グラフモデルとSoEとGraphQL / TECH STAND #7 GraphQL
2022/03/03 に行われた stand.fmさん主催の TECH STAND #7 にて上記のタイトルで登壇しました。
今回の内容は
- GraphQLの採用を検討するにあたって、RESTとの違い、BFFとの違いをデータの観点から言語化したかった
- Hasuraが良いという意見と, Apolloやgraphql-ruby, gqlgenなどのハンドライティングなGraphQLが良いという意見の違いがどこから生まれているかの考察がしたかった
- データ指向アプリケーションデザイン(2017年リリース)にSoEやGraphQLへの言及がないため, 今だとこういう内容が書かれているんじゃないかという考察がしたかった
をモチベーションに調査・検討しました。
発表のハイライトはこちらです。
以下発表内容です。一部発表時から修正してます。
GraphQL and Me
これまでにGraphQLについて書いた記事です。
- Software Design 2021年8月号 第2特集 GraphQLでかなえる効率的なデータ通信
- GraphQLが解決する問題とその先のユースケース - Zenn
- GraphQLの特徴を分解する ~API インターフェース・Universal BFF・API Gateway~ - Qiita
- GraphQLはサーバーサイド実装のベストプラクティスとなるか - Qiita
- GraphQLの全体像とWebApp開発のこれから - Qiita
今回話すこと
データ指向アプリケーションデザインの視点からデータモデルやシステム要件とWebAPIとGraphQLを結びつけ、 他のケースと比較しGraphQLの特徴を整理します。
特に、エンティティ間の関係の複雑さとデータモデリング間の抽象度に着目します。
データ指向アプリケーションデザイン

