【まとめ】LangGraphチュートリアル
昨日ゴールド免許を取得した齊藤です。
久しぶりにLangGraphのチュートリアル確認してみたのですが、ぱっと見でわかりずらいので、簡易的にまとめてみました。(2024年11月23日)
無理矢理、翻訳した箇所もあるのでご愛嬌でお願いします。
こちら公式Tutorialになります
ここからクイックスタート
LangGraph Quickstart
Part1 : ベーシックなチャットボット

Part2 : ツール付きチャットボット

Part3 : メモリー付きチャットボット
Part2と同じ。ただし会話の内容を継承。
Part4 : Human-in-loop
人間の入力の助けを借りるケースに使用。実行前後どちらかに人間の承認を必要とする場合に使用される。
Part5 : Manually Updating State
手動でエージェントのStateの更新をし、エージェントのアクションを変更。
Parg4との違いはグラフを中断し人間がそのアクションを検査する方法、これはアップデートする方法?
Part6 : Customizing State
chatbotが定義されたアクション(part2やpart4で定義されたアクション)にアクセスし、実行することができる。

Part7 : Time Travel
ユーザーがチャットボットとのやり取りの中で誤りに気づき、それを修正したり、別の戦略を試したい場合。
LangGraph Server Quickstart
LangGraphアプリをローカルで立ち上げ、実行するためのクイックスタートガイド
GUIアプリケーション化できるって話?
LangGraph Cloud Quick Start
エージェントのデプロイ方法の紹介。
例)LangGraph Quickstartで紹介したチャットボットのデプロイ
ここからUse Cases
チャットボット
カスタマーサポート

プロンプト生成支援ボット
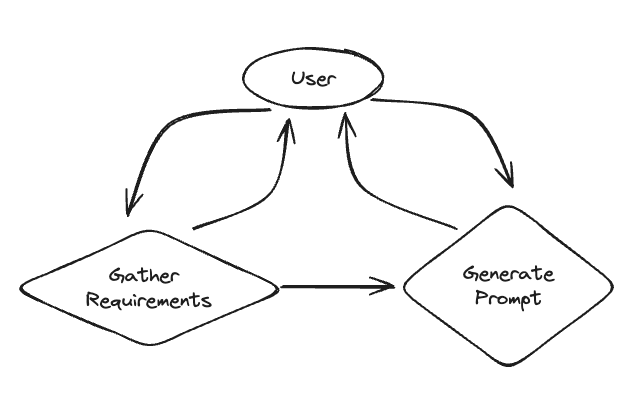
コード生成 , Ragとself-correction使用

RAG
Agentic RAG
Ragを使用したエージェント

Adaptive RAG
(1)クエリ分析と(2)能動的/自己修正的RAGを組み合わせたRAG戦略。

Corrective RAG(CRAG)
検索された文書に対する自己反省/自己評定を組み込んだRAGの戦略である。

Self RAG
検索された文書や世代に対する自己反省/自己採点を組み込んだRAGの戦略である。

SQL database とやりとりするエージェント
SQL データベースに関する質問に答えるエージェントを構築する方法を説明します。
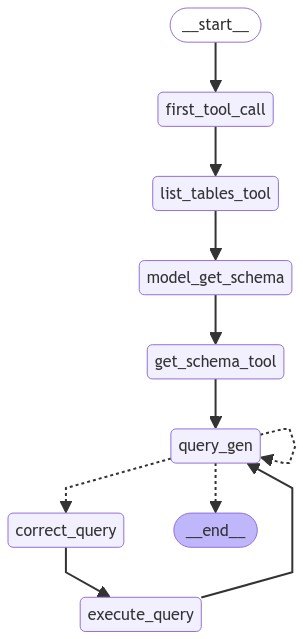
Agent Architectures
Multi-Agent Systems
Network
各タスクに特化したエージェントを作成し、タスクをルーティングする方法

Multi-agent supervisor
異なるエージェントをオーケストレーション(複数の IT 自動化タスクまたはプロセスを調整して実行)する。

Hierarchical Agent Teams
階層的に分散させよう!

Reflection & Critique
Basic Reflection
Reflectionってやつがありますねん。
以下説明
LLMエージェント構築の文脈では、リフレクションとは、選択した行動の質を評価するために、LLMに(ツールや環境からの潜在的な観察とともに)過去のステップを観察するよう促すプロセスを指す。これは、再計画、探索、評価などの下流で使用されます。

Reflexion
ShinnらによるReflexionは、言語によるフィードバックと自己反省を通して学習するように設計されたアーキテクチャである。エージェントは、より質の高い最終的な応答を生成するために、タスクに対する応答を明示的に批評する。

Tree of Thoughts
反省と評価と単純な探索を組み合わせた一般的なLLMエージェント探索アルゴリズム。

Language Agent Tree Search
ZhouらによるLanguage Agent Tree Search (LATS)は、ReACT、Reflexion、Tree of Thoughtsのような類似の手法と比較して、より良いタスクパフォーマンスを達成するために、リフレクション/評価と探索(特にモンテカルロ木探索)を組み合わせた一般的なLLMエージェント探索アルゴリズムである。

Self-Discover Agent
特に説明なし、わかる方いたら教えて下さい!!
Evaluation
Agent-based
コードを変更するたびに手動チェックは大変なので、「ユーザーとの対話をシュミレートする」。

