1人SREが朝一ダッシュボードチェックをAIに手伝ってもらいたいのでPoCしている話
こんにちは。
ご機嫌いかがでしょうか。
"No human labor is no human error" が大好きな吉井 亮です。
プロダクトの規模が小さいと1人 SRE という体制は珍しくないと思います。
1人で何が辛いかというと、相談相手やレビュー相手がいないことです。ですので、最近は AI/LLM に相手をしてもらっています。
運用に使っている Lambda 関数や Terraform のコードをレビューしてみたり(※1)、エラー発生時の1次対応をお願いしてみたり(※2)しています。
※1 プルリクしたら Bedrock にコードレビューしてもらいたい
※2 AIOps入門 AWS Bedrock で障害分析
私は毎朝のタスクとして、ダッシュボードチェックを行っています。
平日なら前日分、土日祝日なら2〜3日分のメトリクスを眺めながら、異常な挙動はないか、パフォーマンス劣化が起きていないかなどの確認をしています。
ただ、1人 SRE の朝一ダッシュボードチェックを以下の心配があります。
- 何の問題もなければ地味で単調なタスクなので、気を抜くと兆候を見逃してしまう可能性は排除できない
- 1人だと考察に多様性が無い
- なにより1人だと飽きてしまう
というころで、朝一ダッシュボードチェックも AI/LLM に手伝ってもらうことにしました。PoC を開始します。
構成
システムは AWS 上に構築しています。
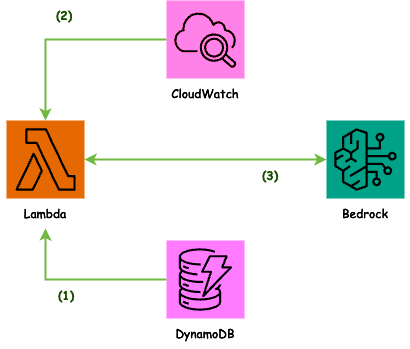
構成図(1)
朝一ダッシュボードの相談をしたい場合は、Lambda 関数を呼び出します。
Lambda 関数ではまず DynamoDB からパラメータを取得します。次のステップで CloudWatch の GetMetricData API を呼び出しているのですが、これに与えるパラメータを格納しています。
例えば、ALB Target Response Time メトリクスなら以下のようなアイテムを DynamoDB に格納しています。CloudWatch メトリクスの画面やユーザーガイドを見ながらパラメータを決めます。
クリックして展開
{
"awsService": {
"S": "ALB_TARGET"
},
"dateRange": {
"S": "7"
},
"namespace": {
"S": "AWS/ApplicationELB"
},
"metricName": {
"S": "TargetResponseTime"
},
"dimensionsName": {
"S": "LoadBalancer"
},
"dimensionsValue": {
"S": "your-load-balancer"
},
"period": {
"S": "300"
},
"stat": {
"S": "p90"
},
"unit": {
"S": "Seconds"
}
}
構成図(2)
CloudWatch からメトリクスを取得しています。ここはオブザーバビリティ系 SaaS、Prometheus、Grafana ファミリーなどメトリクスデータソースは問いません。
例として、以下のメトリクスを取得します。プロダクトによってダッシュボードの構成は違うと思います。ここは SRE の腕の見せどころですね。
- ALB リクエスト数
- ALB ターゲットレスポンスタイム
- Aurora DML レイテンシー
- Aurora Select レイテンシー
- ECS CPU 使用率
ここで取得したメトリクスを次のステップで AI/LLM に投げます。ただ、GetMetricData API のレスポンスをそのまま投げてもノイズになるだけなので、タイムスタンプと値だけを取り出し、JSON に整形しています。
構成図(3)
Amazon Bedrock Converse API を呼び出します。
Converse はどのモデルを利用するにしても一貫したインターフェイスを提供しているということで、モデル変更が柔軟になるだろうという期待で採用しています。
API で指定しているシステムは以下です。役割を決めてあげると精度が上がるようです。
You are a Senior SRE Engineer working in a team developing a smartphone application.
One of your tasks is to detect and prevent application performance degradation and failures.
You are required to correlate various metric data with timestamps and find correlations between them, and report back to us in terms of the following
Increased number of ALB requests is expected to impact response and latency. Please detect changes in response time and latency per request count and tell us if you determine that the increase in requests has caused a sudden performance degradation.
