FPGAラピッドプロトタイピングでMMIOに簡易的にアクセスする
この記事はHardware Description Language Advent Calendar 2024向けに書いた記事です。
はじめに
CPU からアクセスして何らかの設定や制御を行うロジックをRTLで開発する場合、メモリアドレスに何らかの機能をマッピングする事が多いです。
いわゆる MMIO(メモリマップドI/O) などと呼ばれるものです。
きちんとした製品を作る場合、各ロジックモジュール毎にちゃんとしたデバイスドライバを作るべきですが、幾つかの理由で簡単にアクセスしたいケースは多々あります。
- 研究開発における実験のフェーズ(ラピッドプロトタイピング)
- デバイスドライバとは別にロジックモジュールそのものの実機テストを書きたいケース
- GPLライセンスなどの関連でカーネルに組み込まれるデバイスドライバにしたくないケース
筆者は基本的に ラピッドプロトタイピング にFPGAを活用する派なので以降その前提で話を書きますが、この時に「一概に簡単にアクセスしたい」と言っても
など幾つかのパターンがあったりもします。
アクセスされる側も多彩で
- 単なる制御レジスタの読み書きがしたい
- メモリやキュー(FIFO)に対してバーストアクセスしたい
- メモリアクセスというアクション自体に特別な意味を持たせる
といろいろあり、最後のものは筆者はRTOSのFPGA化をした時などは多用しました。
何れにせよ、いろいろな環境において、CPUの発生できるアクセスパターンをなるべく明確に定義して、MMIO に簡便にアクセスできるソフトウェアライブラリがあれば RTL開発が捗るだろうという事で、過去にC++用のライブラリとか、Rust用のクレートとかを作ってみた経緯があるので、少し整理して紹介したいと思います。
前提とする環境
私が前提として置いた環境として
- あまりGUIツールに頼らずにRTLで記述したものでも使えるようにする
- アドレスが階層的に管理されている
- 同じIPでも接続バス幅は可変
といったものを考えています。
例えば下記のような環境で、アドレスデコーダが階層的に存在し、ベースアドレス違いで同じような構成が繰り返されるケースです。
構成は実在のものでもなく別段の意味はないのですが、2カメラと1モニタのシステムみたいなものを書いてみました。
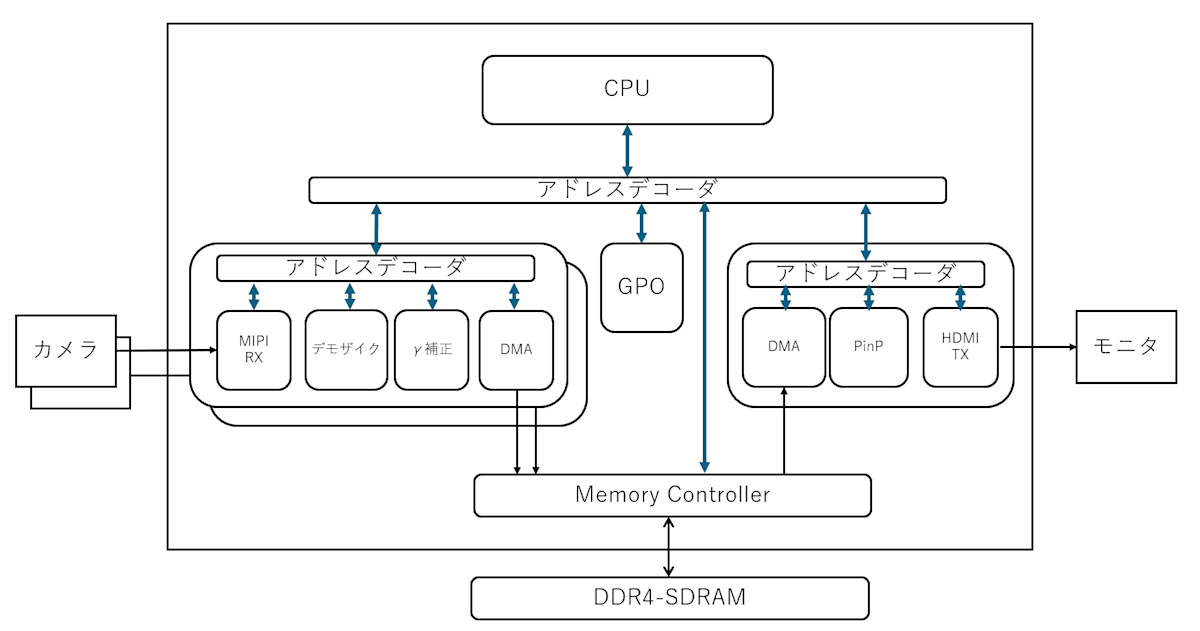
この時 アドレスデコーダも RTL で書いてしまっているようなケースも範疇に含みます。
AMD の Vivado などの場合、GUI の Block Design でいろいろ置いてしまえば、ある程度 GUI ツールがアドレスとかの面倒も見てくれるわけですが、GUI 任せにするとツールのバーションが上がった時など面倒なので、私のようなRTLで書いておきたい派も一定数いるのではないかと思います。
また、接続されるバス幅も可変とすることにします。
これは RTL を書いてみるとわかると思いますが、バス幅の単位でレジスタを並べると楽です。Zynq-7000 は 32bit CPU だけど ZynqMP は 64bit CPU だったりするので、私はそのあたりサクッと切り替える派です。
そうすることで DMA のアドレスやサイズなども 64bit 幅に簡単に拡張できます。
例えば、UART でおなじみの 16450/16550 ですが、8bit CPU 時代はバイト単位でレジスタが配置されており、実際に PC/AT互換機のIO空間にも8bitアクセスの連続番地で置かれているのですが、このあたりでは、バス幅32bit が想定されており、32bit ステップでレジスタが配置されています。
