Next.jsとFirebaseを使用した「いいね」機能のデータ整合性問題の解決策
はじめに
という記事を書いたが、以下の課題を解決したいため、まずは課題を整理して対策を決めたい。
残った課題
- データの整合性がとれていない問題
- セキュリティリスクの懸念
- ユーザー情報の分割の単位をどうするか?
- 記事とそのいいね情報の分割の単位をどうするか?
やりたいこと
このスクラップでは、課題に対する最適な解決策を立てた上で下記の機能を実装するとする。
- 「いいね」機能の活用法
- 自分が「いいね」した記事のリスト表示
- 記事を「いいね」したユーザーのリスト表示
前提
詳細は、上記の記事に書いてますが、一応概要だけ。
システムの概要
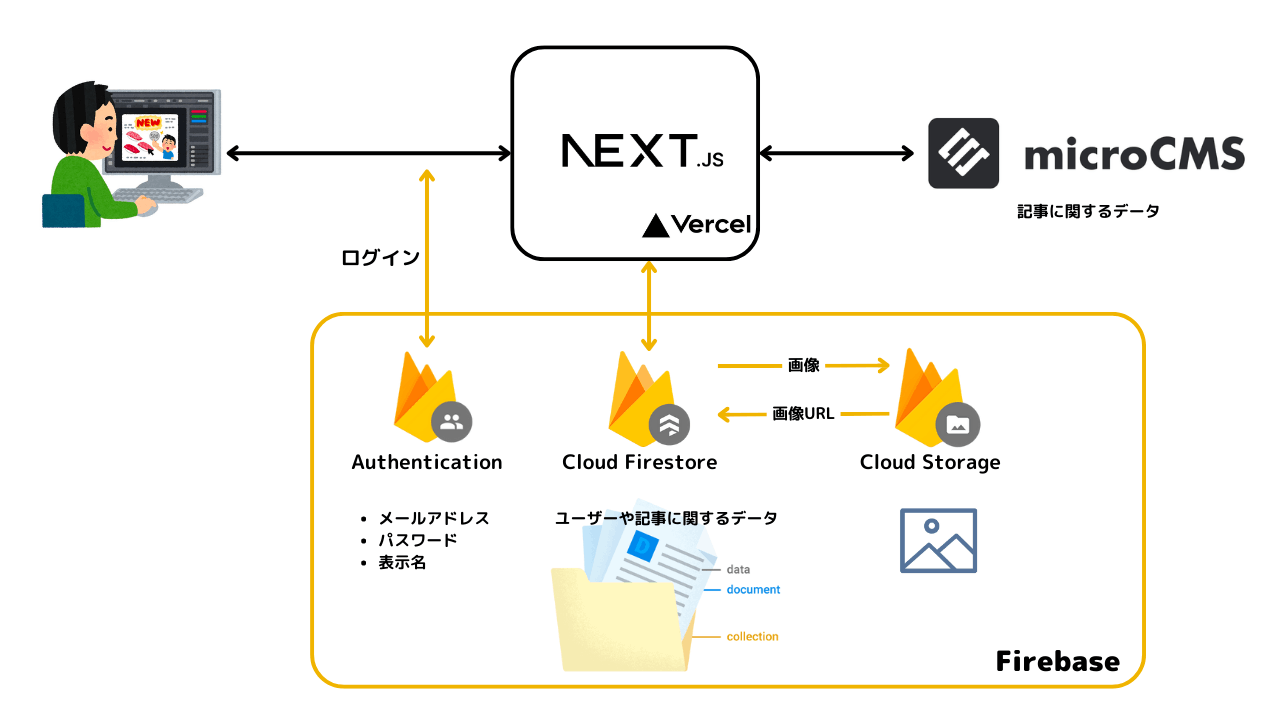
- 技術スタック:Next.js, Firebase (Authentication, Cloud Firestore, Cloud Storage), microCMS
- 「いいね」機能:ユーザーが記事に対して「いいね」を付ける機能
- データはPostsのサブコレクション(LikedUser)に保存
- データ取得:記事データはmicroCMSからAPI経由で、ユーザーデータはFirestoreから取得
課題 1.「データの整合性がとれていない問題」
現状のシステムでは、ユーザーが"いいね"した後に自分のユーザー名を変更すると、"いいね"した記事に残るユーザー名が変更後のものにならないことが問題と定義しました。
解決策
システムのデータの整合性を保つためには、データ同期の導入やデータを一つにまとめて取得するなどの処理が必要となります。しかし、これらの解決策にはそれぞれメリデメがあります。
- 解決策1:データ同期の仕組みの導入
- Firebase間のデータ同期を行う(Cloud Functionsなどを使用して)
- メリット:パフォーマンスの懸念は少ない
- デメリット:実装の手間、複雑性、コストなどが増大する
- Firebase間のデータ同期を行う(Cloud Functionsなどを使用して)
- 解決策2:データを1つにまとめてクライアントサイドジョインなどで取得
- メリット:実装の手間や複雑性が少ない
- デメリット:クエリが2回以上必要になる可能性があり、パフォーマンスに影響が出る
採用する解決策とその理由
解決策2を採用する。
理由:パフォーマンスの問題が解決できれば懸念が少ないから。
解決策2は「データ一元化とクライアントサイドジョイン」という名前にする。
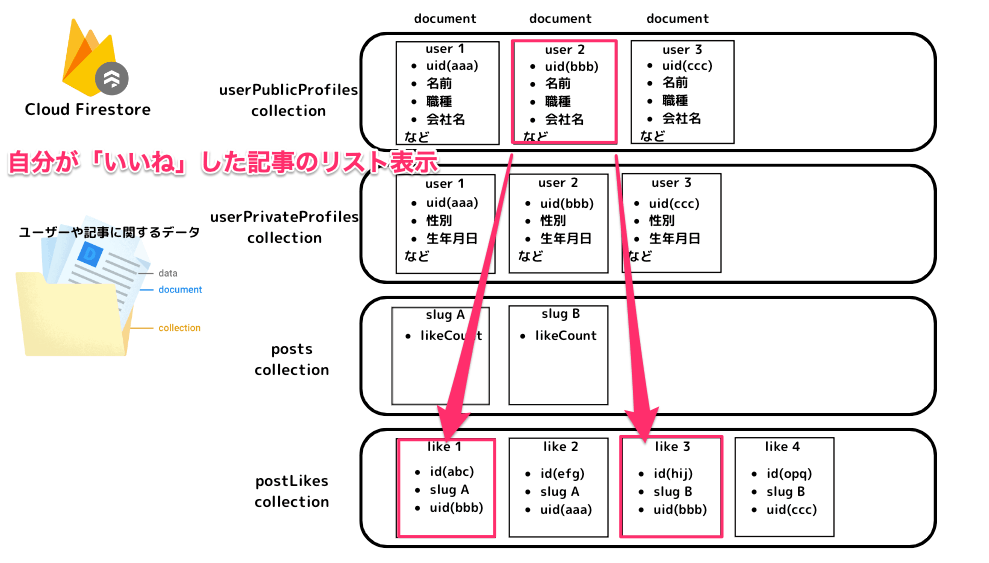
「自分が「いいね」した記事のリスト表示」
データ取得のイメージ
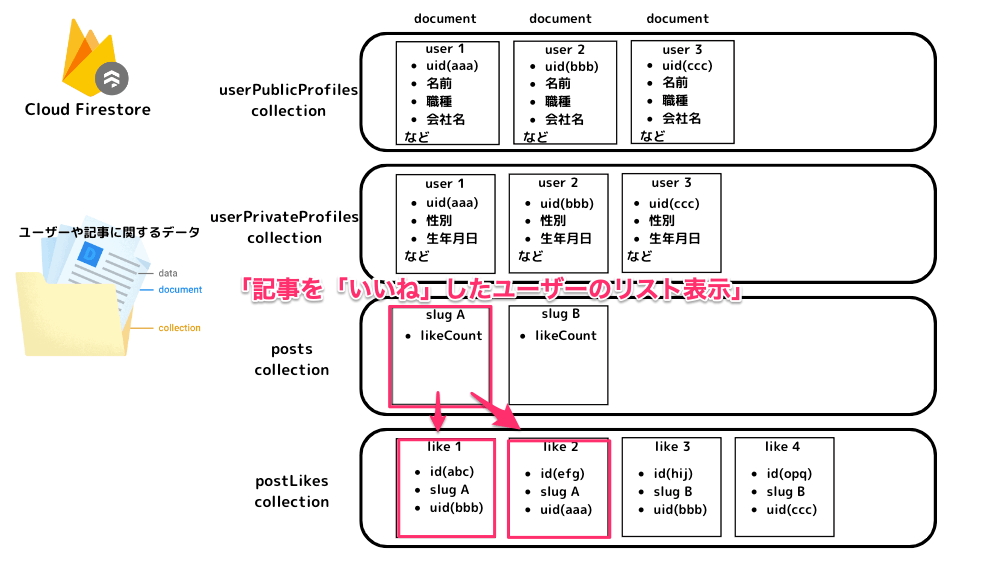
「記事を「いいね」したユーザーのリスト表示」
データ取得のイメージ
参考
データ一元化とクライアントサイドジョインの懸念
課題 2.「セキュリティリスクの懸念」
Firestoreの特性上、ドキュメント全体を取得するか何も取得しないかのどちらかとなり、部分的にドキュメントを取得することができません。これにより、Postsのサブコレクション(LikedUser)のフィールドにあるUIDをキーにしてuserドキュメントを取得すると、自分が閲覧・編集したい情報と同時に他人には見られたくない情報も取得できてしまいます。これは、Firestoreのセキュリティルールがドキュメントレベルで適用されるためです。
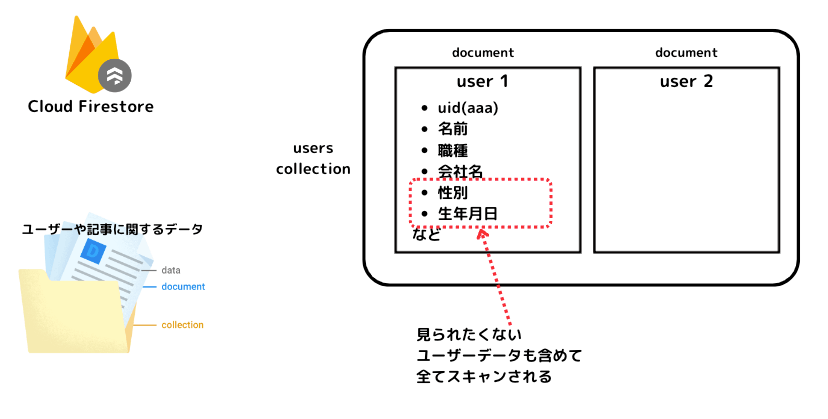
