【Go】Goに入門する - 基礎編 -
Goの特徴
- 静的型付け
- コンパイラ言語(Binary生成)
- 並列処理(Goroutine)
- 実行速度がPythonなどに比べ速い
- 主にバックエンドとCLI開発
- ガベージコレクションによる遅延は発生する(許容できない場合はCやRustを検討)
参考Repo
Install & Setup
下記からインストールし、 コマンドを打って確かめる。それっぽいバージョンが帰ってきたらOK。
go version
適当なディレクトリを作成し、そこで下記のコマンドを入力する。
go mod init [module名]
これは、新しいモジュール(プロジェクト)を作成する際に使用するコマンドで、go.modというファイルが作成される。プロジェクトで外部のパッケージ(ライブラリ)を使うためには、モジュール管理が必要で、その設定をgo.modファイルに(基本的に自動で)記載される。依存パッケージの管理やバージョン管理のために必要なものと押さえておくとよさそう。
次にmain.goファイルを作成する。
Goでは一行目にそのファイルのコードがどのパッケージに属するかを指定する必要がある。プロジェクト内では、mainパッケージが自動的に作られるため、main.goの一行目に下記のように記載し、mainパッケージに属するように指定する。
package main
また、main関数はプロジェクトのエントリーになり、最初に実行される。
下記の例ではGoの標準パッケージであるfmtのPrintlnを使用して出力する。
package main
import "fmt"
func main() {
fmt.Println("hello world")
}
実行するには下記のコマンドをターミナルで打ち込む。無事出力されればOK!
$ go run main.go
hello world
ビルド(=Binaryファイル生成)するには下記のコマンドを打ち込む。
-oオプションでバイナリファイル名を変更できる。下記の例だとappという名前のバイナリファイルを生成している。
$ go build -o app main.go
作成されたバイナリファイルを実行してみると、hello worldと実行されることが確認できる。
$ ./app
hello world
environment variable
.envを読み込む場合下記のライブラリを使用する。
godotenv.Loadを呼ぶと、.envファイルが読み込まれる。
下記の例だと.envファイルが読み込まれ、.envで定義したGO_ENVの値が出力される。
package main
import (
"fmt"
"os"
"github.com/joho/godotenv"
)
func main() {
godotenv.Load()
fmt.Println(os.Getenv("GO_ENV"))
}
なお、インポートしたgithub.com/joho/godotenvは下記のコマンドを打てばインストールできる。
$ go mod tidy
Module, Package
Module
Goでは1つのプロジェクトに対して1つのモジュールが存在する。
外部に公開する場合は、一般的に下記のようなモジュール名になる。
module github.com/youraccount/repository
そしてモジュール直下には以下のファイルが1つずつ存在する。
- go.mod
- go.sum
また、モジュール配下に1つのエントリ(main.go)と複数のパッケージが存在することになる。モジュールとパッケージの関係は1対 Nの関係になる。
Package
小文字と大文字は区別する。
- パッケージ内だけで使用する変数/関数は小文字
- パッケージ外部でも使用する変数/関数は大文字
同じパッケージ間では、インポートせずに異なるファイルで定義した変数/関数が利用可能。
パッケージ跨ぎの場合、大文字で定義した変数/関数のみインポートすれば利用可能。
variable
変数定義方法は2種類ある。
- var
- :=
var
var i int
var i int = 2
var i = 2
- 初期値を与えたら型が類推される
- 初期値なしの場合ゼロ値(intであれば0)になる
:=
i := 1
ui := uint16(2)
fmt.Println(i)
fmt.Printf("i: %v %T\n", i, i) // i: i int
fmt.Printf("i: %[1]v %[1]T ui: %[2]v %[2]T\n", i, ui) // i: 1 int ui: 2 uint16
- 型は類推されるため指定不要
- 初期値必須
- 関数内でしか共有できない
複数定義も可能
var (
i int
s string
b bool
)
pi, title := 3.14, "Go"
型変換
x := 10
y := 1.23
z := x + y // Error: mismatched types int and float64
z := float64(x) + y // OK!
