ECS で小さく始める OpenTelemetry 構成
こんにちは。
ご機嫌いかがでしょうか。
"No human labor is no human error" が大好きな吉井 亮です。
なにごとも小さく始めて成功体験を積み上げながら大きくしていくのが良いと思います。
Observability についても同じ考えです。
これから Observability を導入する方の助けになればと思い、ECS で小さく始める OpenTelemetry 構成をご紹介します。
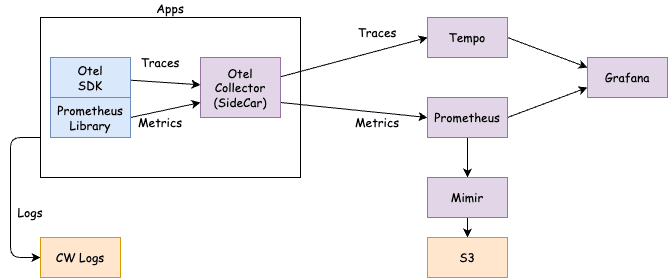
構成
アプリケーションに OpenTelemetry SDK を組み込み、トレースとメトリクスを OpenTelemetry Collector に送信します。
アプリケーションのログは CloudWatch Logs に送信します。
OpenTelemetry Collector はサイドカーを選択肢しました。
OpenTelemetry Collector は Tempo にトレースを送信し、Prometheus にメトリクスを送信します。
Prometheus は Mimir を経由して受信したデータを S3 に保存します。
可視化は Grafana で行います。
全てのコンテナは ECS on Fargate で動作しています。
OpenTelemetry Collector
コンポーネントごとに設定を解説します。
receiver は otlp と prometheus を使用しています。
アプリケーションコンテナに Prometheus Library を計装し、メトリクスエンドポイントを公開しています。そのエンドポイントに対して OpenTelemetry Collector がスクレイピングしてメトリクスを取得しています。
メトリクスやトレースにメタ情報を付与したいので resourcedetection と resource で ECS の情報を取得しています。とはいえ、全ては要らないので選択しています。
exporters には Tempo と Prometheus に送信する設定を記述しています。
クリックして展開
receivers:
otlp:
protocols:
grpc:
endpoint: localhost:4317
prometheus:
config:
scrape_configs:
- job_name: 'prometheus-library'
metrics_path: '/metrics'
scrape_interval: 15s
scrape_timeout: 10s
static_configs:
- targets: ['localhost:8080']
extensions:
health_check: {}
processors:
batch: {}
memory_limiter:
check_interval: 5s
limit_percentage: 80
spike_limit_percentage: 25
resourcedetection:
detectors:
- env
- ecs
resource:
attributes:
- key: net_host_port
action: delete
- key: server_port
action: delete
- key: service_instance_id
action: delete
- key: http_scheme
action: delete
- key: url_scheme
action: delete
- key: cloud.provider
action: delete
- key: cloud.account.id
action: delete
- key: cloud.platform
action: delete
- key: cloud.region
action: delete
- key: cloud.availability_zone
action: delete
- key: aws.ecs.task.arn
action: delete
- key: aws.ecs.task.family
action: delete
- key: TaskDefinitionRevision
from_attribute: aws.ecs.task.revision
action: insert
- key: aws.ecs.task.revision
action: delete
- key: aws.ecs.launchtype
action: delete
- key: aws.ecs.cluster.arn
action: delete
- key: aws.log.group.names
action: delete
- key: aws.log.group.arns
action: delete
- key: aws.log.stream.names
action: delete
- key: aws.log.stream.arns
action: delete
exporters:
debug:
otlp/tempo:
endpoint: tempo.my-local-domain:4317
tls:
insecure: true
prometheusremotewrite:
endpoint: "http://prometheus.my-local-domain:9090/api/v1/write"
resource_to_telemetry_conversion:
enabled: true
service:
extensions:
- health_check
pipelines:
traces:
receivers:
- otlp
processors:
- resourcedetection
- resource
- memory_limiter
- batch
exporters:
- otlp/tempo
- debug
metrics:
receivers:
- otlp
- prometheus
processors:
- resourcedetection
- resource
- memory_limiter
- batch
exporters:
- prometheusremotewrite
