BigQueryではじめる『ビッグデータ分析・活用のためのSQLレシピ』
はじめに
データアナリストや機械学習エンジニアをしている方々の中には、pythonやRは書けるけどSQLには馴染みがない方は多いかと思います。かく言う自分もインターンでするまではSQLに触れたことはありませんでした。
そんな当時SQL初心者であった自分がSQLを勉強した本が『ビッグデータ分析・活用のためのSQLレシピ』でした。データを使用するアナリストや機械学習エンジニアがはじめに手をつけるにはうってつけの本であると思います。
一方で、手を動かしながら『ビッグデータ分析・活用のためのSQLレシピ』を読み進めようとすると初学者にはいくつかのハマりポイントが存在します。例えば、『ビッグデータ分析・活用のためのSQLレシピ』にはクエリを実行するサンプルコードは記載がありますが、どのようにダミーデータをデーブルに保存するかなどは記載がありません。ここで詰まってしまうことで手を動かしながら読み進めることを諦めてしまった人も多いのではないでしょうか?
本記事ではそれらの問題点をBigQueryを用いることで解決し、初学者でも苦労なくSQLの勉強を開始できるようになることを目指します。
想定読者
- SQLを勉強したい
- 『ビッグデータ分析・活用のためのSQLレシピ』を実際に手を動かしながら勉強したい
- 『ビッグデータ分析・活用のためのSQLレシピ』を購入はしたが活用方法がイマイチはっきりしていない
- BigQueryを触ってみたい
『ビッグデータ分析・活用のためのSQLレシピ』について
本記事ではSQLに入門することに主眼を置くため、『ビッグデータ分析・活用のためのSQLレシピ』がどのような本であるかの説明は省略します。
どのような本であるかの詳細を知りたい場合はこちらなどを参照すると良いでしょう。
サポートサイトはこちらになります。サポートサイトからはダミーデータをダウンロードできるため後ほど利用します。
BigQueryではじめる
以下の手順によって手を動かしながら『ビッグデータ分析・活用のためのSQLレシピ』を読める様になることを目指します。
- Googleのアカウントを作成する。(持っていない場合)
- GCP(Google Cloud Platform)のアカウントを作成する。(持っていない場合)
- GCPで新しいプロジェクトを作成する。
- 『ビッグデータ分析・活用のためのSQLレシピ』サポートサイトからダミーデータをダウンロードする。
- ダミーデータをテーブルに保存する。
- 実際にクエリを書いてみる
Googleのアカウントを作成する
Google公式サイトを参考にGoogleアカウントを作成します。
GCP(Google Cloud Platform)のアカウントを作成する
こちらのサイトを参考にGCPアカウントを作成します。
途中クレジットカード情報の入力を求められますが、300ドル分を最大12ヶ月無料で試用できるため今回は無料で利用できます。
GCPで新しいプロジェクトを作成する
Google公式サイトを参考にしてGCPで新しいプロジェクトを作成してください。
プロジェクトの名前やIDは何でも良いのですが今回、
- プロジェクト名:
sql-book-for-bigdata.chap3 - プロジェクトID:
sql-book-for-bigdata.chap3
で設定したプロジェクトを例に進めていくので同じに名前・IDにしておくと混乱が少ないかもしれません。
こちらが完了したらGCPでの設定はほぼ完了です。
『ビッグデータ分析・活用のためのSQLレシピ』サポートサイトからダミーデータをダウンロードする
ダミーデータをダウンロードするためにサポートサイトにアクセスしてください。
ダウンロードデータのとろこにあるSQL_Recipe_sample-code_20170325.zipをクリックするとダウンロードが開始されます。

サポートサイト参考画像
ダミーデータをテーブルに保存する
ダウンロードしたダミーデータを確認する。
まずVScodeでもなんでもいいので先程ダウンロードしたダミーデータを開きます。
そしてChapter3/3-1-1-data.sqlを開いて見てください。以下の画像のようなコードが記載されていることが確認できるかと思います。

