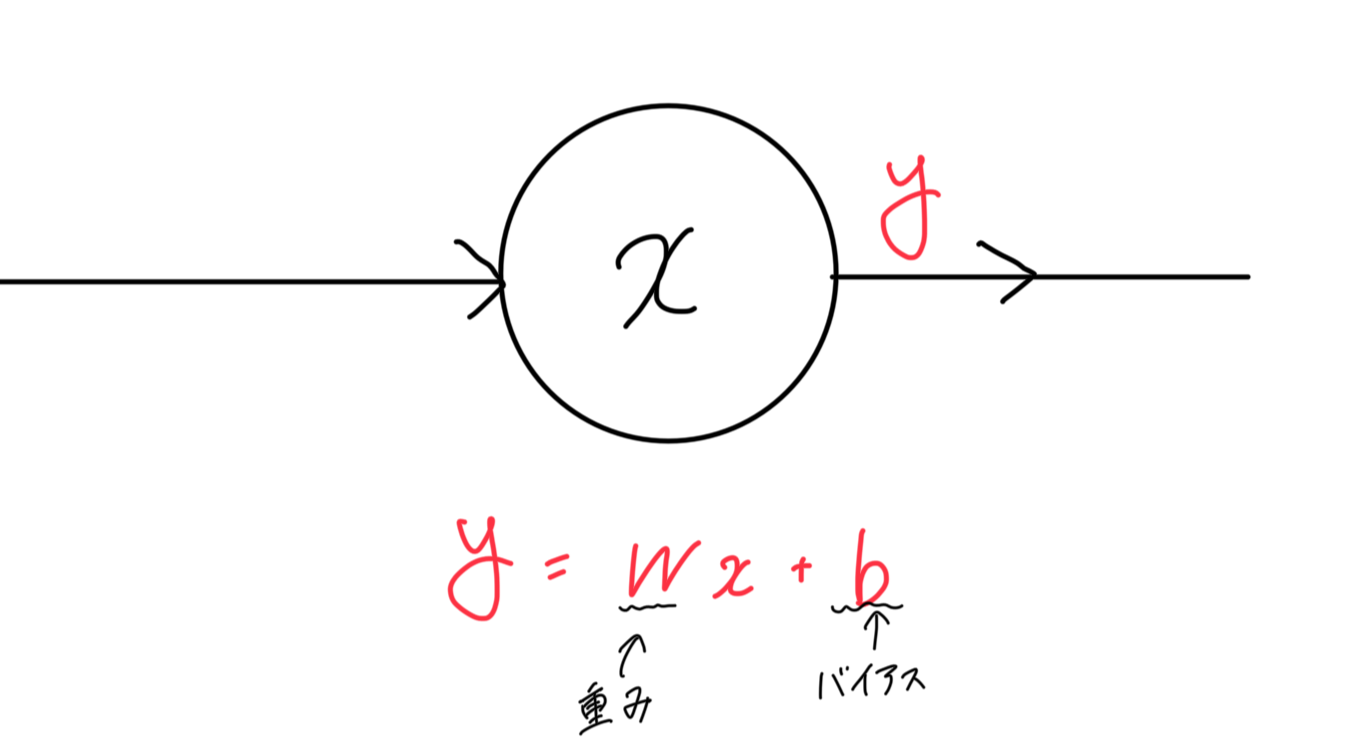
(※普通、NNの記号は
この式はAIについて勉強している方なら一度は目にしたことがある式だと思います。
1つのノード
では、この出力値がどうなればいいか、どうなるように重みやバイアスを調整すれば、学習するのか。そもそも"学習"のゴールってなに?
という話を、以下セクションで詳しく解説していきます。
まずは、本記事のテーマ「"CNN"ってなに?」という話から進めていきます。
CNNとはなんぞや? -畳み込みニューラルネットワーク-
本記事の"CNN"は、米国のニュース報道局のことではありません(笑)。
2012年、画像認識競技会ILSVRCにて、画像認識・ディープラーニング界に激震が走ります。
トロント大学のヒントン教授らが、誤差率がとても低いニューラルネットワークを開発し勝利しました。名はAlexNetです!
その構造(アーキテクチャ)はCNN(Convolutional Neural Network), "畳み込みニューラルネットワーク"と呼ばれました。
主に画像解析, 認識等のタスクでつかわれます。具体的には、
- 画像分類(画像を特定のカテゴリに分類(犬or猫etc...))
- 物体検出(画像内のどこに, 何があるかを特定)
- セグメンテーション(ピクセル単位の分類で物体の領域を特定)
などがあります!