解決策:フィールドの機密レベルを統一する
セキュリティリスクを回避するため、ドキュメント内のすべてのフィールドの機密レベルを統一することが重要です。
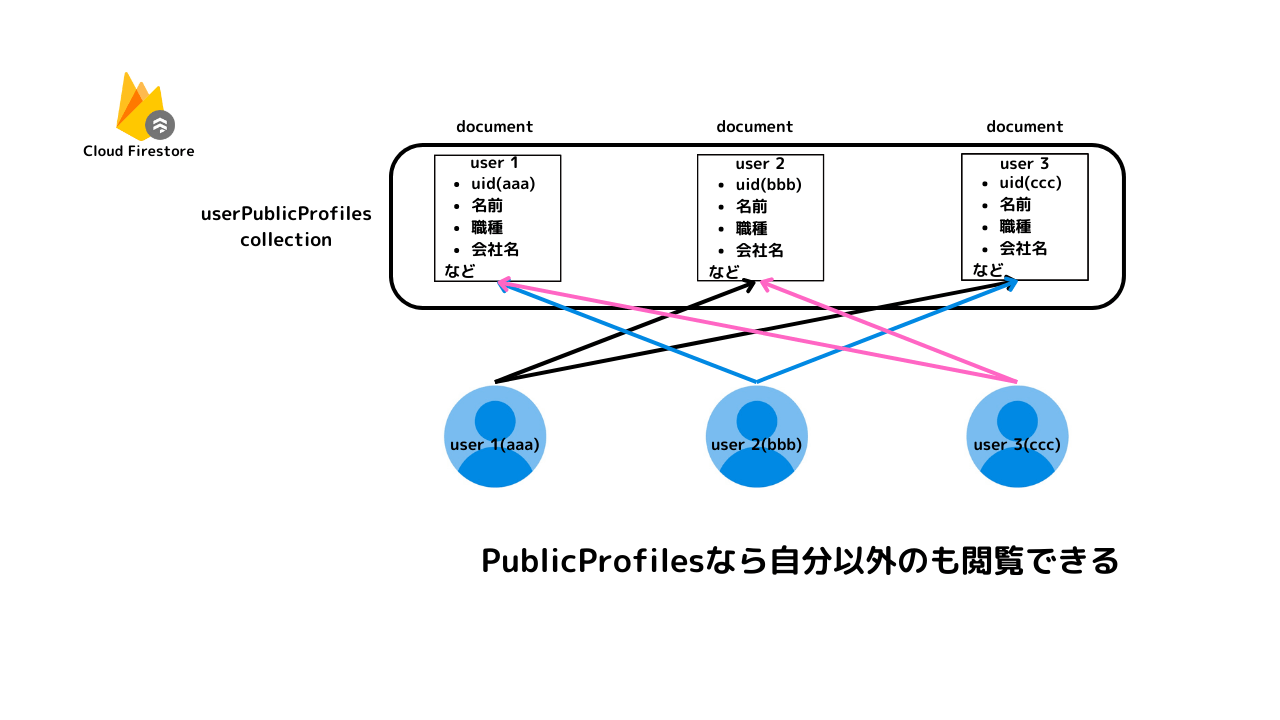
具体的な方法の一例は、usersのドキュメントを二つのコレクション(private_usersとpublic_users)に分割し、それぞれに異なるセキュリティルールを適用するやり方です。
これにより、機密性の異なる情報を別々のドキュメントに格納し、それぞれに適切なアクセス権を設定します。これによって、上述したリスクは回避できます。
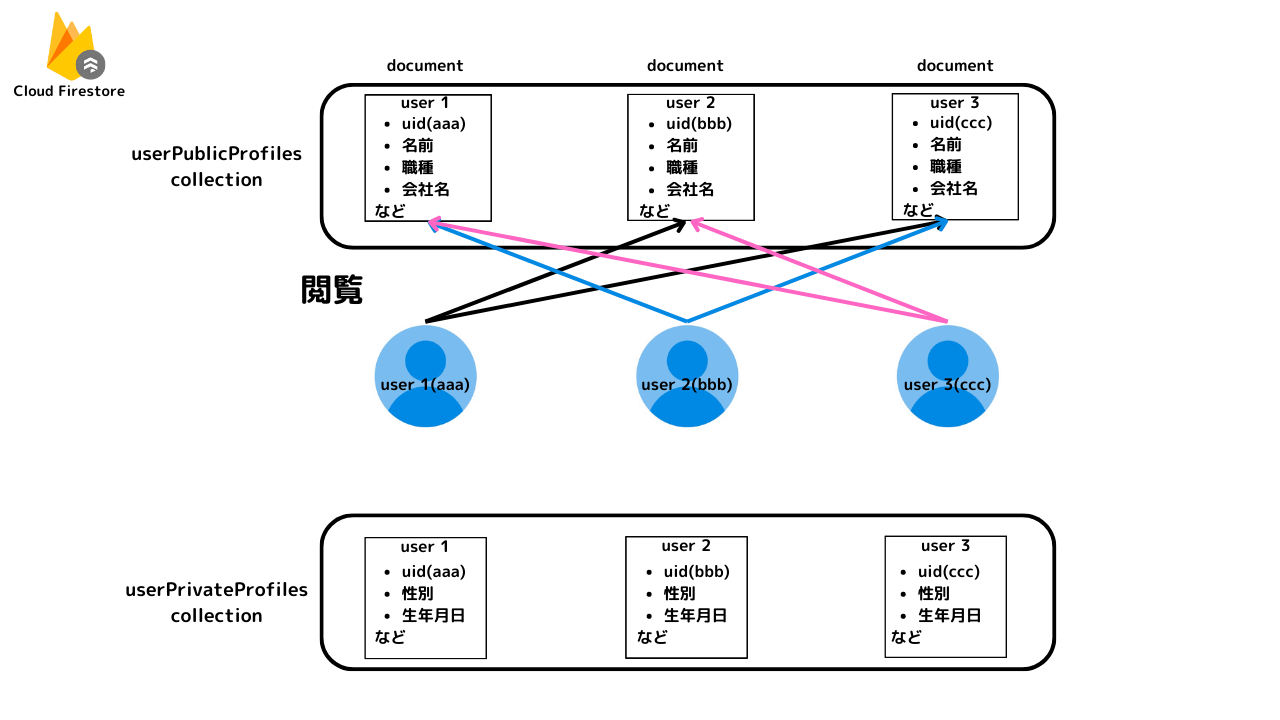
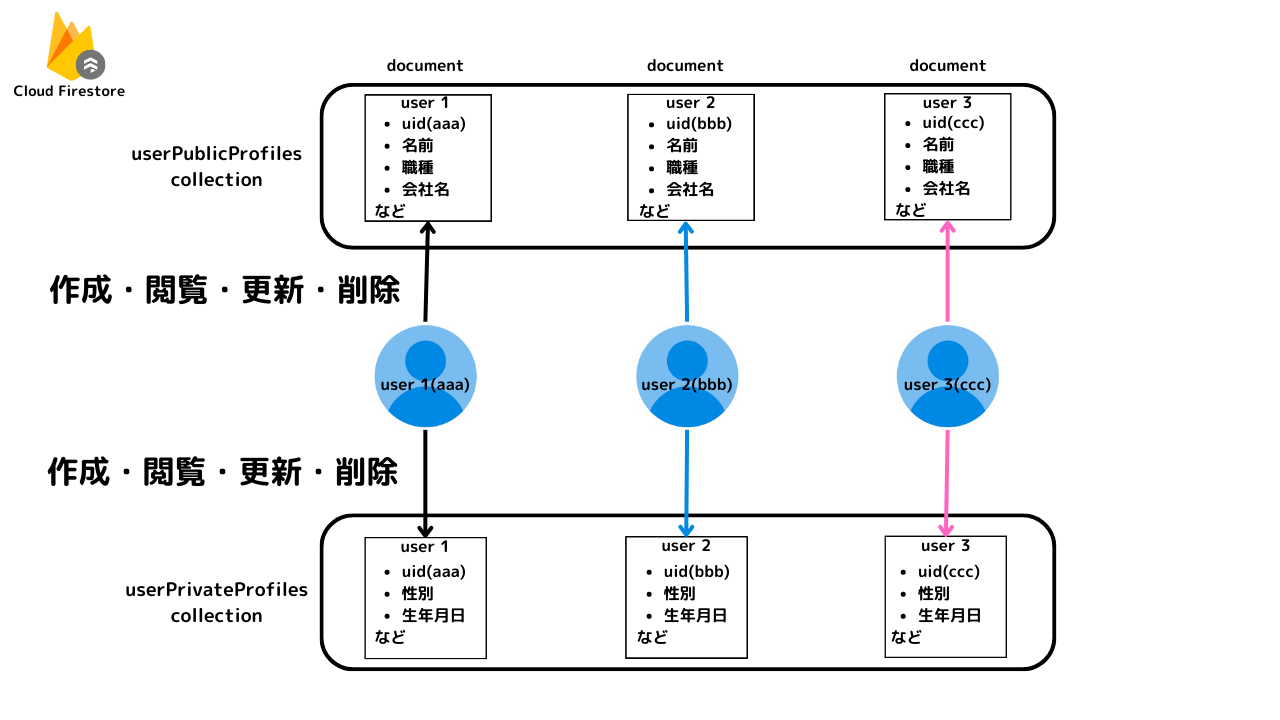
補足(Firestoreのデータモデリングとセキュリティ)
Firestoreにおけるデータモデリングとセキュリティ
Firestoreでは、データ保護のためにセキュリティルールとデータモデリングが密接に関連しており、これらはデータモデル設計の段階で考慮する必要があります。
Firestoreがクライアントからの直接アクセスを許可しているのとは対照的に、RDS(リレーショナルデータベースサービス)のような一般的なデータベースでは、サーバーサイドでデータにアクセスし、ビジネスロジックでデータを加工できます。そのため、RDSではデータモデリングとセキュリティの確保は別々の概念となります。
しかし、Firestoreではクライアントからの直接アクセスが許可されているため、データ加工はサーバーサイド(FirestoreではGoogleのクラウド環境)で行う必要があります。クライアントアプリケーションには改ざんのリスクがあるため、重要なセキュリティルール(誰がどのデータにアクセスできるかなど)の管理はクライアント側ですることは適切ではありません。
Firestoreではドキュメント全体を読み取るか、または何も読み取らないかの二択となり、特定のフィールドだけを読み取ることはできません。そのため、機密性の高い情報とそうでない情報を同一のドキュメントに格納すると、不適切なアクセスが生じる可能性があります。これを防ぐためには、データモデル設計の段階で機密情報と一般情報を別のドキュメントやコレクションに分ける設計を行う必要があります。
課題 3.「ユーザー情報の分割の単位をどうするか?」
TL;DR
結論:「分割ユーザーコレクションモデル」にした
本文
Firestoreのデータモデリングでは、機密情報と一般情報をどのように分割・保存するかは設計の段階で重要な決定となります。
具体的には以下のケースが考えられます。
便宜上、勝手に命名します。
- 方法1:統合ユーザーコレクションモデル(単一ユーザーコレクション・サブコレクションモデル)
- すべてのユーザー情報が一つの "users" コレクションに保管され、公開と非公開の情報がユーザーごとのサブコレクションで管理するモデル
- 方法2:分割ユーザーコレクションモデル
- ユーザー情報を公開情報とプライベート情報に分けて別々のコレクションで管理し、「いいね」情報を独立したコレクションで管理するモデル
- 方法3:CQRSベース分割ユーザーコレクションモデル
- ユーザー情報を公開情報とプライベート情報に分けて別々のコレクションで管理し、「いいね」情報を独立したコレクションで管理する一方で、CQRSパターンを利用して読み書きの最適化を行うモデル
各方法ごとの比較評価
| 比較軸/手段 | 方法1 | 方法2 | 方法3 |
