(DL論文)【ICLR2023】Visual Recognition With Deep Nearest Centroids(DNC)


はじめに
ICLR2023にある論文を読んでみて、論文解説してみました。
今年から研究を始めたばかりでまだ知識も浅いですので、曖昧な部分が多いかもしれません。
概要
・古典的な分類手法であるNearest Centroidsを改良したDeep Nearest Centroids(DNC)を提案
・通常のNNにおけるClassification Layer(分類層)において、DNCに置き換えることで推論結果の説明性を向上
・出力の次元数がクラス数に依存せず、source task からtarget taskへのパラメータの輸送性を向上
・画像分類とセグメンテーションにおいて、精度も向上した
前提知識及び注意点
パラメトリックとノンパラメトリックについて
パラメトリックは、「このパラメータでは、これになる確率が多い」というように、確率分布に従うので、外れ値に弱い(t検定など)
ノンパラメトリックは、分布を仮定しない(事例ベースの推論)ので、パラメトリックよりも外れ値に強い
(ウィルコクソンの順位和検定など)
DNCについての注意点
DNCはNNモデルではなく、分類器である
バックボーンはResNetなどであり、分類層をDNCに置き換えている、つまり、バックボーンから来た特徴量をsubcentroidによりクラスタリングし、分類するという手法である
自分が読む上でよく勘違いしていた
背景
著者は従来のDNNの分類器(層)の欠点について以下を挙げている
1.説明性に欠けている
2.特定のタスクに最適化されており、モデルの潜在データを活用できていない
3.事前学習において、通常分類層を切り離すので、重要なパラメータが失われてしまう
つまり、特徴量の分布を学習により推定し、その分布に基づいて出力、所謂パラメトリックな手法
提案手法
以上の問題に対して、DNCは
DNC
1.特徴量分布に依存していない
2.事例(距離)ベースの推論を行う(ノンパラメトリックな手法)
3.出力結果に対する説明性を持つ
DNCとは何なのか
古典的手法であるnearest centroids分類器を改良
※nearest centroids分類器とは、学習時、クラス毎に重心を求め、推論時、重心が最も近いクラスに分類する方法(k-meansクラスタリングと手法は似ている?)
提案手法DNCでは、ニューラルネットワークで抽出した特徴量に対して、クラス毎に重心を求める
それに加えて、クラス内でサブ重心に分け(k=4)、クラス分類を行う
この重心およびサブ重心を学習中に更新していく(オンラインクラスタリング)
計算量が大きいので、それを改善するためにSinkhorn Iterationアルゴリズムに基づいてオンラインクラスタリングを行う
つまり、教師あり表現学習と教師なしのサブクラス重心の決定を行っている
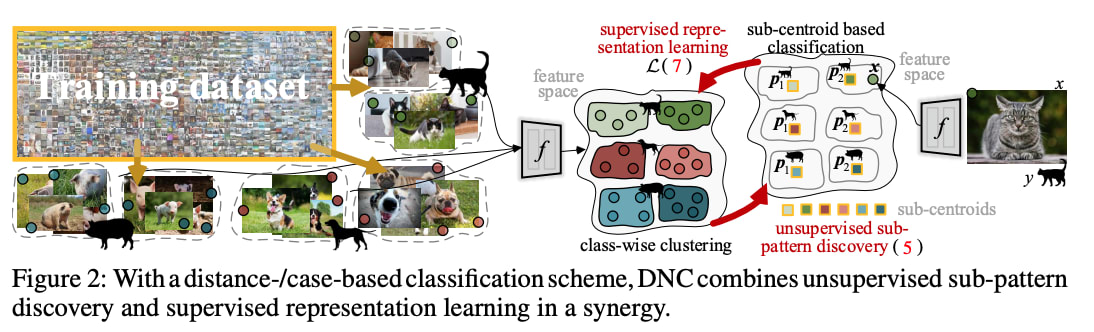
重心およびサブ重心の更新は、momentum的に実行する
セグメンテーションも、ピクセル毎に分類を行う
説明性を向上とは、従来の分類器は確率(犬60%など)を指標としていたが、
NearestCentroid分類器は入力特徴量とクラスタの代表との特徴間距離(犬が1番近いけど、猫が2番目に近いなど)を指標にする『メトリック分類器』である。この意味で、説明性を向上と著者は言っている
以下の図のように、判断根拠を入力画像との類似度をベースに表示することができる