従来のNNとの違い
ここでは詳しいアーキテクチャ(層の構成)について解説していきます。
その前に、ディジタル画像って
- 距離が近いピクセルは似た情報である(色が近い(連続的))
- 画像の一部を拡大すると、全体と似たようなパターンが見られることがある。(自己相似性)
などの特徴があります。
これらの特徴により、CNNは効率的に画像の特徴を捉えることができるのです。
従来のNNは、入力層が全結合層で構成されていました。
画像を全結合層で入力すると、どういうことが起きるかというと、「各ピクセルを1列に並べて学習を始める」てしまい、画像の空間的な情報は無視されます。つまり、ディジタル画像の特徴が生かされないのです。
そこで登場したのが、CNNなわけですね~
CNNの"3つの層" -畳み込み&プーリング, 全結合層-
CNNの最大の特徴は、3つの層(レイヤー)「畳み込み層」, 「プーリング層」, 「全結合層」です。
順番に解説していきます。
畳み込み層
畳み込み(Convolution)層は、「入力された画像データを、フィルタ(カーネル)を使って畳み込み演算、特徴マップを作成」 します。
特徴マップというのは、特徴抽出して得られるデータのことです。(数学的には、特徴マップは行列です)
"畳み込み演算"というのは、「入力データとフィルタの対応する要素同士を掛け合わせ、最後に合計する」という積和演算のことです。そのフィルタを何度も移動させて、特徴マップを完成させます。
この移動の間隔をストライド(stride)といいます。
"フィルタ"というのが、CNNで学習するものになります。
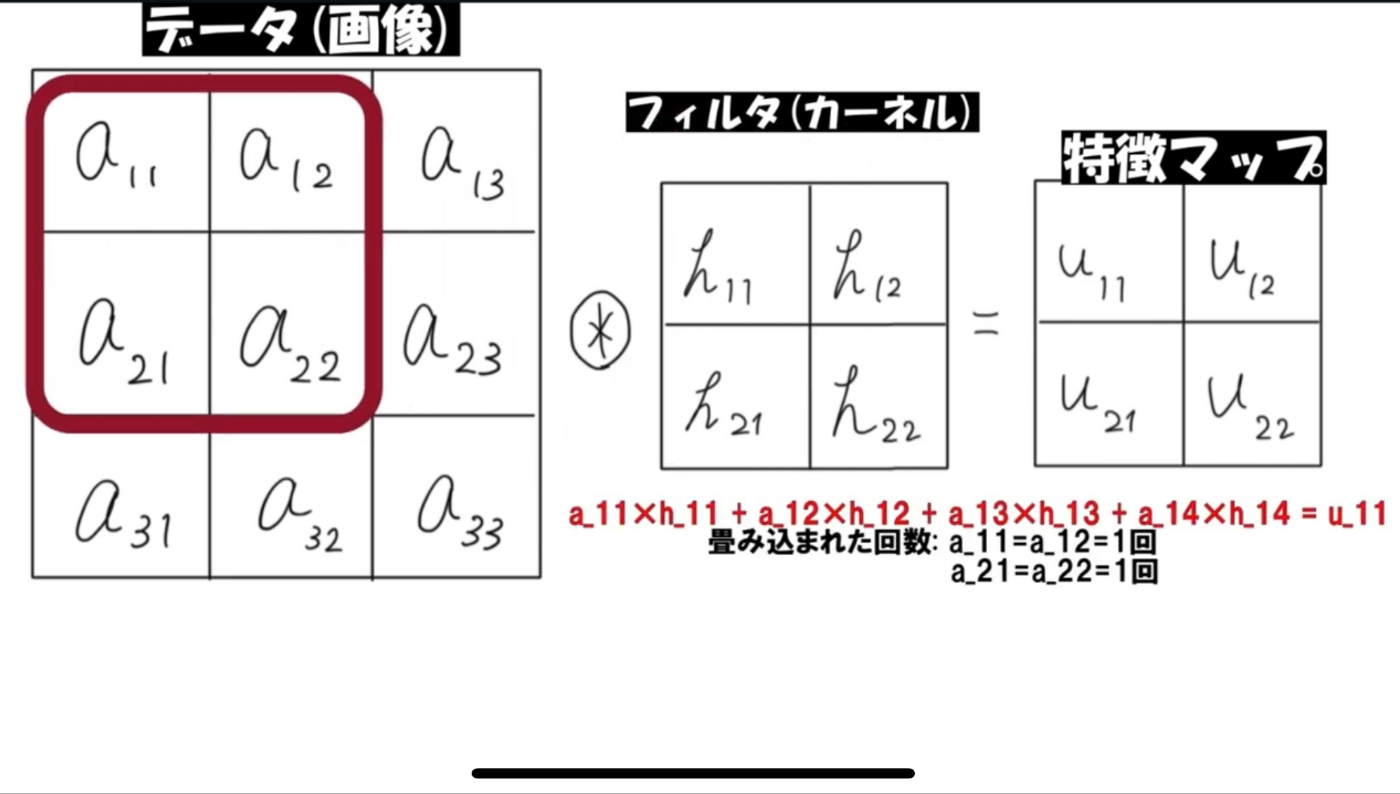

(ここではわかりやすくフィルタの要素を
しかし、画像の「畳み込まれた回数」を見ていただければわかりますが、データをそのまま畳み込むと、端の要素と中央の要素でフィルタにかけられる回数に差が出て しまい、特徴マップが不完全になってしまいます。
そこで、 ゼロパディング という手法を使い、「入力データの周囲に0の要素を埋め込んで、端の要素も2回フィルタにかけられる」ようになります。
もう一つ、これは実際にNNを構成するときに注意することなのですが、畳み込み層を通ると、データサイズはどんどん変化します。が、最終的には正解ラベルのデータとサイズを一緒にしなければなりませんので、逐一データサイズを計算する必要があります。入力データサイズの1辺を
プーリング層