|---|---|---|---|
| データの整合性 | △ | ⚪︎ | × |
| セキュリティ | × | ⚪︎ | △ |
| データアクセスパフォーマンス | △ | △ | ⚪︎ |
| 実装の複雑さ | △ | ⚪︎ | × |
| 拡張性/柔軟性 | × | ⚪︎ | △ |
ここで、◯は良好、△は中等、×は不良を意味します。
以上の点を考慮し「分割ユーザーコレクションモデル」が最も適していると考えました。
評価の根拠は以下に書きました。
データの整合性
方法1:統合ユーザーコレクションモデル(単一ユーザーコレクション・サブコレクションモデル)
評価:「△」
統合ユーザーコレクションモデル(単一ユーザーコレクション・サブコレクションモデル)では、「いいね」の情報が各ユーザーのサブコレクションとして格納されます。そのため、同時に多数のユーザーが一つの記事に対して「いいね」を行うと、記事に対する総「いいね」数を算出する際に、各ユーザーのサブコレクションを全て走査する必要があります。
多くのユーザーが参加するシステムではこの操作は非常に時間がかかり、リアルタイムでの整合性を保つことが難しくなります。そのため、方法1ではデータの整合性が一部損なわれる可能性があるして△と評価しました。
方法2:分割ユーザーコレクションモデル
評価:「⚪︎」
分割ユーザーコレクションモデルでは、ユーザー情報が公開用と非公開用で分割されています。公開用データには全ユーザーからアクセス可能な情報が、非公開用データには個々のユーザーのみがアクセス可能な情報が格納されます。したがって、ユーザー間のデータアクセスの干渉が少なくなります。
さらに、「いいね」の情報も独立したコレクションとして保管されるため、各記事の「いいね」数の算出はこの一つのコレクションにアクセスするだけで可能となります。これによりデータの一貫性と整合性が高く保たれるため、データの整合性について⚪︎と評価しました。
方法3:CQRSベース分割ユーザーコレクションモデル
評価:「×」
CQRSベース分割ユーザーコレクションモデルではデータの整合性を保つのが困難です。CQRSベースの分割ユーザーコレクションモデルでは、データの書き込みと読み込みが別々に行われます。このため、書き込み後に読み込みが即座に最新のデータを反映しない場合があり、その間データの整合性が一時的に損なわれる可能性があります。また、更新処理中のエラー対応が複雑になり、データの整合性を保つのが難しくなります。
セキュリティ
方法1:統合ユーザーコレクションモデル(単一ユーザーコレクション・サブコレクションモデル)
評価:「×」
公開データと非公開データが一つのドキュメントに混在しており、不適切なアクセス設定により非公開データが公開される可能性があるため。
方法2:分割ユーザーコレクションモデル
評価:「⚪︎」
公開データと非公開データが別々のコレクションに保存されており、それぞれに適切なアクセス設定が可能であるため、非公開データの不適切な公開を防ぐことができます。
方法3:CQRSベース分割ユーザーコレクションモデル
評価:「△」
このモデルも公開データと非公開データを分けて管理しますが、書き込みと読み込みが異なるモデルを使用するため、両方のモデルの同期とアクセス制御を適切に行う必要がある。そのため、設定ミスや同期の問題から、データが不適切に公開される可能性があるためです。
データアクセスパフォーマンス
方法1:統合ユーザーコレクションモデル(単一ユーザーコレクション・サブコレクションモデル)
評価:「△」
非公開データと公開データが一緒に保存されているため、不要なデータも同時に読み込まれ、データアクセスパフォーマンスが低下する可能性があるため。