そもそもこの手は読んだだけステータスが変わるレジスタも居るので、うかつにアドレスを詰めると、例えば 64bit CPU に繋いだ時に 32bit アクセスのつもりが「お隣のレジスタも読んだことにされていた」なんて危険な事が起こりかねないわけで、なるべくCPUネイティブなバス幅をそのまま使っておいた方が余計なトラブルに巻き込まれません。
などなど踏まえて、ライブラリを作っています。
アドレスデコーダ
私はよく RTL でアドレスデコーダを書いてしまいます。
WISHBONE の場合
最近ようやく AXI4-Lite への書き換えを進めていますが、私は基本的に WISHBONE バス規格の必要最低限の信号だけを使うという事をよくやっていました。
拙作の Jelly の ここから引用しますが、例えば、こんな感じでアドレスデコーダを構成していました。
// アドレス選択
assign wb_sys_stb_i = wb_peri_stb_i & (wb_peri_adr_i[24:13] == 12'h000); // 0x80000000-0x8000ffff
assign wb_fmtr_stb_i = wb_peri_stb_i & (wb_peri_adr_i[24:13] == 12'h010); // 0x80100000-0x8010ffff
assign wb_rgb_stb_i = wb_peri_stb_i & (wb_peri_adr_i[24:13] == 12'h012); // 0x80120000-0x8012ffff
assign wb_sel_stb_i = wb_peri_stb_i & (wb_peri_adr_i[24:13] == 12'h013); // 0x80130000-0x8013ffff
assign wb_vdmaw_stb_i = wb_peri_stb_i & (wb_peri_adr_i[24:13] == 12'h021); // 0x80210000-0x8021ffff
// 読み出しデータ選択
assign wb_peri_dat_o = wb_sys_stb_i ? wb_sys_dat_o :
wb_fmtr_stb_i ? wb_fmtr_dat_o :
wb_rgb_stb_i ? wb_rgb_dat_o :
wb_sel_stb_i ? wb_sel_dat_o :
wb_vdmaw_stb_i ? wb_vdmaw_dat_o :
{WB_DAT_WIDTH{1'b0}};
// アクノリッジ選択
assign wb_peri_ack_o = wb_sys_stb_i ? wb_sys_ack_o :
wb_fmtr_stb_i ? wb_fmtr_ack_o :
wb_rgb_stb_i ? wb_rgb_ack_o :
wb_sel_stb_i ? wb_sel_ack_o :
wb_vdmaw_stb_i ? wb_vdmaw_ack_o :
wb_peri_stb_i;
WISHBONE バスは、バス幅に隠れてしまう下位のアドレスを持たないのでアドレスをシフトして読まないといけないというのはあるのですが、比較的少ない記述量で書けるので好んで使っていました。
また、基本的にはペリフェラルバスはそれほど高いクロックを割り当てていなかったのであまり気にせずにデコードしていました。
AXI4-Lite の場合
最近少し心を入れ替えて(?)、「ペリフェラルバスもコアと同じ周波数にして完全同期回路がいいのでは?」という考えも踏まえて、AXI4-Lite の導入を思考中です。
何より Vivado はもちろん Verilator などのよく使うシミュレータで SystemVerilog の Interface がそこそこ動くようになってきたというのが一番の動機でしょうか?