畳み込み層で完成した特徴マップは、1層通るだけで莫大な情報量となります。ここで、プーリング層を通して、特徴マップを圧縮し、計算コストを削減させます。
プーリング層にも「最大値プーリング(MaxPooling)」や「平均値プーリング(AveragePooling)」等がありますが、ここでは最大値プーリングで説明します。
「特徴マップを、あらかじめ設定されたフィルタの大きさに従って最大値を抽出する」 のが最大値プーリングです。
例えば、4×4の入力データをフィルタサイズ2×2で最大値プーリングすると、入力データ2×2の最大値の要素4つが集まった2×2のデータに圧縮されます。
特徴マップを縮めるなんてことしていいのか、と思いますよね?
ディジタル画像の特徴を思い出してください。画像の一部は、全体と似たパターンが出る自己相似性がある。この特徴のおかげで、プーリングを行っても画像の重要な情報を損なうことなく、学習が可能なのです。
プーリング層通過前のデータサイズの1辺を
表にまとめるとこんな感じです。
| 層 | 学習するもの | 出力されるもの |
|---|---|---|
| 畳み込み層 | フィルタ | 特徴マップ |
| プーリング層 | なし | 特徴マップを圧縮したもの |
この"畳み込み層->プーリング層"という流れを何度も繰り返し、出力層へ向かっていきます。
全結合層
最後は、"全結合層(Affine変換)"に通されます。
畳み込み層で特徴抽出し、プーリングでまとめる... これらは画像認識の準備段階でした。
学んだ特徴量に基づいて認識・分類を行うのが、全結合層となります。
例えば、「入力された画像が犬か猫かを分類する」CNNは、入力された画像が"犬である確率"と"猫である確率"の2つの値が必要となります。
「犬の"確信度"」を算出するのが全結合層の役割です。
活性化関数セクションで詳しく話しますが、全結合層のみで"確率値"が出力されるわけではありません。
主に出力層に全結合層が使われます。
損失関数
次に損失関数(誤差関数)について説明します。
損失関数とは、「入力データに対する正解と予測の差」を計算するために必要です。
学習のゴールは、「その正解と予測の差を0にする」 ように目指すことです。
予測とは、学習している重みやバイアスのことです。
例えば、"平均二乗誤差(MSE, Mean Squared Error)", "クロスエントロピーロス(CELoss, Cross Entropy Error Loss)"などがあります。