方法2:分割ユーザーコレクションモデル
評価:「△」
公開データと非公開データが別のコレクションに保存されていますが、それぞれのコレクションからデータを取得するため、2回のアクセスが必要になるため、パフォーマンスが低下する可能性があります。
方法3:CQRSベース分割ユーザーコレクションモデル
評価:「⚪︎」
読み取りモデルと書き込みモデルが別れており、読み取り専用モデルは最適化された形でデータを格納・取得することができます。したがって、データの取得速度が高速化され、パフォーマンスが向上します。
実装の複雑さ
方法1:統合ユーザーコレクションモデル(単一ユーザーコレクション・サブコレクションモデル)
評価:「△」
非公開データと公開データが一つのドキュメントに混在しているため、データの取扱いが複雑になる可能性があるため。
方法2:分割ユーザーコレクションモデル
評価:「⚪︎」
公開データと非公開データを分けて保存するシンプルな構造であり、実装が直感的であるため。
方法3:CQRSベース分割ユーザーコレクションモデル
評価:「×」
読み込みモデルと書き込みモデルを同期させる必要があり、またそれぞれのモデルに対して適切なアクセス制御を行う必要があるため、実装が複雑になる可能性があるため。
拡張性/柔軟性
方法1:統合ユーザーコレクションモデル(単一ユーザーコレクション・サブコレクションモデル)
評価:「×」
公開データと非公開データが一つのドキュメントに混在しているため、データ構造の変更が難しく、拡張性に乏しいと言えます。
方法2:分割ユーザーコレクションモデル
評価:「⚪︎」
公開データと非公開データが別々のコレクションに保存されているため、それぞれのデータ構造を独立して変更・拡張することが容易であり、柔軟性が高いです。
方法3:CQRSベース分割ユーザーコレクションモデル
評価:「△」
読み込みモデルと書き込みモデルを別々に持つため、それぞれの拡張が可能ではありますが、両モデルの整合性を保つための追加の労力が必要となります。したがって、柔軟性がある一方で、拡張の複雑さも増すと言えます。
参考
各方法ごとの比較評価をする際に、以下の書籍の「第5章 Firestore データモデリング」を参考にしました。
第5章の要約
Firebaseの運用では、小さなドキュメントとシンプルなセキュリティルールが推奨されます。リファレンス型を用いてドキュメント間の関連性を明示的に表現し、必要に応じて非正規化を活用します。ただし、読み取り頻度と更新頻度のバランスが重要です。
1:1リレーションは異なるコレクションに格納することで表現できます。また、リレーションの表現にはDocumentReferenceを活用します。
コレクションはドキュメントをまとめるために利用し、1対多のリレーションはサブコレクションやコレクショングループを使って表現します。サブコレクションは上位コレクションにアクセス頻度の高い情報を、下位のサブコレクションに従属情報を格納することで見通しを良くします。
複雑なドキュメントとセキュリティルールの管理にはCQRSの考え方が有効です。これにより、読み書きの責務を分けてデータモデル設計を効率化します。
だいぶ簡略化したので、正確な情報は実際の書籍を参考にしてください。
主に参考にした部分
分割ユーザーコレクションモデルの採用には、上記の書籍の中にあった、いくつかのポイントが影響を与えています。
「ドキュメントはシンプルで小さく保つことが望ましい。遅延読み込みが可能なデータはリファレンスだけを持たせ、実際のデータはクライアントサイドジョインで取得する。」(p83)