データの量や複雑さ、変化の速度が主な課題であるアプリケーションの事をデータ指向と呼びます。今日の多くのアプリケーションは、演算指向ではなくデータ指向であり、こちらの方が大きな問題なのです。
今回話す事に関連する章
- 2章 データモデルとクエリ言語
- 2.1.5 今日のリレーショナルデータベースとドキュメントデータベース
- 2.3 グラフ型のデータモデル
- 4章 エンコーディングと進化
- 4.3.2 サービス経由でのデータフロー: RESTとPRC
原著が出たのが2017年。主にSystem of RecordとSystem of Insightの話。2022年現在なら必ずSystem of EngagementやGraphQLが書かれていたはず
GraphQLとは
GraphQLは、APIのクエリ言語であり、既存のデータでこれらのクエリを実行するためのランタイムです。" [1]
"モダンなWebアプリの宣言的データフェッチ" [2]
- WebAPI上で動く事を想定されている
- HTTP-based
- 即時性
- グラフモデルを採用している ← 今回の本題
データモデルのエンティティと関係
データモデルとは
データモデルは、おそらくソフトウェアを開発するにあたって最も重要な部分でしょう。これは、データモデルがソフト ウェアの書き方だけではなく、私達が解決しようとする問題に対する考え方に対して、きわめて重要な影響力を持っている
ためです。アプリケーション開発者は、現実の世界(そこには人々、組織、物、行動、金銭の流れ、センサーなど)を見て、 それをオブジェクトやデータ構造と、それらのデータ構造を操作するAPIによってモデル化します。こういった構造は、しばしばアプリケーション固有のものになります。多くのアプリケーションは、いくつものデータモデルのレイヤーを重ねて いくことよって構築されています。