基本どれを使ってもよいのですが、例えば画像セグメンテーションでは、「ピクセルが認識対象かそれ以外か」の2値分類となりますので、2値分類に特化した"バイナリクロスエントロピーロス(BCELoss, Binary Cross Entropy Loss)"を使います。
活性化関数
畳み込み層->プーリング層の間に、活性化関数 が必要です。
また、全結合層の後に活性化関数が必要とされる場合もあります。(ケースバイケースということです)
活性化関数とは、「入力が線形な関数でも出力を非線形な関数にしたりと、出力を調整することができる」というものです。
例えば「画像を見て犬か猫かを自動判別する」CNNを作るには、
最終的にはその画像が「犬である確率」と「猫である確率」の2値が必要です。全結合層で出力されるのは、「犬の確信度」のみです。この確率もどきの値で、一応犬か猫かの判別は可能です。
じゃあそれでいいじゃんって思う方もいるかもしれませんが、その確率もどきの値を"0~1までの真の確率の値"に変換することができれば、"しきい値"を設定することで、例えばその確率値が0.5以上ならすべて犬と判断する, のようにモデルの挙動を変えることができます。
この例のように全結合層の出力を確率値に変えたりすることができるのが、活性化関数です。
上の例だと「シグモイド(Sigmoid)関数(
「NNの基礎」セクションの図をもう少し詳しく見ていきましょう。
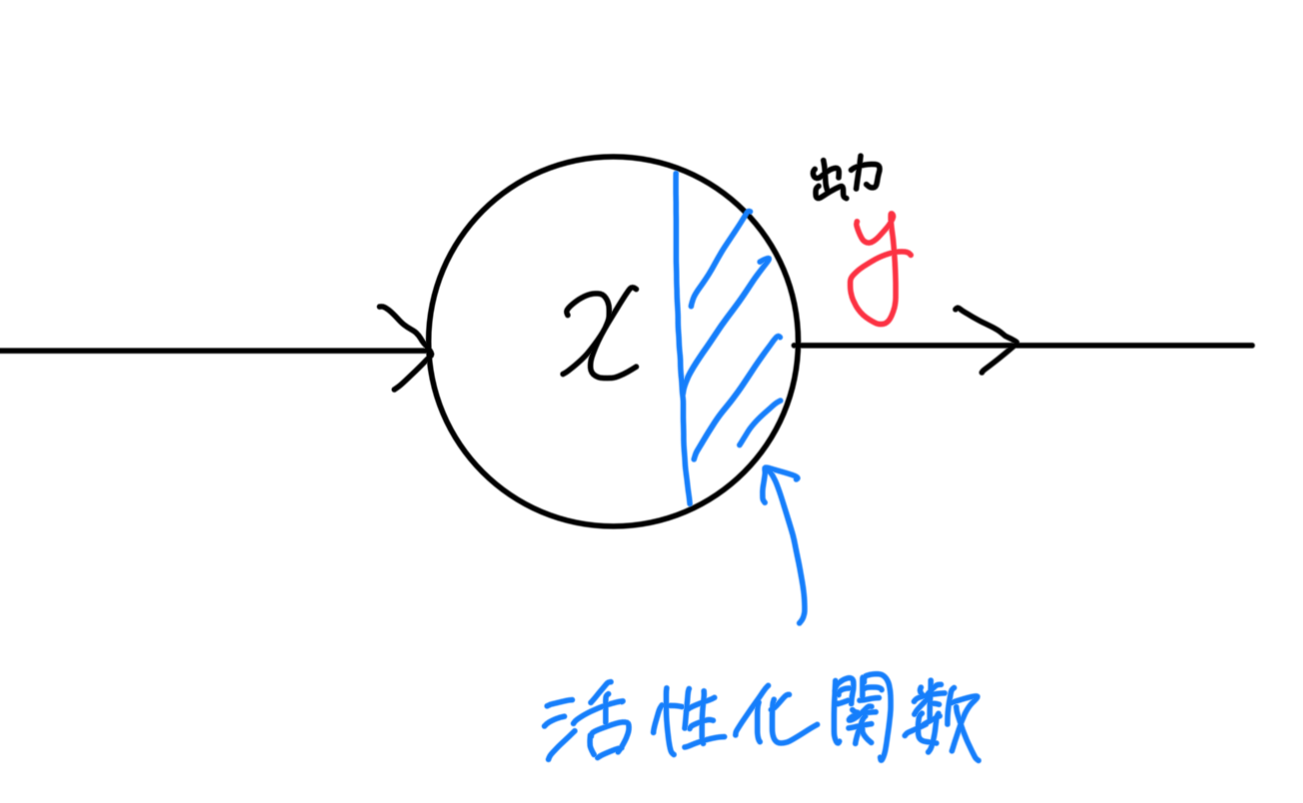
ノードに入力された値は、活性化関数を通して出力され、次のノードに入力されます。
使用する活性化関数を
出力は活性化関数で計算された値が出力されるので、式
この活性化関数は基本的には、
「畳み込み層->活性化関数->プーリング層->...->全結合層」という感じで、畳み込み層の直後に使われることが多いのですが、活性化関数は適当に選んでいい、というわけでもないのです。
これについては、後の「勾配消失問題」のセクションで詳しく解説します。
勾配 ー誤差逆伝播法ー
ここで学習時「どんな風に、誤差が伝播するのか」という話をしたいと思います。数学の"微分"の概念が入ってきます。小難しい話ですし、これを理解しないとCNNを作ることはできないというわけではないので、完璧に理解する必要はありません。
勾配
損失関数のセクションで、学習のゴールは「正解と予測(重み, バイアス)の差が小さくなる」ことと言いましたが、その"差"のことを"勾配"といいます。
学習過程で、その勾配を小さくするには、どうすればいいのでしょうか?
