Snowflakeのマイクロパーティション
Snowflakeのデータウェアハウスとしてのスケーラビリティ、パフォーマンス、多くの有用な機能の根源の一つに、マイクロパーティションというアーキテクチャの良さがあります。
Snowflakeはオブジェクトストレージ上に構成されたマイクロパーティションと、そのメタデータを徹底的に最適化することで、ACID制御からタイムトラベルまで、多くの機能をとてもうまく実装しています。(でもこのアーキって最近よく聞くIcebergや他のオープンテーブルフォーマットとちょっと似てない?というのは今回とは別のお話)
マイクロパーティションを超わかりやすく解説されているほーりーさんの素晴らしい記事はこちら。
このマイクロパーティションはプルーニングという仕組みにより、Snowflakeのパフォーマンス向上に絶大な影響を与えています。解説記事はこちら。
最近、マイクロパーティションどうしてる?
もちろんマイクロパーティションは今もSnowflakeの中枢で絶大なパワーを発揮し続けています。ただ、最近のSnowflakeはAI Data Cloudを標ぼうしており、大々的な公式発表はAIに関するものが非常に多いです。そこまでマイクロパーティションについて語られることは多くなくなってきた印象です。
しかし、(外部の人間として勝手に言いますが)Snowflakeはやっぱりデータベースの技術の会社です!RDBMSを0から構築できるスーパーDBエンジニアたちが作った会社なのです。Snowflake開発チームのエンジニア達は今も、SQLの機能/性能の改善、その重要な一部としてのマイクロパーティション、およびそのメタデータを利用したパフォーマンス向上のための開発をずっと続けています。
そんななか、面白いブログ記事が公式から上がったので、その背景を含めて紹介します。
ORDER BYとLIMITの組み合わせ
今回ブログで紹介されているTop-Kと呼ばれているクエリは、要するにSELECT結果の順序を指定するORDER BY句と、結果行数を指定するLIMIT句の組み合わせです。
組み合わせて使いたい
Snowflake関係なくSQL一般論として、ORDER BYとLIMITはユースケースとして一緒に使いたいものです。
何万行、何億行もあるテーブルをORDER BYするときは、そのなかの上位何件かを使いたいときがほとんどです。並べ替えたうえで全件眺めたいという人はいないでしょう。もちろんフィルタ/サマリした結果だけを並べ替えるときはそんな問題はありませんが、SQLが実現したい要件は実に様々です。
一方LIMITはそもそもORDER BYと一緒に使わないと結果が非決定的となってしまい、複数回実行時の結果の同一性が担保されません。LIMIT単独で使うのはせいぜいサンプル的にテーブルにどんなデータが入っているかを確認するときくらいでしょうか。
でも性能は悪い
しかしSQLの論理構造を考えると、ORDER BYとLIMITの性能的な組み合わせは良くありません。
LIMITは単体で使えば性能は非常に高速です。それはそうです。無作為にLIMITで指定されている行数だけを読み込めば、そこでスキャンを止めることができるからです。元のテーブルが何億行でもLIMIT 100であれば性能はほぼ一定で高速です。どんなRDBMSでもそうです。
しかし、ORDER BYと組み合わせた瞬間、LIMITの良さは失われてしまいます。並べ替えた(ORDER BY)結果を絞り込んで(LIMIT)で取得したいからです。つまり「スキャン」→「ソート」→「絞り込み」という順序になります。すると、最終的に取得したい結果行がどんなに少なくても、スキャンIOやソート量はそれとは一切関係なく大きなものとなってしまいます。
このような処理順序の考え方を知っておくことはSQLチューニングのテクニックとしてはとても重要です。WHEREやGROUP BYなど他の句も含めた全体的な流れについてはkさんの以下のブログがわかりやすいです。
ORDER BYとLIMITを組み合わせた瞬間、結果がどんなに小さくても、ORDER BYで全体をソートする必要がある、というのは論理的に考えれば当然のことです。だからこそWHEREによるフィルタリングやGROUP BYによるグルーピングをしっかりとしなければならない、というのがSQLチューニングの考え方の一つです。(RDBMS側も色々考えていて、上記kさんのブログで紹介されているように、Index付与済み列であればソート済みのため全体ソートを回避できる、と言った工夫もされています)
でも何度も言いますが、SQLが実現したい要件は本当に様々なんです。どうしても実際に大量データをスキャンしてソートすることを余儀なくされることはいくらでもあり得ます。そんな時は素直にコンピューティングパワーに頼るしかありません・・・でした。
Snowflakeのマイクロパーティションがまたやってくれた!
Snowflakeはこの常識を打ち破りました!Snowflakeでは、「スキャン」「ソート」「絞り込み」を同時に行ってくれます。・・・って何を言っているんでしょう?
2023年7月頃にリリースされ、その後1年かけて進化していったTop-KアルゴリズムによるORDER BYとLIMITの最適化は、マイクロパーティションの良さを最大限に生かして、このわけのわからないことを実現しています。
Top-Kアルゴリズムによるプルーニング
このリリース以来、SnowflakeはORDER BYとLIMITが同時に使われたとき、マイクロパーティションを順次スキャンしていき、その1つ1つの過程で中間結果をソートし、確認されたk番目に大きい値を保持しながら次のマイクロパーティションをスキャンするかどうかを判断します。これにより、保持しているk値より小さい値しか含まないとわかっているマイクロパーティションを読み飛ばす、つまりプルーニングすることができます。こうすることで、スキャンが進めば進むほど、読み飛ばして良いマイクロパーティションが増えていくことになります。
これにより、「スキャン」「ソート」「絞り込み」を同時に、より正確にいうと、マイクロパーティションごとに「スキャン」と「ソート」を行い、先に「絞り込み」を行うことができるのです。
なんとSnowflakeはこんなところでもマイクロパーティションの最大値/最小値メタデータを用いたプルーニングを実行していたのでした!
しかも、ユーザは何一つクエリを書き換える必要はありません。Snowflake側でしれっとされていたリリースだけで、従来のSQLの常識を覆し、劇的なパフォーマンス改善を実現しています。さらに最初のリリースから約1年で改善もどんどん行われており、今では最初のスキャンの前からクエリとメタデータを考慮して、スキャンするパーティションの順序の最適化までしているとのこと・・・!
実際に試してみる
そうとわかったらやってみましょう!SNOWFLAKE_SAMPLE_DATAを使った、非常にシンプルな実験です。
LIMITだけ
TPCH_SF100のORDERSテーブルには1.5億行のデータが入っています。まずはLIMITで100件だけ中身をみてみましょう。
select * from snowflake_sample_data.tpch_sf100.orders limit 100;
結果は2.8秒で返ってきました。