変数
変数は書き換え可能。
i := 1
i = 2
i += 2
i *= 2
fmt.Printf("i: %v\n", i) // i: 8
定数
constで定義した定数は書き換え不可能。
const secret = "abc"
func main() {
secret = "def" // Error: cannot assign to secret (neither addressable nor a map index expression)
}
また、constでは連番つきの定数がよく使われる。
type Os int
const (
Mac Os = iota + 1
Windows
Linux
)
func main() {
fmt.Printf("Mac: %v Windows:%v Linux:%v\n", Mac, Windows, Linux) // Mac: 1 Windows:2 Linux:3
}
pointer
ポインター
uint16では2バイト分のメモリが確保される。
変数名に&をつけると先頭アドレスを取得できる。
下記の例では、ui1とui2のアドレスを出力しているが、ちょうど2バイト分離れていることがわかる。
var ui1 uint16
fmt.Printf("memory address of ui1: %p\n", &ui1) // memory address of ui1: 0x1400010200a
var ui2 uint16
fmt.Printf("memory address of ui2: %p\n", &ui2) // memory address of ui2: 0x1400010200c
ポインター変数
ポインタ変数とは、他の変数のメモリ上のアドレスを指し示す変数のこと。
宣言時は型の前に*をつける。
var ui1 uint16
var p1 *uint16
fmt.Printf("value of p1: %v\n", p1) // nil
p1 = &ui1
fmt.Printf("value of p1: %v\n", p1) // 0x1400000e0ca
また、ポインター変数のポインタが指し示す先の変数の値を取得することを dereference と言う。
変数の先頭に*をつけることで dereference が可能。
fmt.Printf("value of ui1(dereference): %v\n", *p1) // 0
dereference で参照先の変数の値を書き換えることも可能。
*p1 = 2
fmt.Printf("value of p1: %v\n", ui1) // 2
ダブルポインタ
ポインタのポインタをダブルポインタという。
つまりダブルポインタは「ポインタ変数自体のアドレスを指すポインタ」となる。
var pp1 **uint16 = &p1
fmt.Printf("value of pp1: %v\n", pp1) // 0x14000110028
slice, map
配列定義
配列の初期化は以下のように行う。
var a1 [3]int
var a2 = [3]int{10, 20, 30}
a3 := [...]int{10, 20} // ...とすることで自動的に要素数が決まる
fmt.Printf("%v %v %v\n", a1, a2, a3) // [0 0 0] [10 20 30] [10 20]
fmt.Printf("%v %v\n", len(a3), cap(a3)) // 2 2
fmt.Printf("%T %T\n", a2, a3) // [3]int [2]int
配列は要素数が固定になる。より柔軟にデータを持ちたい場合はスライスを用いる。
slice
スライスは要素数を空にすると定義できる。
varと:=の定義の違いは、前者はnilとして認識されるのに対し、後者は(カーリーブラケットで初期化しているため)nilとして認識されない。
var s1 []int
s2 := []int{}
fmt.Println(s1) // []
fmt.Println(s2) // []
fmt.Println(s1 == nil) // true
fmt.Println(s2 == nil) // false
要素の追加は append で行う。
他のスライスを追加する際は ... として可変長であることを示す必要がある。
var s1 []int
s1 = append(s1, 1, 2, 3)
fmt.Println(s1) // [1 2 3]
s3 := []int{4, 5, 6}
// スライスに対してスライスを追加するには...を使用
s1 = append(s1, s3...)