In LangSmith
上記Agent-basedをLangSmithを使用して、実行
Experimental
Web Research (STORM)
ユーザが提供したトピックについて、ウィキペディアスタイルの記事を生成するように設計されている。より整理された包括的な記事を生成するために、2つの主要な洞察を適用する
- 類似のトピックを照会してアウトライン(計画)を作成することで、網羅性を向上させる。
- 多視点的で(検索に)基づいた会話シミュレーションは、参照数と情報密度を高めるのに役立つ。
https://langchain-ai.github.io/langgraph/tutorials/storm/storm/

TNT-LLM
TNT-LLMは、生の会話ログからユーザーの意図(または他のカテゴリ)の豊富で解釈可能な分類法を生成する。この分類法は、LLMがログにラベルを付けるために下流で使用することができ、その結果、アプリにデプロイ可能な安価な分類器(エンベッディング上のロジスティック回帰分類器など)を適応させるためのトレーニングデータとして使用することができます。

Web Navigation
use computerみたいなパソコン操作の自動化

Competitive Programming
このチュートリアルでは、パフォーマンスを向上させるために、3つの補完的な技術、すなわち、リフレクション、検索、および人間によるループ内コラボレーションを活用したコンピューティング・オリンピアード・エージェントを構築します
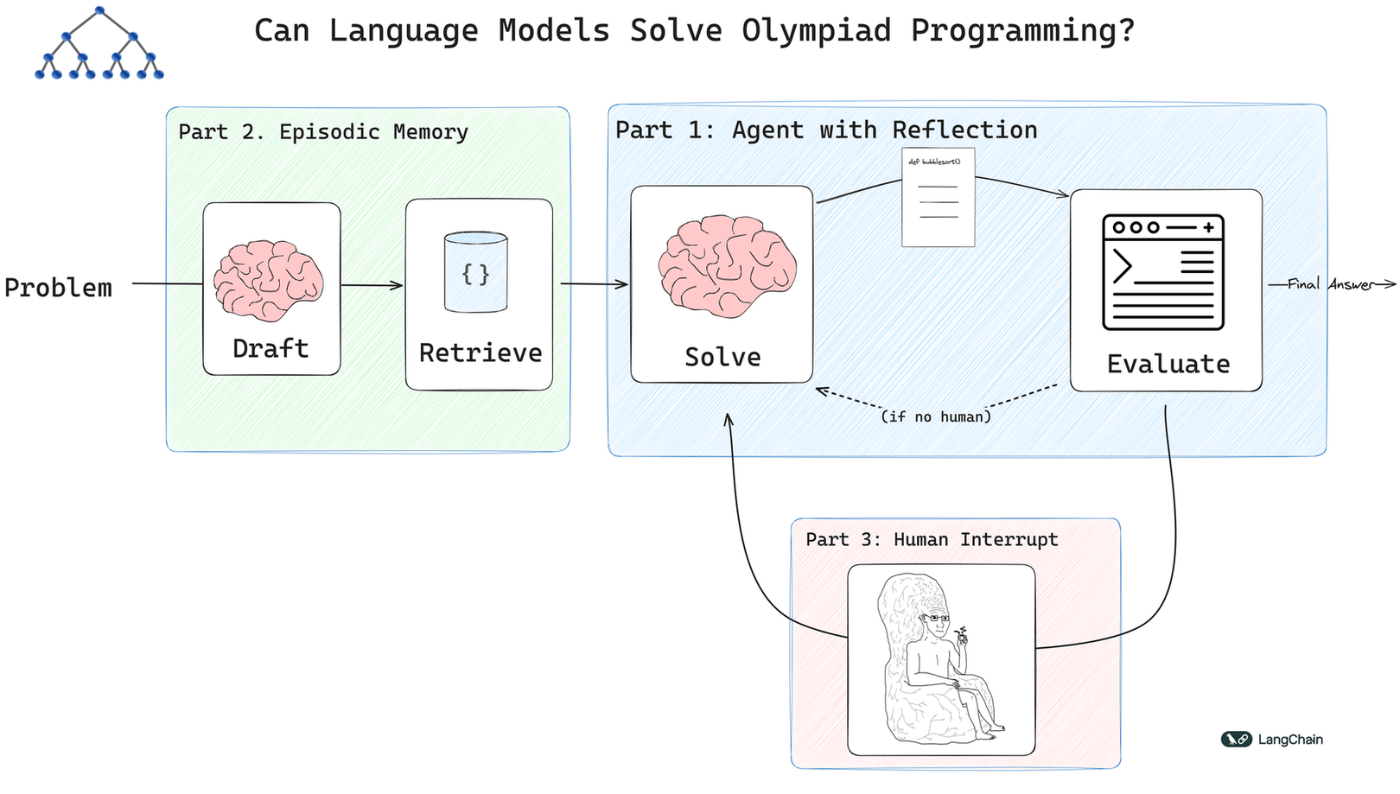
Complex data extraction
関数呼び出しはLLMをソフトウェアスタックに統合するための核となるプリミティブです。私たちはLangGraphのドキュメントのいたるところで関数呼び出しを使っています。なぜなら、関数呼び出し(別名ツールの使用法)を使った開発は、カスタム文字列パーサーを書く伝統的な方法よりもずっとストレスがない傾向があるからです。
しかし、GPT-4やOpusなどの強力なモデルでも、複雑な関数、特にスキーマに入れ子があったり、より高度なデータ検証ルールがあったりすると、やはり苦労します。
信頼性を高める基本的な方法は3つあります:より良いプロンプト、制約のあるデコード、そして再プロンプトによる検証です。
最後の手法については、ツール呼び出しをサポートするLLMであれば一般的に適用できるため、ここでは2つのアプローチを取り上げます。
Discussion