- debug
Prometheus
Prometheus は特になにも設定はしていません。Mimir の送信先のみです。
クリックして展開
remote_write:
- url: http://mimir.my-local-domain:8080/api/v1/push
Tempo
Tempo は All In One 型のコンテナイメージを使用しています。システム全体が中規模以上になってくるようならマイクロサービス型の構成を検討するつもりです。
metrics_generator は今回どうしても導入したかった機能です。
トレースからメトリクスを生成する機能です。
overrides で機能を有効化しています。
storage は S3 を使用しています。
compactor で 720 時間以上前のデータを削除する設定をしています。トレースをログやメトリクスを関連付けている場合は期間を合わせて設定します。
クリックして展開
distributor:
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
ingester:
flush_all_on_shutdown: true
server:
http_listen_port: 8080
metrics_generator:
storage:
remote_write:
- url: http://prometheus.my-local-domain:9090/api/v1/write
send_exemplars: true
path: /var/tempo/generator/wal
compactor:
compaction:
block_retention: 720h
storage:
trace:
backend: s3
wal:
path: /var/tempo/wal
s3:
bucket: My_Bucket_Name
endpoint: s3.ap-northeast-1.amazonaws.com
region: ap-northeast-1
overrides:
defaults:
metrics_generator:
processors: ["service-graphs", "span-metrics"]
Mimir
storage は S3 を使用しています。Tempo とはそれぞれ別のバケットを使用しています。
あとはテンプレート通りで、特にこれといった設定はしていません。
クリックして展開
target: all
activity_tracker:
filepath: "/data/metrics-activity.log"
common:
storage:
backend: s3
s3:
bucket_name: My_Bucket_Name
endpoint: s3.ap-northeast-1.amazonaws.com
region: ap-northeast-1
ruler:
rule_path: /data/data-ruler/
ruler_storage:
storage_prefix: ruler
alertmanager:
sharding_ring:
replication_factor: 1
alertmanager_storage:
storage_prefix: alertmanager
blocks_storage:
storage_prefix: blocks
bucket_store:
sync_dir: /data/tsdb-sync/
tsdb:
dir: /data/tsdb/
compactor:
data_dir: /data/data-compactor/
limits:
compactor_blocks_retention_period: 30d
store_gateway:
sharding_ring:
replication_factor: 1
ingester:
ring:
replication_factor: 1
ECS タスク定義
アプリケーションコンテナのタスク定義です。かなり抜粋しています。
OTEL_EXPORTER_OTLP_ENDPOINT は "http://localhost:4317" を指定しています。サイドカーの OpenTelemetry Collector 宛です。
ECS のサイドカーは localhost です。Docker Compose に慣れていると最初は違和感があります。
クリックして展開
"containerDefinitions": [
{
"name": "app",
"image": "my_image",
"portMappings": [
{
"containerPort": 8080,
"hostPort": 8080,
"protocol": "tcp"
}
],
"essential": true,
"environment": [
{
"name": "OTEL_EXPORTER_OTLP_ENDPOINT",
"value": "http://localhost:4317"
},
{
"name": "OTEL_RESOURCE_ATTRIBUTES",
"value": "service.name=app"
},
],
},
{
"name": "otel",
"image": "my_otel_col_image",
"portMappings": [
{
"name": "otel-4317-tcp",
"containerPort": 4317,
"hostPort": 4317,
"protocol": "tcp"
}
],
"essential": true,
"command": [
"--config=/etc/otel-config.yaml"
],
"environment": [
{
"name": "OTEL_RESOURCE_ATTRIBUTES",
"value": "service.name=app"
}
],
}
],
宿題
トレースとログの関連付けができていません。
CloudWatch Logs にコンテナログを保存しているところのツラミが少々ありまして。。。
Loki を追加して Loki にログを送ると個人的には楽になると思っていますが、自分だけがログを見るわけではないのでバランスが必要です。
Discussion