fmt.Println(s1) // [1 2 3 4 5 6]
makeを使ったスライス定義は次のようになる。
// int型の要素数0、キャパシティ2のスライスを定義
s4 := make([]int, 0, 2)
fmt.Println(s4) // []
// とはいえキャパシティを超えて追加可能
s4 = append(s4, 1, 2, 3, 4)
fmt.Println(s4) // [1 2 3 4]
スライスの切り取りは次のようにできる。
ただし、スライスの切り取りはメモリを共有するようになっているため代入先の変更が代入元にまで影響することに注意する。
s5 := make([]int, 4, 6)
fmt.Println(s5) // [0 0 0 0]
// s5のindex1~2の要素をs6に代入
s6 := s5[1:3]
s6[1] = 10
fmt.Println(s5) // [0 0 10 0]
fmt.Println(s6) // [0 10]
// s6への要素追加はs5のキャパ(6)内に収まるためs5にも反映される
s6 = append(s6, 2)
fmt.Println(s5) // [0 0 10 2]
fmt.Println(s6) // [0 10 2]
メモリを共有させたくない場合はcopyを使用する。
copyは次のように使用する。コピー先の変更がコピー元に影響していないことがわかる。
// s5を作成
s5 := make([]int, 4, 6)
fmt.Println(s5) // [0 0 0 0]
// s5のindex1~2の要素を独立したスライスs6にコピー
s6 := make([]int, len(s5[1:3]))
copy(s6, s5[1:3])
// 書き換え
s6[1] = 10
fmt.Println(s5) // [0 0 0 0] ← 変更されない
fmt.Println(s6) // [0 10] ← s6だけが変更される
// s6に2を追加
s6 = append(s6, 2)
fmt.Println(s5) // [0 0 0 0] ← 変更されない
fmt.Println(s6) // [0 10 2] ← s6が独立している
スライスの部分的な要素に対してメモリを共有するやり方もある。
s5 := make([]int, 4, 6)
// index1~2まで切り取り、1~2までメモリを共有する
fs6 := s5[1:3:3]
fmt.Println(s5) // [0 0 0 0]
fmt.Println(fs6) // [0 0]
fs6[0] = 6
fs6[1] = 7
fs6 = append(fs6, 8)
fmt.Println(s5) // [0 6 7 0]
fmt.Println(fs6) // [6 7 8]
s5[3] = 9
fmt.Println(s5) // [0 6 7 9]
fmt.Println(fs6) // [6 7 8]
map
mapの基本的な使い方は次のようになる。
// keyがstring, valueがintのマップを定義
var m1 map[string]int
m2 := map[string]int{}
fmt.Println(m1) // map[]
fmt.Println(m2) // map[]
fmt.Println(m1 == nil) // true
fmt.Println(m2 == nil) // false
// 追加
m2["A"] = 10
m2["B"] = 20
m2["C"] = 0
fmt.Println(m2) // map[A:10 B:20 C:0]
// 削除
delete(m2, "A")
// 存在しない値を取得しようとすると0が返される
fmt.Println(m2["A"]) // 0
// ただキーは存在するが値が0の場合も0になる
fmt.Println(m2["C"]) // 0
// 値として存在するのか、そもそも存在しないのかは ok を使って判別できる
// そもそも存在しない場合ok = false
v, ok := m2["A"]
fmt.Println(v, ok) // 0 false
// 存在する(値が0)場合ok = true
v, ok = m2["C"]
fmt.Println(v, ok) // 0 true
mapの要素をfor文で取り出す方法は次のようになる。
必ず同じ順番で取り出すことは保証されないので注意。
for k, v := range m2 {
fmt.Printf("%v %v\n", k, v)
}
struct, receiver
struct
構造体を作ることができる。構造体とは、実体を作る型のようなもの。
type Task struct {
Title string
Estimate int
}
func main() {
// 実態を生成
task1 := Task{
Title: "Learn Golang",
Estimate: 3,
}
// Titleを書き換え
task1.Title = "Learning Go"
fmt.Println(task1) // {Learning Go 3}
fmt.Println(task1.Title) // Learning Go
// task1とtask2は別のメモリ領域に格納されることを示す
var task2 Task = task1
task2.Title = "new"
fmt.Println(task1) // {Learning Go 3}
fmt.Println(task2) // {new 3}
// &をつけてポインタ変数を作成
task1p := &Task{
Title: "Learn concurrency",
Estimate: 2,
}