そうです、微分です。
微分とは、関数の接線の傾きを求めることでした。その接線の傾きの値が分かれば、重みをどう変化させれば損失関数の値が小さくなるかを予測できるのです。
といっても、その重みは、前のノードの活性化関数が噛んでいるので、偏微分 という計算です。
具体的には、以下のグラフを見てください。
曲線が損失関数, 縦軸
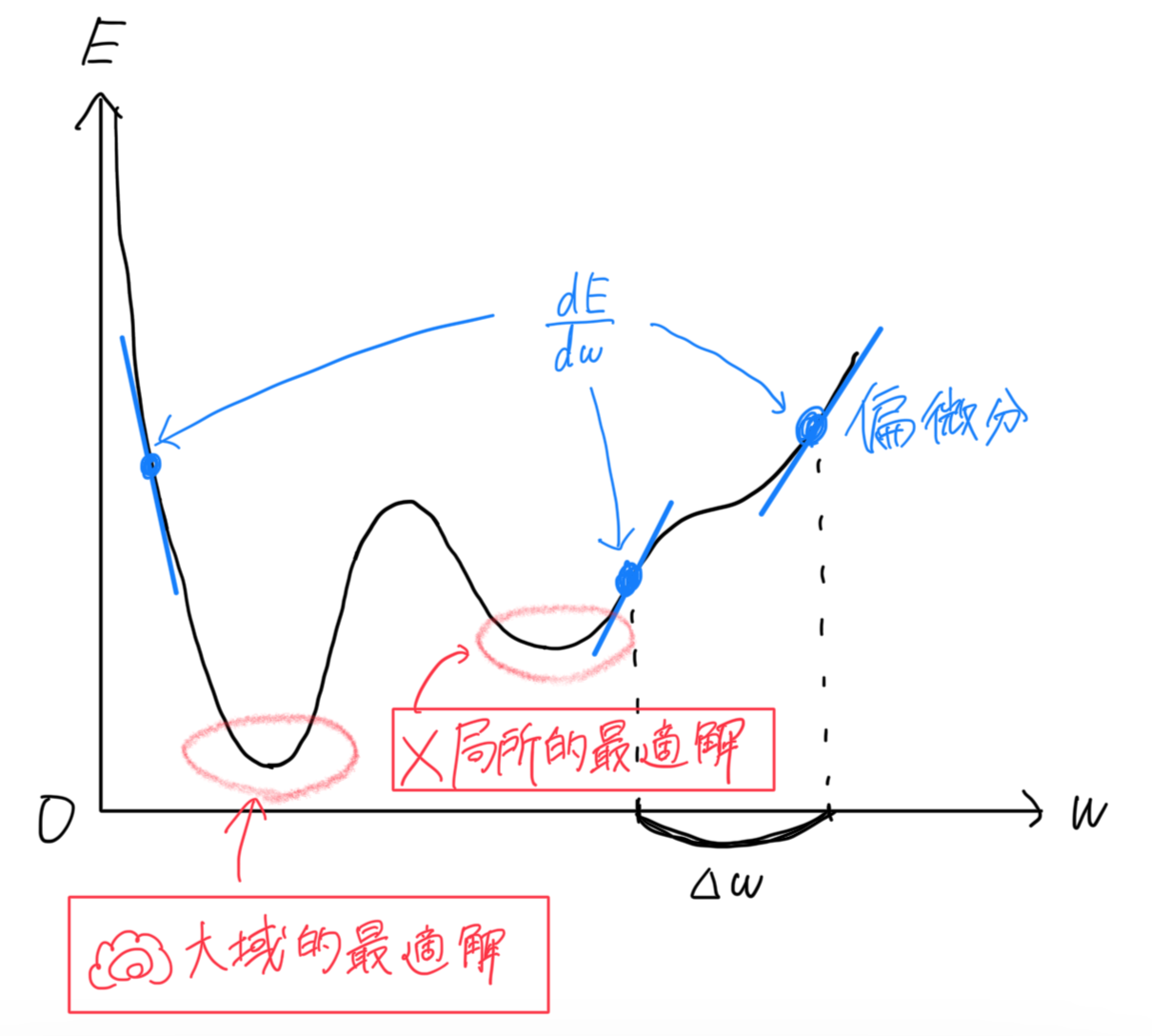
ゴールは、一番損失関数の値が小さくなる最小値, "大域的最適解"周辺です。
最小値では、接線の傾きが0に近くなります。つまり、接線の傾きが小さくなる方へ重みを移動させれば最小値にたどり着けるということです。
誤差逆伝播法
入力データは入力層->出力層に向かって最終的な出力を得ます。
このプロセスを"順伝播"といいます。出力を得た後、正解と比較して、誤差が計算されます。
誤差がどの重みによって生じたかを探し当てるため、その誤差を伝播させます。
しかし、結論を言えば、誤差は出力層->入力層のように逆伝播します。このプロセスを、"誤差逆伝播法(バックプロパゲーション)"といいます。
なぜ誤差を順伝播してはダメなのか
それは、「もし誤差を順伝播させれば、出力層側のノードすべてに影響を及ぼすから」です。
順伝播だと、入力層側の層に修正が入ります。すると、その層の修正は出力層側の層すべてに影響を及ぼすのです。
具体的には、「活性化関数」セクションの式をもう少し詳しく書いてみると分かります。
(1層目から
この式で
入力層側、一番内側の
しかしこれが逆伝播だと、
外側の
誤差逆伝播法について詳しい証明知りたい、という方は以下の動画を見てほしいです。
とてもわかりやすいのでおすすめです。
最適化アルゴリズム -オプティマイザ-
もう一つここで紹介しておきたいものがあります。それは、"最適化アルゴリズム(オプティマイザ)"です。
役割は、「損失の値を0にする」というゴールまでなるべく効率よく到達する手助けをし てくれれることです。"勾配降下法", "確率的勾配降下法", "モーメンタム" 等ありますが、ここでは代表的な2つだけ解説したいと思います。
