Snowflakeのクラスタリングキーと実行計画、Hiveからの移行
Snowflake Advent Calendar 2022の22日目の記事です。
お仕事でSnowflakeのクエリをいくらか書く機会があったので、その知見を共有します。
基本的には、Snowflakeのテーブルスキーマやクエリは、特に難しいことを考えなくても期待通りに動きます。とはいえ、製品内部のデータ構造を予想しながら実行計画と対話する(DBAの人たちがよくやっているやつです)みたいな作業もしばしば必要でした。
比較的性能にインパクトが大きいと感じたのはクラスタリングキーです。このキーは、無理やり普通のRDBMSに当てはめるなら、プライマリキーやインデックスに相当するものです。特に大きなテーブルに関しては、データスキャン量が不必要に膨らまないようにするため、クラスタリングキーを意識したクエリを書く必要がありました。
その辺りについて、調査方法やTIPSについてもまとめて整理しました。
注記
- この記事の知識は2021年末ごろのものが多いです。Snowflakeはどんどん機能追加がされていくので、ここにある情報もいずれ古くなるかもしれない(もう古くなっているかも?)点にはご注意ください。
- 基本的にはお仕事で使っているSnowflakeアカウント上の実行結果をそのまま載せていますが、テーブル名などは改変している箇所があります。
前知識
ここでは改めて筆者の理解を書きましたが、マイクロパーティション等については既に様々な解説記事もあるので、それらについても参照ください。
クラスタリングキー
Snowflakeの内部のデータ構造は、マイクロパーティションと呼ばれる独自構造を採用しているとされます。どんなものかというと、テーブルを一定区間ごとに水平分割した上で、カラムナフォーマット形式でAmazon S3にオブジェクトとして格納してるみたいです。
水平分割は自動的に行われるのですが、どのカラムの値を基準にして分割し内部的に保存するかをcreate table時に指定できます。指定するカラムのことをクラスタリングキーと呼びます。指定しなかった場合は……ドキュメントに記載はないと思いますが、たぶんSnowflakeにお任せということになるのでしょう。
例えば、何らかのイベント(利用者のアクセスログやシステムの内部で発生した出来事)を格納したテーブルに対しては、イベントの発生時刻をクラスタリングキーにする方針が考えられます。データがどう挿入され参照されるかに応じて適切なクラスタリングキーを指定すると、後述するプルーニングが効きやすくなる可能性が高まります。
クエリプルーニング
個々のマイクロパーティション中の値の分布について、Snowflakeはグローバルなメタデータのデータベースで管理しています。
Snowflakeは、以下を含む、マイクロパーティションに保存されているすべての行に関するメタデータを保存します:
- マイクロパーティションの各列の値の範囲。
- 個別の値の数。
- 最適化と効率的なクエリ処理の両方に使用される追加のプロパティ。
そして、SQLの実行時には、メタデータから予めスキャンする必要がないと分かっているマイクロパーティションへのアクセスを省略します。10年分のデータが入ったテーブルだけど、今は過去1週間のデータしかいらない……みたいな時だと、過去1週間分のマイクロパーティションにしかアクセスせずに済む……かもしれません。
メタデータを参照してスキャン量を削減することをプルーニングと呼びます。
ベストプラクティスの確認
そもそもクラスタリングキーは設定するべきか
公式ドキュメントは、性能上の利益が得られる時にだけクラスタリングキーを設定するべきだとしています。
クラスタリングキーは、すべてのテーブルを 対象とするものではありません。
(中略)
また、テーブルのクラスタ化を明示的に選択する前に、テーブルでクエリの代表セットをテストして、パフォーマンスベースラインを確立することを、Snowflakeは 強く お勧めします。
https://docs.snowflake.com/ja/user-guide/tables-clustering-keys.html
個人的な経験としては、数GB以下の小さいテーブルには設定するメリットを感じません。たとえ仮想ウェハハウスのサイズが小さくても、ごく短時間でフルスキャンしてくれるからです。
一方で、例えば100GBを超えるようなテーブルだとチューニングの余地が出てくるかな、という感触があります。
もっとも、会社業務で触ったテーブルたちについては、同じ種類のデータに対して一律にクラスタリングキーを設定していることも多かったです。アクセスログが格納されているテーブルは全てイベント時刻カラムをクラスタリングキーにする、といった具合ですね。
経験的に学んだこと
さて、ここからは、経験的にあれこれ学んだことの紹介になります。
