CoreMLでの推論結果に使われるVNObservationクラスについて
このページでわかること
- CoreMLで推論を行った結果はVNObservationに準拠したクラスに格納されるよ
- 機械学習のタスクによって格納されるクラスが変わるよ
- Appleが公式で公開されている学習済みモデルでそれぞれどのクラスを使えばいいか分かるよ
前提:CoreMLについて
Appleの機械学習フレームワークです。2017年に発表されて以来、さまざまな機能の拡張が行われていて、AI機能を搭載したアプリに使われています。
GPUを搭載しているマシンとデータセットを使って、特定の機械学習タスクの学習を行なった結果のモデルを学習済みモデルといいます。CoreMLで読み込ませることができる学習済みモデルはmlmodel(mlPackage)というフォーマットにする必要があるのですが、これはCoreMLToolsを使って学習済みモデルを変換したり、XcodeにバンドルさせているCreate MLを使って学習を行うことで用意することができます。
つまり、CoreMLはすでに学習済みのモデル(mlmodelやmlPackage)を読み込んで、さまざまなアプリで学習必要なしにAI機能を使うことができる、というわけです。
VNObservationクラスについて
VNObservationクラスは、Visionフレームワークに含まれています。
このクラスを継承したクラスとして、各機械学習タスクの結果を格納するサブクラスがあります。
一方VNObservationのプロパティとしては、どの機械学習タスクでも使われる汎用的なプロパティが用意されています。
*/
@available(iOS 11.0, *)
open class VNObservation : NSObject, NSCopying, NSSecureCoding, VNRequestRevisionProviding {
/**
@brief The unique identifier assigned to an observation.
*/
open var uuid: UUID { get }
/**
* @brief The level of confidence normalized to [0, 1] where 1 is most confident. The only exception is results coming from VNCoreMLRequest, where confidence values are forwarded as is from relevant CoreML models
* @discussion Confidence can always be returned as 1.0 if confidence is not supported or has no meaning
*/
open var confidence: VNConfidence { get }
/**
* @brief The duration of the observation reporting when first detected and how long it is valid.
* @discussion The duration of the observation when used with a sequence of buffers. If a request does not support a timeRange or the timeRange is not known, the start time and duration will be set to 0.
*/
@available(iOS 14.0, *)
open var timeRange: CMTimeRange { get }
- UUID:結果を区別するためのID
- confidence:機械学習モデルが回答を出すに至った信頼度
- timeRande:回答を出力するまでの時間
の3つが含まれています。
モデルのロードからVNObservationへ結果の格納の流れ
学習済みモデルをロードしてから推論実行までの流れはとてもシンプルです。
Visionフレームワークをimportして、いくつかのオブジェクトを用意します。
ロード
let model: VNCoreMLModel
private init() {
// mlmodelの場合
self.model = try! VNCoreMLModel(for: YOLOv3TinyInt8LUT(configuration: .init()).model)
// mlpackageの場合
self.model = try! VNCoreMLModel(for: DepthAnythingV2SmallF16P6().model)
}
推論
VNCoreMLRequestはロードしたモデルに入力する時に使うオプションを設定します。
モデルに入力する実データは画像を例にするとVNImageRequestHandlerを初期化する時にセットします。
VNImageRequestHandlerがperformメソッドを実行すると推論が始まって、その結果は自身のresultプロパティに格納されます。
let request = VNCoreMLRequest(model: model)
request.preferBackgroundProcessing = true
request.imageCropAndScaleOption = .centerCrop
let handler = VNImageRequestHandler(cgImage: input)
try! handler.perform([request])
// このresultはVNObservationに準拠したクラスのいずれか
if let result = request.results?.first {
// 結果を利用
...