(中略)それぞれのレイヤーはクリーンなデータモデルを提供することで下位のレイヤーの複雑さを隠蔽してくれています。こうした抽象化によって、(中略)様々なグループの人々が効率的に作業できるのです。データモデルはソフトウェアにできること、そしてできないことに関してきわめて大きな影響を及ぼすので、アプリケーションに適したデータモデルを選択するのは重要です。
出典: データ指向アプリケーションデザイン 2章 データモデルとクエリ言語
データモデルの歴史
- 今日、データベースで最も使われるデータモデルはリレーショナルモデル。正規的な構造化で データを保存し、クエリを実行出来る、リレーショナル・データベース管理システム(RDBMS)とSQL
- 1970年代や1980年代にはネットワークモデルや階層モデルが提案されていた
- 2010年代にNoSQLの潮流の中で注目されているのがドキュメントモデルとグラフモデル
データモデル毎のエンティティと関係

内容
データモデル毎のエンティティと関係
- リレーショナル
- RDBMS, SQL
- データの整合性・一貫性を維持する必要があるビジネスデータ
- 関係はSQLクエリで表現する
- エンティティ: スキーマオンライト
- 関係: スキーマオンリード
- ドキュメント
- MongoDB, Firestore, KVS, オブジェクト指向プログラミング, JSON
- 自己完結しているドキュメント郡で、ドキュメント間の関係がそれほど存在しない。多対多が苦手。
- エンティティ: スキーマオンリード
- 関係: スキーマオンリード
- グラフ
- Neo4j, Cypher, SPARQL
- 潜在的にはあらゆるデータ同士に関連が存在する、関係がとても複雑なケースに有効
- エンティティ: スキーマオンライト
- 関係: スキーマオンライト

内容
リレーショナルモデルとグラフモデルのエンティティの関係についての比較