お仕事で触っているテーブルは、主にApache HiveからSnowflakeに移行したものでした。Hiveにはマイクロパーティションのような柔軟そうなものはないのですが、パーティションというスキャン範囲を狭める仕組みがあります。例えば日付ごとにディレクトリを切っておきそれをHiveに登録すると、SQLのクエリに対象日付が指定されているなら、読み出すファイルをその日付範囲だけに削減してくれる仕組みです。
慣習的に、パーティションキーにはstring型のdtというカラムが使われていました。中身には'20211204'のような yyyymmdd 形式の値が入っています。
Hive向けに書かれていたSQLクエリを簡単に移植できるようにするため、Snowflakeでもほぼ同様のカラムを提供することにしました。
以下のテーブルt1は、そういった状況を擬似的に再現したサンプルデータです。
create or replace transient table t1 (event_time timestamp_tz, dt string, uri string) cluster by (dt) as
select
timestampadd(second, uniform(0, 365 * 24 * 60 * 60 - 1, random()), '2021-01-01T00:00:00+09:00'::timestamp_ltz) as event_time,
to_varchar(event_time, 'yyyymmdd') as dt,
concat('/articles/', uuid_string())
from table(generator(rowcount => 5 * 1000 * 1000))
order by event_time;
select * from t1 limit 5;
+-------------------------------+----------+------------------------------------------------+
| EVENT_TIME | DT | URI |
|-------------------------------+----------+------------------------------------------------|
| 2021-07-22 10:54:52.000 +0900 | 20210722 | /articles/260a2166-1cb8-404f-8838-d9feec2fcbd1 |
| 2021-09-11 19:41:47.000 +0900 | 20210911 | /articles/52d6cb3b-d069-453b-a786-1677484d2069 |
| 2021-07-11 01:44:28.000 +0900 | 20210711 | /articles/3be5073b-92c2-486a-a4c8-fb921dae2642 |
| 2021-07-24 10:52:14.000 +0900 | 20210724 | /articles/74dd2da2-b6fc-4c42-b9e8-bd888cf8d617 |
| 2021-05-29 04:58:14.000 +0900 | 20210529 | /articles/ddbf4601-48e7-4a1a-a9d6-64727922c7c8 |
+-------------------------------+----------+------------------------------------------------+
実行計画の出し方
なんかこのクエリ遅いぞ、となった場合には、そのクエリが何をやってるのか知りたくなります。Snowflakeの場合、とても綺麗なプロファイラがくっついているので、だいたいこれで用は足ります。
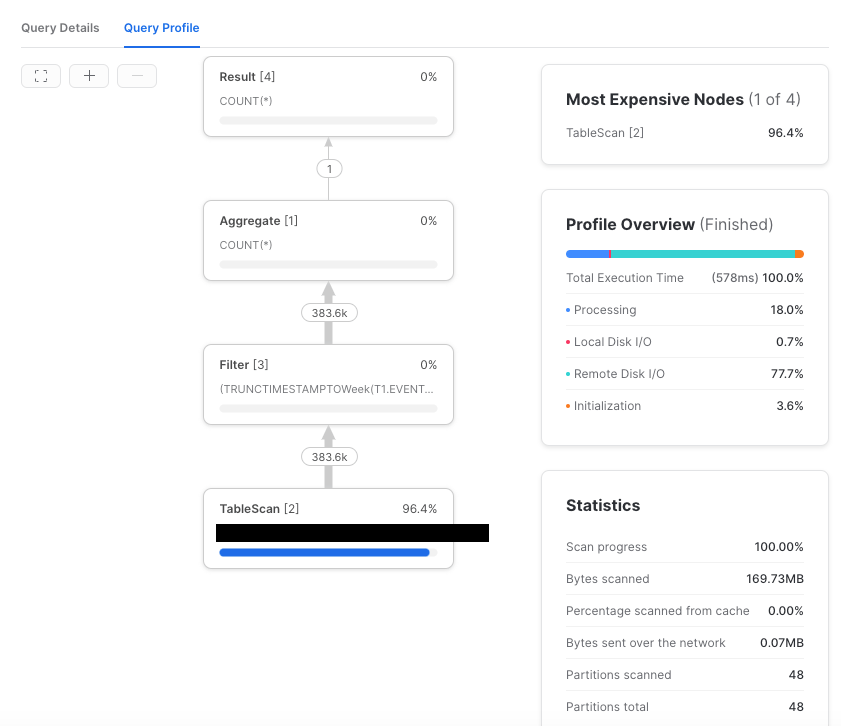
もう一つがEXPLAIN、つまり実行計画です。実行計画は system$explain_plan_json という関数で生成できます。人間が読みやすい表示にするには system$explain_json_to_text と組み合わせます。
select system$explain_json_to_text(system$explain_plan_json(
$$
select count(*) from t1 where dt = '20211225'; -- クリスマスの件数
$$
));
GlobalStats:
bytesAssigned=36811264
partitionsAssigned=3
partitionsTotal=12
Operations:
1:0 ->Result COUNT(*)
1:1 ->Aggregate aggExprs: [COUNT(*)]
1:2 ->Filter T1.DT = '20211225'
1:3 ->TableScan USERS."XXXXXXX@example.com".T1 DT {partitionsTotal=12, partitionsAssigned=3, bytesAssigned=36811264}
