AWSにおける信頼性を考慮した構成の実践(社内システム)




初めに
生産技術部で製品の検査工程を担当しているエンジニアです。工場のデータを見える化するため、AWS上にシステムを構築しています。設計の原則にベストプラクティスとして記載されている内容を実践し、実装に詰まったところを整理します。
信頼性を考慮した構成とポイント
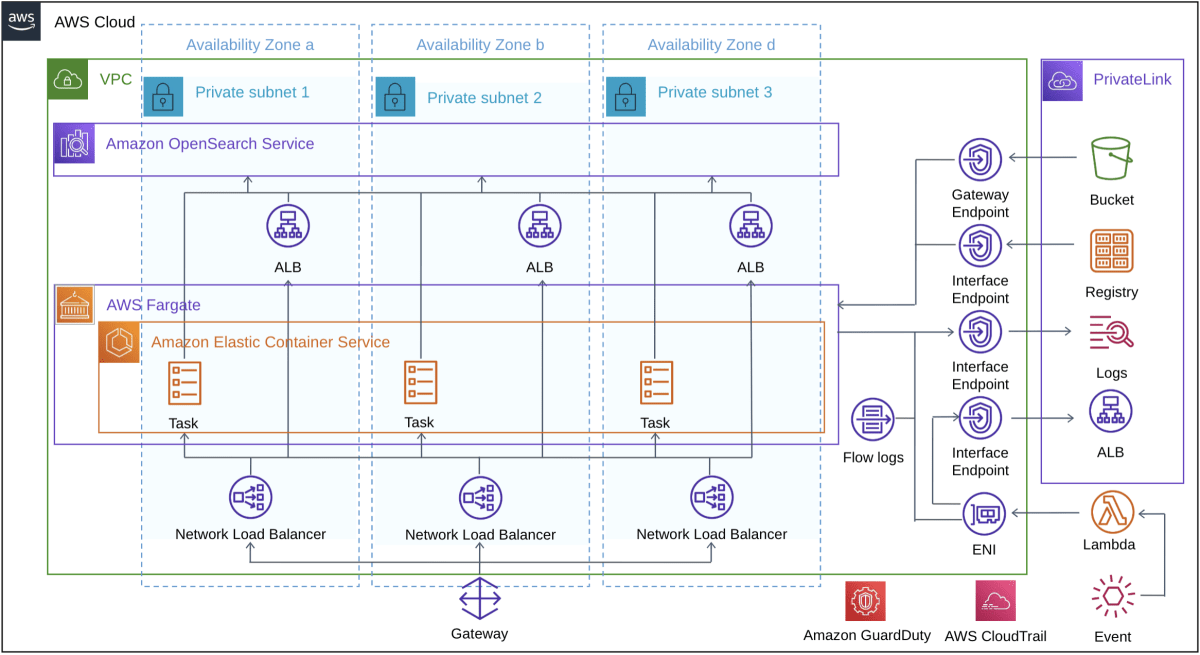
DirectConnectを利用し、オンプレミス環境とAWS間を接続しています。社内限定のシステムのため、Internet Gatewayは利用せずPrivate Subnetに閉じています。インターネットへの接続が必要なサービスは全てPrivateLinkで接続しています。
設計の原則に基づき、以下の3点を実践しました。これらを実践する上で検討したことを紹介します。
- 水平方向にスケールしてワークロード全体の可用性を高める
- キャパシティの推測をやめる
- 障害から自動的に復旧する
具体的な実装は、以下のソースコードを参照してください。
※ただし、実際のものとは異なり、DirectConnectで接続する設定にはなっていません。
水平方向にスケールしてワークロード全体の可用性を高める
オンプレミス環境とAWS間の可用性について
本件は社内に限定したサービスであり、オンプレミス環境とAWSの間はDirect Connectにより接続し、オンプレミスを拡張したネットワークとして利用しています。Direct Connectについても冗長化することで可用性を高めています。
vpc内のリソースの可用性について
vpc内の各リソースは3つのAZに配置することで、あるAZに障害が起きても、サービスを停止することなく稼働し続けられるようにしています。Fargate上のタスク、OpenSearch上のノードが単一障害点にならないように、ELB(NLBとALB)を配置し死活監視を行います。これにより単一の障害がワークロード全体に与える影響を低減しています。また、ELBを用いることで、負荷分散が可能になります。ALBはラウンドロビン、NLBはフローハッシュアルゴリズムによってリクエストをバックエンドのリソースにルーティングを行います。ELB自体についても、自動でスケールするため、ELBがボトルネックになることはありません。
OpenSearchは、3つのAZに3つのマスターノードを配置することでダウンタイムをなく、残りの2つの専用マスターノードがマスターを選択することができます。
CloudFormationには、データノード(Instance)3つ、マスターノード3つを3つのAZにデプロイするように設定しています。
OpenSearchServiceDomain:
Type: AWS::OpenSearchService::Domain
Properties:
ClusterConfig:
InstanceCount: 3
InstanceType: !Ref InstanceType
DedicatedMasterEnabled: true
DedicatedMasterType: !Ref InstanceType
DedicatedMasterCount: 3
ZoneAwarenessEnabled: true
ZoneAwarenessConfig:
AvailabilityZoneCount: 3