task1p.Title = "Changed"
// dereferenceして実態を出力
fmt.Println(*task1p) // {Changed 2}
// 新たにポインタ変数を作成
var task2p *Task = task1p
task2p.Title = "Changed by Task2"
// task1p, task2p は 同じ構造体を指しているため、変更はもう一方のポインタでも反映される
fmt.Println(*task1p) // {Changed by Task2 2}
fmt.Println(*task2p) // {Changed by Task2 2}
}
receiver
receiverという仕組みを使って構造体に関連づけられたメソッドを定義できる。
receiverには以下の2種類ある。
- 値レシーバー
- ポインタレシーバー
値レシーバー
値レシーバーでは、その型のインスタンスのコピーがメソッドに渡される。そのため、メソッド内でレシーバーを変更しても元のオブジェクトには影響しない。
type Task struct {
Title string
}
func (t Task) UpdateTitle(newTitle string) {
t.Title = newTitle
}
func main() {
task := Task{Title: "Learn Go"}
task.UpdateTitle("Master Go")
fmt.Println("Task Title:", task.Title) // Task Title: Learn Go
}
ポインタレシーバー
ポインタレシーバーでは、レシーバーのポインタがメソッドに渡される。
これにより、レシーバーのフィールドをメソッド内で変更すると、その変更が元のオブジェクトに反映される。
type Task struct {
Title string
}
// ポインタを受け取れるようにする
func (t *Task) UpdateTitle(newTitle string) {
t.Title = newTitle
}
func main() {
task := Task{Title: "Learn Go"}
fmt.Println("Before:", task.Title) // "Before: Learn Go"
task.UpdateTitle("Master Go")
fmt.Println("After:", task.Title) // "After: Master Go"
}
function, closure
function
以下は関数を定義しdefereを付与した処理を記載している。
defereについては以下の2つを押さえておく。
- defer へ渡した関数の実行を、呼び出し元の関数の終わり(returnする)まで遅延させる
- defer へ渡した関数の引数は、すぐに評価されるが、その関数自体は呼び出し元の関数がreturnするまで実行されない
func funcDefer() {
defer fmt.Println("main func final-finish")
defer fmt.Println("main func semi-finish")
fmt.Println("hello world")
}
func main() {
funcDefer()
}
実行結果はこのようになる。
hello world
main func semi-finish
main func final-finish
ファイル名の拡張子を排除した配列を返す関数の実装は次のようなものになる。
func trimExtension(files ...string) []string {
out := make([]string, 0, len(files))
for _, f := range files {
out = append(out, strings.TrimSuffix(f, ".csv"))
}
return out
}
func main() {
// funcDefer()
files := []string{"file1.csv", "file2.csv", "file3.csv"}
fmt.Println(trimExtension(files...)) // [file1 file2 file3]
}
ファイルを開いてファイルオブジェクトの参照を返す関数の実装は次のようなものになる。
func fileChecker(name string) (string, error) {
f, err := os.Open(name)
if err != nil {
return "", errors.New("file not found")
}
defer f.Close()
return name, nil
}
name, err := fileChecker("file.txt")
if err != nil {
fmt.Println(err)
return
}
fmt.Println(name)
無名関数
無名関数は以下のようにする。
関数のお尻に()をつけることで即時実行する(即時関数)。
i := 1
func(i int) {
fmt.Println(i) // 1
}(i)
即時実行しない無名関数は下記の通り。
f1 := func(i int) int {
return i + 1
}
fmt.Println(f1(2)) // 3
引数に無名関数を渡す例。
func addExt(f func(file string) string, name string) {
fmt.Println(f(name))
}
f2 := func(file string) string {
return file + ".csv"
}
addExt(f2, "file") // file.csv