勾配降下法
最適化アルゴリズムには複数あるといいましたが、すべて"勾配降下法(最急降下法)(Gradient Descent)"の派生です。
「勾配」セクションの図より、重みの変化量
勾配更新後の新しい重みを
この式は勾配更新式とも呼ばれます。
ここで、なぜ
「導関数の値が正[負]の値であれば、勾配を負[正]方向に移動する」からです。
この
確率的勾配降下法
確率的勾配降下法(SGD, Stochastic Gradient Descent)は一言でいうと、"ランダム性のある勾配降下法"です。
勾配更新式は共通ですが、勾配降下法と違うのは、
ランダムな1データだとどういう利点があるかというと、
"局所的最適解で収束しないように、「ノイズ」で勾配計算にばらつきを生じさせ、極小値から抜け出す手助けをする"という点です。
"学習のゴールは最小値、つまり微分した値が0になる点"といいましたが、微分した値が0になるのは最小値とは限りません、"極小値"でもそうです。
最小値, 極小値、どちらもくぼみという点では同じですが、別の名で
「大域的最適解」, 「局所的最適解」と呼ばれます。
再度図を提示します。
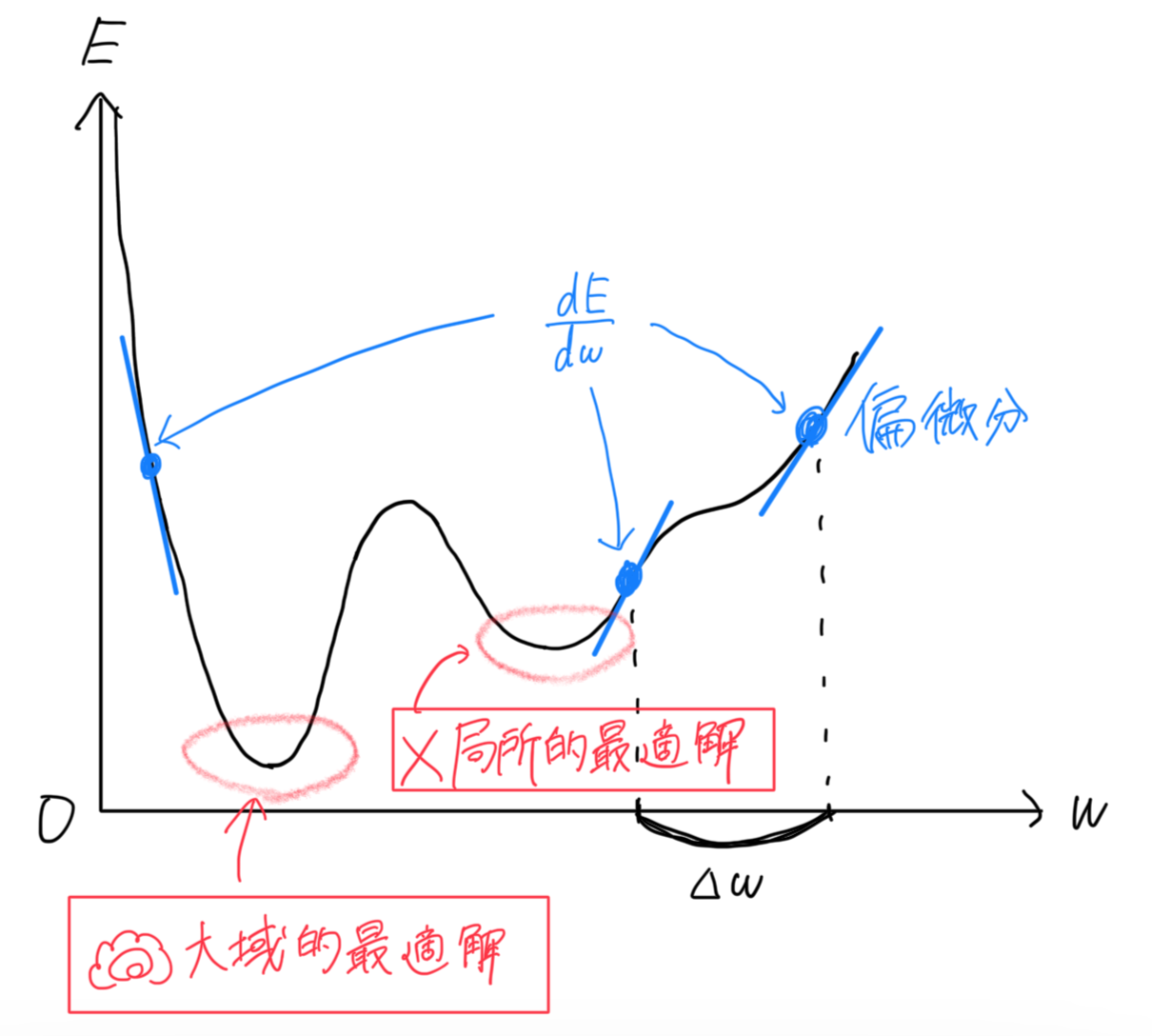
この図の局所的最適解は、偽物です。見かけ上、その点で差が0だと誤認してしまい、学習が停止してしまいます。
そこで、ランダムなデータを勾配更新の取っ掛かりとすることで、"ノイズ"が発生します。そのノイズが、勾配更新にばらつきを生じさせ、極小値から抜け出す手助けをしてくれます。ノイズって悪いイメージが多いですが、そうとも限らないのがこの例です。
勾配消失問題
3つのレイヤー"畳み込み層", "プーリング層", "全結合層"、"活性化関数"で出力を制限、目標の"損失関数", 勾配修正の"オプティマイザ"...
CNNを構成するパーツが上セクションで学習できましたね。
ここで、勾配消失問題というのを解説します。
勾配消失問題とは?原因は??
勾配消失問題とは、主に中間層で発生します。
NNの層が深くなるにつれ、伝播していく誤差がどんどん小さくなり、