ユーザー情報を公開情報とプライベート情報に分けることで、ドキュメントが小さく保たれ、シンプルになります。
「結合 vs 正規化」(p92)
「いいね」情報を独立したコレクションで管理することで、データが一元管理(正規化)され、情報の一貫性が保たれます。また、特定のユーザーに関連する「いいね」情報だけを取得するシナリオでは、このモデルが有利となります。しかし、各「いいね」が頻繁に更新される場合、データ取得の効率と更新の頻度との間にトレードオフが生じます。
「いいね」情報を独立したコレクションで管理することで、非正規化が利用され、読み取りオペレーションの回数が減少します。しかし、データの更新頻度とのトレードオフも考慮に入れているため、「いいね」情報の更新が頻繁に発生する可能性がある場合には、このアプローチが最適です。
方法2:分割ユーザーコレクションモデルをテキスト形式で表現(図解)
userPublicProfiles/ (collection)
├─ userId1/ (document)
│ ├─ username
│ ├─ email
│ └─ ...
└─ userId2/ (document)
...
userPrivateProfiles/ (collection)
├─ userId1/ (document)
│ ├─ address
│ └─ ...
└─ userId2/ (document)
...
課題 4.「記事とそのいいね情報の分割の単位をどうするか?」
TL;DR
結論:「分割コレクションモデル」にした
本文
ここでは、Firestoreのデータモデリングにおける記事情報とユーザーの評価情報(いいね)をどのように保存するかについて評価軸を基に検討します。
やりたいこと
以下のことを実現しやすい設計を選択したい。
- あるユーザーが「いいね」した記事のリスト表示
- マイページで、特定のユーザーIDがいいねした記事一覧を表示させたい
- 記事を「いいね」したユーザーのリスト表示
評価軸
データモデリングを行うにあたり、以下の点を重視します。評価軸を大事にするものから先に書いてます。
- データ整合性
- パフォーマンス
- コードの可読性
- 拡張性
- スケーラビリティ
前提となる要件
- 同じデータは複数持たせず、リファレンスだけを持たせ、実際のデータはクライアントサイドジョインで取得する
- 記事データは基本的にmicroCMSからAPI経由で取得する
- 記事とユーザーの関連情報はFirestoreから取得します
予測できること
「いいね」の数は「記事」の数よりも増えやすいと予想します。なぜなら記事は運営者側しか作成できないので。
データモデリングの方法とその評価
便宜上、勝手に命名します。
パターン1:統合コレクションモデル(単一ポストコレクション・サブコレクションモデル)
「いいね」情報が各投稿のサブコレクションとして管理されているモデル
テキスト形式で表現(図解)
posts/ (collection)
├─ slug1/ (document)
│ ├─ likes (sub collection)
│ ├─ likesCount
│ ├─ slug
│ └─ title
└─ slug2/ (document)
パターン2:分割コレクションモデル
「いいね」情報が独立したコレクションとして平坦に管理されているモデル
テキスト形式で表現(図解)
posts/ (collection)
├─ slug1/ (document)
│ ├─ likesCount
│ ├─ slug
│ └─ title
└─ slug2/ (document)
...
