kaggleコミュニティコンペ開催報告と上位解法
この記事は何?
Kaggle Competitions MasterのRyushiです!
2025/5/10に同じくKaggle Masterのyukiさんとコンペを主催しましたので、そのまとめ記事です。
コンペ概要
1. コンペ内容
与えられた写真がどの国で撮影されたかを分類するコンペを開催しました。
分類対象の国は以下の5つです。
- 日本
- アメリカ
- イギリス
- ブラジル
- オーストラリア
2. データセット
CSVファイル
-
train.csv / test.csv
画像と紐づくID、撮影月、正解ラベルが含まれています。
train.csvのみ、写真が撮影された緯度経度の情報も提供されています。 -
country_map.csv
国ラベルと国名のマッピングデータです。
画像
-
各国で撮影された写真データを提供しています。
-
画像には回転または反転したものがあります。
-
一つの地点で方角を変えて最大4枚まで写真が提供されています。
方角はファイル名から判断可能です。
solution
上位ソリューション概要
- シンプルな画像認識タスクであったものの、1位、2位、4位は生成AIを活用したソリューションであり、3位と5位は従来の画像認識モデルを用いたアプローチでした。
- 時代の流れを反映した、多様な手法が並ぶ結果となりました。
なお、最終的な上位Leaderboardは以下のようになりました
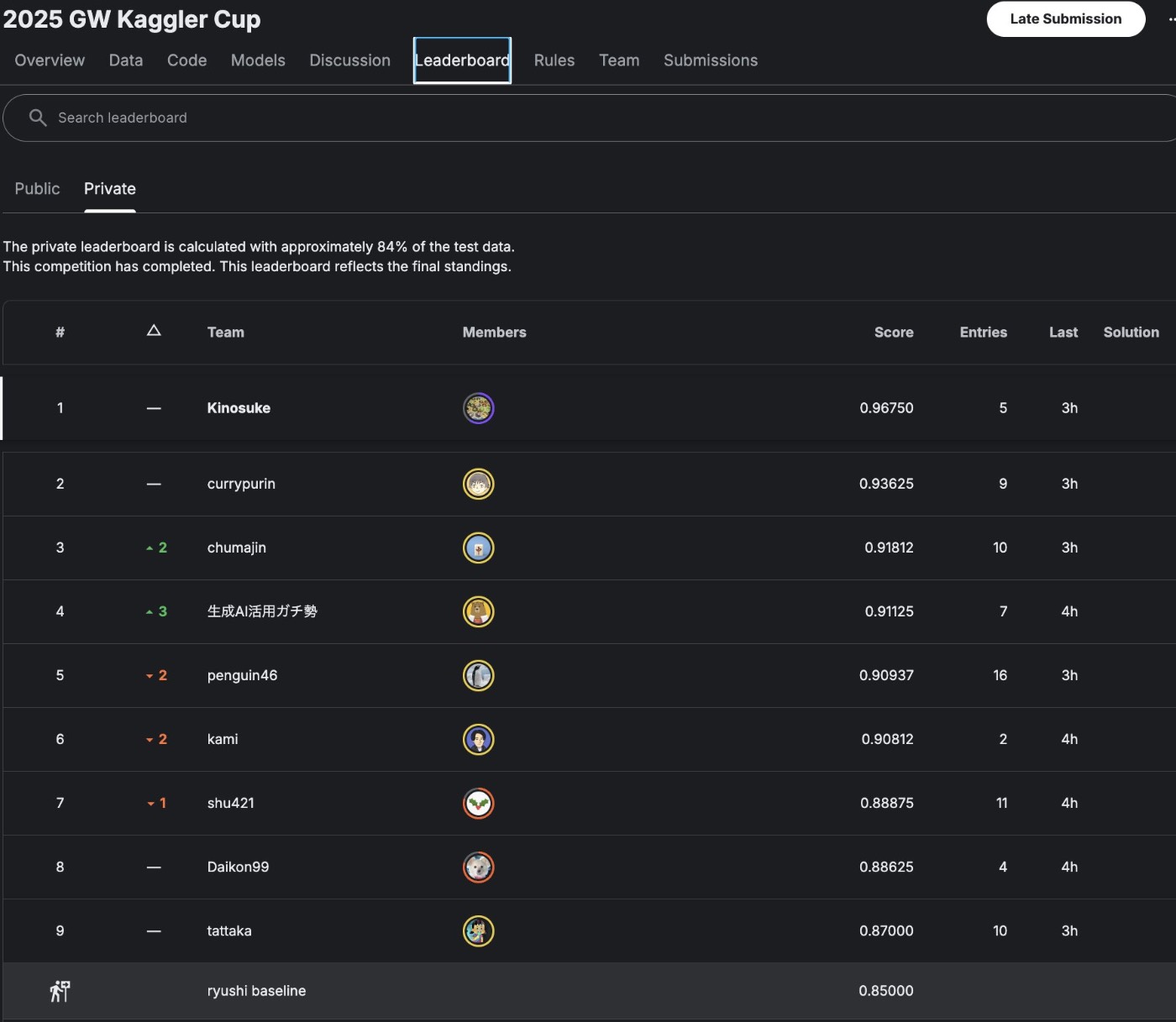
それでは、1~5位のソリューションを紹介したいと思います。
1st place: Kinosuke
使用データ
- 同じ ID に紐づく4方向画像 (_0 / _90 / _180 / _270) をすべて使用(不足分は存在する分だけ利用)
学習設定(HuggingfaceのTrainer使用)
- epochs: 8
- batch size: 32
- 学習率 (lr): 5e-3
- 混合精度(fp16)を利用
- モデルの保存および評価は各 epoch ごとに実施
CV戦略
- 時間不足のためクロスバリデーション(CV)は実施せず
- Public Leaderboard (LB) を全振りで評価
推論方法
- 画像単位で logits を算出
- 同一 ID 内の画像 logits を平均化
- その平均値の中で最大値のクラスを最終予測とする
追加情報:SigLIPモデルについて
- 使用モデル:
SigLIP (google/siglip-so400m-patch14-384)
※当初SigLIP2を使っているつもりでしたが、実際はSigLIPを利用していました🙇♂️
SigLIP2のほうが性能は高い可能性があります。
SigLIP2についての詳細はこちら → SigLIP2紹介記事
提出結果
| 実験名 | Public LBスコア | Private LBスコア |
|---|---|---|
| SigLIP (全画像使用) | 0.96750 | 0.97000 |
| SigLIP(角度0のみ) | 0.93187 | 0.92000 |
| ConvNeXt-Base | 0.76812 | 0.74333 |
なぜSigLIPを選択したか?
- 道路やランドマークといった画像の特徴をとらえるのに強力な大規模・汎用の視覚言語モデルであること
- マルチモーダル学習済みであるため、位置・文化・言語などの手掛かりを暗黙的に学習していると考えたため
実装の工夫
- SigLIP2はモデルサイズが大きく、ローカル環境でのフルファインチューニングは難しいが、
ImageEncoder部分のみを使用し、線形ヘッド以外凍結することで、Colab環境でも学習可能にした - ColabのGPU (T4) で、全角度の画像を使い8エポック学習させても約8分程度で完了