クエリプロファイルを見ると、ほとんどパーティションをIOしていないことがわかります。
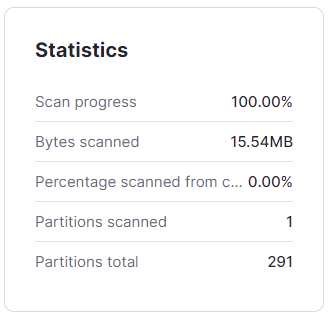
ORDER BYだけ
1.5億件全量ORDER BYしてSELECTすると、XSサイズのWHで約2分程度で完了します。(それでも速いんですが)
select * from snowflake_sample_data.tpch_sf100.orders order by o_orderdate;

クエリプロファイルを見ると、当然ですが全パーティションをスキャンしています。それどころか、ソートのための中間データがメモリに乗りきらずストレージへのSpillが発生してしまっており、おそらくそのため全体パーティション数が2倍に膨れ上がるという事象が発生しています。

ORDER BY×LIMIT
さぁ本番です。ORDER BYとLIMITの組み合わせはどうなんでしょうか。WHキャッシュが効くのを防ぐため別のWHで実行します。
select * from snowflake_sample_data.tpch_sf100.orders order by o_orderdate limit 100;
うぉー速い!なんと3.3秒!ほとんどLIMITだけと変わらない!
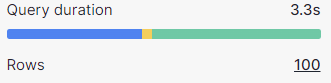
しっかりとプルーニングが効いています!

ORDER BYだけのときの124秒が3.3秒になったので、なんと37倍の高速化です。素晴らしい!IOを減らしてSpillの発生を抑えられたことで、かなり劇的にメリットが見えるようなケースとなりました。
SnowflakeはDBとしても進化を止めない
いやー、面白いですね。公式ブログを見て、私の常識から最初はなかなか理解が追い付かなかったのですが、仕組みを知ってなるほど!と思え、実際に体感できて、これは記事にしなければ!との思いで書かせていただきました。
改めて、マイクロパーティションは素晴らしいアーキテクチャですし、それを最大限活かしてまだまだ高みを目指していこうというSnowflakeの開発チームに私は本当に敬意を表します。AI Data CloudとしてのSnowflakeもとても良いですが(Notebook最高すぎる)、Cloud Native Data Warehouseとして、いやUnistoreも合わせてCloud Native Relational DatabaseとしてのSnowflakeにも、私は今後も一層注目し続けるつもりです。

Snowflake データクラウドのユーザ会 SnowVillage のメンバーで運営しています。 Publication参加方法はこちらをご参照ください。 zenn.dev/dataheroes/articles/db5da0959b4bdd
Discussion