重みが更新されにくくなる問題です。これは、学習を妨害する深刻な問題です。
原因は、不適切な活性化関数を使用すること です。
例えば、中間層の活性化関数にシグモイド関数を使ったとしましょう。
シグモイド関数には、"微分値は必ず1より小さくなる"という性質があります。
活性化関数のセクションの最後でお話しした通り、重み
ですので、微分といっても損失関数
連鎖律というものを使って計算しますが、1回の微分を2つの微分値の積の形で表す手法です。
1より小さい数を掛け合わせれば、その値はどんどん小さくなっていき、最終的にはほぼ0になります。
すると、勾配更新式
つまり、重みがほとんど更新されなくなるわけです!!
解決策
ではどうすればいいのでしょうか?
ここで紹介するのは、「適切な活性化関数を使用する」ことです。
例えば、"ReLU関数"です。
式は、
これは、xが正の数ならば微分値が1となり、勾配が消失しないということです。
しかし、xが負の数ならば微分値が0となり、学習が進まなくなる"死んだニューロン"という問題が生じることもあり、またそれの解決策となるReLU関数の派生が開発されています。
活性化関数は、中間層と出力層でそろえる必要はないので、目的に応じてそれぞれ選択する必要があります。
その他用語
ここでは、実際にコーディングする際に使用する言葉について解説していきます。
データセット, 教師データ
学習データ全体を管理するクラスのことです。
例えば、「画像データ」とそれに対応する「正解ラベル」(犬の画像->ラベル0, 猫の画像->ラベル1)の紐づけを行ったりします。
ちなみに、画像データと正解ラベルのセットを"教師データ"といいます
データローダ
データセットから複数のデータとラベルをまとめて取得し、小分けにするクラスことです。
「小分け」については、次に解説しています。
バッチ
例えば、「1000枚の画像データ」(データセット)を学習するとしましょう。
計算の効率化のために、この学習するデータを小分けにします。
1000枚を「200枚のグループ」に分けると、1000枚のデータを一巡するには「5回」となりますよね?