2nd place: currypurin
"geolocal/StreetCLIP"を用いたゼロショット予測のアプローチです。
- 回転画像を使ったり、ラベルごとに重み付けを変えたりと様々な工夫を試みましたが、結果が安定せず、最終的には単純にID毎に複数枚の画像を推論し、その予測値を単純平均して最終予測としました。
StreetCLIP にたどり着くまで
Kaggle上で動き、写真に写っているものを表現できる高性能モデルを探していたところ、
-
最初のプロンプト例:
「Kaggle上で動くもので、写真に写っているものを表現できるもので性能が高いのって何がある?」このpromptではあまり良い回答が得られませんでした。
-
改良したプロンプト例:
「重くても良いので、この画像は、日本、アメリカ、オーストラリアのどこで撮影されたものだと思う? というコードを動かせるモデルを教えて」
この質問を通じて、o3(AIアシスタント)が "geolocal/StreetCLIP" を1番に推薦し、実際に試したところPublic LBで0.96のスコアを獲得できました。
3rd Place: chumajin
-
モデル
convnext_xlarge_384_in22ft1k -
画像サイズ
384 × 384 -
学習バッチサイズ
8 -
学習データ
全角度方向の画像を使用 -
検証・推論
- groupby(IDごと)での平均(mean)を取得
- その後 argmax で最終クラスを決定
-
クロスバリデーション
- country ラベルによる Stratified K-Fold
- 時間不足のため 1 fold のみで提出
-
エポック数
計 10 エポック予定だったが、時間不足により 8 エポックで終了して提出 -
データ拡張 (Augmentation)
aug = { "train": A.Compose([ A.Resize(cfg.imsize, cfg.imsize), A.HorizontalFlip(p=0.5), A.VerticalFlip(p=0.5), A.Transpose(p=0.5), A.Normalize( mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225), max_pixel_value=255.0, ), ToTensorV2() ], p=1.), "valid": A.Compose([ A.Resize(cfg.imsize, cfg.imsize), A.Normalize( mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225), max_pixel_value=255.0, ), ToTensorV2() ], p=1.) }
学習設定および結果
-
Optimizer
Adam -
Scheduler
cosine_schedule_with_warmup -
最終クロスバリデーションスコア (CV)
0.942
その他 実験履歴・気づき
- 1 fold と 5 fold の両方を試したが、CVスコアもLBスコアも大差なく、1 foldで十分と判断した
- 大きいモデルほどスコアが良い傾向
- 例:
swin_tiny_patch4_window7_224のスコアは0.818で、ConvNeXt_xlargeの0.942と比較し明らかに劣るため、大きなモデルが有利と判断
- 例:
- Normalize処理の入れ忘れにより、最初はスコアが全く伸びず苦戦した
- 補助損失として月・緯度・経度を試したが、スコア向上には繋がらなかった
- TTA (Test Time Augmentation) をやりたかったが時間が足りなかった