無名関数を返す関数の例。
func multiply() func(int) int {
return func(n int) int {
return n * 1000
}
}
f3 := multiply()
fmt.Println(f3(2)) // 2000
closure
カウンターするクロージャーを作成。
func countUp() func(int) int {
count := 0
return func(n int) int {
count += n
return count
}
}
f4 := countUp()
for i := 1; i <= 5; i++ {
v := f4(2)
fmt.Println(v)
}
実行結果はこのようになる。
// 2
// 4
// 6
// 8
// 10
interface
型の一種でメソッドを定義できる。構造体(struct)とともに使うことが多い。
下記の例だと、vehicleという構造体は、controllerのもつメソッド2つを実装しているため、「vehicleはcontrollerのインターフェースを実装している」と言える。
type controller interface {
speedUp() int
speedDown() int
}
type vehicle struct {
speed int
enginePower int
}
func (v *vehicle) speedUp() int {
v.speed += 10 * v.enginePower
return v.speed
}
func (v *vehicle) speedDown() int {
v.speed -= 5 * v.enginePower
return v.speed
}
そして、constrollerの引数を受け取って2つのメソッドを実行する関数を作成する。
func speedUpAndDown(c controller) {
fmt.Println(c.speedUp())
fmt.Println(c.speedDown())
}
呼び出す。
vはcontrollerインターフェースを実装したvehicleなので引数のcontroller条件を満たすため、引数に渡すことができる。
func main() {
// 実体を生成
v := &vehicle{0, 5}
speedUpAndDown(v)
}
実行結果。
// 50
// 25
ちなみにインターフェースで定義したメソッドいずれかが未実装の構造体を渡した場合、エラーとなる。上記の例で言うと、例えばspeedDownを実装した関数をコメントアウトするとspeedDownが抜けていると怒られる。
cannot use v (variable of type *vehicle) as controller value in argument to speedUpAndDown: *vehicle does not implement controller (missing method speedDown)
また、Stringメソッドを以下のようにvehicleに対して実装する。
func (v vehicle) String() string {
return fmt.Sprintf("Vehicle current speed is %v (enginePower %v)", v.speed, v.enginePower)
}
そして、fmt.Printlnにvehicleを渡すと以下の結果が出力される。
fmt.Println(v) // Vehicle current speed is 25 (enginePower 5)
これは、Printlnをすると引数で渡された値にString()メソッドが実装されているかチェックされ、実装されていたらその返り値を返しているためである。
また、どんな型でも受け入れることができる any 型は interface で定義可能。以下はどちらも同じany型を意味する。
var i1 interface{}
var i2 any
if, for, switch
if
if 文は下記のように書く。
a := -1
if a == 0 {
fmt.Println("zero")
} else if a > 0 {
fmt.Println("positive")
} else {
fmt.Println("negative")
}
実行結果
negative
for
for文は以下のように書く。
for i := 0; i < 5; i++ {
fmt.Println(i)
}
実行結果
0
1
2
3
4
継続条件の記載を省略すると無限ループになるため注意。
// 継続条件を省略すると無限ループになる
for {
fmt.Println("Working")
time.Sleep(2 * time.Second) // 2秒待つ
}
break でループから抜けることができる。
// breakでループから抜ける
var i int
for {
if i > 3 {
break
}
fmt.Println(i)
i += 1
time.Sleep(300 * time.Millisecond)
}
実行結果
0
1
2
3
switch
for文とswitch文を組み合わせることもできる。
下記の例だと8の時にbreakしているが単にbreakだけを書くとswitch文を抜けることになる。
for文にloopと名前をつけ、breakにfor文名を指定することで8の時にループを抜けることができる。
loop:
for i := 0; i < 10; i++ {
switch i {
case 2:
continue
case 3:
continue
case 8:
break loop // ATTENTION!!
