DataSpider(Dr.Sum Connect)でSalesforce API タイムアウトを乗り越える
前に、ConnectからSalesforceのデータを抽出して、Dr.Sumに取り込む方法を紹介しました。
上記の記事の方法でデータが取得できるようになるのですが、クラウド製品によくあるタイムアウトエラーにひっかかることがあります。
実際のエラーはこちらです。
SalesforceのAPIがエラーを返しました。エラーコード:[QUERY_TIMEOUT] エラーメッセージ:[Your query request was running for too long.]
メッセージコードSALESFORCE0010E
[get_data(クラウド/Salesforce/データ読み取り(クエリー))]の処理に失敗しました。原因:[[UnexpectedErrorFault [ApiFault exceptionCode='QUERY_TIMEOUT'
exceptionMessage='Your query request was running for too long.'
extendedErrorDetails='{[0]}'
抽出するデータの件数やカラム数が多かったり、Salesforce側で他の処理が忙しかったりすると発生します。
やっかいなのは
・正常に処理ができる
・タイムアウトエラーになる
これが気まぐれなんですね。
自テナントでSalesforce使っていないであろう夜中に処理をしてもエラーになる時があるのです。
ETL屋さんとして、見過ごせません。
今回はこのタイムアウトが発生しても夜間処理を成功させるスクリプトの作り方を解説します。
解決策は複数回のスクリプト実行
まずは取得するデータ量を調整してみましょう。
対応策はこちらです。
・オブジェクト内の全データではなく、[最新1週間以内]など抽出範囲を限定する
・分析に必要なカラムだけを選んで取得する
これでタイムアウトが解決できたら、万歳です。
しかし悲しいことに、いろいろ手は尽くしてみたのですが、ウチの環境ではタイムアウトが出続けています。
夜間であれば3回に一度は成功する確率です。
そこでタイムアウトを容認する、エラー前提の処理を作ることにしました。
夜間に複数回処理をする機構をつくる
タイムアウトエラーをしても、処理を繰り返し、朝までに一度でも成功すればOK、というスクリプトを作りました。
現在、対象のオブジェクトは4つですが、30分に一度、スクリプトを動かし、まだデータ取り込みに成功していないオブジェクトは処理をするという流れになります。
処理の流れは下図になります。
まずはトリガーとなるスクリプトです。
02のIntervalBatch_Salesforceに今回の機構を入れております。
夜間に10回スクリプトは実行されます。

IntervalBatch_Salesforceのスクリプトの詳細です。
ここではログに情報を出力しながら、孫スクリプトを呼び出しています。

孫スクリプトのひとつ[SF_ユーザー_User]スクリプトです。