リレーショナルモデル
- エンティティ間の関係はクライアントがSQLで取得する際にJOINすることで表現する(関係: スキーマオンリード)
- SQLクライアントがエンティティ間の関係の複雑さを負担をする
- エンティティ間の関係の複雑さが増えるとクライアントの負担が増大する
グラフモデル
- エンティティ間の関係はスキーマを宣言する際やデータを挿入する際に決定される(関係: スキーマオンライト)
- クライアントはエンティティとその関係を予め宣言された通りにクエリし、データ取得が出来る
- エンティティ間の関係の複雑さが増えてもクライアントの負担は増えない
前述した、リレーショナルモデル、ドキュメントモデル、グラフモデルの比較を行う。
リレーショナルモデルはRDBMSで採用されているため馴染み深いはず。データの整合性や一貫性を重要視し、テーブルを疎結合に保存・管理する。予めテーブル構造を決めてスキーマを作成し、その後にデータの格納と取り出しを行う。エンティティ間の関係はSQLのクエリでクライアントが任意に作成する。(関係のスキーマオンリード)データベース側での関係のサポートはほとんどないと言っていい(外部キー制約があるが単に削除時の制約に過ぎない)。そのため関係が複雑になった場合にクライアントの実装負荷が増加する。ここでいう実装負荷は、記述量が増える事による実装負荷と関係性を理解するための認知負荷がある。
他方、グラフモデルはリレーショナルモデルが扱いきれないようなエンティティの関係の複雑さがとても大きいデータに対して設計されたモデルである。スキーマにエンティティと同様に関係も記述する(関係のスキーマオンライト)。クライアントはクエリによってデータを取得するが、その際に予め設定された関係を利用して複数のエンティティにまたがったデータを一度に取得することが出来る。関係の複雑さが増大した場合でも、無理なく複雑なデータを取得出来る。
