KV260 で PS から PL へのシングルアクセス速度を測ってみる
はじめに
以前、Ultra96V2(ZynqMP) のPS⇔PL間性能計測という記事を書きました。
この時は特に RPU を意識しつつ PS <-> PL のメモリ帯域を測りましたが、今回はレジスタの読み書きなどのシングルアクセスの速度(というかレイテンシ)が気になったので、少し測ってみました。
やったこと
下記のように、FPD0, FPD1, LPD0 の 3つの PS からのアクセスポートを 32bit 幅で BRAM を接続し 333MHz のバスクロックとして構成しつつ、アクセスを覗くための ILA を埋め込んだプロジェクトを作りました。
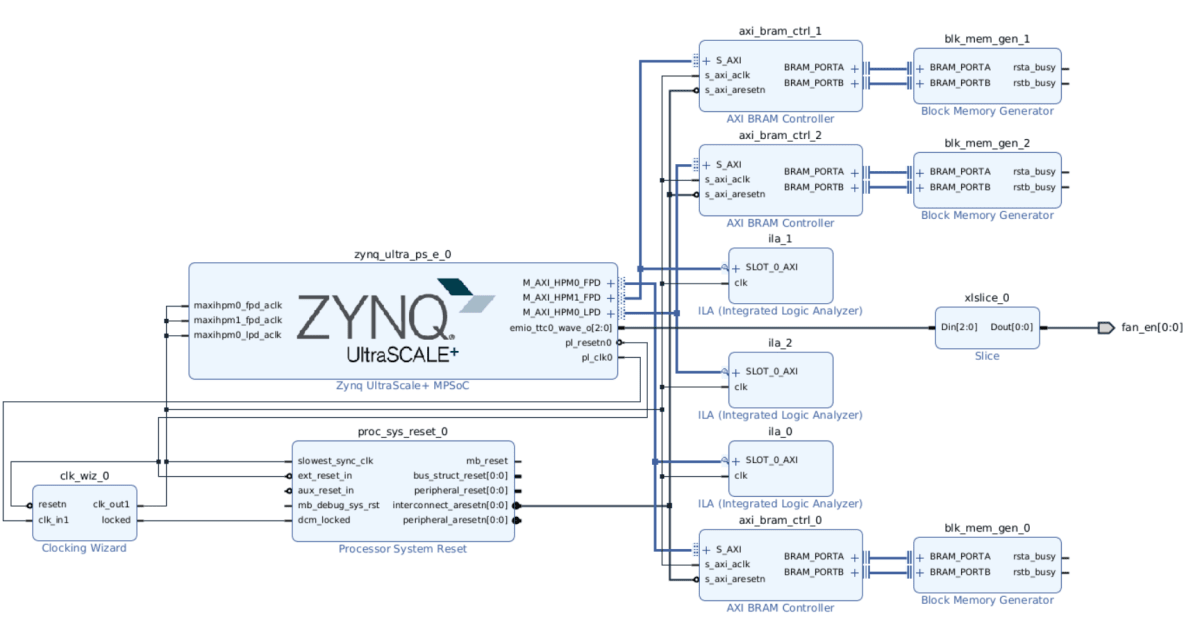
ここから、APU、RPU それぞれから、read のみ、write のみ、read/writw の3パターンでアクセスを繰り返し、ILAで覗いて周期を測ってみました。
RPU の MPU 設定はキャッシュ無しとし、APU は単に uio で開いて mmmap したのみの状態です。
アクセス周期計測
先に結果を結果を張っておくと下記のようになりました。
FPD0 と FPD1 は特に差が無かったようなので纏めています。
結構適当な条件で適当に測っているので、信憑性は話半分に大雑把に傾向が掴めればと思います。
| CPU | I/F | access | cycle | commands | word/sec | average latency |
|---|---|---|---|---|---|---|
| RPU | FPD | READ | 47 | 1 | 7.1M | 141 ns |
| RPU | FPD | WRITE | 43 | 3 | 23.3M | 43 ns |
| RPU | FPD | R/W | 94 | 2 | 7.1M | 141 ns |
| RPU | LPD | READ | 28 | 1 | 11.9M | 84 ns |
| RPU | LPD | WRITE | 24 | 3 | 41.7M | 24 ns |
| RPU | LPD | R/W | 56 | 2 | 11.9M | 84 ns |
| APU | FPD | WRITE | 55 | 4 | 24.2M | 41 ns |
| APU | FPD | READ | 32 | 1 | 10.4M | 96 ns |
| APU | FPD | R/W | 63 | 1 | 5.3M | 189 ns |
| APU | LPD | WRITE | 30 | 8 | 88.9M | 11 ns |
| APU | LPD | READ | 48 | 1 | 6.9M | 144 ns |
| APU | LPD | R/W | 95 | 2 | 7.0M | 143 ns |
ライトバッファなどと思われる挙動で綺麗な周期にならなかったものは、周期が現れる cycle で その間に発行されたコマンド数で数えています。
リファレンスマニュアルを見ればわかるが、RPU(Cortex-R5)は LPD 側にあり、APU(Cortex-A53)は FPD側にあるので、当然アクセスレイテンシも概ねそうなっているのですが、唯一 APU からの WRITE だけそうなっていない。ライトバッファなどが有効に機能しているのかもしれない。
詳細
RPU からの Read の場合
基本的にこんな感じで間欠にアクセスが発生しています。CPU のメモリ機構や PL の間のインターコネクトでそれなりの距離があるのでしょう。

RPU からの Write の場合
Write の場合はある程度バッファされるのか、3つずつのアクセスが繰り返されていました。

APU からの write
APU側は ライトバッファなどがリッチなのか、8つずつのアクセスが繰り返されていました。

APU から LPD への Read/Write
なぜか初回の READ 後だけ時間がかかり、その後はそれなりに速くなっていました。
計測は先頭を除外して安定した区間で行いましたが、謎です。

おわりに
以前作った FPGA 版 RTOS などの性能限界を見積もろうと思って、軽い気持ちで始めたのですが、ARM などのコアのバスアクセスが覗けるというのはなかなか楽しいことに気が付きました。
今回分かったこととして ZynqMP は PS と PL がワンチップに収まており、その間の接続が強力であることは特徴の一つなのですが、簡素なシングルアクセスを多用すると、プログラミングは楽なのですがそれなりにバスアクセス待ちのCPUストールが発生していそうなことが見えてきました。
簡単な制御レジスタ程度なら殆ど問題になりませんが、大量のデータを渡したりするときはDMAで別途OCMに送るなり、バースト転送できるようなアクセスパターンにするなり工夫が必要そうです。
また、制御レジスタをポーリング待ちするようなことも良くやりますが、やはりちゃんと割り込みを使うのが効率的にも思いました。
ここが問題になることはめったにないとは思いますが、感覚をつかんでおくのは大事ですね。
Discussion