AXI4-Lite の課題は、Lite といいつつ信号数が多く、ソースコードがごちゃごちゃしがちなところでしたので、Interface で綺麗に書ければそれはそれで解決するわけです。
まだ試行中ですが、例えばこちらなどで、こんなコードにしています。
// Interface
localparam DEC_GPIO = 0;
localparam DEC_FMTR = 1;
localparam DEC_RGB = 2;
localparam DEC_WDMA = 3;
localparam DEC_NUM = 4;
jelly3_axi4l_if
#(
.ADDR_BITS (AXI4L_PERI_ADDR_BITS),
.DATA_BITS (AXI4L_PERI_DATA_BITS)
)
axi4l_dec [DEC_NUM]
(
.aresetn (axi4l_peri_aresetn ),
.aclk (axi4l_peri_aclk ),
.aclken (1'b1 )
);
// address map
assign {axi4l_dec[DEC_GPIO].addr_base, axi4l_dec[DEC_GPIO].addr_high} = {40'ha000_0000, 40'ha000_ffff};
assign {axi4l_dec[DEC_FMTR].addr_base, axi4l_dec[DEC_FMTR].addr_high} = {40'ha010_0000, 40'ha010_ffff};
assign {axi4l_dec[DEC_RGB ].addr_base, axi4l_dec[DEC_RGB ].addr_high} = {40'ha012_0000, 40'ha012_ffff};
assign {axi4l_dec[DEC_WDMA].addr_base, axi4l_dec[DEC_WDMA].addr_high} = {40'ha021_0000, 40'ha021_ffff};
// Decoder
jelly3_axi4l_addr_decoder
#(
.NUM (DEC_NUM ),
.DEC_ADDR_BITS (28 )
)
u_axi4l_addr_decoder
(
.s_axi4l (axi4l_peri ),
.m_axi4l (axi4l_dec )
);
いろいろツッコミどころはあろうかとは思いますが、Interface 内にアドレス範囲を示す信号を入れ込んでしまって、アドレスデコーダの中で判定するようにしてしまったわけです。
WISHBONE のように assign だけで完結させずに、アドレスデコーダを別モジュールにしたので、内部で FF を打つことが出来るようになり、速度を上げやすくなり、かつ、数の多い信号線は Interface の配列 に押し込んだわけです。
CPU 側のプログラム
ここで、MMIO を使う時点で、ポインタを使える言語で開発する必要があります。筆者の使える範囲では、アセンブラと、C/C++言語と、Rust がこれに該当しますが、ひとまず C++ と Rust で、Linux 上、および、ベアメタルで同じコードが動けばよい、と考えます。
UIO や u-dma-buf を楽に扱いたい
UIO や u-dma-buf を使うには、
- 自分が使いたい該当するデバイスファイルを探し出す
- open する
- mmap する
- 使い終わったらクローズする
という手順が必要です。一方で、mmap してしまえばあとは、ベアメタルとさして変わらない。ということになります。
そこで、基本的なアクセスメソッドを、基底クラスや、クレートとして準備しておけば、Linux でも ベアメタルでも同じコードが走る構成が作れます。
基本アクセスの抽象化
C++ 版だとこのあたりに
void WriteMem (MemAddrType addr, DataType data) { WriteMem_<DataType> (addr, data); }
void WriteMem64 (MemAddrType addr, std::uint64_t data) { WriteMem_<std::uint64_t>(addr, data); }
void WriteMem32 (MemAddrType addr, std::uint32_t data) { WriteMem_<std::uint32_t>(addr, data); }
void WriteMem16 (MemAddrType addr, std::uint16_t data) { WriteMem_<std::uint16_t>(addr, data); }
void WriteMem8 (MemAddrType addr, std::uint8_t data) { WriteMem_<std::uint8_t> (addr, data); }
void WriteMemS64(MemAddrType addr, std::int64_t data) { WriteMem_<std::int64_t> (addr, data); }
void WriteMemS32(MemAddrType addr, std::int32_t data) { WriteMem_<std::int32_t> (addr, data); }
void WriteMemS16(MemAddrType addr, std::int16_t data) { WriteMem_<std::int16_t> (addr, data); }
void WriteMemS8 (MemAddrType addr, std::int8_t data) { WriteMem_<std::int8_t> (addr, data); }