ダウンロードしてきたダミーデータからBigQueryにテーブルを作成する
試しにChapter3/3-1-1-data.sqlのデータをBigQueryのテーブルに保存してみます。
まず、GCPのナビゲーションメニューからBigQueryを探し出してSQLワークスペース移動します。すると以下のような画面になっていると思われます。

画像の画面に遷移できたらsql-book-for-bigdata.chap3のよこの縦三点リーダーをクリックしてデータセットを作成をクリックします。すると以下のような画面に移ります。

今回はChapter3のダミーデータを作成したいので、
- データセットID:chap3
- データのロケーション:asia-northeast1 (東京)
としておきましょう。(データのロケーションはどこでも良いです)
データセットを作成をクリックするとエクスプローラーからsql-book-for-bigdataのもとにchap3が作成されたことが確認できます。
次に、Chapter3/3-1-1-data.sqlのコード(下記のコード)をコピーします。
DROP TABLE IF EXISTS mst_users;
CREATE TABLE mst_users(
user_id varchar(255)
, register_date varchar(255)
, register_device integer
);
INSERT INTO mst_users
VALUES
('U001', '2016-08-26', 1)
, ('U002', '2016-08-26', 2)
, ('U003', '2016-08-27', 3)
;
そして、コピーしたものをエディタに貼り付けをします。
その後、貼り付けたものを以下のように編集します。
DROP TABLE IF EXISTS `sql-book-for-bigdata.chap3.mst_users`;
CREATE TABLE `sql-book-for-bigdata.chap3.mst_users` (
user_id STRING
, register_date DATETIME
, register_device INT64
);
INSERT INTO `sql-book-for-bigdata.chap3.mst_users`
VALUES
('U001', '2016-08-26', 1)
, ('U002', '2016-08-26', 2)
, ('U003', '2016-08-27', 3)
;
今、エディタの画面が以下の画像のようになっていればOKです。

