DynamoDB設計 キャッチアップ
記載するものはすべて引用。
キャッチアップ用
押さえておくべきDynamoDB設計(ベストプラクティス) まとめ
DB設計は必ずアクセスパターン(仕様)が決まってから着手すること
でないとDB設計根本から変更することになる
つまり運用は楽になるかもだけど、開発時に考え抜いて設計要
Primary Key
データはPartition Key(PK)、または PK と Sort Key(SK)の組み合わせで識別される。= Primary Key
テーブル数を少なく設計する。
テーブル数
少ないとキャパシティユニットを最適化できる
関連するデータをまとめとくと応答時間短縮に繋がる。←「参照の局所化」
設計が優れたアプリケーションでは、必要なテーブルは 1 つのみです。
インデックス設計
なのでアクセスパターン要件の洗い出しが完了するまでDynamoDB設計に取りかからない
GSIオーバーローディング
Query対象が増えた時のために1つのGSIに複数の検索要件を持たせる。
Composite Key (キーの結合)
より効果的なセカンダリインデックスキーを実現。
クエリを最適化したい場面で効果的。
注意点
- 外部結合ができないため複雑な検索がにがて
- PKは完全一致、ソートがSort Keyでないとできない
- 検索条件が増えるとその分のデータが増えることが多い
DynamoDB設計のちょっとした技
- 異なる用途で同じグローバルセカンダリインデックスを利用する
- 同じ検索方法(完全一致、部分一致、範囲指定)なら同じGSIを使う
- ソートキーに複合情報を持たせる
- データタイプ+日時など
- 前方一致で検索できる
- 無効なデータをインデックスせず、GSIのインデックスを小さく保つ
- ランキング上位5件とか
DynamoDBのテーブル設計に最適!NoSQL WorkbenchのData modelerで今度こそDynamoDBを使いこなす!
- 「NoSQL Workbench」を使うことで設計が正しいか検証可能
- ER図を作成する
- 多対多の関係なら「隣接関係のリスト設計パターン」
- 「ユースケース/アクセスパターン列挙->NoSQL Workbenchで設計->データ投入->検証->設計修正」のサイクルを何度か実施するのが効率良さそう
- 設計原則としてユースケースの洗い出しが重要
- LSIやGSIが必要なので重要
- NoSQL Workbentchを使用
- テーブル設計の作成
- 終わった後にはまる設計を構築するのに時間がかかる
【イチから理解するサーバーレスアプリ開発】 サーバーレスアプリケーション向きの DB 設計ベストプラクティス 20190905版
多対多の関係を管理するためのベストプラクティス
隣接関係のリスト設計パターン
- より一般的には、DynamoDB のグラフデータ (ノードとエッジ) を表現する方法
- 最上位エンティティ (グラフモデル内のノードと同義) はすべて、パーティションキーを使用して表現されます
- 他のエンティティとの関係 (グラフのエッジ) は、ソートキーの値をターゲットエンティティ ID (ターゲットノード) に設定することによって、パーティション内の項目として表現
- メリット
- ターゲットエンティティ (ターゲットノードへのエッジを含む) に関連するすべてのエンティティ (ノード) を見つけるために重複データを最小限に抑えられること
- クエリパターンを簡素化できる
