Goのstringsパッケージを読む
はじめに
Goの標準ライブラリのstringsパッケージのいくつかの関数の実装を読み込んで、どんな感じになっているのかを知る
そもそもGoにおけるstring型について
Goのstringは読み取り専用のbyteのsliceである。Goの符号化方式はUTF-8なので、文字列をUTF-8エンコードしたbyte列が入る。
string型の値をループして、各要素にアクセスしたときの挙動
for を使って適当なstring型の値をループする。ループ内でどう要素にアクセスするかで、得られる値やその型が変わる。
イテレーター変数を使って、インデックスアクセスした場合
uint8型の値にアクセスできる。uint8型は8bit、つまり1byte分のデータ表現ができる。型の指定時によく見るbyteはuint8型の型エイリアスである。
stringは読み取り専用のbyteのsliceであるので、ループでは基底配列の要素を1つずつ参照していることになる。(= 文字列のUTF-8エンコード結果としてのbyte列を1byteずつアクセスしていることになる)
参照する値の型の確認
package main
import "fmt"
func main() {
str := "Hello 世界"
for i := 0; i < len(str); i++ {
fmt.Printf("%T\n", str[i])
}
}
実行結果
uint8
uint8
uint8
uint8
uint8
uint8
uint8
uint8
uint8
uint8
uint8
uint8
参照する値の確認
package main
import "fmt"
func main() {
str := "Hello 世界"
for i := 0; i < len(str); i++ {
fmt.Printf("%v\n", str[i])
}
}
実行結果
72
101
108
108
111
32
228
184
150
231
149
140
for rangeのループで、2番目のループ変数として得られる値を使ってアクセスした場合
int32型の値にアクセスできる。得られる値はUnicodeのコードポイントと呼ばれる数字であり、Unicodeのコードポイント範囲が全部で110万の文字の登録に対応できるので、そのパターンすべての表現に必要な21bitを格納することができるint32型が利用されている(のだと思う)。今回の文脈では、Unicodeのコードポイントを示すrune(int32型の型エイリアス)として一般的には使われる。
参照する値の型の確認
package main
import "fmt"
func main() {
str := "Hello 世界"
for _, s := range str {
fmt.Printf("%T\n", s)
}
}
実行結果
int32
int32
int32
int32
int32
int32
int32
int32
参照する値の確認
package main
import "fmt"
func main() {
str := "Hello 世界"
for _, s := range str {
fmt.Println(s)
}
}
実行結果
72
101
108
108
111
32
19990
30028
ちなみに、以下で確認してみると、上記数字らは確かにUnicodeのコードポイントであることがわかる。
runeとして入っているUnicodeのコードポイントに対応する文字は、以下のようにstring()で囲ってあげることで、簡単に示すことができる。
package main
import "fmt"
func main() {
str := "Hello 世界"
for _, s := range str {
// sはrune
fmt.Printf(string(s))
}
}
Hello 世界
参考
strings.ToUpper
概要
要は渡した文字列を大文字にしてくれる関数

実装を追う
// ToUpper returns s with all Unicode letters mapped to their upper case.
func ToUpper(s string) string {
isASCII, hasLower := true, false
for i := 0; i < len(s); i++ {
c := s[i]
if c >= utf8.RuneSelf {
isASCII = false
break
}
hasLower = hasLower || ('a' <= c && c <= 'z')
}
if isASCII { // optimize for ASCII-only strings.
if !hasLower {
return s
}
var (
b Builder
pos int
)
b.Grow(len(s))
for i := 0; i < len(s); i++ {
c := s[i]
if 'a' <= c && c <= 'z' {
c -= 'a' - 'A'
if pos < i {
b.WriteString(s[pos:i])
}
b.WriteByte(c)
pos = i + 1
}
}
if pos < len(s) {
b.WriteString(s[pos:])
}
return b.String()
}
return Map(unicode.ToUpper, s)
}
詳細を追ってみる。
まずは最初の部分。
isASCII, hasLower := true, false
for i := 0; i < len(s); i++ {
c := s[i]
if c >= utf8.RuneSelf {
isASCII = false
break
}
hasLower = hasLower || ('a' <= c && c <= 'z')
}
やってることは、
- 渡された文字列を1バイトずつループで見る
- もしASCIIの範囲よりも大きい数字を表すバイトが登場したら、それはASCIIではないのでループを終える
- 小文字が登場したかを記録する
である。
utf8.RuneSelf というのは、以下で定義されている。10進数に直すと128である。
ASCII文字は10進数で表すと0〜127の範囲で定義され、かつUTF-8でも127以下となる1byteで定義される。もし、ループの中で登場するバイトを10進数にしたものが128より大きかったら、その時点でASCIIではないということになる。
続きを追ってみる。
if isASCII { // optimize for ASCII-only strings.