なんとなく読めます。TableScanなどはクエリプロファイルに表示される演算子と同様のものだと思います。
実行計画は、SQLを実行する前にSnowflakeがそのクエリをどう認識しているかを知る手がかりになります。プロファイルのように実行はしていないので、例えばキャッシュのスピルが発生しているか等の実行時情報はありません。きれいなグラフィカル表示でもないです。ただ、すぐ出せて大まかな雰囲気が分かるので重宝します。
メタデータに基づくプルーニングがよく効いているかは partitionsAssigned を見ればわかります。この値が partitionsTotal に対して大きすぎる場合は、テーブルを過剰にスキャンしていることになるので、チューニング余地があるかもしれません。
ちなみに、たぶんフルスキャン時だと思うのですが、bytesAssignedは0になることがあるのでGlobalStatsのbytesAssignedの大小はあんまり当てにならない気がします。
クラスタリングキーに「当てる」クエリを書くこと
前述のように、クラスタリングキーは普通のRDBMSのインデックスとは異なるのですが「ちゃんとオプティマイザがクラスタリングキーに基づいてスキャン範囲を狭められるようなクエリを書く」という意味では、書き心地がちょっとだけ類似しています。
-- クラスタリングキーdtでスキャン範囲を狭めるようにクエリを書く
select count(*) from t1 where dt between '20211220' and '20211225';
しかし、インデックスのように、構築したB木を走査しているわけではありません。クラスタリングキーでなくとも、それで十分にプルーニングが効くなら用は足りるということです。
-- これはフルスキャンにはならない(可能性が高い)
select count(*) from t1 where event_time between '2021-12-20T00:00:00+09:00'::timestamp_ltz and '2021-12-25T00:00:00+09:00'::timestamp_ltz;
なぜなら、dtでクラスタリングされているということは、当たり前ですがevent_timeも同一日ごとに値が分布しているはずだからです。したがってプルーニングが(最も効果的かはともかくそれなりの効率で)効くようです。
そのカラムで絞り込んだ時に、読み出すマイクロパーティションをどこまで効率的に減らせそうかは、system$clustering_information関数を使うことでも雰囲気がわかります。
select system$clustering_information('t1', '(event_time)');
{
"cluster_by_keys" : "LINEAR(event_time)",
"notes" : "Clustering key columns contain high cardinality key EVENT_TIME which might result in expensive re-clustering. Consider reducing the cardinality of clustering keys. Please refer to https://docs.snowflake.net/manuals/user-guide/tables-clustering-keys.html for more information.",
"total_partition_count" : 48,
"total_constant_partition_count" : 0,
"average_overlaps" : 29.0,
"average_depth" : 30.0,
"partition_depth_histogram" : {
"00000" : 0,
"00001" : 0,
"00002" : 0,
"00003" : 0,
"00004" : 0,
"00005" : 0,
"00006" : 0,
"00007" : 0,
"00008" : 0,
"00009" : 0,
"00010" : 0,
"00011" : 0,
"00012" : 12,
"00013" : 0,
"00014" : 0,
"00015" : 0,
"00016" : 0,
"00064" : 36
}
}
Clustering key columns contain high cardinality key EVENT_TIMEとあるように、今回の場合はそんなに理想的な状況にはなっていないようですね。
オプティマイザが理解できるようにクエリを書くこと
複雑な条件式を与えてしまっているとき、Snowflakeはうまくプルーニングをしてくれないことがあります。例えばこんな感じです。
-- 12/20週の行数を数えたい!!