# Perspective
- See [Explanation of Metrics Data](#explanation-of-metrics-data) for the meaning of metrics data
- ALB target response time, less than 0.5 seconds is considered normal
- Aurora DML Latency, less than 1.5 milliseconds is considered normal
- Aurora Select latency, less than 0.4 milliseconds is considered normal
- Detecting performance degradation and its signs
- Reports a pattern of slowly worsening metrics
- Detects the occurrence or suspicion of a failure
- Reports a metric pattern of sudden fluctuations in metric data
- Report a metric pattern where metric data is suddenly missing
- Report any extreme up/down fluctuations in metrics data during a period of time
- Ignore if it fluctuates by 10%% in an hour
- Metrics data include data from the past few days, but the primary data to investigate are those within 24 hours of the present
- Use data from the past few days as a performance baseline
# Explanation of Metrics Data
The types of metrics data to be obtained and their descriptions are shown below.
## ALB Requests
Number of requests processed via IPv4 and IPv6. This metric is only incremented for requests for which the load balancer node was able to select a target. Requests that are rejected before a target is selected are not reflected in this metric.
## ALB Target Response Time
The time (in seconds) elapsed after a request leaves the load balancer before the target begins sending response headers.
## Aurora DML Latency
Average time (in milliseconds) for inserts, updates, and deletes against the database cluster.
## Aurora Select Latency
Average time (in milliseconds) for select queries against the database cluster.
## ECS CPU Utilization
Number of CPU units used by the task for the resource specified by the dimension set being used.
## Reporting format
Please report in markdown format. Please summarize the main points using bullet points and provide supporting data.
Report only objective facts based on data; do not include speculation or suggestions for improvement.
If no abnormality is found, please report “no abnormality”.
Please summarize your report in less than 4000 bytes and describe in Japanese.
レスポンス
AI/LLM からのレスポンスは以下のようになりました。(抜粋です)
事実に基づいたレスポンスだと感じました。平常ではない時間帯を発見してくれています。
# 分析報告
## ALBターゲットレスポンスタイムの異常
1. 急激な悪化
- 2025-01-29 15:00頃に0.196秒まで急上昇(基準値0.5秒未満)
- 通常時の約40倍に悪化
- 同時刻のリクエスト数は11件で通常(4件)の約3倍
- その後15:05には0.119秒まで改善2
. 一時的な悪化
- 2025-01-23 22:55頃に0.245秒まで上昇
- 同時刻のリクエスト数は6件で若干増加
- その後すぐに通常値に回復
## ALBリクエスト数の特徴
1. 通常パターン
- 1時間ごとに4件のリクエストが発生する安定したパターン
2. 異常パターン- 2025-01-29 15:00に11件の突発的なリクエスト増加
- 2025-01-23 22:55に6件の小規模な増加
## Aurora DMLレイテンシーの異常1. 急激な悪化
- 2025-01-29 15:00頃に4.089ミリ秒まで上昇(基準値1.5ミリ秒未満)
- ALBレスポンスタイム悪化と同時刻
- その後徐々に通常値に回復
## Aurora Selectレイテンシーの異常
1. 急激な悪化- 2025-01-28 04:35頃に0.804ミリ秒まで上昇(基準値0.4ミリ秒未満)
- その後すぐに通常値に回復## ECS CPU使用率の異常1. 急激な上昇
- 2025-01-24 05:00頃に23.98%まで上昇
- 2025-01-27 05:00頃に13.13%まで上昇
- 2025-01-28 05:00頃に14.46%まで上昇
- 2025-01-29 05:00頃に12.44%まで上昇
- 2025-01-30 05:00頃に31.29%まで上昇
以上の分析から、2025-01-29 15:00頃に発生したリクエスト数増加が、ALBレスポンスタイムとAurora DMLレイテンシーの急激な悪化を引き起こしたことが確認されました。
出力形式の指定、観点を増やしかつ詳細化、入力メトリクスの精査などまだまだ改善できるところはありそうです。
今後の展開
ALB と Aurora のメトリクスを組み合わせただけで PoC を開始しました。様々なメトリクスの組み合わせを試してみたいと考えています。
ログをメトリクス化してこの仕組みで使用するのも面白そうです。
ChatBot のように連続して会話しながらダッシュボードチェックができると記事の冒頭であげたような心配が解決できそうです。
CloudWatch anomaly detection や Amazon Q Developer による運用上の問題の調査と修正 なども取り込むとより問題の早期発見ができそうです。
Lambda 関数のソースコード
PoC で使用している Lambda 関数のソースコードを公開します。
出力結果を見ながらプロンプトは毎日微調整を繰り返しています。
以下のリポジトリをクローンやフォークしてお使いください。
宣伝
私が運営に関わっている OpsJAWS では、AIOps に関する勉強会を開催します。
会場とオンラインのハイブリット開催です。上の話も含めて多くの AIOps に関する話を聞けると思います。お気軽に参加ください。
Discussion