この「200枚のグループ」を"バッチサイズ", 「5回」を"イテレーション"といいます。
つまり、言い換えると1000枚を「バッチサイズ200の5イテレーションに分けて学習する」となります。
エポック
データセット全体で何回学習するかのことです。
もし3エポックで学習するなら、「1000枚×3回」のデータが学習に使われることになります。
ただし、同じデータを繰り返し学習するイメージです。
過学習
訓練データに対して学習しすぎて、新しいデータでうまく予測できなくなる現象のことです。
過学習を防ぐためには、データを増やすなどの対応があります。
まとめ
これで、CNNの基本中の基本が抑えられましたね✨
まとめです。
- CNNは、ディジタル画像の特徴を生かしたニューラルネットワーク
- CNNは、"畳み込み層", "プーリング層", "全結合層"から成る
- 適切なオプティマイザと活性化関数の選択が必要
具体的なプロセスは、
- 順伝播
入力データを順方向にNNへ流し、最終的な出力を得る - 誤差の計算
出力層での誤差を損失関数を用いて計算 - 逆伝播
出力層から順に誤差を逆向きに伝播
どの方向に、どれだけ修正するべきかを計算(\frac{dE}{dw} - 重みの更新
勾配更新式を使い、重み, バイアスを更新(w_{new}=w_{old}-η\frac{dE}{dw}
難しい数式の証明等は割愛して解説させていただきました。
といっても、CNN, AIって、微分以外は難しい数学は使われていないのがまた面白いところです。
参考文献下のリンクにて、実際に初めてCNNを用いて制作した「自作画像切り抜きAI」についての記事を投稿予定です。授業の発表用に作ったものなので精度はまちまちですが、参考になれば幸いです。
またWebアプリ形式にしたのでそちらの記事も公開予定です。
そちらもぜひよろしくお願いします。
最後までご覧いただき、ありがとうございました。
参考文献
- 「PyTorch実践入門 ~ディープラーニングの基礎から実践へ」, イーライ・スティーブンス(訳 小川雄太郎)等, 2021年初版
- 「~画像認識技術の進化を実感~CNNの歴史Part1」, yan, https://gri.jp/media/entry/364, (2021.06.12最終更新), 2025年3月1日アクセス
- 「機械学習とディープラーニング(深層学習)の違いとは?」, AIsmiley, AIsmiley編集部, https://aismiley.co.jp/ai_news/what-is-the-difference-between-deep-learning-and-machine-learning/, (2024.03.04最終更新), 2025年3月1日アクセス
- 「畳み込みネットワークCNN(Convolutional neural network)」, Qiita, DeepTama(DeepTama)in NPO法人AI開発推進協会, https://qiita.com/DeepTama/items/379cac9a73c2aed7a082, (2023.12.26最終更新), 2025年3月1日アクセス
- 「【決定版】スーパーわかりやすい最適化アルゴリズム -損失関数からAdamとニュートン法-」, Qiita, omiita(オミータ), https://qiita.com/omiita/items/1735c1d048fe5f611f80, (2024.06.11最終更新), 2025年3月1日アクセス
- 「第10回 ニューラルネットワークの計算式」, YSE/AI入門, 未来を切り開くOT・AI・デジタルビジネス人材を育む YSE 横浜システム工学院専門学校, https://www.yse.ac.jp/pickup/ai/vol10.html, 2025年3月1日アクセス
- 「全結合層」, AI用語集(G検定対応), https://zero2one.jp/ai-word/fully-connected-layer/#:~:text=全結合層とは,を示す確率となります。, 2025年3月1日アクセス
- 「勾配消失問題とは?活性化関数が原因となる理由や解決方法を分かりやすく解説」, JITERA, 武宮太雅, https://jitera.com/ja/insights/41710, (2024.11.06最終更新), 2025年3月1日アクセス
- 「ニューラルネットワークの数学(逆伝播)」, ディープラーニングの基礎(PyTorch), キカガク, https://free.kikagaku.ai/tutorial/basic_of_deep_learning/learn/neural_network_basic_backward, 2025年3月1日アクセス
- 「【超優しいデータサイエンス・シリーズ】機械学習とディープラーニングの関係は?」, yan, https://gri.jp/media/entry/437, (2020.12.07最終更新), 2025年3月1日アクセス
- 「機械学習と深層学習の違いとは?メリットや課題を挙げながら解説」, DSK 株式会社電算システム, https://www.dsk-cloud.com/blog/difference-machine-learning-and-deep-learning#toc-2, (2022.04.27最終更新), 2025年3月1日アクセス
- 「押さえておきたい機械学習とディープラーニングの違い」, 株式会社 日立ソリューションズ・クリエイト, https://www.hitachi-solutions-create.co.jp/column/technology/machine-learning-deep-learning.html#h2-1, (2019.11.21投稿), 2025年3月1日アクセス
- PyTorch -独自データセット(custom dataset)の作り方【初級 深層学習講座】, ある(Aru)'sテクログ 主にプログラミング・AIについて発信するブログ, https://tech.aru-zakki.com/pytorch-custom-dataset/, (2024.09.13最終更新), 2025年3月2日アクセス
編集者のGitHub, Qiita記事のリンク
- Github
AI_jikken -
後日投稿予定
Qiita「【AI・初心者】高専生が自作画像切り抜きAI搭載Webアプリを作ってみた話」
Discussion