text-generation-webuiコトハジメ
概要
GUIでNLPを扱える「text-generation-webui」を使えるようになる
Windows環境なので、よろしくお願いします
レポジトリ
環境構築
venvの作成(最初だけ)
python -m venv .venv
venvの読み込み(毎回)
.\.venv\Scripts\activate
ライブラリのインストール
pip install -r requirements.txt
GPUが使えるPytorchを別途インストール
pip install --upgrade torch --index-url https://download.pytorch.org/whl/cu118
bitsandbytesを以下の方法でWindowsでも使えるようにする
起動
python server.py
このあとhttp://127.0.0.1:7860/がアクセスできるようになるはずなのでアクセスすればOK
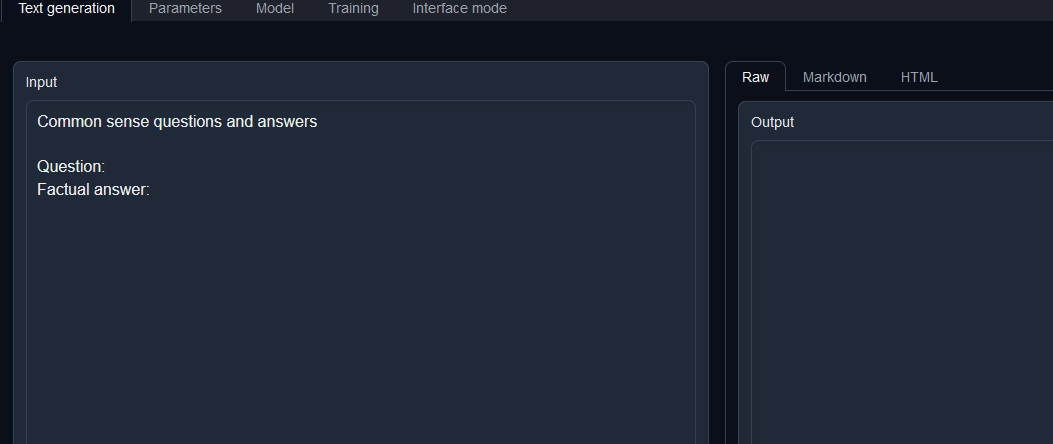
テキスト生成
まずModelタブに行きModelを選択する。このModelは下にある「Download custom model or LoRA」からhuggingfaceのものをダウンロードできる。今回は
「cyberagent/open-calm-small」を入れた
そのあとModelを選択し、Text generationに移動する。Transformersの設定に関してはload-in-8bitとかあるので適宜設定するが、今回は無視
InputにPromptを書くが、Promptはテンプレートが使用できるので、下から選択、そうするとInputの値が変わるので、あとは好きにテキストを書いてGenerateを押す。
訓練
Modelで訓練したいModelを選択し、Trainingタブに移動。
下にある三つを選択する必要がある
- Dataset
- Evaluation Dataset
- Data Format
Fomatの作成
alpacaベースだが、dolly-15k-jaはindex,instruction,(input),output,categoryの4or5カラムのフォーマットになっているため、それに対応したフォーマットを作成する必要がある
training/formats/alpaca-format.jsonをコピーし、「databricks-dolly-15k-ja-format」にリネーム、以下のように変更。
やっていることはinputがあるバージョンとないバージョンの二パターンを登録する感じ
{
"instruction,output": "Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n%instruction%\n\n### Response:\n%output%",
"instruction,input,output": "Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.\n\n### Instruction:\n%instruction%\n\n### Input:\n%input%\n\n### Response:\n%output%"
}
これでFormatの準備は完了
Datasetのダウンロードと配置
Datasetはダウンロード機能がまだないので自分で落としてくる必要がある。
以下からjsonファイルをダウンロード、text-generation-webuiのtraining/datasetsに配置
Datasetの整形
databricks-dolly-15k-jaはinputsがない時は空文字として渡すことになっている。これだと全部inputsがあるバージョンに入ってしまうため、いらないinputを消す必要がある。
"input":""\nみたいな感じで検索し、検索にヒットしたものを削除する。
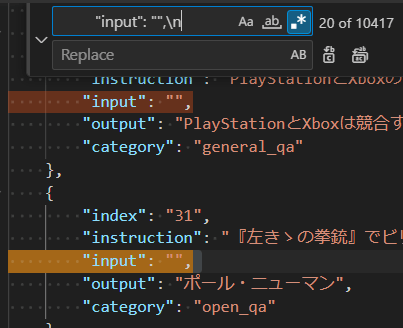
これでDatasetの整形も完了
実行
Nameを指定、Dataset、Evaluation Dataset, Data Formatを選択しStart LoRA Trainingを実行
もしも選択肢にでてこなかったら以下のボタンを押すと再読み込みできるのでやってみること。

しばらくしたら以下のようなものがでてくるので、その後は気長に待つ。