編集したのは以下の点です。
sql-book-for-bigdataの部分には自身が設定したプロジェクトIDが入ります。
+ DROP TABLE IF EXISTS `sql-book-for-bigdata.chap3.mst_users`;
- DROP TABLE IF EXISTS mst_users;
+ CREATE TABLE `sql-book-for-bigdata.chap3.mst_users` (
+ user_id STRING
+ , register_date DATETIME
+ , register_device INT64
+ );
- CREATE TABLE mst_users(
- user_id varchar(255)
- , register_date varchar(255)
- , register_device integer
- );
+ INSERT INTO `sql-book-for-bigdata.chap3.mst_users`
- INSERT INTO mst_users
エディタの実行をクリックするとmst_usersという名前のテーブルがchap3のもとに作成されます。
これで本に記載のあるクエリを実行できるようになりました!!
他のダミーデータを追加したい時
今回はChapter3/3-1-1-data.sqlのダミーデータをBigQueryで利用できるようにしました。同様の手順を踏むことによって他のダミーデータもBigQueryで活用できるようになります。
すべてのダミーデータをBigQueryに保存しようとすると多少面倒かと思われるので、「実際にクエリを書いてみて、結果を確認してみたい!」となったダミーデータだけを保存するようにするのがいいと思われます。
補足
今回はさくっとSQLに入門することが目的であるため深堀りはしませんが疑問に思われるであろう点の補足をします。
-
テーブル名について
BigQueryではテーブルを参照する際に
{project-id}.{dataset-id}.{table-name}で参照する必要があります。
そのためmst_usersをsql-book-for-bigdata.chap3.mst_usersへと変更する必要があったのです。 -
型について
varchar(255)やintegerといった型はBigQueryではサポートされていないため適宜変更してあげる必要があります。
これに関しては公式ドキュメントを参照するのが良いと思われます。
実際にクエリを書いてみる
では、実際に保存したテーブルから欲しいデータを抽出するためのクエリを書いてみましょう。
『ビッグデータ分析・活用のためのSQLレシピ』27ページのコード3.1.1.1:コードをラベルに置き換えるクエリを実行してみたいと思います。
BigQueryのエディタに以下のクエリを書いて実行します。
SELECT
user_id,
CASE
WHEN register_device = 1 THEN "PC"
WHEN register_device = 2 THEN "SP"
WHEN register_device = 3 THEN "APP"
ELSE
""
END
AS device_name
FROM
`sql-book-for-bigdata.chap3.mst_users`
以下のような結果が得られれば成功です。
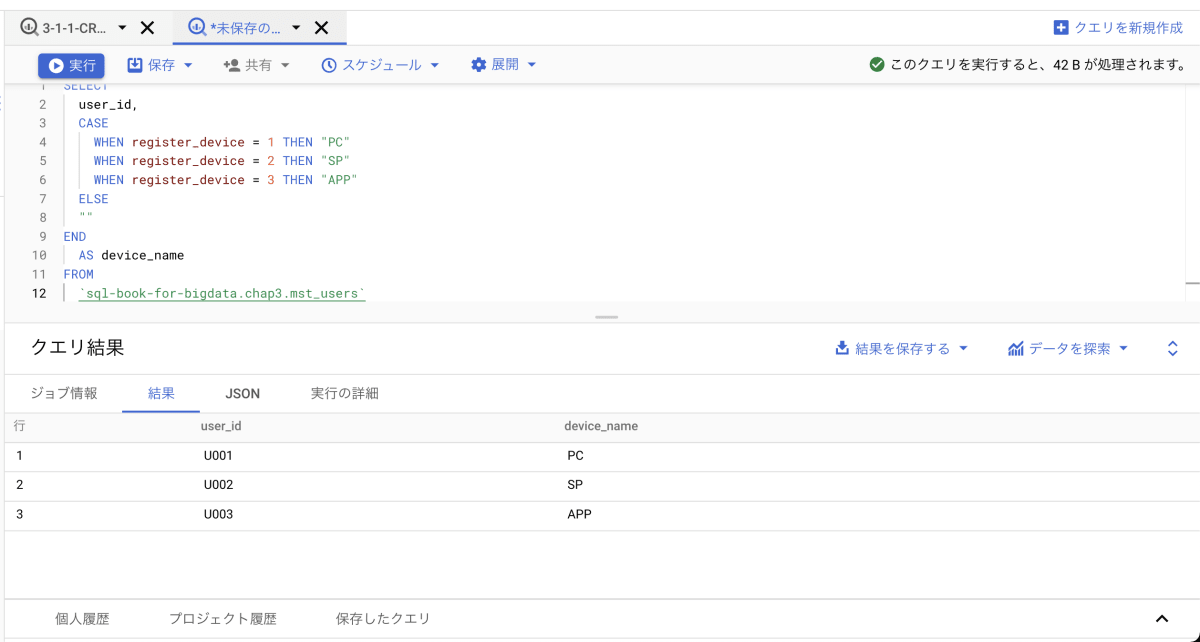
これにてダミーデータをBigQueryに保存して、自身で実際にクエリを叩いてみるという一連の流れが完了です。お疲れ様でした。
今回は1つのダミーデータのみを保存・クエリの実行を行いましたが他のダミーデータも同様の手順を踏むことによってBigQueryに保存することが可能です。
ぜひ他のデータも保存して実際にクエリを書いてみてください!
最後に
今回は自分がSQLを勉強した際に活用した『ビッグデータ分析・活用のためのSQLレシピ』をBigQueryを使って勉強する方法を紹介しました。
SQLがスラスラ書けると機械学習を使いたいときの特徴量作成なども高速に行うことができるようになったりと様々な恩恵があるので是非SQLに入門してみてください!
何かのお役に立てていれば幸いです。
Discussion
BigQueryサンドボックスを使えばクレジットカードの登録無しでBigQueryを使えます。
テーブルは60日しか保存されませんが無料枠と同じ無料使用量の上限ですので、簡単な練習用でしたらこちらのほうが楽です。