注目すべきは枠を囲ったところです。
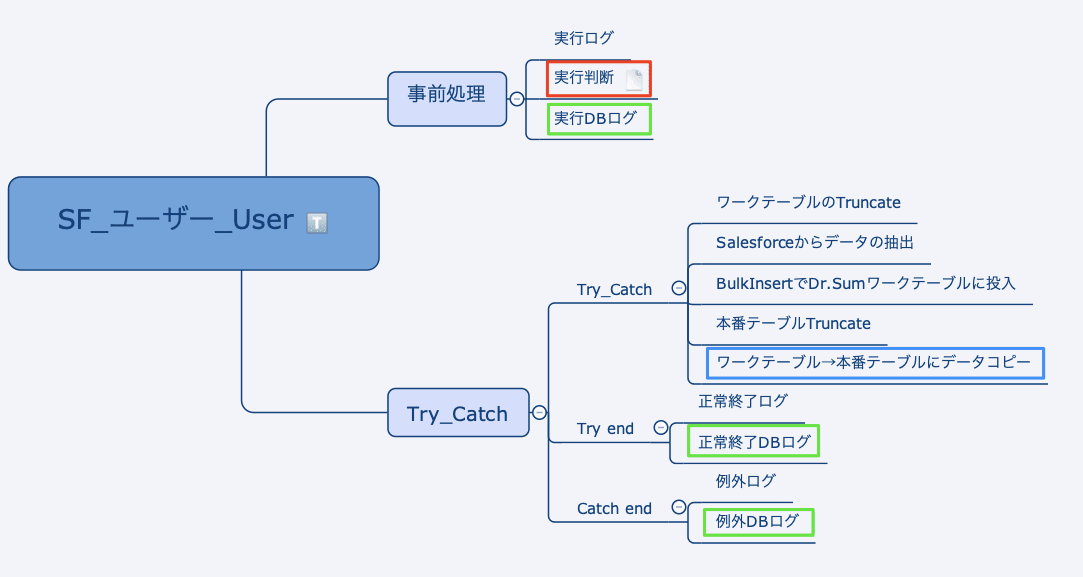
| 枠 | 意味 |
|---|---|
| 青 | ワークテーブルをつかう |
| 緑 | DBのイベントログを更新する |
| 赤 | DBのイベントログを実行判断をする |
この枠囲いのところが、複数回スクリプトを回す処理で重要なところです。
ひとつずつ解説をしていきます。
ワークテーブルをつかう
データロードを高速にするためにBulkInsertをつかっています。
データ取り込み前にTruncateをしているので、タイムアウトエラーになると、テーブルは0件になってしまいます。
今回はタイムアウトエラーが起きる前提なので、本番テーブルが0件になるのはマズイです。
そのため、処理はワークテーブルをつかうようにします。
DBのイベントログを更新する
こちらは実行判断をするための準備です。
各孫スクリプトの処理が成功しているか否かをDBに記載します。
そのため、Dr.Sumに[ETL_EventLog]テーブルを作成しています。
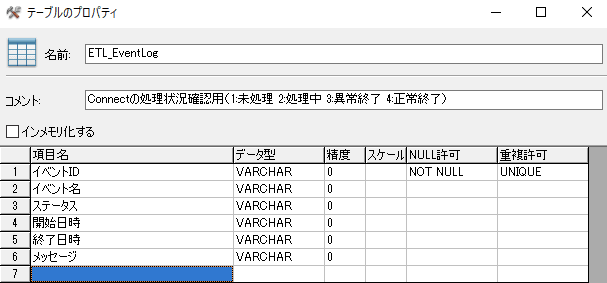
CREATE TABLE ETL_EventLog (
イベントID VARCHAR NOT NULL UNIQUE,
イベント名 VARCHAR,
ステータス VARCHAR,
開始日時 VARCHAR,
終了日時 VARCHAR,
メッセージ VARCHAR);
ALTER TABLE ETL_EventLog MODIFY COMMENT 'Connectの処理状況確認用(1:未処理 2:処理中 3:異常終了 4:正常終了)';
テーブルのコメントに記述している[ステータス]カラムが重要です。
1:未処理 2:処理中 3:異常終了 4:正常終了
イベントIDが001から004までが孫スクリプトです。
後述する実行判断で、処理実行が決定しましたら、該当イベントの項目をUPDATEします。
実行ログ
UPDATE ETL_EventLog
SET
ステータス = '2',
開始日時 = '${タイムスタンプ}',
メッセージ = '処理を開始します。'
WHERE
イベントID = '${実行スクリプトID}'
正常終了ログ
UPDATE ETL_EventLog
SET
ステータス = '4',
終了日時 = '${タイムスタンプ}',
メッセージ = '正常終了しました。'
WHERE
イベントID = '${実行スクリプトID}'
例外ログ
UPDATE ETL_EventLog
SET
ステータス = '3',
終了日時 = '${タイムスタンプ}',
メッセージ = '${エラーメッセージ}'
WHERE
イベントID = '${実行スクリプトID}'
このイベントログはETLをつくる上で必須ととらえて良いと思います。
これとは別にテキストへのログ出力も行いますが、テーブルを見ればすぐに状況がわかるというところが、運用面で大変好都合です。