if !hasLower {
return s
}
var (
b Builder
pos int
)
b.Grow(len(s))
for i := 0; i < len(s); i++ {
c := s[i]
if 'a' <= c && c <= 'z' {
c -= 'a' - 'A'
if pos < i {
b.WriteString(s[pos:i])
}
b.WriteByte(c)
pos = i + 1
}
}
if pos < len(s) {
b.WriteString(s[pos:])
}
return b.String()
}
ASCII定義の文字のみで渡された文字列が成り立つときのみ、実行される処理である。ASCIIに最適化された処理である。
やってることは、
- 渡された文字列がASCII定義の文字のみで構成されていたら、処理を実行する。
- もし小文字が1つも含まれていなかったらreturnしてToUpper自体をおしまい
- 渡されたbyte数分のバッファ確保(Builderを用いた文字列構築にて、メモリの追加割当や不要なコピーが発生しないようにする)
- 小文字に到達するまでループする。小文字に到達したらそれを大文字に変換して、そこに至るまでの文字全部をまとめてバッファに書きこむ
- ループ終わった時点でバッファに書きこんでいない文字があれば、それらを全部バッファに書きこむ
- バッファに書きこんだbyte列をstring型の値として返却する
c -= 'a' - 'A' は、小文字であるcの中身を大文字に変換する計算。uint8同士の数値計算である。ASCIIに絞った処理だから成り立つ。
続きをさらに追ってみる。
return Map(unicode.ToUpper, s)
Map関数については、stringsパッケージに存在する主要関数の1つなので、別でスクラップに枠を取ってしっかり追う。今回はざっくり何してるのかだけ調べると、公式ドキュメントには以下のような記載があった。
Map returns a copy of the string s with all its characters modified according to the mapping function. If mapping returns a negative value, the character is dropped from the string with no replacement.
Map関数は、Map(mapping func(rune) rune, s string) stringという形を取るが、これは、ここでmappingとして渡した関数を、sとして渡した文字列全てに適用し、結果として返すというもの。ToUpper関数では、unicodeパッケージのToUpper関数を渡しており、それが適用された結果がstrings.ToUpperの戻り値となる。
じゃあ、unicodeパッケージのToUpper関数は何をしているのか。以下が内容である。
func ToUpper(r rune) rune {
if r <= MaxASCII {
if 'a' <= r && r <= 'z' {
r -= 'a' - 'A'
}
return r
}
return To(UpperCase, r)
}
ASCIIだったら、'a' - 'A'で大文字にして返している。そうじゃなかったら、unicodeパッケージのTo関数を呼び出している。unicodeパッケージのTo関数は、与えられたruneを指定されたケース(UpperCase or LowerCase or TitleCase)に変換してくれる関数である。与えられたruneに対応するケースがなければそのまま返す。
// To maps the rune to the specified case: [UpperCase], [LowerCase], or [TitleCase].
func To(_case int, r rune) rune {
r, _ = to(_case, r, CaseRanges)
return r
}
参考
strings.ToLower
概要
要は渡した文字列を小文字にしてくれる関数

実装を追う
strings.ToUpperとほぼ同じ。諸々が反転しているだけである。
// ToLower returns s with all Unicode letters mapped to their lower case.
func ToLower(s string) string {
isASCII, hasUpper := true, false
for i := 0; i < len(s); i++ {
c := s[i]
if c >= utf8.RuneSelf {
isASCII = false
break
}
hasUpper = hasUpper || ('A' <= c && c <= 'Z')
}
if isASCII { // optimize for ASCII-only strings.
if !hasUpper {
return s
}
var (
b Builder
pos int
)
b.Grow(len(s))
for i := 0; i < len(s); i++ {
c := s[i]
if 'A' <= c && c <= 'Z' {
c += 'a' - 'A'
if pos < i {
b.WriteString(s[pos:i])
}
b.WriteByte(c)
pos = i + 1
}
}
if pos < len(s) {
b.WriteString(s[pos:])
}
return b.String()
}
return Map(unicode.ToLower, s)
}
strings.ToTitle
概要
渡した文字列をTitle Caseにしてくれる関数

実装を追う
そもそもTitle Caseってなんだ?