postLikes/ (collection)
├─ likeId1/ (document)
│ ├─ userId
│ └─ postId
└─ likeId2/ (document)
パターン3:スラッグ基盤サブコレクションいいねモデル
各投稿のスラッグごとに「いいね」のドキュメントが作成され、それに紐づくサブコレクションとして「いいね」情報が管理されているモデル
テキスト形式で表現(図解)
posts/ (collection)
├─ slug1/ (document)
│ ├─ likesCount
│ ├─ slug
│ └─ title
└─ slug2/ (document)
...
postLikes/ (collection)
├─ slug1/ (document)
│ ├─ likes (sub collection)
│ │ ├─ likeId1/ (document)
│ │ ├─ userId
│ │ └─ postId
├─ slug2/ (document)
│ ├─ likes (sub collection)
│ │ ├─ likeId1/ (document)
│ │ ├─ userId
│ │ └─ postId
...
比較表
| 評価軸 | パターン1 | パターン2 | パターン3 |
|---|---|---|---|
| データ整合性 | ◯ 「いいね」の管理が各記事に紐付けられるため、整合性が保たれます。 | ◯ 「いいね」が独立したコレクションとして管理されるため、整合性が保たれます。 | ◯ 「いいね」が独立したコレクションとして管理され、記事ごとに分割されているため、整合性が保たれます。 |
| パフォーマンス | △ 特定ユーザーの「いいね」した記事リストを取得する際には全ての記事をスキャンする必要があるため、パフォーマンスに影響があります。 | △ 「いいね」が増えると、特定ユーザーまたは特定記事の「いいね」リストを取得する際にパフォーマンスが低下します。 | △ 記事が多くなると、特定ユーザーの「いいね」リストを取得する際のパフォーマンスが低下します。 |
| コードの可読性 | ◯ データ構造が直感的であるため、コードの可読性は高いです。 | ◯ 独立したコレクションとして「いいね」を管理することは、コードの可読性を高めます。 | △ 記事ごとに「いいね」コレクションが存在すると、コードの複雑性が増します。 |
| 拡張性 | ◯ 各記事に対する「いいね」が直接的に関連付けられているため、拡張性があります。 | ◯ 「いいね」を別のエンティティとして扱うため、拡張性が高いです。 | ◯ 記事ごとに「いいね」を管理することは、拡張性があります。 |
| スケーラビリティ | △ 記事数が増えると、特定ユーザーの「いいね」リストを取得する際のパフォーマンスが低下します。 | △ 「いいね」の数が増えると、パフォーマンスが低下します。 | △ 記事数が増えると、特定ユーザーの「いいね」リストを取得する際のパフォーマンスが低下します。 |
- データ整合性に関しては、どれも同点
- 同じデータが複数のドキュメントに存在しない設計ではある
- どの設計も一番大事にしている「データ整合性」の問題(ユーザーが"いいね"した後に自分のユーザー名を変更すると、"いいね"した記事に残るユーザー名が変更後のものにならないことが問題)は理論上起こり得ない設計にはなっている
- ただし全パターンともに「いいね」のカウントと「いいね」の具体的なデータ(ユーザーIDと記事ID)は分離しています
- そうした理由:記事ごとの「いいね」の数を素早く取得するため
- これら二つのデータを常に同期させるためにトランザクションを使用してFirestoreのデータを更新することで、データベースの一貫性を保とうとしています
- 同じデータが複数のドキュメントに存在しない設計ではある
- パフォーマンスに関して
- あるユーザーが「いいね」した記事のリスト表示の場合は、パターン2が優勢
- パターン1と3は、全ての記事(posts collection)をスキャンし、それぞれの記事に対してlikesサブコレクションを探索する必要があります。これは非常に高コストな操作となります。特に記事の数が多い場合やユーザーが多数の記事に「いいね」をしている場合、この操作は大量のリソースを消費します。...懸念①
- ある記事を「いいね」したユーザーのリスト表示の場合は、パターン1と3が優勢
- パターン2は、全postLikesコレクションをスキャンし、特定のユーザーIDまたは記事ID(slug)をもつドキュメントを探す必要がある...懸念②
- パターン1は、特定の記事ドキュメント(slug1など)内の「likes」サブコレクションにアクセスするだけで、「いいね」したユーザーのリストを取得できます
- パターン3では、「postLikes」コレクション内の特定の記事ドキュメント(slug1など)内の「likes」サブコレクションにアクセスするだけで、「いいね」したユーザーのリストを取得できます。
- あるユーザーが「いいね」した記事のリスト表示の場合は、パターン2が優勢
最終的にパターン2を選ぶ
理由:懸念②は工夫次第で解決できそうだから。
解決策は3つ候補がある
-
Firestoreに適切なインデックスをはる
- クエリ速度向上のため、'postId'にインデックスを設定。ただし、大量データ時のパフォーマンス制約が懸念(ちなみに、この対策は不要)
-
UI上の工夫
- 「いいね」リストが必要になるまでデータを取得しないことで、初期ロードパフォーマンスを改善。ただし、リスト表示時の遅延が問題
-
Next.jsのgetStaticPropsで静的レンダリング
- 「いいね」リストが頻繁に更新されない場合に有効。クライアントパフォーマンス改善のため、サーバーサイドでデータ取得・静的ページ生成。頻繁な更新で再生成が必要な場合は注意
Firestoreに適切なインデックスをはる対策は不要な理由
具体的には以下のセクションから確認できます
Single-field indexes
A single-field index stores a sorted mapping of all the documents in a collection that contain a specific field. Each entry in a single-field index records a document's value for a specific field and the location of the document in the database. Cloud Firestore uses these indexes to perform many basic queries. You manage single-field indexes by configuring your database's automatic indexing settings and index exemptions.Automatic indexing
By default, Cloud Firestore automatically maintains single-field indexes for each field in a document and each subfield in a map. Cloud Firestore uses the following default settings for single-field indexes:For each non-array and non-map field, Cloud Firestore defines two collection-scope single-field indexes, one in ascending mode and one in descending mode.