- Augmentationにrotation処理が含まれていないことに気づいたが、Flipだけでも十分効果があった
- RTX 5090を購入して使用。学習速度が非常に速く快適であり、今回のチャレンジには不可欠だった
4th Place:生成AI活用ガチ勢(RabotniKuma)
-
モデル
大規模マルチモーダル言語モデルQwen/Qwen2.5-VL-72B-Instruct-AWQを使用 -
タスク設計
画像群と撮影月(month)を入力として、「この写真はどの国で撮影されたか?」をモデルに質問形式で解かせる -
プロンプト設計
- システムメッセージでモデルに役割を定義
default_system = ( "You are Qwen, a virtual human developed by the Qwen Team, Alibaba. " "You are a helpful assistant.") - ユーザーメッセージで複数枚画像を順に埋め込み、月情報をテキストとして組み込んだ質問を与える
- 対象の選択肢として
「Japan, United States of America, United Kingdom, Brazil, Australia」
の中から回答するよう誘導
prompt_template = ( "What country were these photos taken in ? Note that the photos are taken in {month}." "Choice: Japan, United States of America, United Kingdom, Brazil, Australia. " "Answer the country name only.")
- システムメッセージでモデルに役割を定義
-
データ処理
- 各IDごとに複数画像をまとめて読み込み
- 月情報(1~12)を英語表記(January ~ December)に変換してプロンプトに含める
-
モデル推論
- GPUを活用し、チャット形式で画像とテキストを同時に入力
- 最大4枚の画像を1つのプロンプトに組み込み、連続的に全テストデータに対して生成処理を実施
5th Place: penguin46
-
モデル
convnext_small_384_in22ft1kのシングルモデルを使用 -
データ拡張
0°, 90°, 180°, 270° の回転をかけて回転に対応
さらに回転しながらの TTA (Test Time Augmentation) を実施 -
推論・学習方法
1画像ずつ学習・推論を行い、最後にIDごとにクラスごとの予測値の平均を計算し、最も高いクラスを提出 -
モデルサイズとスコア傾向
tiny < base < largeの順でスコアが良くなった -
その他試み
IDごとに画像をスタックした2.5D入力も試したが、方角を考慮してくれることを期待したものの効果はなかった
コンペ振り返り
難易度調整
コミュニティコンペにしてはかなりレベルが高い(GM:7, Master:10, Expert:8)メンバーだったので4hで完全理解されないように、かつ難しすぎず、その上であんまり揺れても面白くないけど少しは揺れてほしいよね、そしてなにより面白く....など様々な点を考慮して、作成しました。
そもそも、4hで画像認識タスクをやってもらうのはなかなかレベルが高いことだと分かっていましたが、このメンバーならしっかり仮説検証もしてくるだろうという信頼の基設計していました。
また、画像コンペも生成AIで解く時代がやってきたなと、時代の潮流を感じました。
終わったあと、レベル感がちょうどよかったとコメントいただけて良かったです。
コンペ始まるまでドキドキですが、出る側だけじゃなくて作る側も楽しい!!
読んでくださりありがとうございました。
Discussion