Title Caseとは冠詞とかそういう特殊なのを除いた全ての単語の先頭の文字だけ大文字にするものらしい。
ABC だったら、Abc みたいな。
strings.ToTitle自体の実装はシンプルで、strings.ToUpperやstrings.ToLowerと同じく内部的にはMapを呼び出しているだけ。
ただし、ASCIIの場合の条件分岐などはなく、すぐにMap関数にunicode.ToTitleを渡している。
// ToTitle returns a copy of the string s with all Unicode letters mapped to
// their Unicode title case.
func ToTitle(s string) string { return Map(unicode.ToTitle, s) }
unicode.ToTitleはASCII定義の文字だったらUpper Caseを返す。そうじゃなかったら、そのunicode定義文字に対応するTitle Caseを返してくれる。
// ToTitle maps the rune to title case.
func ToTitle(r rune) rune {
if r <= MaxASCII {
if 'a' <= r && r <= 'z' { // title case is upper case for ASCII
r -= 'a' - 'A'
}
return r
}
return To(TitleCase, r)
}
ASCII定義の文字だったら全て大文字というのはTitle Caseの定義と異なるのでは?実際に試してみても、ToUpperのような挙動となってしまう。
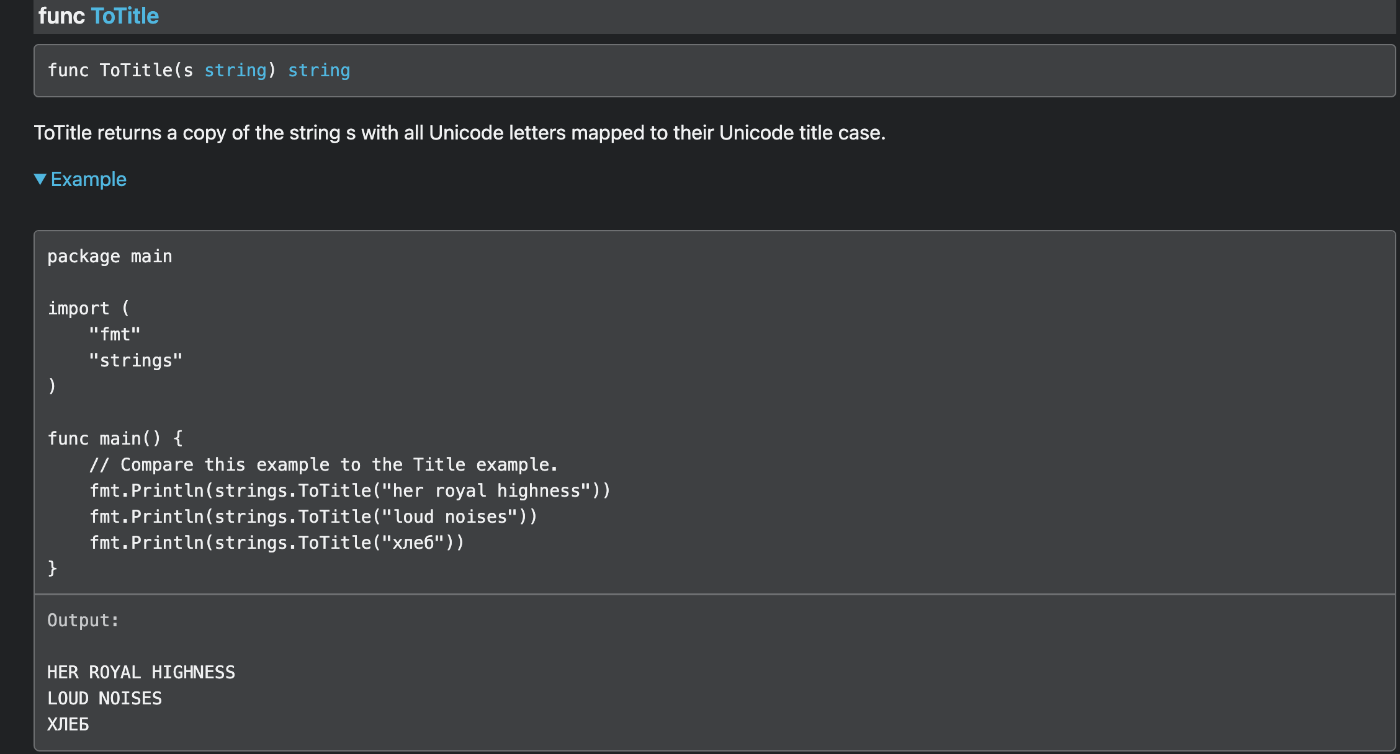
これについては調べても正直理由がわからなかった。
むしろ、DEPRECATEDになっている、strings.Titleのほうが期待するTitle Caseを返すっぽい。

strings.Map
概要
渡した文字列の1つ1つの文字に対して、第一引数で渡したmapping関数を適用し、適用後の文字列を返すというもの。もし渡したmapping関数の中で負の数を返した場合、その文字は最終的な文字列から欠落する。

実装を追う
処理は以下である。
func Map(mapping func(rune) rune, s string) string {
// In the worst case, the string can grow when mapped, making
// things unpleasant. But it's so rare we barge in assuming it's
// fine. It could also shrink but that falls out naturally.