システム要件とデータモデル
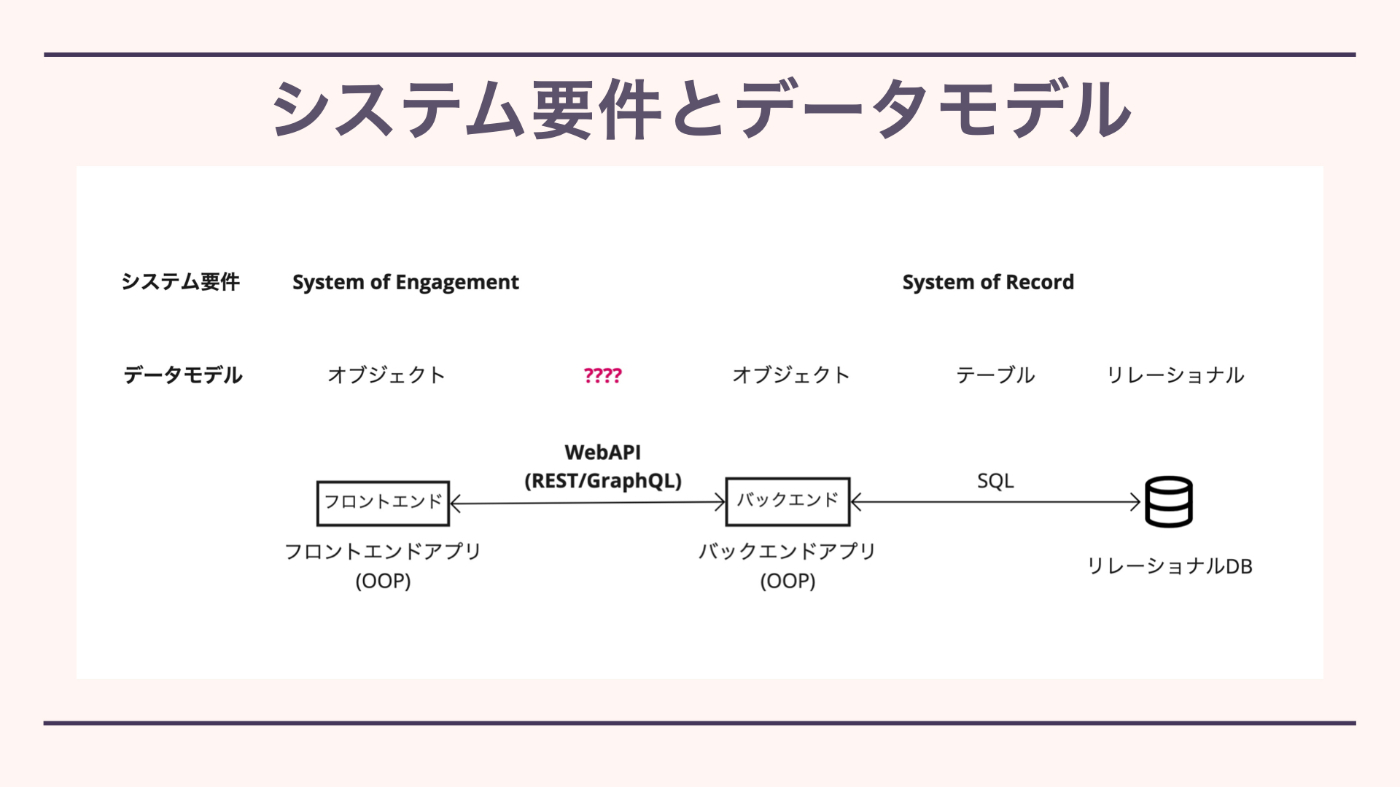
- フロントエンド、バックエンド、リレーショナル・データベースの一般的な構成
- リレーショナルDB間とバックエンドアプリはSQLでやり取りする
- バックエンドアプリとフロントエンドアプリはWebAPIでやり取りする
System of Record と System of Engagement

出典: System of Record と System of Engagement Naoya Ito - Speaker Deck
- 書かれたのは2016年
- 当時でもなるほどなぁと思った
- System of Recordはバックエンド, System of Engagementはフロントエンド, ネイティブアプリとざっくり思ってもらえばok
データフロー

内容
バックエンドアプリとリレーショナルDBのデータフロー
- ほとんどのSoR(バックエンド)アプリケーションはリレーショナルDBを採用する。
- 書込みの整合性や一貫性が保たれ、SQLクエリで柔軟にデータ加工が出来る
- テーブルが疎結合に保存される、関係は読込時にクライアントが負担する
- SoRとRDBとのテーブル間の関係の複雑さを解消する方法としてORMが発明された。ORMを利用したプログラムではORMのモデルに関係を表現する。(ORMによる抽象化)

内容
フロントエンドとバックエンド間のデータフロー
- 最近のサービスはフロントエンドとバックエンドを分離することでSoEとSoRの責務をきっちり分けられるようになった。(もちろん今でも分離されていないアプリケーションは多いが今日はWebAPIの話なのでそういうことにしておきます🙏)
- バックエンドは今でもリレーショナルDBとオブジェクト指向プログラミングが主戦場