select count(*) from t1 where date_trunc(week, event_time) = '2021-12-20T00:00:00+09:00'::timestamp_ltz
GlobalStats:
bytesAssigned=591479808
partitionsAssigned=48
partitionsTotal=48
Operations:
1:0 ->Result COUNT(*)
1:1 ->Aggregate aggExprs: [COUNT(*)]
1:2 ->Filter (TRUNCTIMESTAMPTOWeek(T1.EVENT_TIME)) = '2021-12-19 15:00:00.000000000Ztz=1980'
1:3 ->TableScan USERS."XXXXXXX@example.com".T1 EVENT_TIME {partitionsTotal=48, partitionsAssigned=48, bytesAssigned=591479808}
こういう時には人間がちょっとばかり工夫して、Snowflakeが理解できる形式に書き換えてやる必要があります。なんとなくですが、クラスタリングキーに関数適用や演算がくっついているとうまくプルーニングしてくれない気がします(そういう意味でも普通のRDBMSのインデックスと似ているかもしれません)。
先の例は「日付が対象週の初日から末日の間である」と言い換えてクエリを書き換えます。ちょうど date_truncとlast_dayが上手く使えます。
select count(*) from t1 where event_time between date_trunc('week', '2021-12-20T00:00:00+09:00'::timestamp_ltz) and last_day('2021-12-20T00:00:00+09:00'::timestamp_ltz)
Explainを見てみます。ちゃんとプルーニングされています。
GlobalStats:
bytesAssigned=147393536
partitionsAssigned=12
partitionsTotal=48
Operations:
1:0 ->Result COUNT(*)
1:1 ->Aggregate aggExprs: [COUNT(*)]
1:2 ->Filter (T1.EVENT_TIME >= '2021-12-19 15:00:00.000000000Ztz=1980') AND (T1.EVENT_TIME <= '2021-12-30 15:00:00.000000000Ztz=1980')
1:3 ->TableScan USERS."XXXXXXX@example.com".T1 EVENT_TIME {partitionsTotal=48, partitionsAssigned=12, bytesAssigned=147393536}
暗黙の型変換が入ってもダメだった
暗黙の型変換が問題になることは稀かもしれないのですが、遭遇したので紹介しておきます。
t1テーブルに対して集計するクエリにはdtが使われていることがほとんどですが、中には整数リテラル(!)を使った指定が行われていることがありました。
select count(*) from t1 where dt between 20211220 and 20211225;
こういうクエリもHiveだと暗黙の型変換が行われ、そして特に問題なく動いてしまいます。
Snowflakeはこのクエリを効率的に扱えません。「全行読んでるみたいだけど何が起きてるんだろう!?」という問題が起きました。Explainを見ると納得できます。
GlobalStats:
bytesAssigned=591479808
partitionsAssigned=48
partitionsTotal=48
Operations:
1:0 ->Result COUNT(*)
1:1 ->Aggregate aggExprs: [COUNT(*)]
1:2 ->Filter ((TO_NUMBER(T1.DT, 18, 5)) >= 20211220) AND ((TO_NUMBER(T1.DT, 18, 5)) <= 20211225)
1:3 ->TableScan USERS."XXXXXXX@example.com".T1 DT {partitionsTotal=48, partitionsAssigned=48, bytesAssigned=591479808}
結局、筆者の社内では整数リテラルのクエリを見つけては片っ端から書き換えるバトルが発生しました。
Snowflake社のサポートは好評
記事の本題からは少し外れますが、Snowflake社のサポートはなかなか丁寧で、個別のSQLクエリに関する技術的な疑問にもちゃんと答えてくれるみたいです(筆者は直接やり取りしたことがないので又聞きですが)。
サポートでありがちな「エスカレーションしないと技術がわかる人が出てこない」みたいな問題がないのは良いですね。
まとめ
- クラスタリングキーは、しばしば性能に大きな影響を与えるようです
- 実行計画は、グラフィカルに見る方法のほか、
system$explain_plan_jsonで出力させることもできます
実行計画に関する挙動は、実装依存の面があるはずです。この知見は2021年12月ごろに書かれましたが、将来のSnowflakeのオプティマイザはもっと賢く進化してくれたりするかもしれません。
Discussion