ナレッジグラフ(1)
はじめに
ナレッジグラフに関する2021年発表のサーベイ論文を紹介します。本論文は、全37ページにわたって、ナレッジグラフの要素技術を幅広く網羅しています。基本的な概念や技術の全体像を把握するのに適した内容で、ナレッジグラフを初めて学ぶ方にも、理解をさらに深めたい方にも有用です。中でも、第3章の演繹的推論と第4章の帰納的推論は、ナレッジグラフと機械学習の関係を理解する上で非常に有用です。本論文を出発点に、参考文献を調査したり、本論文を引用している関連文献を辿ることで、ナレッジグラフに関する知識をさらに広げることができます。
A. Hogan et al., “Knowledge Graphs,” ACM Computing Surveys, vol.54, no.4, pp.71:1–71:37, 2021.
論文の構成は以下の通りです。以降では、各章の概要をざっと紹介します。
- Introduction
- Data Graphs
- Deductive Knowledge
- Inductive Knowledge
- Summary and Conclusion
各章の概要
- Introduction
1.1 Overview and Novelty
1.2 Terminology
1.3 Article Structure
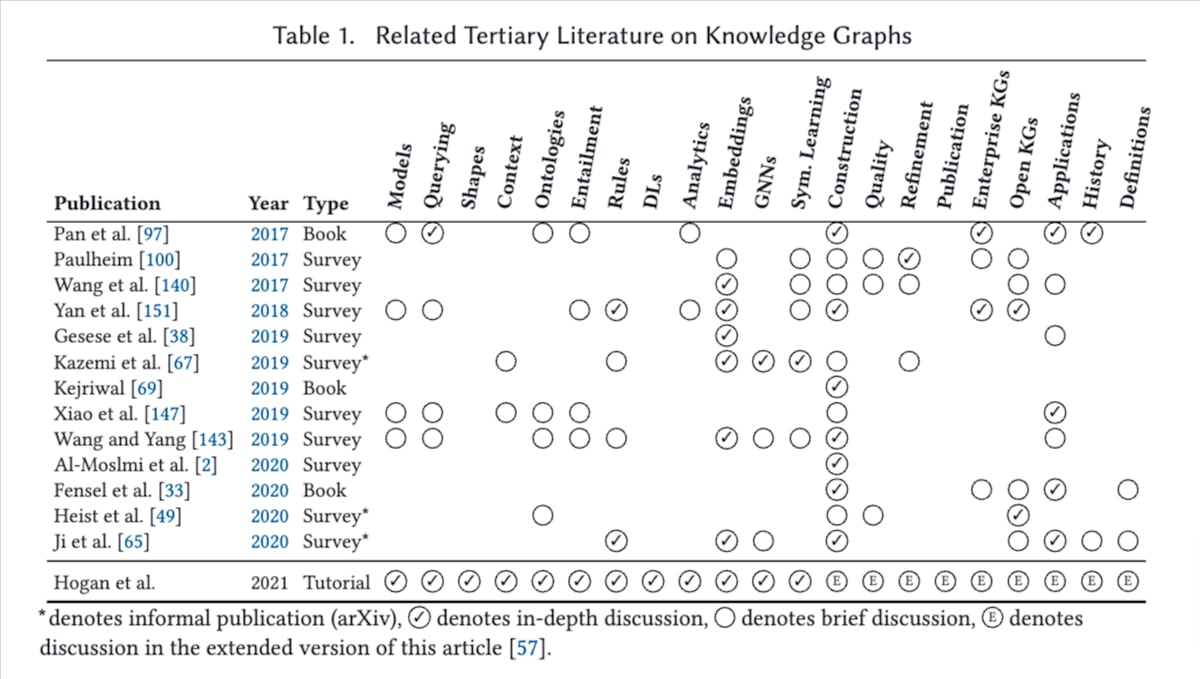
- 本論文は、ナレッジグラフの基礎概念や技術を広範かつ包括的に解説します。既存文献との差異として、特定の実装やツールに焦点を当てるのではなく、ナレッジグラフの主要な概念と技術を広く紹介することを重視しています(下図を参照。拡張版[57]については、おわりにを参照)。
- ナレッジグラフは、現実世界の知識を蓄積・伝達するデータのグラフであり、オープン型と企業内利用のエンタープライズ型に分類されます。知識は、演繹的手法および帰納的手法を利用して拡張可能です。
- Data Graphs
2.1 Models
2.2.1 Directed Edge-labelled Graphs
2.1.2 Heterogeneous Graphs
2.1.3 Property Graphs
2.1.4 Graph Dataset
2.1.5 Other Graph Data Models
2.1.6 Graph Stores
2.2 Querying
2.2.1 Graph Patterns
2.2.2 Complex Graph Patterns
2.2.3 Navigational Graph Patterns
2.2.4 Other Features
2.3 Validation
2.3.1 Shapes Graphs
2.3.2 Conformance
2.3.3 Other Features
2.4 Context
2.4.1 Direct Representation
2.4.2 Reification
2.4.3 Higher-arity Representation
2.4.4 Annotations
2.4.5 Other Contextual Frameworks
第2章では、グラフデータモデルの概要と、それをクエリおよび検証するための言語について説明します。
- ナレッジグラフは、現実世界のエンティティをノード、エンティティ間の関係をエッジで表現します。代表的なモデルには、有向エッジラベル付きグラフ、プロパティグラフ、RDF(Resource Description Framework)があります。プロパティグラフはノードやエッジに属性を持たせる特徴があり、RDFは異なるデータを統合しやすい標準化された仕組みを提供します。これらのグラフモデルは、リレーショナルデータベースよりも直感的で柔軟にデータの関係性を表現できる点で優れ、知識の統合や管理に適しています。
- クエリ言語は、ナレッジグラフ内のデータを検索・操作するための手段を提供します。SPARQLはRDFに対応し、パターンマッチングを基に柔軟なデータクエリが可能です。一方、GremlinやCypherはプロパティグラフ用で、Gremlinはノード間をたどる「トラバース型」、CypherはSQLに似た「宣言型」のクエリを提供します。