}
受け取った結果を元に、結果の情報を処理してUIに返却します。
VNObservationを継承したクラス
VNObservationを継承したクラスは、各機械学習タスクの結果の情報を全て格納するために、それぞれ個別のプロパティが用意されています。
例えば画像内に写っている物体が何かを判別するタスク(分類タスク)は、あらかじめ回答群となる単語リストの中からモデルが「これだ!」と決定するので、決定した単語に対応する単語リストのindexの値が必要です。
物体検出(画面内のどこに、何があるか判別する)タスクでは上記のindexの値のほかに、四角で囲う座標の情報を格納する必要がありますし、画像生成タスクでは生成した画像の多次元配列(width,height,b,g,r)を格納するプロパティが必要です。
そのため、各タスクでそれぞれのプロパティを持ったクラスを用意して格納する必要があります。
ここでは、そのうちのいくつかのクラスを説明します。
①VNDetectedObjectObservation
画像分類(Image Classificaion)をはじめとした検出系で使われるクラスの親元です。
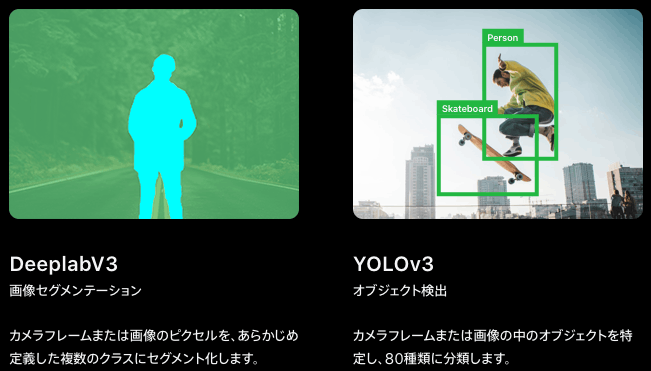
ここでは四角(BoundingBox)で囲う座標やセマンティックセグメンテーション(下記画像参照)で検出した物体を分類するためのVNPixelBufferObservationが格納されています。
/*!
@class VNDetectedObjectObservation
@superclass VNObservation
@brief VNDetectedObjectObservation is VNObservation in an image that has a location and/or dimension. Further attributes depend on the specific detected object.
@discussion All result objects (faces, scene objects, shapes etc) must extend from this class.
*/
API_AVAILABLE(macos(10.13), ios(11.0), tvos(11.0))
@interface VNDetectedObjectObservation : VNObservation
/*!
@brief create a new VNDetectedObjectObservation with a normalized bounding box and a confidence of 1.0.
*/
+ (instancetype)observationWithBoundingBox:(CGRect)boundingBox;
+ (instancetype)observationWithRequestRevision:(NSUInteger)requestRevision boundingBox:(CGRect)boundingBox API_AVAILABLE(macos(10.14), ios(12.0), tvos(12.0));
/*!
@brief The bounding box of the detected object. The coordinates are normalized to the dimensions of the processed image, with the origin at the image's lower-left corner.
*/
@property (readonly, nonatomic, assign) CGRect boundingBox;
/*!
@brief The resulting CVPixelBuffer from requests that generate a segmentation mask for the entire image.
*/
@property (readonly, nonatomic, nullable) VNPixelBufferObservation * globalSegmentationMask API_AVAILABLE(macos(12.0), ios(15.0), tvos(15.0));
@end
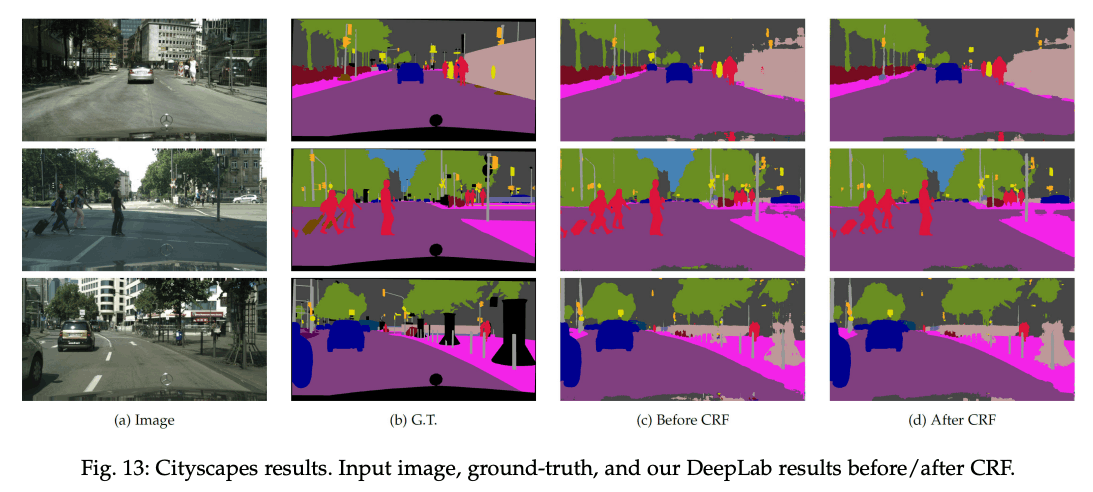
セマンティックセグメンテーションの実行例
(DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs より引用)
②VNRecognizedObjectObservation
VNDetectedObjectObservationを継承した、検出した物体が何だったかを格納するプロパティを含むクラスです。
/**
@class VNRecognizedObjectObservation
@superclass VNDetectedObjectObservation
@brief VNRecognizedObjectObservation is a VNDetectedObjectObservation with an array of classifications that classify the recognized object. The confidence of the classifications sum up to 1.0. It is common practice to multiply the classification confidence with the confidence of this observation.