余談ですが、もっと運用しやすくするために、トランザクション型のログも用意しようと考えています。
そうするとどのオブジェクトは平均何回で取り込みしている、などのタイムアウトの分析もできるようになりますね^^
DBのイベントログを実行判断をする
いよいよ実行判断処理についてです。
夜間で10回スクリプトを流すとお伝えしましたが、毎回取り込みをしていると、Salesforce側にも負荷がかかりますし、スマートじゃないですね。
そのため、孫スクリプトは必ず処理判断を行うようにします。
孫スクリプトの最初ではこの実行判断処理を呼び出します。
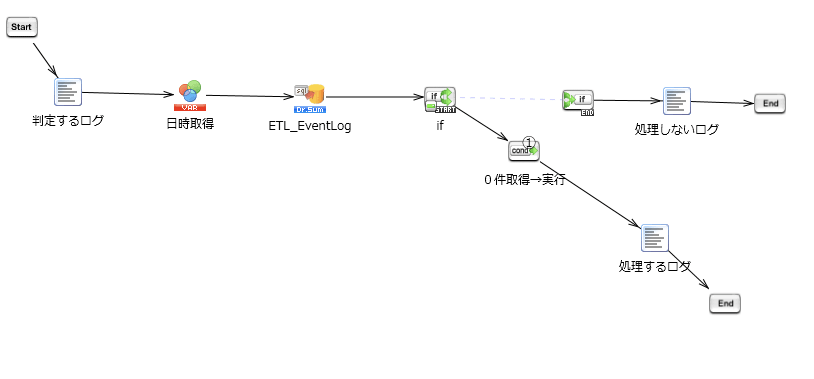
処理判断は[ETL_EventLog]テーブルでこちらの条件を入れています。

1.最後に処理をしてから6時間以上経過している
2.最後の処理が"未処理"または"異常終了"
これが夜間のうちに一度でも処理が成功するまで、スクリプトを流すロジックになります。
0:00の初回処理では、前回処理より6時間経っているので、処理を行います。
初回処理で正常終了すると、ステータスが正常終了となり、開始日時も0:00になるので、その日の処理対象からは外れます。
初回処理で異常終了すると、ステータスが異常終了となり、開始日時も0:00になるので、次回の処理対象となります。
仮に処理をしている途中で、次のスクリプトが処理判断をしに来ても、ステータスが処理中なので、その日の処理対象からは外れます。
このような処理分岐となります。
SQLはこちらです。
SELECT
ETL_EventLog.ステータス,
ETL_EventLog.開始日時
FROM
ETL_EventLog
WHERE
ETL_EventLog.イベントID ='${実行スクリプトID}' AND
ETL_EventLog.終了日時 >'${現在日時よりn時間マイナス}' AND
(ETL_EventLog.ステータス ='4' OR
ETL_EventLog.ステータス ='2')
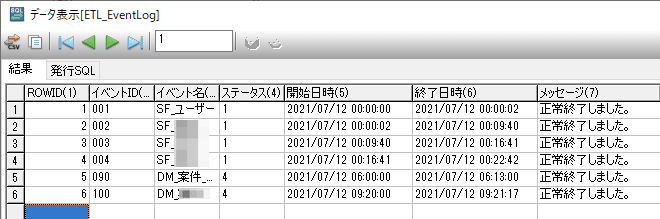
この処理分岐を行って、30分間隔でスクリプトを実行すると、下図のような形となります。

001から004がSalesforceのオブジェクトです。
001と003は一発成功です。
002は0:00、0:30、1:00と3回タイムアウトエラーを起こし、4回目の1:30で処理が成功しています。
004は0:00、0:30と2回タイムアウトエラーを起こし、3回目の1:00で処理が成功しています。
このロジックを作って2週間くらい回していますが、まだ4回連続エラーの壁は超えたことはありません。
今日も元気に動いております。
最後に
今回はSalesforceが対象ですが、クラウド系にAPI接続する仕組みだと、タイムアウトは避けられない問題となります。
タイムアウトを起こさないようにする工夫の他に、このような処理を組み込んでみるとよいですね。
参考になれば幸いです。
Discussion