DataType ReadMem (MemAddrType addr) { return ReadMem_<DataType> (addr); }
std::uint64_t ReadMem64 (MemAddrType addr) { return ReadMem_<std::uint64_t>(addr); }
std::uint32_t ReadMem32 (MemAddrType addr) { return ReadMem_<std::uint32_t>(addr); }
std::uint16_t ReadMem16 (MemAddrType addr) { return ReadMem_<std::uint16_t>(addr); }
std::uint8_t ReadMem8 (MemAddrType addr) { return ReadMem_<std::uint8_t> (addr); }
std::int64_t ReadMemS64(MemAddrType addr) { return ReadMem_<std::int64_t> (addr); }
std::int32_t ReadMemS32(MemAddrType addr) { return ReadMem_<std::int32_t> (addr); }
std::int16_t ReadMemS16(MemAddrType addr) { return ReadMem_<std::int16_t> (addr); }
std::int8_t ReadMemS8 (MemAddrType addr) { return ReadMem_<std::int8_t> (addr); }
void WriteReg (MemAddrType reg, DataType data) { WriteReg_<DataType> (reg, data); }
void WriteReg64 (MemAddrType reg, std::uint64_t data) { WriteReg_<std::uint64_t>(reg, data); }
void WriteReg32 (MemAddrType reg, std::uint32_t data) { WriteReg_<std::uint32_t>(reg, data); }
void WriteReg16 (MemAddrType reg, std::uint16_t data) { WriteReg_<std::uint16_t>(reg, data); }
void WriteReg8 (MemAddrType reg, std::uint8_t data) { WriteReg_<std::uint8_t> (reg, data); }
void WriteRegS64(MemAddrType reg, std::int64_t data) { WriteReg_<std::int64_t> (reg, data); }
void WriteRegS32(MemAddrType reg, std::int32_t data) { WriteReg_<std::int32_t> (reg, data); }
void WriteRegS16(MemAddrType reg, std::int16_t data) { WriteReg_<std::int16_t> (reg, data); }
void WriteRegS8 (MemAddrType reg, std::int8_t data) { WriteReg_<std::int8_t> (reg, data); }
DataType ReadReg (MemAddrType reg) { return ReadReg_<DataType> (reg); }
std::uint64_t ReadReg64 (MemAddrType reg) { return ReadReg_<std::uint64_t>(reg); }
std::uint32_t ReadReg32 (MemAddrType reg) { return ReadReg_<std::uint32_t>(reg); }
std::uint16_t ReadReg16 (MemAddrType reg) { return ReadReg_<std::uint16_t>(reg); }
std::uint8_t ReadReg8 (MemAddrType reg) { return ReadReg_<std::uint8_t> (reg); }
std::int64_t ReadRegS64(MemAddrType reg) { return ReadReg_<std::int64_t> (reg); }
std::int32_t ReadRegS32(MemAddrType reg) { return ReadReg_<std::int32_t> (reg); }
std::int16_t ReadRegS16(MemAddrType reg) { return ReadReg_<std::int16_t> (reg); }
std::int8_t ReadRegS8 (MemAddrType reg) { return ReadReg_<std::int8_t> (reg); }
Rust 版だと このあたり に該当するものがいます。
pub trait MemAccess {
fn addr(&self) -> usize;
fn size(&self) -> usize;
fn phys_addr(&self) -> usize;
unsafe fn copy_to_usize(&self, src_adr: usize, dst_ptr: *mut usize, count: usize);
unsafe fn copy_to_u8(&self, src_adr: usize, dst_ptr: *mut u8, count: usize);