default:
fmt.Printf("%v ", i)
}
}
for...rangeでループすることもできる。
type item struct {
price float32
}
// 3つの構造体を持つitem型のスライス
items := []item{
{price: 10},
{price: 20},
{price: 30},
}
for i := range items {
items[i].price *= 1.1
}
fmt.Printf("%+v\n", items) // [{price:11} {price:22} {price:33}]
errors
エラー定義
errorsパッケージを使用してエラーを定義できる。
err01 := errors.New("something wrong")
// %pでポインタの位置を、%Tで型を、%vで値を出力
fmt.Printf("%[1]p %[1]T %[1]v\n", err01) // 0x1400008e050 *errors.errorString something wrong
fmt.Println(err01) // something wrong
ちなみに全く同じエラーを定義して比較してみるとfalseになる。
なぜならerr01とerr02はerros.Newされた際に異なるメモリ空間に定義されるためである。
err01 := errors.New("something wrong")
err02 := errors.New("something wrong")
fmt.Println(err01 == err02) // false
エラーのラップ
fmt.Errorfを使って、新しいエラーメッセージadd infoを作成し、そのエラーメッセージに元のエラー(errors.New("original error") で作られたエラー)をラップしている。
%wで、ラップされたエラーを保持するために使われ、元のエラーが後からアクセス可能になる。
err0 := fmt.Errorf("add info: %w", errors.New("original error"))
fmt.Printf("%[1]p %[1]T %[1]v\n", err0) // 0x140000bc000 *fmt.wrapError add info: original error
アンラップすると付加情報(add info)が除かれ、元のエラーが取得できる。
fmt.Println(errors.Unwrap(err0)) // original error
センチネルエラー
センチネルエラーとは、特定のエラー状態を表すために、あらかじめ定義されている固定値のエラーのこと。
複数ラップされたエラーがあり、それがセンチネルエラーであるかどうか確認するケースを例にとる。まずセンチネルエラーを定義しそれをラップしたerr2を定義する。err2はさらにラップされている。
var ErrCustom = errors.New("not found")
err2 := fmt.Errorf("in repository layer: %w", ErrCustom)
fmt.Println(err2) // in repository layer: not found
err2 = fmt.Errorf("in service layer: %w", err2)
fmt.Println(err2) // in service layer: in repository layer: not found
ここで、err2がErrCustomのエラーであるかどうかerrors.Isで確認する。
if errors.Is(err2, ErrCustom) {
fmt.Println("matched") // matched
}
標準パッケージに用意されているエラー(os.ErrNotExist)も使ってみる。
os.Open()でファイルが存在しない場合、ErrNotExistというエラーが返ってくる仕様のためerr3で返されるエラーはos.ErrNotExistになりif文の中が実行される。
func fileChecker(name string) error {
f, err := os.Open(name)
if err != nil {
return fmt.Errorf("in checker: %w", err)
}
defer f.Close()
return nil
}
file := "dummy.txt"
err3 := fileChecker(file)
if err3 != nil {
if errors.Is(err3, os.ErrNotExist) {
fmt.Printf("%v file not found\n", file) // dummy.txt file not found
} else {
fmt.Println("unknown error")
}
}
generics
genericsで型決定を遅延させることができる。
また、interfaceで型制約をかけることも可能。
type customConstraints interface {
int | int16 | float32 | float64 | string
}
// TにcustomConstraintsで制約をつける
func add[T customConstraints](x, y T) T {
return x + y
}
add(1, 2)
add(1.1, 2.2)
add("file", ".txt")
unittest
以下の2つの関数をテストするとする。
func add(x, y int) int {
return x + y
}
func divide(x, y int) float32 {
if y == 0 {
return 0.
}
return float32(x) / float32(y)
}
addを右クリックしてテストを自動生成できる。
package main
import "testing"
func Test_add(t *testing.T) {
type args struct {
x int
y int
}
tests := []struct {
name string
args args
want int
}{
// TODO: Add test cases.