Firestoreが自動的に各ドキュメントの各フィールドにシングルフィールドインデックスを作成し、これらのインデックスを使って基本的なクエリを実行できることが分かります。具体的には、各非配列・非マップフィールドに対して昇順と降順の2つのコレクションスコープのシングルフィールドインデックスが作成されます。したがって、 'postId' というフィールドにも自動的にインデックスが作成されます。
なので、あとはUI上の工夫をすることで懸念①は抑えられると期待してパターン2を選ぶこととしました。
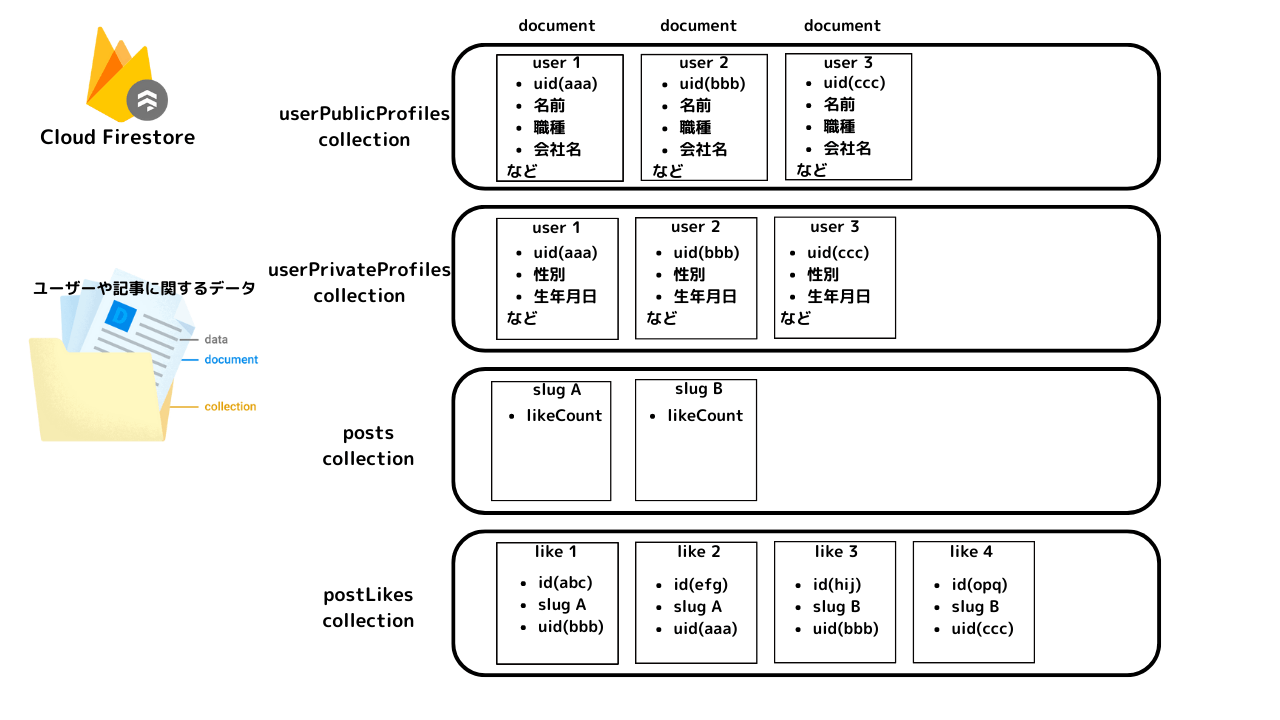
最終的なモデルをテキスト形式で表現(図解)
userPublicProfiles/ (collection)
├─ userId1/ (document)
│ ├─ username
│ ├─ email
│ └─ ...
└─ userId2/ (document)
...
userPrivateProfiles/ (collection)
├─ userId1/ (document)
│ ├─ address
│ └─ ...
└─ userId2/ (document)
...
posts/ (collection)
├─ slug1/ (document)
│ ├─ likesCount
│ ├─ slug
│ └─ title
└─ slug2/ (document)
...
postLikes/ (collection)
├─ likeId1/ (document)
│ ├─ userId
│ └─ postId
└─ likeId2/ (document)
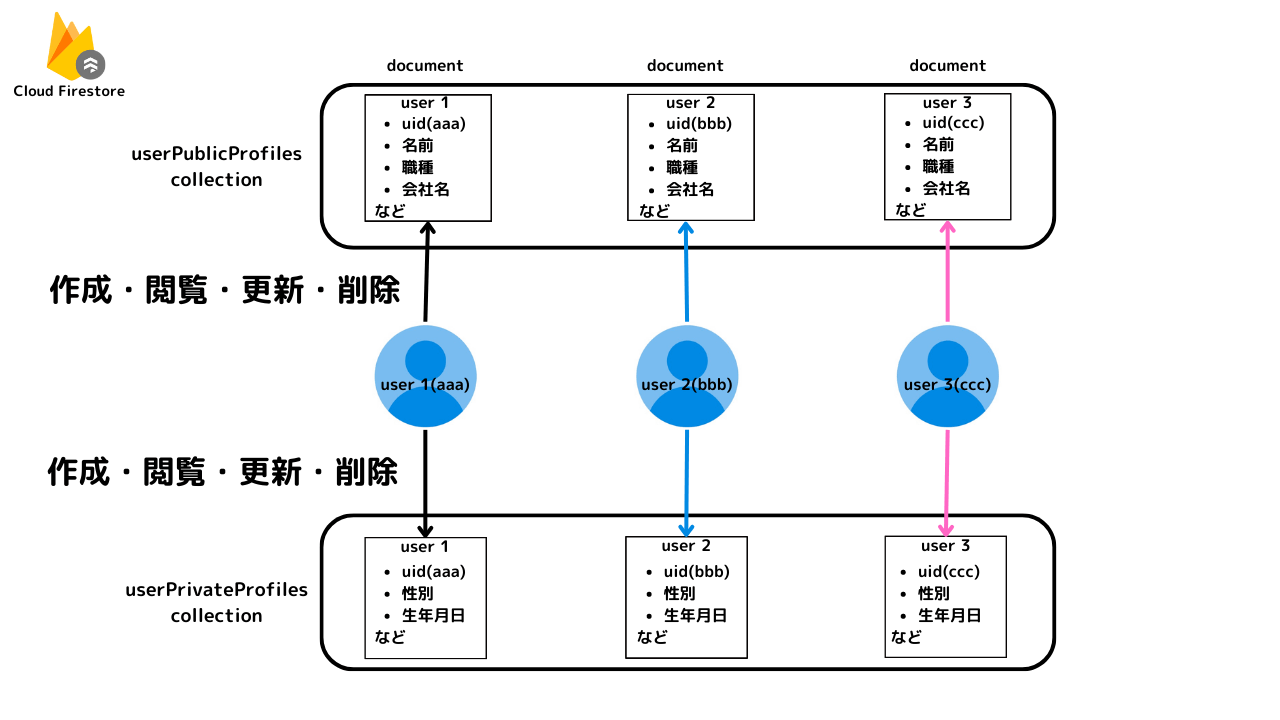
セキュリティルール
rules_version = '2';
service cloud.firestore {
match /databases/{database}/documents {
match /userPublicProfiles/{userId} {
allow read: if request.auth != null;
allow create, update: if request.auth != null && request.auth.uid == userId;
}
match /userPrivateProfiles/{userId} {
allow read, create, update: if request.auth != null && request.auth.uid == userId;
}
match /posts/{postId} {
allow read: if request.auth != null;
allow create, update: if request.auth != null;
}
match /postLikes/{likeId} {
allow read: if request.auth != null;
allow create: if request.auth != null && request.auth.uid == request.resource.data.userId;
allow delete: if request.auth != null && resource.data.userId == request.auth.uid;
}
}
}
これらのルールは以下のように解釈できます
userPublicProfiles/{userId}
- 読み取り:ログインユーザーに許可。
- 作成と更新:自分のIDであれば許可。
userPrivateProfiles/{userId}
- 読み取り、作成、更新:自分のIDであれば許可。
posts/{postId}
- 読み取り、作成、更新:自分のIDであれば許可。
必要であればここは下記のような対策が必要
FirestoreのセキュリティルールにおけるlikeCountの取り扱い
問題提起
Firestoreのセキュリティルールでは、posts/{postId}の作成・更新を全てのユーザーに許可する形になっています。これは投稿の作成や更新を通常、投稿者本人だけに制限すべき場合と異なります。ただし、全ユーザーにlikeCountの増減機能を許可する必要があるため、このような設定になっています。
取りうる解決方法
likeCountを直接データベースに更新する必要がある場合は、Cloud Functionsなどを使ってサーバーサイドで処理を行うことも検討できます。ユーザーが"like"アクションを行うと、そのアクションがトリガーとなり関数が実行され、サーバーサイドでlikeCountが安全に更新されます。ただし、このアプローチは追加のコストやセットアップの複雑さという考慮点を伴います。
