【Dify】チャンク?何それ美味しいの?
Difyを触っていた時にナレッジを食わそうと思い、データをぶち込んだところ「チャンク設定」という単語を見つけたので、気になって調べてみました。

日本語記事も見つけたのですが、実装メインの記事が多かったので 「チャンクとは?」を理解することを目標に調べてみました。
以下参考記事です
登場する用語説明。
- sequence(シーケンス):一連のトークン(文字、単語、またはサブワード単位)のこと。入力と出力シーケンスがある。
- fine-tuning(ファインチューニング)::事前に学習されたLLMを、特定のタスクやドメインに適応させるために、より小規模でタスク特化型のデータセットを用いてさらに訓練するプロセス。
チャンクとは
チャンクとは大容量のドキュメントを小さなドキュメントに分けて、より管理しやすくするための施策です。
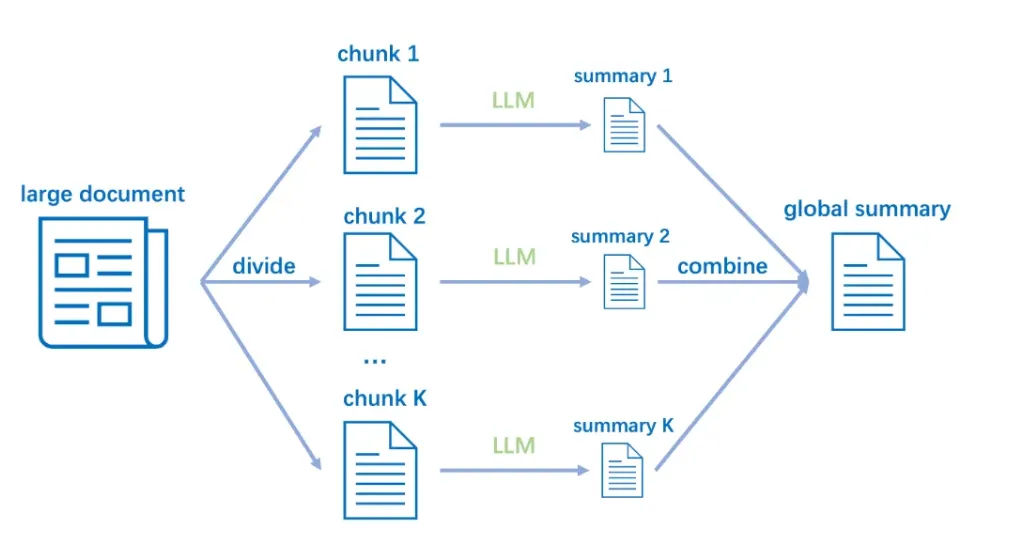
チャンクの基本的な発想は大量のデータをより小さく、管理しやすいように分割しLLMに取り込むアプローチ方法になります。感覚的に「ハリーポッターシリーズを全作品ぶっ通して見続けた後に書く感想文よりも、1作品ごとに見てから書く感想文の方が全体としてはいい出来だよね」みたいな話に近いです。
LLMの文脈ではチャンクは入力データとモデルの出力の両方に適用でき、より効率的な処理とメモリ管理が可能になります。
インプットチャンクとアウトプットチャンクが存在する。
インプットチャンク
インプットチャンクとはLLMに食わせる前の大容量のドキュメントから作成した小さなドキュメントのことを指しています。LLMによって処理された後でその結果を組み合わせたり、後処理したりして最終的な出力を得ることができるようになっていますが、最適なチャンクの分割方法は基本的にはありません。それはチャンクを細かく分けすぎた場合文章の前後の意味を理解することができずに、出力の精度向上が見込めないからです。ただし私たちが利用している文章には独自の構造が存在しているので、その構造をチャンク分割方法に落とし込むことで精度の向上が見込めます。
例えば、下記の論文を読み込ませる必要があった場合。

データの構造を理解せずに五行ずつのチャンクに区切ることをしてしまうと、文章の意味は理解することが難しくなってしまいます。
一方で、下記のように段落ごとで区切ることで文章自体の意味も理解しやすくなり、出力精度も高くなりやすい傾向があります。

アウトプットチャンク
メモリの制限(モデルごとのトークン制限)や後続の処理を容易にするために、モデルからの出力を小さなチャンクに分けるプロセスのことを指します。この処理は長いシーケンス文章の生成時に、非常に有効な手段として用いられます。
アウトプットチャンクを使用しなければ、一度の処理で行おうとしてしまうと、メモリの制限や文章生成の失敗につながることが起きてしまいます。
Difyにおけるチャンク設定について
Difyのチャンク設定は自動設定とカスタム設定の2パターンに分かれています。
自動設定は文字通り自動でチャンクの分割を行ってくれ、カスタムは手動でカスタムすることになります。
まずナレッジ機能を使ってみたいという方は自動設定からチャンク分割を行ってみましょう。
データは先ほどの論文をナレッジとして突っ込んでみました。
設定
データを入れてみると以下のようなプレビューが画面上に表示されます。これは各チャンクの文章の始まりと、チャンクの中に含まれる文字数を表しています(最初が524文字、その次が350文字…)。文字の分割がはじまっている箇所を見ると、段落ごとに綺麗に分かれていないことがわかります。またナレッジとして必要のない単語も含まれているのですが、これはデータの前処理が必要になってくるので割愛します。

作成後以下のようにチャンクが分割されていることを確認することができました。引用部分やタイトル部分は不必要になるユースケースがほとんどだと思うので、あとはこれらのチャンクを無効して、ワークフローにナレッジを入れるだけで、チャンク設定は完了になります。

まとめ
チャンクの概要を知ることができました。チャンクのカスタム設定や、インポートするデータの前処理部分は省いてしまいましたが、また機会があればまとめてみます。
また、参考記事ではチャンクの活用事例としてファインチューニングを取り上げていましたが、精度上げるならRAG検索の方が精度いいんじゃね?みたいなお話なんかもあったりします。もし気になった方はこちらの記事もみてみてください。→https://zenn.dev/neoai/articles/e75b6f033a4fd9
何かご質問や間違いありましたら、ご連絡お待ちしておりますー。
Discussion