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
if got := add(tt.args.x, tt.args.y); got != tt.want {
t.Errorf("add() = %v, want %v", got, tt.want)
}
})
}
}
TODO箇所にテストケースを追加。
{
name: "1+2=3",
args: args{x: 1, y: 2},
want: 3,
},
以下のコマンドをターミナルに入力しテストする。
-vは詳細表示のオプション。
$ go test -v .
=== RUN Test_add
=== RUN Test_add/1+2=3
--- PASS: Test_add (0.00s)
--- PASS: Test_add/1+2=3 (0.00s)
PASS
ok go-basics 0.205s
divideの方も自動生成するとテストケースが追加される。
以下はTODOにテストケースを追加後の例。
package main
import (
"testing"
)
func Test_add(t *testing.T) {
type args struct {
x int
y int
}
tests := []struct {
name string
args args
want int
}{
{
name: "1+2=3",
args: args{x: 1, y: 2},
want: 3,
},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
if got := add(tt.args.x, tt.args.y); got != tt.want {
t.Errorf("add() = %v, want %v", got, tt.want)
}
})
}
}
func Test_divide(t *testing.T) {
type args struct {
x int
y int
}
tests := []struct {
name string
args args
want float32
}{
{
name: "1/2=0.5",
args: args{x: 1, y: 2},
want: 0.5,
},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
if got := divide(tt.args.x, tt.args.y); got != tt.want {
t.Errorf("divide() = %v, want %v", got, tt.want)
}
})
}
}
また、どの程度テストがカバーできているかカバレッジを出してみる。
以下だとカバレッジ75%となっており全てのケースがテストできていないことがわかる。
$ go test -v -cover -coverprofile=coverage.out .
=== RUN Test_add
=== RUN Test_add/1+2=3
--- PASS: Test_add (0.00s)
--- PASS: Test_add/1+2=3 (0.00s)