*/
@available(iOS 12.0, *)
open class VNRecognizedObjectObservation : VNDetectedObjectObservation {
open var labels: [VNClassificationObservation] { get }
}
このプロパティlabelsは、検出対象の物体リストの中から一番それっぽい物体から先頭に並んでいるリストです。なのでこのリストの先頭3つを取得したら画像に写っている可能性が高い3つの単語が得られます。
case let detection as VNRecognizedObjectObservation:
let labels: [VNClassificationObservation] = detection.labels
let top3Labels: [VNClassificationObservation] = Array(detection.labels[0..<2])
③VNPixelBufferObservation
結果を画像として受け取る時に使うクラスです。カメラの読み込みなどで使われるCVPixelBufferで受け取ります。
/**
@class VNPixelBufferObservation
@superclass VNObservation
@brief VNPixelBufferObservation returns the prediction of a model as a CVPixelBufferRef.
@discussion This is the returned observations for models that are not classifiers and return an image as a prediction. The confidence for these observations is always 1.0.
*/
@available(iOS 11.0, *)
open class VNPixelBufferObservation : VNObservation {
/**
@brief The resulting image from a request like VNCoreMLRequest where the model produces an image as an output.
*/
open var pixelBuffer: CVPixelBuffer { get }
/**
@brief The name used in the model description of the CoreML model that produced this observation allowing to correlate the observation back to the output of the model. This can be nil if the observation is not the result of a VNCoreMLRequest operation.
*/
@available(iOS 13.0, *)
open var featureName: String? { get }
}
④VNCoreMLFeatureValueObservation
ほとんどの学習済みモデルは出力結果を数ステップでUIに表示できるレベルにするモデルが多いですが、機械学習のネットワークの途中にある多次元配列をそのまま出力するモデルもあります。
多次元配列で表現しているデータをそのまま画像で保存したり、多次元配列のデータを別の学習済みモデルに入力したり、多次元配列のまま一旦保存したりとさまざまな用途があります。
多次元配列のデータそのものは、MLFeatureValueのプロパティmultiArrayValue: MLMultiArrayに保存されます。
/**
@class VNCoreMLFeatureValueObservation
@superclass VNObservation
@brief VNCoreMLFeatureValueObservation returns the prediction of a model as an MLFeatureValue.
@discussion This is the returned observations for models that are not classifiers and that do not return an image as a prediction. The confidence for these observations is always 1.0.
*/
@available(iOS 11.0, *)
open class VNCoreMLFeatureValueObservation : VNObservation {
/**
@brief The result VNCoreMLRequest where the model produces an MLFeatureValue that is neither a classification or image. Refer to the Core ML documentation and the model itself for the handling of the content of the featureValue.
*/
@NSCopying open var featureValue: MLFeatureValue { get }
/**
@brief The name used in the model description of the CoreML model that produced this observation allowing to correlate the observation back to the output of the model.