マテリアライズされたグラフパターン
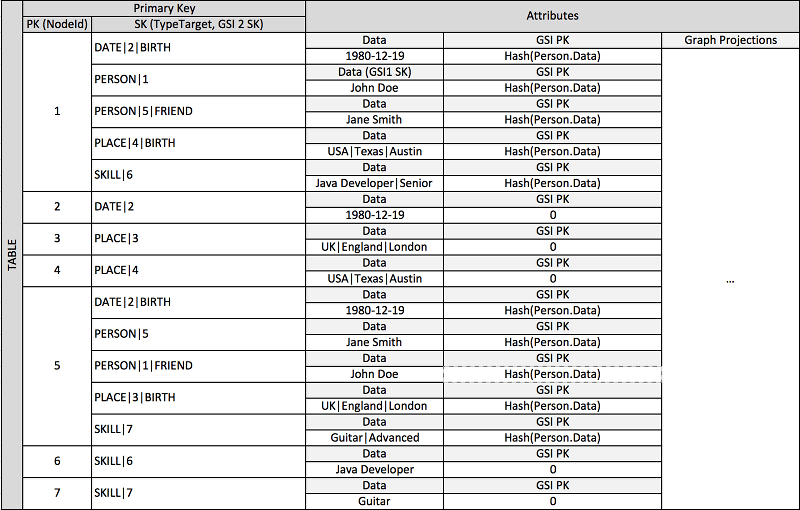
DynamoDBで多対多のテーブル設計
-
上のドキュメントの補足
-
ユーザーとグループをDynamoDBで実現する例
-
Adjancy List Design Pattern(隣接リストパターン)
- PK=SK(GSI-PK)=user_idのとき、ユーザーを示す。
- PK=SK(GSI-PK)=group_idのとき、グループを示す。
- PK=user_id, SK(GSI-PK)=group_id のとき、user_idに所属するグループを示す。
- つまり、group_idに所属するuser_idの数だけ冗長である
-
クエリが簡単になる
- PK=SK=user_id としてget_itemしたら良い。任意のグループの詳細情報であれば、PK=SK=group_id
DynamoDB でリレーショナルデータをモデル化するための最初のステップ
- DynamoDB の場合は答えが必要な質問が分かるまで、スキーマの設計を開始しないでください。ビジネス上の問題とアプリケーションのユースケースを理解することが極めて重要
- 設計の手順
- 新しいアプリケーションの場合は、アクティビティや目的に関するユーザーストーリーを確認します。特定するさまざまなユースケースを文書化し、必要なアクセスパターンを分析
- 既存のアプリケーションでは、クエリログを分析して、ユーザーが現在どのようにシステムを使用しているか、主要なアクセスパターンを調べます。
- 本番環境で見つかる可能性のあるクエリパターンの複雑さの範囲を表します
DynamoDB 用の NoSQL
- テーブルの数が少なくなると、スケーラビリティが向上し、必要なアクセス権限の管理が少なくなり、DynamoDB アプリケーションのオーバーヘッドが削減されます。また、バックアップコストを全体的に低く抑えるのにも役立ちます。
改めてDynamoDBのテーブル設計を考える
- 用途によっては無理に1つのテーブルにまとめなくてもいいんじゃない?
- SQL一応使える
書籍「RDB技術者のためのNoSQLガイド」
- 書店ではNoSQLの書籍が見つからなかった
- 2016年の書籍で古さが気になる
- もしWebの記事で足りなかったら読むかも
DynamoDBのテーブルを1つだけにする設計のコツ(考え方編)
- テーブル設計の例
DynamoDBのスキーマ設計について学んだこと
DynamoDB の設計について考えてみる。
- DynamoDBのモデリングプロセス
- 業務分析とデータモデリング
- アクセスパターン設計
- TableとIndex設計
- クエリ条件設計
- 追加条件が生じたら?
- サービスに合わせてテーブル・インデックス設計を変更
- 他のサービスと連携する
Amazon DynamoDB のテーブル設計で悩んだら最初に読もう -これだけ知ればある程度の検索には対応できる-
- ローカルセカンダリインデックスは初回構築時にしか設定できない
- 1つのテーブルにつき5つまで
AWS DynamoDBの設計で「サーバーレスアプリケーション向きの DB 設計ベストプラクティス」を実践する
RDB設計者のための DynamoDB の解説!開発経験者が語る DynamoDB 設計入門🤔
DynamoDB の設計について
NoSQL初心者のためのDynamoDBデータ構造
DynamoDBのテーブル設計どうやってるのか雰囲気掴みたい