NLBをマルチAZに配置する際の注意点
ALBはクロスゾーン負荷分散がデフォルトで有効になっていますが、NLBは無効となっていますので、有効にしないと1つのAZに配置されます。クロスゾーン負荷分散を有効にすることで、AZ毎のリソースの数が異なっていても、負荷を均等に保つことができます。
CloudFormationには以下の設定を追加することで有効にすることができます。
Nlb:
Type: AWS::ElasticLoadBalancingV2::LoadBalancer
Properties:
LoadBalancerAttributes:
- Key: load_balancing.cross_zone.enabled
Value: true
OpenSearchをALBに接続する際の注意点
OpenSearchのエンドポイントはドメインエンドポイントとなりますが、ALBはドメインエンドポイントをターゲットにする事が出来ないため、Lambdaを用いて割り当てる必要があります。具体的な方法は、下記記事に記載しています。
障害から自動的に復旧する
ECSを利用し、DesiredCountを設定することで、クラスタ内に指定した数のタスクが走ることを維持することができます。一つのタスクが止まり指定した数よりもタスクが少ない場合に、タスクが自動で配置され、起動します。
LogstashService:
Type: AWS::ECS::Service
Properties:
DesiredCount: 2
キャパシティの推測をやめる
設計の原則に記載されているように、オンプレミスのワークロードにおける障害の一般的な原因はリソースの飽和状態で、ワークロードに対する需要がそのワークロードのキャパシティーを超えたときに発生します。ECSのタスクに対してApplicationAutoScalingを設定することで、タスクのワークロード使用率をモニタリングし、タスクの追加と削除を自動で行います。
以下では、タスクの最小数を3、最大数を6として設定しています。
ServiceScalingTarget:
Type: AWS::ApplicationAutoScaling::ScalableTarget
Properties:
MinCapacity: 3
MaxCapacity: 6
ApplicationAutoScalingはCloudWatchによりタスクのワークロードをモニタリングします。以下の参考では、CPUの使用率を監視し、70%を上回った時にスケールアウトし、50%を下回った時にスケールインするように設定しています。
番外:キャパシティプロバイダによるコスト最適化
ECSはキャパシティプロバイダを設定することで、クラスタ内のタスクで使用するインフラストラクチャを管理することができます。Fargateでは、FargateとFargate Spotキャパシティーの両方を使用することができ、Fargate Spotを使用すると、割り込み許容のあるECSのタスクをFargateの料金と比較して割引料金で実行することができます。
最後に
素人ながら、信頼性を考慮して設計を行いました。負荷試験などももちろん実施したことがないため、検証はこれから勉強しながら実施していきます。運用面の検討や、セキュリティについても検討しましたので、別の記事で紹介したいと思います。
Discussion