メリット
- likeCountの取得が速く、フロントエンドロジックがシンプルに
デメリット
- サーバーサイド技術の使用による追加コスト
- 複雑なセットアップが必要
- 関数の実行失敗によるデータの不整合リスク
postLikes/{likeId}
- 読み取り:ログインユーザーに許可。
- "like"の作成・削除は"like"をするユーザー自身のみ。
モデル(図)
セキュリティルール(図)
やりたいことの実装
このスクラップでは、課題に対する最適な解決策を立てた上で下記の機能を実装することです。
懸念は一定克服できたので、このFirestoreの設計に沿ったデータ取得の実装を行ってみる。
「いいね」機能の実装
「自分が「いいね」した記事のリスト表示」
データ取得のイメージ
実装イメージ
import {
collection,
getDocs,
query,
where
} from 'firebase/firestore'
import { auth } from '@/lib/firebase/client'
const userId = auth.currentUser?.uid
useEffect(() => {
if (!userId) return
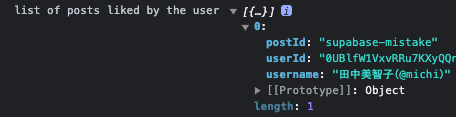
const fetchLikedPosts = async () => {
try {
const userLikesRef = collection(db, 'postLikes')
const userLikesSnapshot = await getDocs(query(userLikesRef, where('userId', '==', userId)))
const likedPosts = userLikesSnapshot.docs.map((doc) => doc.data())
console.log('list of posts liked by the user', likedPosts)
} catch (error) {
console.error('Failed to fetch liked posts:', error)
}
}
fetchLikedPosts()
}, [userId])
「記事を「いいね」したユーザーのリスト表示」
データ取得のイメージ
実装イメージ
import {
collection,
doc,
getDoc,
getDocs,
query,
where
} from 'firebase/firestore'
useEffect(() => {
const fetchLikingUsers = async () => {
try {
const postLikesRef = collection(db, 'postLikes')
const postLikesSnapshot = await getDocs(query(postLikesRef, where('postId', '==', postId)))
const likedUserIds = postLikesSnapshot.docs.map((doc) => doc.data().userId)
const userPromises = likedUserIds.map((userId) => {
const userDocRef = doc(db, 'userPublicProfiles', userId)
return getDoc(userDocRef)
})
const userSnapshots = await Promise.all(userPromises)
const likedUsers = userSnapshots.filter((snapshot) => snapshot.exists()).map((snapshot) => snapshot.data())
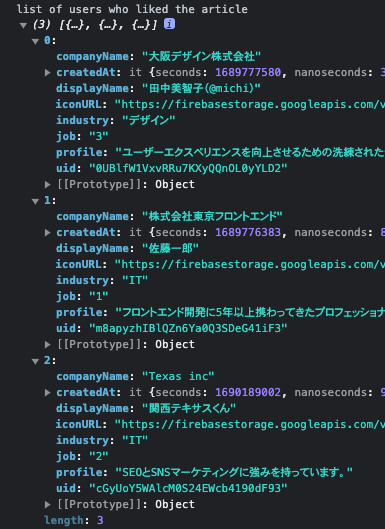
console.log('list of users who liked the article', likedUsers)
// `likedUsers` now contains the data for all users who have liked the current post
} catch (error) {
console.error('Failed to fetch users who liked the post:', error)
}
}
fetchLikingUsers()
}, [postId])
postIdはslug(string)