unsafe fn copy_to_u16(&self, src_adr: usize, dst_ptr: *mut u16, count: usize);
unsafe fn copy_to_u32(&self, src_adr: usize, dst_ptr: *mut u32, count: usize);
unsafe fn copy_to_u64(&self, src_adr: usize, dst_ptr: *mut u64, count: usize);
unsafe fn copy_to_isize(&self, src_adr: usize, dst_ptr: *mut isize, count: usize);
unsafe fn copy_to_i8(&self, src_adr: usize, dst_ptr: *mut i8, count: usize);
unsafe fn copy_to_i16(&self, src_adr: usize, dst_ptr: *mut i16, count: usize);
unsafe fn copy_to_i32(&self, src_adr: usize, dst_ptr: *mut i32, count: usize);
unsafe fn copy_to_i64(&self, src_adr: usize, dst_ptr: *mut i64, count: usize);
unsafe fn copy_to_f32(&self, src_adr: usize, dst_ptr: *mut f32, count: usize);
unsafe fn copy_to_f64(&self, src_adr: usize, dst_ptr: *mut f64, count: usize);
unsafe fn copy_from_usize(&self, src_ptr: *const usize, dst_adr: usize, count: usize);
unsafe fn copy_from_u8(&self, src_ptr: *const u8, dst_adr: usize, count: usize);
unsafe fn copy_from_u16(&self, src_ptr: *const u16, dst_adr: usize, count: usize);
unsafe fn copy_from_u32(&self, src_ptr: *const u32, dst_adr: usize, count: usize);
unsafe fn copy_from_u64(&self, src_ptr: *const u64, dst_adr: usize, count: usize);
unsafe fn copy_from_isize(&self, src_ptr: *const isize, dst_adr: usize, count: usize);
unsafe fn copy_from_i8(&self, src_ptr: *const i8, dst_adr: usize, count: usize);
unsafe fn copy_from_i16(&self, src_ptr: *const i16, dst_adr: usize, count: usize);
unsafe fn copy_from_i32(&self, src_ptr: *const i32, dst_adr: usize, count: usize);
unsafe fn copy_from_i64(&self, src_ptr: *const i64, dst_adr: usize, count: usize);
unsafe fn copy_from_f32(&self, src_ptr: *const f32, dst_adr: usize, count: usize);
unsafe fn copy_from_f64(&self, src_ptr: *const f64, dst_adr: usize, count: usize);
unsafe fn write_mem(&self, offset: usize, data: usize);
unsafe fn write_mem_usize(&self, offset: usize, data: usize);
unsafe fn write_mem_u8(&self, offset: usize, data: u8);
unsafe fn write_mem_u16(&self, offset: usize, data: u16);
unsafe fn write_mem_u32(&self, offset: usize, data: u32);
unsafe fn write_mem_u64(&self, offset: usize, data: u64);
unsafe fn write_mem_isize(&self, offset: usize, data: isize);
unsafe fn write_mem_i8(&self, offset: usize, data: i8);
unsafe fn write_mem_i16(&self, offset: usize, data: i16);
unsafe fn write_mem_i32(&self, offset: usize, data: i32);
unsafe fn write_mem_i64(&self, offset: usize, data: i64);
unsafe fn write_mem_f32(&self, offset: usize, data: f32);
unsafe fn write_mem_f64(&self, offset: usize, data: f64);