- フロントエンドとバックエンド間のデータフローはWebAPIを利用する。
- 今日、主に利用されるWebAPIの形式はREST APIとGraphQL APIがある
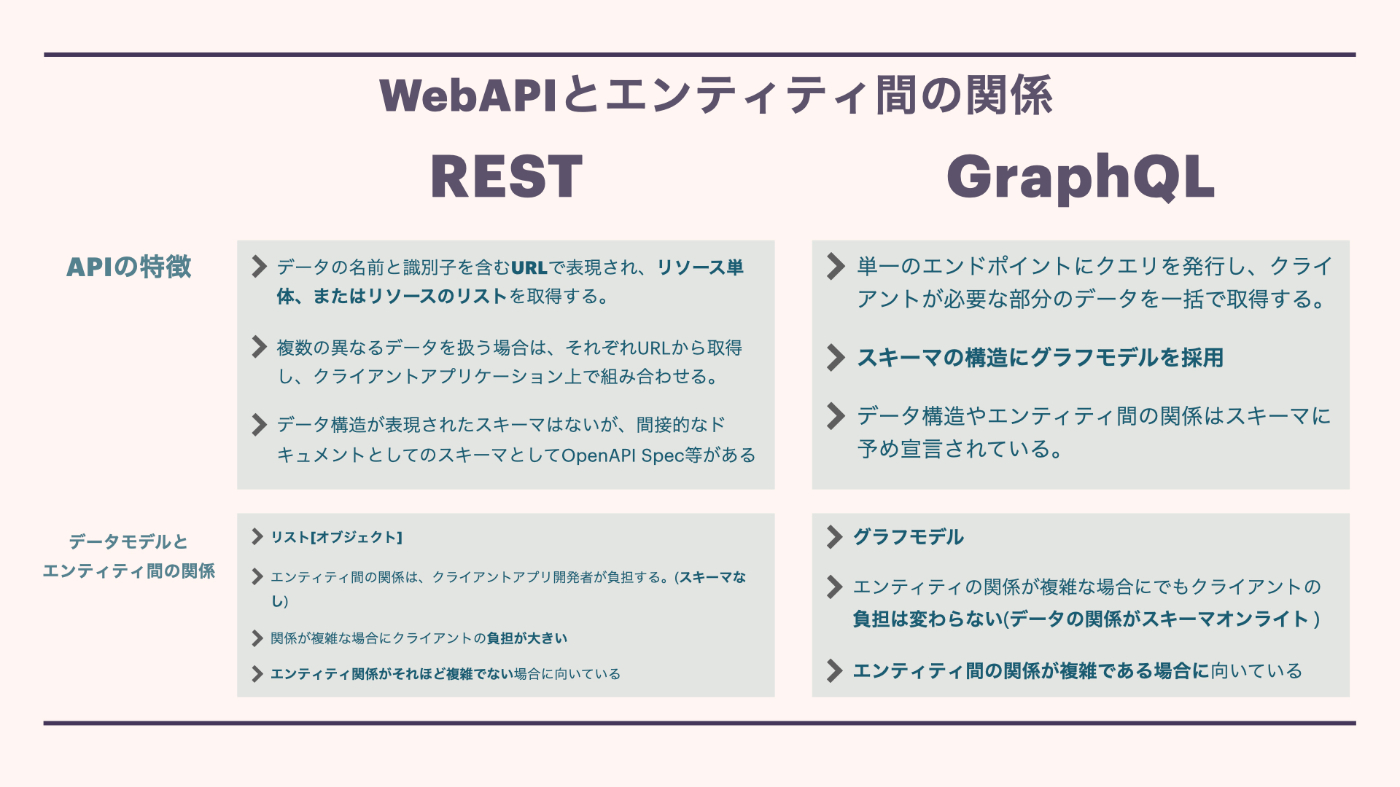
WebAPIとエンティティ間の関係
内容
WebAPIとエンティティ間の関係
REST
APIの特徴
- データの名前と識別子を含むURLで表現され、リソース単体、またはリソースのリストを取得する。
- 複数の異なるデータを扱う場合は、それぞれURLから取得し、クライアントアプリケーション上で組み合わせる。
- データ構造が表現されたスキーマはないが、間接的なドキュメントとしてのスキーマとしてOpenAPI Spec等がある
データモデルとエンティティ間の関係
- リスト[オブジェクト]
- エンティティ間の関係は、クライアントアプリ開発者が負担する。(スキーマなし)
- 関係が複雑な場合にクライアントの負担が大きい
- エンティティ関係がそれほど複雑でない場合に向いている
GraphQL
APIの特徴
- 単一のエンドポイントにクエリを発行し、クライアントが必要な部分のデータを一括で取得する。
- スキーマの構造にグラフモデルを採用
- データ構造やエンティティ間の関係はスキーマに予め宣言されている。
データモデルとエンティティ間の関係
- グラフモデル
- エンティティの関係が複雑な場合にでもクライアントの負担は変わらない(データの関係がスキーマオンライト )
- エンティティ間の関係が複雑である場合に向いている
データモデリングのインピーダンスミスマッチと抽象化
インピーダンスミスマッチ
- ある2者間でモデリングしたデータの構造が異なる場合、変換に発生する差異をインピーダンスミスマッチという
- 例: バックエンドアプリ(オブジェクト) ⇔ リレーショナルDB(テーブル)
- 例: フロントエンドでのデータモデリング ⇔ WebAPIのデータモデリング