*/
@available(iOS 13.0, *)
open var featureName: String { get }
}
Appleが公開している各学習済みモデルはどのクラスを使うか
Appleの学習済みモデル一覧ページでは、学習済みでCoreMLを使ってロードできるモデルが公開されています。
しかしモデルを使って推論をした結果を指定したクラスに格納することはできず、モデルがあらかじめ指定したクラスに格納されてしまいます。
以下に確認ができている、各モデルが使うクラスを一覧にします。(随時更新中)
| 手法名 | モデルについて | 格納時に使うクラス |
|---|---|---|
| YOLOv3 | オブジェクトの領域を検出して識別する | VNRecognizedObjectObservation |
| DeeplabV3 | オブジェクトの領域をピクセル単位で検出して分類する | VNCoreMLFeatureValueObservation |
| Depth Anything V2 | 単眼カメラで撮影された画像の奥行きを推定する | VNPixelBufferObservation |
| FastViT | 画像中の主要なオブジェクトを分類する | VNClassificationObservation |
どうやって調べる?
地道にデバッグで調べています。
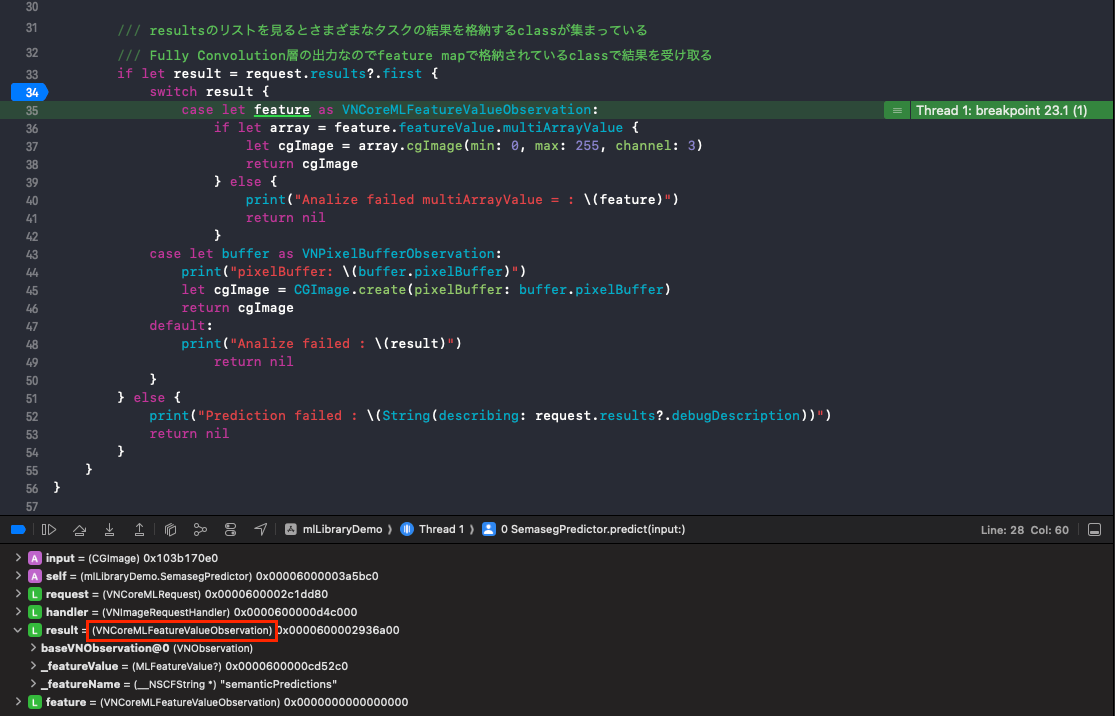
VNCoreMLRequestのプロパティrequest.results?.firstのTypeを調べると、どのクラスを使って結果が格納されているかを知ることができます。
学習済みモデルをダウンロードしてXcodeで見てみるとメタデータは確認できますが、どのクラスを使うかは書いてありません...
DeeplabV3のモデルより
まとめ
この記事ではCoreMLを使ったモデルの推論結果が格納される、VNObservationとVNObservationに準拠したクラスについて説明しました。
また、Appleの機械学習モデルも含めCoreMLで推論した結果はどのクラスに格納されるか分からないので、実際に動かしてみていくつかのモデルがどのクラスに格納されるかをまとめました。
機械学習モデルを使ったアプリを作る方はまず間違いなくこのクラスにお世話になると思うので、よりこの記事で理解を深めてもらえたら幸いです。
Apple Intelligenceで汎用モデルが出てくる前に、まずはこの辺りの公開されているモデルで遊んでみてはいかがでしょうか?
Discussion