unsafe fn read_mem(&self, offset: usize) -> usize;
unsafe fn read_mem_usize(&self, offset: usize) -> usize;
unsafe fn read_mem_u8(&self, offset: usize) -> u8;
unsafe fn read_mem_u16(&self, offset: usize) -> u16;
unsafe fn read_mem_u32(&self, offset: usize) -> u32;
unsafe fn read_mem_u64(&self, offset: usize) -> u64;
unsafe fn read_mem_isize(&self, offset: usize) -> isize;
unsafe fn read_mem_i8(&self, offset: usize) -> i8;
unsafe fn read_mem_i16(&self, offset: usize) -> i16;
unsafe fn read_mem_i32(&self, offset: usize) -> i32;
unsafe fn read_mem_i64(&self, offset: usize) -> i64;
unsafe fn read_mem_f32(&self, offset: usize) -> f32;
unsafe fn read_mem_f64(&self, offset: usize) -> f64;
unsafe fn write_reg(&self, reg: usize, data: usize);
unsafe fn write_reg_usize(&self, reg: usize, data: usize);
unsafe fn write_reg_u8(&self, reg: usize, data: u8);
unsafe fn write_reg_u16(&self, reg: usize, data: u16);
unsafe fn write_reg_u32(&self, reg: usize, data: u32);
unsafe fn write_reg_u64(&self, reg: usize, data: u64);
unsafe fn write_reg_isize(&self, reg: usize, data: isize);
unsafe fn write_reg_i8(&self, reg: usize, data: i8);
unsafe fn write_reg_i16(&self, reg: usize, data: i16);
unsafe fn write_reg_i32(&self, reg: usize, data: i32);
unsafe fn write_reg_i64(&self, reg: usize, data: i64);
unsafe fn write_reg_f32(&self, reg: usize, data: f32);
unsafe fn write_reg_f64(&self, reg: usize, data: f64);
unsafe fn read_reg(&self, reg: usize) -> usize;
unsafe fn read_reg_usize(&self, reg: usize) -> usize;
unsafe fn read_reg_u8(&self, reg: usize) -> u8;
unsafe fn read_reg_u16(&self, reg: usize) -> u16;
unsafe fn read_reg_u32(&self, reg: usize) -> u32;
unsafe fn read_reg_u64(&self, reg: usize) -> u64;
unsafe fn read_reg_isize(&self, reg: usize) -> isize;
unsafe fn read_reg_i8(&self, reg: usize) -> i8;
unsafe fn read_reg_i16(&self, reg: usize) -> i16;
unsafe fn read_reg_i32(&self, reg: usize) -> i32;
unsafe fn read_reg_i64(&self, reg: usize) -> i64;
unsafe fn read_reg_f32(&self, reg: usize) -> f32;
unsafe fn read_reg_f64(&self, reg: usize) -> f64;
いずれも、一通りのサイズに対するアクセスを Mem 版 と Reg 版で作っているのがポイントで、Reg 版に関しては、先に述べた、バス幅によるアドレッシングの単位の変更に対応しています。
そしてこれは基本的に静的に解決されるので基本的にはロスなく実装されるはずです。
階層的アドレスデコード
ちなみにベースアドレスから相対的にアクセスする機能も備えています。UIO などを使う場合、ペリフェラルモジュールの数だけ open したりしたくないので、ペリフェラル空間全体を mmap した一つのオブジェクトを切り分けて使いたいです。
C++版の例をこちらから引用すると、
// mmap uio
jelly::UioAccessor uio_acc("uio_pl_peri", 0x08000000);
if ( !uio_acc.IsMapped() ) {
std::cout << "uio_pl_peri mmap error" << std::endl;
return 1;
}
// アドレス振り分け