- 特にフロントエンドでは、REST APIから取得出来るデータとの差異が発生することがある。
- SoEの要件の変化の速さについていけない
- UIに正解がない ≒ APIのモデリングに正解がない
- またフロントエンドではバックエンドの複数のAPIを結合して1つのデータとして扱う場合もある。
- それら差異はフロントエンド側(クライアント)が負担することになる
抽象化レイヤとしてのBFFおよびGraphQL
- フロントエンドとバックエンドのデータモデリングのインピーダンスミスマッチを解決する目
的での負担を減らすためにBFF(Backend for Frontends)の概念が生まれた - フロントエンドのデータモデリングに沿ったデータ集約・変換するAPI
- これによってフロントエンドの負担(変換処理)を減らす事ができた
- 複雑さを隠蔽するための抽象化層
- GraphQLはBFF的特徴を内包している
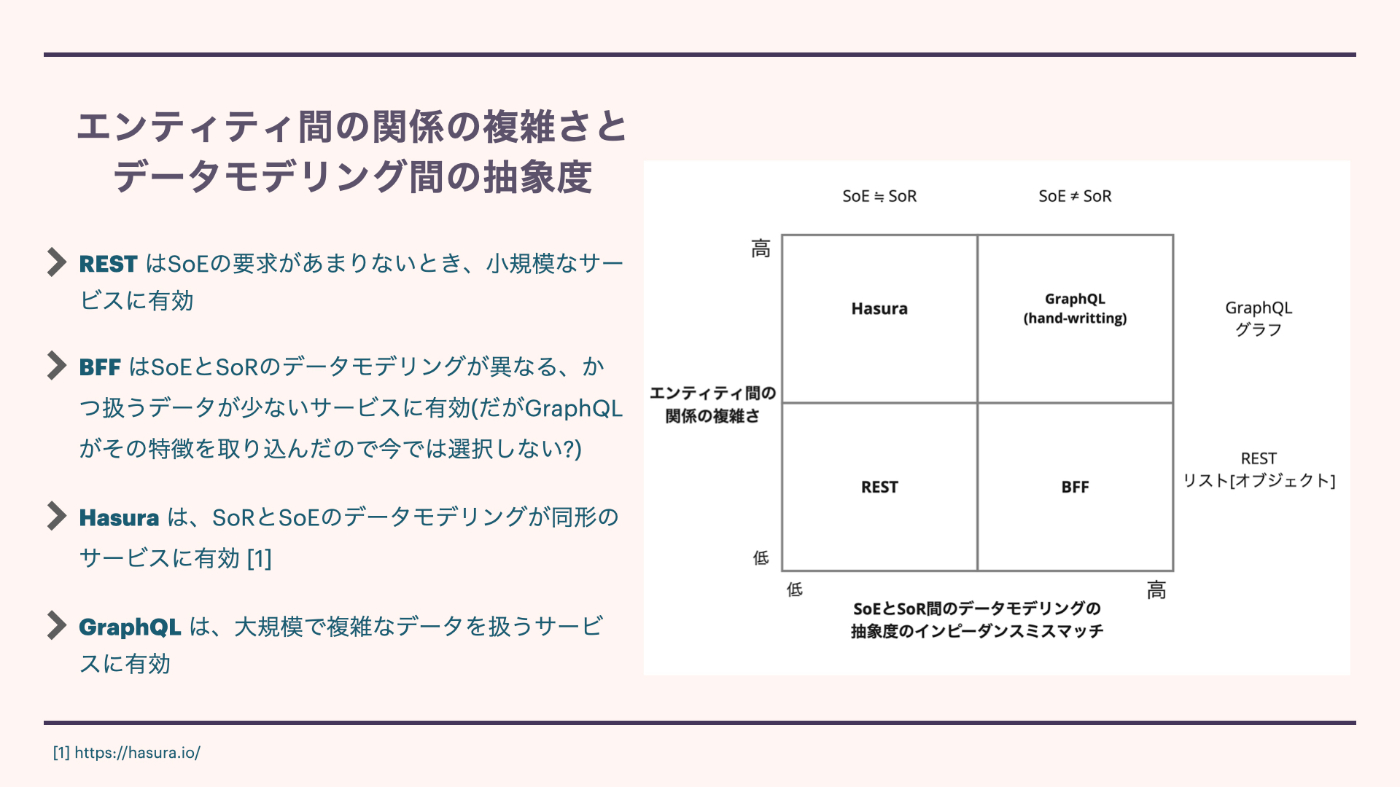
エンティティの関係の複雑さとデータモデリング間の抽象度
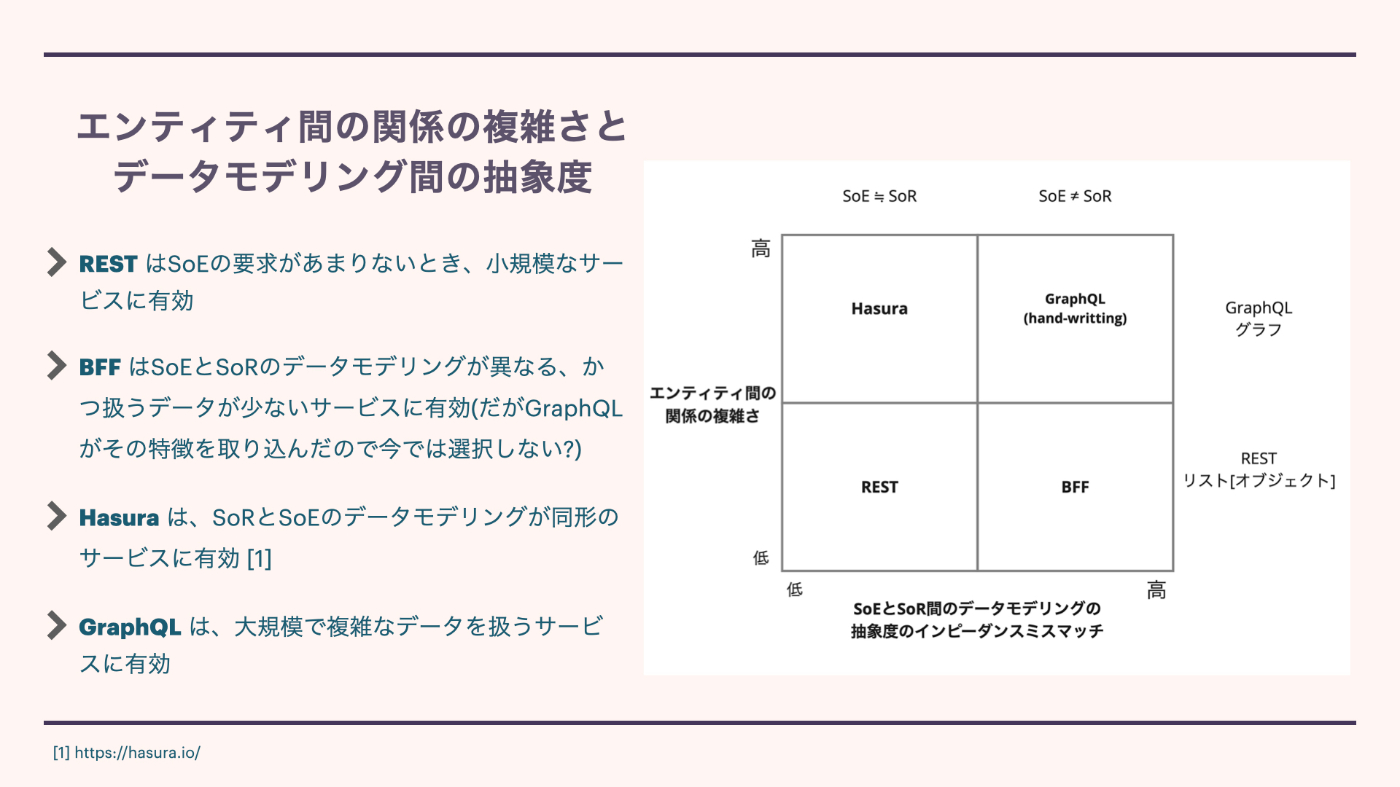
内容
- REST はSoEの要求があまりないとき、小規模なサービスに有効
- BFF はSoEとSoRのデータモデリングが異なる、かつ扱うデータが少ないサービスに有効(だがGraphQLがその特徴を取り込んだので今では選択しない?)
- Hasura は、SoRとSoEのデータモデリングが同形のサービスに有効 [1]
- GraphQL は、大規模で複雑なデータを扱うサービスに有効
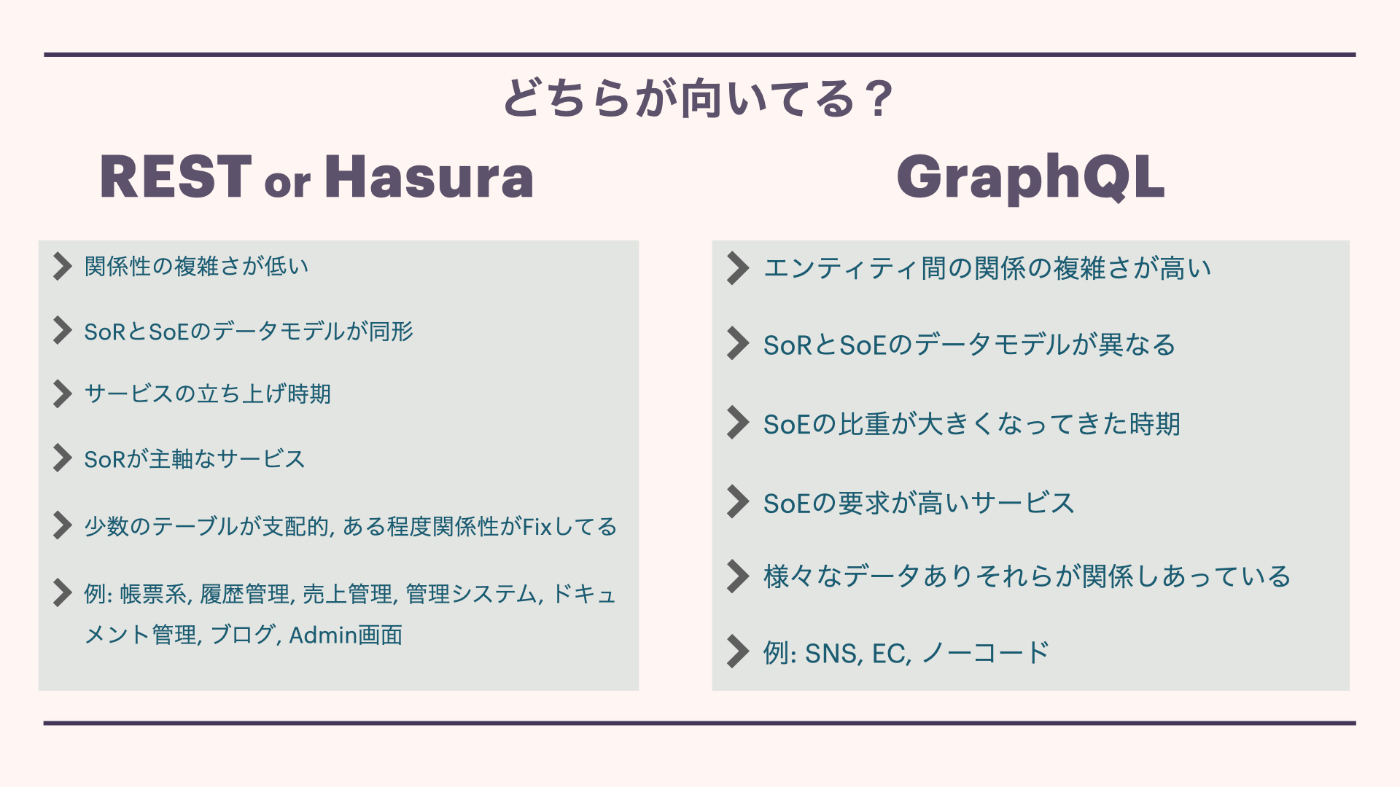
内容
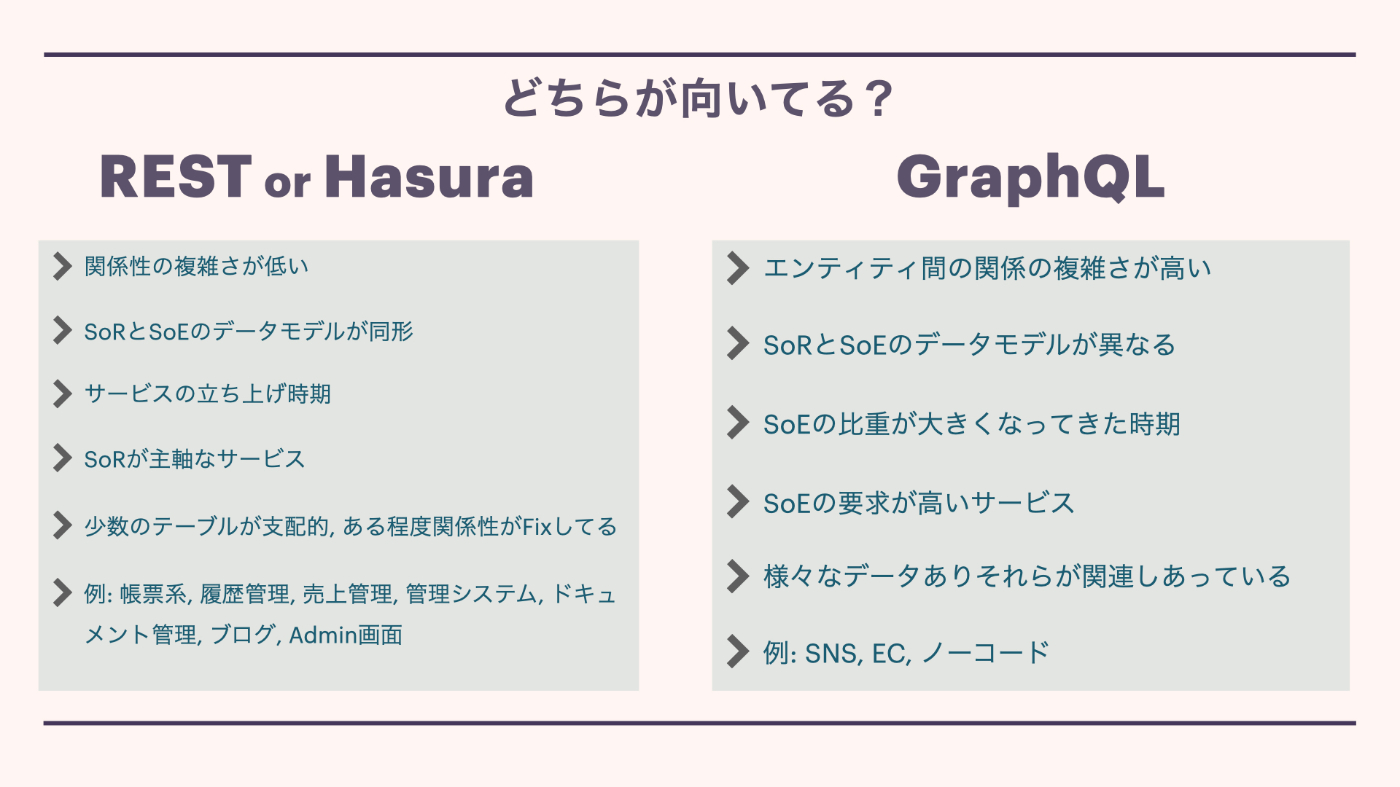
どちらが向いてる?