- 大規模で多様なデータを扱うナレッジグラフでは、異なるデータソースの統合やスキーマの変更による影響でデータ間に不整合が生じる可能性があります。ナレッジグラフの検証は、データ構造が指定された制約を満たしているかを確認するものです。制約は、ノードやエッジに関する属性や接続のルールを指定した「シェイプグラフ(Shape Graph)」によって定義されます。こうした検証により、一貫性やデータ構造の完全性を保証することができます。シェイプグラフを記述する言語にはShape Expressions(ShEx)とSHACLがあります。
- ナレッジグラフは、データの意味を、そのデータに関する時間、場所、出典などの「コンテキスト」で表現します。表現方法には、直接表現(属性として追加)、リエフィケーション(エッジをリソースとして再定義)、高次元表現(多次元データの活用)などがあります。また、注釈(Annotations)を用いることで、データの信頼性や不確実性を記述することも可能です。
- Deductive Knowledge
3.1 Ontologies
3.1.1 Interpretations
3.1.2 Assumptions
3.1.3 Semantic Conditions
3.1.4 Individuals
3.1.5 Properties
3.1.6 Classes
3.1.7 Other Features
3.2 Semantics and Entailment
3.2.1 Model-theoretic Semantics
3.2.2 Entailment
3.3 Reasoning
3.3.1 Rules
3.3.2 Description Logics
第3章では、知識を表現し、新しい知識を導き出すための演繹的な形式論を紹介します。
- オントロジーは、ナレッジグラフにおいてデータの意味や構造を体系化するためのルールや仕組みです。例えば、「都市」「観光地」といったグループ(クラス)を定義し、それに「サンティアゴ」や「マチュピチュ」などのエンティティ(個別要素)を分類します。プロパティはこれらの要素の関係を表し、「サンティアゴは都市」といった情報をつなげる役割です。さらに、プロパティには「対称性(例: AがBに関連するならBもAに関連)」「推移性(例: AがB、BがCに関連するならAがCに関連)」といった性質を持たせることもできます。クラスやプロパティのルールを設定することで、ナレッジグラフは整理され、隠れている関係を見つけることができます。
- 演繹的推論は、オントロジーやルールを利用してナレッジグラフから新しい情報を導き出す仕組みです。例えば、データ「サンディエゴは都市である」と、ルール「すべての都市は場所」があれば、「サンティアゴは場所」という結論が導かれます。この得られた結論、すなわち新しい知識をエンテイルメント(含意)と呼びます。これらの仕組みによって、ナレッジグラフは明示的に記述されていない暗黙的な情報を導き出すことができ、単なるデータの集まりではなく「知識」の集積として利用することができます。
- Inductive Knowledge
4.1 Graph Analytics
4.1.1 Graph Algorithms
4.1.2 Graph Processing Frameworks
4.2 Knowledge Graph Embeddings
4.2.1 Translational Models
4.2.2 Tensor Decomposition Models
4.2.3 Neural Models
4.2.4 Language Models
4.2.5 Entailment-aware Models
4.3 Graph Neural Networks
4.3.1 Recursive Graph Neural Networks
4.3.2 Convolutional Graph Neural Networks
4.4 Symbolic Learning
4.4.1 Rule Mining
4.4.2 Axiom Learning
第4章では、追加の知識を発見するための帰納的技術を説明します。