auto reg_sys = uio_acc.GetAccessor(0x00000000);
auto reg_fmtr = uio_acc.GetAccessor(0x00100000);
auto reg_rgb = uio_acc.GetAccessor(0x00120000);
auto reg_sel = uio_acc.GetAccessor(0x00130000);
auto reg_wdma = uio_acc.GetAccessor(0x00210000);
// RGBの中をさらに振り分け
auto reg_demos = reg_rgb.GetAccessor(0x00000000);
auto reg_colmat = reg_rgb.GetAccessor(0x00000800);
// カメラ電源ON
reg_sys.WriteReg(2, 1);
// video input start
reg_fmtr.WriteReg(REG_VIDEO_FMTREG_CTL_FRM_TIMER_EN, 1);
reg_fmtr.WriteReg(REG_VIDEO_FMTREG_CTL_FRM_TIMEOUT, 10000000);
reg_fmtr.WriteReg(REG_VIDEO_FMTREG_PARAM_WIDTH, width);
reg_fmtr.WriteReg(REG_VIDEO_FMTREG_PARAM_HEIGHT, height);
reg_fmtr.WriteReg(REG_VIDEO_FMTREG_PARAM_FILL, 0x100);
reg_fmtr.WriteReg(REG_VIDEO_FMTREG_PARAM_TIMEOUT, 100000);
reg_fmtr.WriteReg(REG_VIDEO_FMTREG_CTL_CONTROL, 0x03);
のように、一つの UIO オープンから、複数のコアのアドレスを相対的に振り分けていって、相対レジスタ番号でアクセスできるようにしています。
コピーコンストラクタなども用意しているので、コピーしたり、別関数に引数で渡すことも出来ます。
また振り分けで作られたオブジェクトが全て消えると自動で close されます。
Rust 版は、例えばこちらなどから引用すると
// UIO
println!("\nuio open");
let uio_acc = UioAccessor::<usize>::new_with_name("uio_pl_peri").expect("Failed to open uio");
println!("uio_pl_peri phys addr : 0x{:x}", uio_acc.phys_addr());
println!("uio_pl_peri size : 0x{:x}", uio_acc.size());
// アドレス振り分け
let reg_gid = uio_acc.subclone(0x00000000, 0x400);
let reg_fmtr = uio_acc.subclone(0x00100000, 0x400);
let reg_rgb = uio_acc.subclone(0x00120000, 0x10000);
let reg_wdma = uio_acc.subclone(0x00210000, 0x400);
// RGBをさらに振り分け
let reg_fmtr = reg_rgb.subclone(0x00000000, 0x400);
let reg_demos = reg_rgb.subclone(0x00000800, 0x400);
基本的に C++ 版同様にさらに subclone を繰り返す事も可能です。
また、subclone32 のようなメソッドも用意しており、64bit バスを 32bit にバス幅変更するブリッジが途中にあっても対応可能です。
何も指定しない場合は、コンパイル環境のポインタサイズがデフォルトのバス幅となります。
キャッシュへの対応
ikwzm 氏の uiomem や u-dma-buf にはキャッシュを操作する機能もあります。
実験的ですが、下記のようなキャッシュ制御の機能も検討中です。
pub trait MemAccessSync {
unsafe fn sync_owner(&self) -> u32;
unsafe fn sync_for_cpu(&self);
unsafe fn sync_for_cpu_with_range(
&self,
sync_offset: usize,
sync_size: usize,
sync_direction: u32,
sync_for_cpu: u32,
);
unsafe fn sync_for_device(&self);
unsafe fn sync_for_device_with_range(
&self,
sync_offset: usize,
sync_size: usize,
sync_direction: u32,
sync_for_device: u32,
);
}
おわりに
今回説明してきた内容は、あくまでラピッドプロトタイピングや、実機でモジュールテストを行う事を目的に簡易的なアクセスを提供するものです。
なので大雑把な部分は多いのですが
- 毎回 UIO をオープンして mmap するのも面倒
- ZynqMP で 64bit の APU と 32bit の RPU でコードを使いまわしたい
などの点で、ちょっとだけ楽するという目的は概ね果たせてきました。
筆者の Jelly などのサンプルプログラムの中で、度々多用している割にちゃんとした説明が用意出来ていなかった箇所なので、今回を機に少し解説記事っぽいものを書いてみました。
FPGAでラピッドプロトタイピングしたいという、誰かの参考になれば幸いです。
Discussion