REST or Hasura
- 関係性の複雑さが低い
- SoRとSoEのデータモデルが同形
- サービスの立ち上げ時期
- SoRが主軸なサービス
- 少数のテーブルが支配的, ある程度関係性がFixしてる
- 例: 帳票系, 履歴管理, 売上管理, 管理システム, ドキュメント管理, ブログ, Admin画面
GraphQL
- エンティティ間の関係の複雑さが高い
- SoRとSoEのデータモデルが異なる
- SoEの比重が大きくなってきた時期
- SoEの要求が高いサービス
- 様々なデータありそれらが関係しあっている
- 例: SNS, EC, ノーコード
APIの進化性
話は変わって進化性の話。進化性の軸でRESTとGraphQLを比較すると双方の良さが見えてくる。
進化性
- 進化性には前方互換性と後方互換性がある。
- 前方互換性、未来において変化していけること。変化しやすいこと。
- 後方互換性, 古いコードでも利用出来ること。変化しないこと。
出典: データ指向アプリケーションデザイン 4章 エンコーディングと進化
RESTとGraphQLと進化性
REST
- 利用され始めるとURLやデータの内容を変更しない。そのため、後方互換性に強いといえる。
- API毎に独立したデータであるため、ロジックの実行範囲とデータの利用範囲が限定的。計算量やI/Oのコストが見積もりやすい。
- API毎の利用制限がかけやすい
- 仕様の変更を極力行わないパートナーAPI,パブリックAPIに向いている
GraphQL
- スキーマは変化し続ける事を想定されている。そのため前方互換性に強いといえる。
- クエリによって計算量やI/Oのコストが変動する
- クライアントが発行するクエリを制限しづらい。
- 仕様変更を頻繁に行う、1st Party APIに向いている
GraphQLをいつ入れるべきか

出典: System of Record と System of Engagement Naoya Ito - Speaker Deck
なおやさんの状況に共感。個人的な意見としては、
サービスによっては立ち上げ期はSoR(バックエンド)のロジック実装に注力して、SoE要件的なUI/UXはある程度犠牲にしつつドメインロジックの構築を高速に行う、この際はRuby on Rails等のMVCなモノリスで作る(開発チームの手が最速なツールで作る)。ある程度ビジネスロジックが完成し、プロダクトマーケットフィットした段階でビジネスの比重がSoE要件に移るタイミングでGraphQLとNext.js等を採用してがっつりフロントエンドを作る。
一方サービスによっては最初からSoE要件が高いサービスもある。例えばSNS, EC, ノーコードツールといった、ユーザーの使いやすさや体験の良さがビジネスのドライバーであるサービス。その場合は開発当初からGraphQLとNext.js等を採用してフロントエンドとバックエンドの実装を並行して行う。
まとめ
改めて、GraphQLとは
データ指向アプリケーションデザインの観点から見ると、
グラフモデルを採用した、データの関係が複雑、またはデータモデリング間の抽象度がSoEとSoRとは異なる、要求の高いSoEを実現するためWebAPI
- REST 対 GraphQL, BFF 対 GraphQL, Hasura 対 Hand-writtingの GraphQL(Apollo等)の違いをデータの関係の複雑さと抽象度の違いを
分類した - 将来においてもRESTでよいアプリケーション、またGraphQLに向いているアプリケーションを分類した
- GraphQLと比較することで、RESTの良さを再発見することができた
おわりに
今回のイベントで、打ち合わせしたわけでもなくそれぞれの発表者がGraphQLを様々な角度から語っていて、多面的に理解できてとてもよかったです。イベントを主催していただいたstand.fmの方々、登壇者の方々、参加していただいた方々、良いイベントをありがとうございました 🙌 🙌
Youtubeにアーカイブがあるみたいなのでよかったらどうぞ
イベントをみた感想です

Discussion