- グラフ解析とは、グラフネットワークに分析アルゴリズムを適用し、その構造(トポロジー)やノード間の接続関係を調べる手法です。ナレッジグラフの特徴抽出に使われる代表的なアルゴリズムには、重要なノードやエッジを特定する「中心性」、密接に結びついたサブグラフを見つける「コミュニティ検出」、グラフ全体の頑健性を評価する「接続性分析」、接続パターンが似たノードを見つける「ノード類似性」、大規模なグラフを簡略化して全体を把握する「グラフ要約」などがあります。また、Apache Spark(GraphX)、GraphLab、Pregelといったグラフ処理フレームワークを利用することで、大規模なナレッジグラフの解析を効率よく行うことも可能です。
- ナレッジグラフ埋め込みは、グラフを数値ベクトルに変換し、機械学習で扱いやすい形式に変換する技術です。これにより、グラフ構造を保持しながら、低次元の連続空間でデータを表現できます。埋め込みがグラフ構造を正しく反映しているかを確認する仕組みとして、正のエッジ(グラフ内に存在するエッジ)のスコアを最大化させ、負の例(存在しないエッジ)のスコアを最小化することで、信頼性の高い埋め込みを生成します。この埋め込みは、グラフの特徴を潜在的に表現し、リンク予測や類似性計算などに利用されます。代表的な埋め込み手法として、「Translational Models」など5つのモデルが紹介されています。
- 埋め込み手法とは別に、グラフ専用の機械学習アーキテクチャを設計するアプローチがあります。その1つであるグラフニューラルネットワーク(GNN)は、ニューラルネットワークをグラフの構造に適応させたものです。通常のニューラルネットワーク(例えばfully connected feed forward NN)は均一な構造を持ちますが、GNNではグラフの特徴を反映し、ノードとその隣接するノードとが接続されるように設計されています。GNNはエンドツーエンドの教師あり学習をサポートしており、グラフ内の要素やグラフ全体の分類が可能です。化合物や画像の分類、交通予測、推薦システム、ナレッジグラフ内の重要ノードの特定など、幅広い応用が実現されています。GNNには、再帰型と畳み込み型という代表的な2つのアプローチがあります。
- これまで紹介した教師あり学習では数値モデルを使用しますが、その結果がどのように導き出されたのかを理解するのが難しいという課題があります。一方、ナレッジグラフにおけるシンボリック学習では、正のエッジ(存在する関係)と負のエッジ(存在しない関係)を基に、新しい関係やパターンを推測するルールを学習します。このルールは解釈がしやすい形式で表現されるのが特徴です。代表的な手法として、「もし~ならば~」という条件付きルールを発見する「ルールマイニング」と、「すべての~は~である」「~と~は重ならない」といった論理的ルール(公理)を見つける「公理マイニング」があります。
- Summary and Conclusion
第5章では、将来の研究課題を取り上げています。
- 注目の研究テーマとして、ラベルやプロパティの意味を考慮したプロパティグラフの形式論、状況に応じたデータを推論・クエリする手法、数値表現を用いた近似的なクエリ応答、時間や場所に応じて変化する埋め込み技術が挙げられます。
- ルールやオントロジーを埋め込みに統合する技術、複雑な分類が可能なグラフニューラルネットワーク、さらに進化したルールおよび公理マイニングなども重要なテーマです。
- スケーラビリティやデータとモデルの品質、マルチモーダルデータの取り扱い、動的データへの対応、そしてユーザビリティなどの課題も残されています。
おわりに
サーベイ論文の概要を紹介し、ナレッジグラフの要素技術を俯瞰しました。本論文で取り上げられているナレッジグラフの具体例に関するデータは、こちらで公開されています。
本論文は2021年に発表されたもので、大規模言語モデル(Large Language Model, LLM)や検索拡張生成(Retrieval-Augmented Generation, RAG)といった最新技術には触れていません。そのため、これらの分野については別途調査が必要です。
また、本論文の基となっているarxiv版は135ページにもおよぶ大作で、ACM掲載にあたり内容が一部圧縮されています。圧縮された内容を含む拡張版が公開されています。
次回は、ACM論文と拡張版の差分について紹介する予定です。
Discussion