解釈可能とは、距離ベースの分類器はノンパラメトリックであり、人間の行う経験ベースの分類に似ている。その意味で、DNCは解釈可能である。

サブ重心の推定
より有効な表現を示すサブ重心を求めるため、決定論的なクラスタリング手法を、特徴空間内で行った
特徴行列
以下の式を解くことで、サブ重心を推定する
ここで、
※Sinkhorn Iterationアルゴリズムについては少し曖昧な表現とさせて頂きます
ここで、
DNCの学習
以上のサブ重心推定処理により、クラス数Cとサブ重心数Kの、合計C×K個の特徴ベクトルが得られる
特徴行列
つまり、DNCの学習は、教師あり表現学習とクラス毎の重心推定(上の式)の繰り返しである
学習の過程で特徴空間は変化するので、それに応じてサブ重心まで推定するのは、高速なSinkhorn アルゴリズムと言えども、計算負荷が大きい
そこで、以下のようにmomentum的にサブ重心
ここで、μはmomentum係数、xは現在のバッチ内での、クラスcのサブ重心kに割り当てられた平均特徴ベクトルである
しかし、表現学習において、バッチ数が小さいと表現の精度も落ちてしまう
そこで、前のバッチ分の特徴量を保存しておき、保存した特徴量と現在の分でクラスタリングを行う
関連手法
kNNを分類器として教師あり表現学習を行う手法も提案された
しかし、nearest neighbor法はあまりクラス表現の学習には向いていない
nearest centroidsをDNNの分類器に使う研究もあったが、その時はサブ重心を用いず、特徴表現を細かくできていなかった(つまり、クラス毎に1つの表現しかない)
サブ重心(sub centroids=prototype)に分けて、今まで見たものに基づいて物事を認識するという方法は、心理学のプロトタイプ理論に当てはまる
よって、DNCは人間が普段行っている認識方法を模倣している
実験
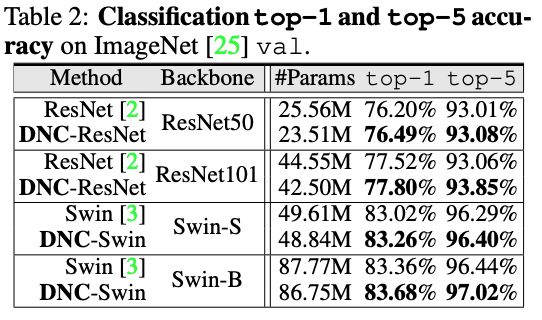
画像分類
CIFAR-10とImageNetをデータセットとして用いる
CIFAR-10:200epoch
バッチサイズ:128,
学習率:ResNet 0.1
schedule:step polynomial annealing
サブ重心の数:K=4
μ:0.999

ImageNet:100(ResNet), 300(Swin Transformer)epoch
バッチサイズ:16
学習率:ResNet 0.1(ResNet), 0.0005(Swin Transformer)
schedule:step(ResNet) polynomial annealing(Swin Transformer)
セグメンテーション
最後の1×1畳み込み層を外して、DNCを入れる
サブ重心の数:K=10
μ:0.999
学習率:0.1(backbone:ResNet101), 6e-5(backbone:Swin-B)
cropsize&batch:512&16(ADE20K), 769&8(Cityscapes)
data augmentation: scale&color jittering, flipping&cropping

即席(アドホック)の説明可能性についての実験
特徴量のコサイン類似度に基づいて、各サブ重心と最も近い画像を結び付ける(90epochまでは通常の学習、残り10epochでこの操作を行う)
IF,thenルールに基づいて、各サブ重心の特徴量同士のコサイン類似度を比較し、任意の画像がそのクラスに分類される過程を示す
これは人間の内部での意思決定と似ているので、説明可能性が向上していると考えられる

DNCがクラスのサブ重心同士の(dis)similarityを表示することで、推定結果の透明性を向上させることができる

サブ重心K=4の場合の、各サブ重心の代表画像

その他の実験(一部抜粋)
サブ重心, 外部メモリ(バッチサイズ), モーメンタム更新について
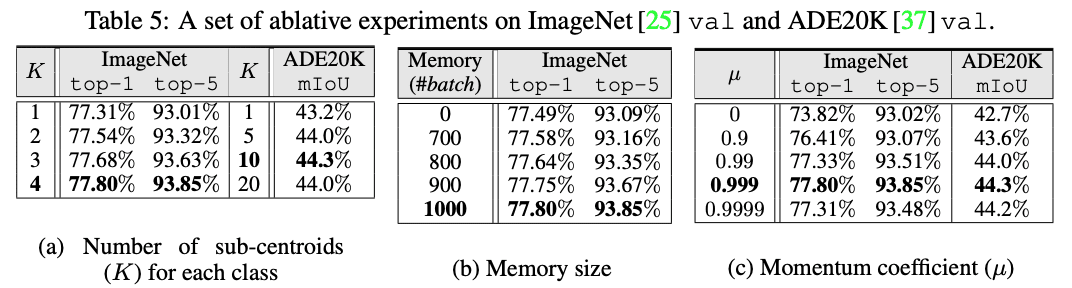
k-meansとSinkhorn との精度比較

他の距離ベース分類器との比較
DeepNCMは、k-means法をクラスタリングに用いる(サブ重心なし)

DeepNCAは、k-NN法を用いる

ContrastiveSeg-DeepLabV3は、セグメンテーションにcontrastive learningを用いる

Kをサンプル数に応じて変えた場合

これからの課題(future work)
Sinkhorn-KnoppアルゴリズムがO(n^2ε^3)時間で動作するため、学習効率が低下してしまう。
クラス毎のサンプル数に応じてKを変えることで、さらなる向上に繋がる(実際に、1〜4までサンプル数に応じて変えた結果を示す)
従って、学習時にクラスタ数を自動的に決めるようなアルゴリズムだとさらなる向上に繋がる
所感
やはりsub centroidsが効いているのかと最初に感じた(論文の著者も述べている)
事前学習する際の、学習パラメータの輸送損失が0であることは確かに有用性があると考えた
説明可能性とは、間違った例にはこの画像(サブ重心の代表から画像を引っ張ってくる)がありますよみたいなことができる、ということ?
DNCが出力次元に左右されない、とはいってもクラス毎に重心を取る時点で出力次元を変えているのではないかと考えられる
SimCLRなどの教師なし表現学習との精度比較について知りたかった→(著者の解答(Open Review))DNCはそもそも「softmaxを用いない分類器」の提案であり、SimCLRなどは距離学習の手法の1つに過ぎない
参考文献
[1] "Visual Recognition With Deep Nearest Centroids" Wenguan Wang, Cheng Han, Tianfei Zhou & Dongfang Liu
CCAI, Zhejiang University, Rochester Institute of Technology & ETH Zurich(Published as a conference paper at ICLR 2023)
Discussion