=== RUN Test_divide
=== RUN Test_divide/1/2=0.5
--- PASS: Test_divide (0.00s)
--- PASS: Test_divide/1/2=0.5 (0.00s)
PASS
coverage: 75.0% of statements
ok go-basics 0.205s coverage: 75.0% of statements
coverage.outはこのような感じ。
mode: set
go-basics/main.go:3.24,5.2 1 1
go-basics/main.go:7.31,8.12 1 1
go-basics/main.go:8.12,10.3 1 0
go-basics/main.go:11.2,11.32 1 1
go-basics/main.go:14.14,18.2 0 0
カバレッジのログファイルは下記で出力可能。
$ go tool cover -html=coverage.out
するとブラウザが立ち上がり、どの部分がテストできていないか視覚的にわかる。
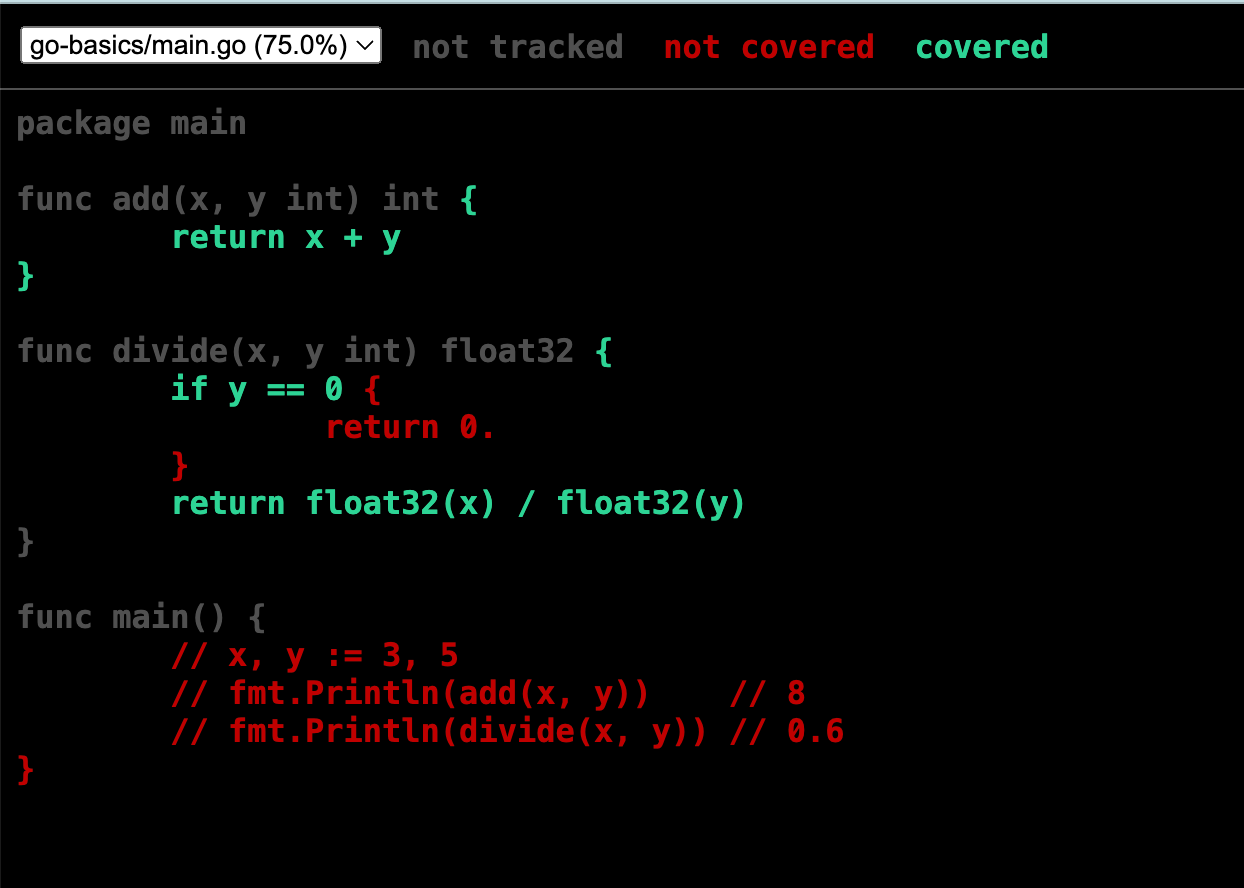
最後の赤部分はコメントアウトなので、yが0のケースを追加したらカバレッジ100%を達成できる。
logger
package main
import (
"io"
"log"
"os"
)
func main() {
file, err := os.Create("log.txt")
if err != nil {
// Fatallnでエラーのログを出力し、プログラムを強制終了する
log.Fatalln(err)
}
defer file.Close()
// ログのオプション設定
// Lshortfileでログに行表示を含め、LstdFlagsで時刻情報を含める
flags := log.Lshortfile | log.LstdFlags
// log.Newでログを新規作成
// 第一引数で、MultiWriterでfileと標準出力(Stderr)両方に書き込む
// 第二引数でログの先頭に表示したい文言を指定
// 第三引数でログオプション
warnLogger := log.New(io.MultiWriter(file, os.Stderr), "WARN: ", flags)
errorLogger := log.New(io.MultiWriter(file, os.Stderr), "ERROR: ", flags)
warnLogger.Println("warning A")
errorLogger.Fatalln("critical error")
}
以下のコマンドをターミナルに入力。
L24でwarning Aというログが出ていることがわかる。
$ go run .
WARN: 2024/10/06 01:13:24 main.go:26: warning A
ERROR: 2024/10/06 01:13:24 main.go:27: critical error
exit status 1
また、log.txtというファイルが生成され、同様のログが出力されている。