// The output buffer b is initialized on demand, the first
// time a character differs.
var b Builder
for i, c := range s {
r := mapping(c)
if r == c && c != utf8.RuneError {
continue
}
var width int
if c == utf8.RuneError {
c, width = utf8.DecodeRuneInString(s[i:])
if width != 1 && r == c {
continue
}
} else {
width = utf8.RuneLen(c)
}
b.Grow(len(s) + utf8.UTFMax)
b.WriteString(s[:i])
if r >= 0 {
b.WriteRune(r)
}
s = s[i+width:]
break
}
// Fast path for unchanged input
if b.Cap() == 0 { // didn't call b.Grow above
return s
}
for _, c := range s {
r := mapping(c)
if r >= 0 {
// common case
// Due to inlining, it is more performant to determine if WriteByte should be
// invoked rather than always call WriteRune
if r < utf8.RuneSelf {
b.WriteByte(byte(r))
} else {
// r is not an ASCII rune.
b.WriteRune(r)
}
}
}
return b.String()
}
mappngという仮引数を用いて呼べる関数は、runeを受け取ってruneを返す。
そのmappingを、sで表現される置換前文字列の1つ1つの文字にforループを用いて適用していく。
そして、最終的なアウトプットは、var b Builderで定義されたバッファに詰まったbyte列をstring型にした文字列である。
続いて、以下で最初のforループで何をしているのかを見てみる。
まずは、そのループ回担当のルーンに対してmappingを適用する。
もし出力が、 �ではない && 渡したルーンと変わらない場合(= 特に変換がかからなかった時)、次のループ回にうつる。
- �は
utf8.RuneErrorで表現されるもので、utf8で表現できないバイトに割り当てられる。
もし、変換結果が�だったときはutf8パッケージのDecodeRuneInStringを使って現在のiから有効なルーンとそのバイト幅を取得し、それが元のルーンと同じだったら次のループ回にうつる。
もし、変換結果が元のルーンとは異なり、ルーンの値がnegativeではなく、かつ正常変換できている場合(�じゃない場合)はbのサイズを拡張した後、iまでの文字列と変換結果のルーンをbに書きこみ、ループを終了する。
for i, c := range s {
r := mapping(c)
if r == c && c != utf8.RuneError {
continue
}
var width int
if c == utf8.RuneError {
c, width = utf8.DecodeRuneInString(s[i:])
if width != 1 && r == c {
continue
}
} else {
width = utf8.RuneLen(c)
}
b.Grow(len(s) + utf8.UTFMax)
b.WriteString(s[:i])
if r >= 0 {
b.WriteRune(r)
}
s = s[i+width:]
break
}
最初のループのあとを見る。
もし入力に対してmappingを適用した結果、何も変化がなかった( b.Cap() == 0 )ら、元の文字列をそのまま返す。
続いて最初のループから漏れた残りの文字列sを、1つずつmapping関数にかけて結果がnegativeじゃなかったらbに書きこんでいく。r < utf8.RuneSelf (つまりASCII定義の文字)だった場合、Goコンパイラのインライン展開が行われるb.WriteByte(byte(r))を優先的に使い、そうじゃないときはb.WriteRune(r)を実行する。
そして、最後にb.String()で結果として返す。
// Fast path for unchanged input
if b.Cap() == 0 { // didn't call b.Grow above
return s
}
for _, c := range s {
r := mapping(c)
if r >= 0 {
// common case
// Due to inlining, it is more performant to determine if WriteByte should be
// invoked rather than always call WriteRune
if r < utf8.RuneSelf {
b.WriteByte(byte(r))
} else {
// r is not an ASCII rune.
b.WriteRune(r)
}
}
}
return b.String()
疑問としては、最初に出現する置換後結果が異なる変換の検出については、変換結果がRuneErrorかどうかなどのチェックなどをしているが、そのチェックのループをbreakしているので、2番目以降の変換対象に対しては特に確認とかしていないこと。チェックしなくてもいいのだろうか。ここがあまり理解できていない。
strings.Index
概要
探索対象の文字列の中で渡した文字列が最初に見つかった箇所のインデックス番号を返す。見つからなかったら-1を返す。

実装を追う
とても詳しい記事がすでにあるので、以下で担保