GPT-5時代の「大規模言語モデル(LLM)」超入門
はじめに
なぜ今LLMを学ぶ必要があるのか?
「AIが書いた文章」「AIが作ったイラスト」といったニュースが日常となり、ChatGPTのような 大規模言語モデル(以下LLM) は私たちの生活や仕事に深く浸透しました。
多くの人が「便利」と感じる一方で、その裏側で何が起きているのか。
なぜこれほど賢く振る舞えるのか、その「魔法」の正体はまだ謎に包まれています。
GPT-5のような最新モデルが次々と登場し、その進化のスピードはとどまることを知りません。
AIの進化は、単に仕事を効率化するだけでなく、ビジネスのあり方そのものを根本から変えようとしています。
この記事では、LLMが 「なぜ、どうやって」 動いているのかを解き明かします。
そして、この「魔法」を使いこなすことが、ビジネスパーソンにとってなぜ不可欠なのかをお伝えします。
LLMはどうやって「賢さ」を生み出しているのか?
まずLLMの基礎的な定義を理解しましょう。
LLMとは何か?
LLMはLarge Language Modelの略で、従来のAIや言語モデルと比較して、膨大なテキストデータから学習し、人間が使う自然な言語を高度に理解・生成・分析する能力を持つモデルです。
単なる情報の検索やパターン認識だけでなく、文脈に応じた対話や文章の要約、創造的なコンテンツの生成、プログラミングのコード生成ができます。
LLMの仕組みについて
LLMが自然な言語を理解し、生成を行うプロセスは、人間が言葉を扱うプロセスとは根本的に異なります。
LLMにおけるAIの「思考」プロセスは、
1. 言語をコンピュータが扱える数値に変換
2. 数値データを処理
といったアーキテクチャ(設計)によってLLMの知的能力の根幹を築いています。
言語をコンピュータが扱える数値に変換
人間が文章を理解するのと同じように、LLMもまず言葉を小さな単位に分解します。
1. トークン化
文章をAIが理解できる最小単位の「トークン」に分割する工程です。
英語では単語や句読点、日本語では文節がトークンとして扱われ、それぞれが一意のID(認識番号) に変換されます。
この数値化は、AIが膨大なテキストデータを効率的に取り扱うために不可欠な処理です。

2. 埋め込み
トークン化されたIDは、さらに「埋め込み(Embedding)」というプロセスを経てベクトルに変換を行います。
この埋め込み(Embedding)とは、テキストをコンピューターが理解しやすい「数字のリスト」 に変換する技術です。
この数字のリストは単なる識別子ではなく、それぞれの単語が持つ「意味」や、他の単語との「関係性」を数学的に表現しています。
-
例えば、以下の数式を見てみましょう
E(「王様(男性・支配者)」)−E(男性)+E(女性)≈E(「女王様(女性・支配者)」)
この数式は「王様(男性・支配者)」から「男性」という要素を抜き取って「女性」という要素を足すと、「女王様(女性・支配者)」になる、ということを数学的に表現しています。
この技術のおかげで、LLMは単語の表面的な並びだけでなく、言葉の裏にある「意味の繋がり」を捉えることができ、人間が持つ言語のニュアンスや文脈を理解する基盤を築いています。
文脈理解の鍵となる「脳」の仕組み
LLMが驚くほど自然な文章を生成できるのは、単語の意味だけでなく、文章全体の文脈を正確に捉えるこ能力を備えているからです。
Attentionメカニズム
LLMが入力データ内で「重要な部分に焦点を当てる」ことを可能とする仕組みです。
通常人間が文章を読む際には、重要なキーワードや文脈に注意がいくと思います。
これと同じように、膨大な情報から関連性の高い部分を見つけ出すといったことを可能としたメカニズムです。
Attentionの計算は、Query(クエリ)、Key(キー)、Value(バリュー)という3つのベクトルをもとに行われています。
-
Query(Q)
- 現在のタスクや探している「問いかけ」を表すベクトルです。
-
Key(K)
- 探索対象となる入力データの各要素の「識別子」や「見出し」を表すベクトルです。
-
Value(V)
- 探索対象の各要素が持つ「内容」や「実際の情報」を保持するベクトルです。
| 要素 | 役割 | 例 |
|---|---|---|
| Query(Q) | 探している情報、問いかけ、現在の文脈を表す | 質問:「りんごはどんな味ですか?」 |
| Key(K) | 探索対象となる情報の「見出し」「識別子」 | 応答候補の見出し:「りんごの味」 |
| Value(V) | 探索対象の情報に含まれる「内容」 | 応答候補の内容:「甘くて酸っぱい」 |
仕組みを簡単に解説
Attentionのプロセスは、大きく3つのステップに分けられます。
1. 関連性を見つける
モデルは「今知りたいこと」(Query)と、文章中にあるそれぞれの単語(Key)との関連性を計算します。
この関連性が高いほど、その単語は重要と判断されます。
2. 重要度の決定
関連性の計算後、モデルはそれぞれの単語に**「注意の重み」**を割り当てます。
この重みは、単語の重要度を数値で表したものです。
3. 重要な情報を集約する
最後に、モデルはそれぞれの単語に重みを掛け合わせて足し合わせます。
これにより、重要度の高い単語ほど大きく反映され、重要度の低い単語はほとんど無視されることになります。
この重み付けされた合計が、現在のタスクに最も関連性の高い情報だけが凝縮された 「コンテキストベクトル」 となり、次の処理に送られます。
簡単に言えば、「文章全体の中から、最も必要な情報だけを選び出し、それをまとめて次のステップに渡す」 プロセスです。
この仕組みがあるからこそ、LLMは長文の中からでも、文脈を正確に捉えることができるのです。
Attentionの進化
ただAttentionにも一つの弱点がありました。
それは、単語の「順番」を無視してしまうことです。
Attentionはすべての単語を同時に処理するため、例えば 「彼が彼女を好き」と「彼女が彼を好き」 のように、同じ単語が使われていても、単語の順番によって意味が全く異なるような文を区別できません。
この問題を解決するために登場したのが、「位置エンコーディング(Positional Encoding)」と呼ばれるものです。
位置エンコーディングは、単語の元々の位置情報を特別な数字のリスト(ベクトル)として表現し、その情報を単語自体の情報に付け加えます。
これにより、モデルは単語の「意味」だけでなく、それが 「文章のどこにあるか」 という情報も同時に処理できるようになります。
この位置エンコーディングとAttentionメカニズムが組み合わされることで、AIは単語の意味と文中の役割の両方を正確に捉え、非常に精度の高い文章理解と生成が可能になるのです。
LLMの頭脳「Transformerモデル」
現在のLLMの基盤となっているのは、2017年に発表された論文「Attention Is All You Need」で提案された「Transformer」アーキテクチャです。
従来のモデルは、文章を一つひとつ順番に処理するため、長い文章の最初のほうの情報を忘れてしまう 「長期記憶の問題」 や、処理速度の遅さという課題を抱えていました。
Transformerは、再帰的な構造を完全に排除し、文章全体を一度に処理できるAttentionメカニズムを核とすることで、GPUのような並列処理に特化したハードウェアの能力を最大限に引き出すことができるようになったことでこの問題を根本から解決しました。
この高速な並列化能力が、それまで不可能だったテラバイト級の膨大なデータ学習を可能にし、LLMの**「大規模」**化という新しい時代の幕を開きました。
この「規模」の拡大により、LLMに**「創発能力(以下にて記述)」**という新しい能力が引き出されることにもつながりました。
Transformerの仕組み
Transformerは、主に「エンコーダ」と「デコーダ」という2つの主要な構成要素から成り立っています。
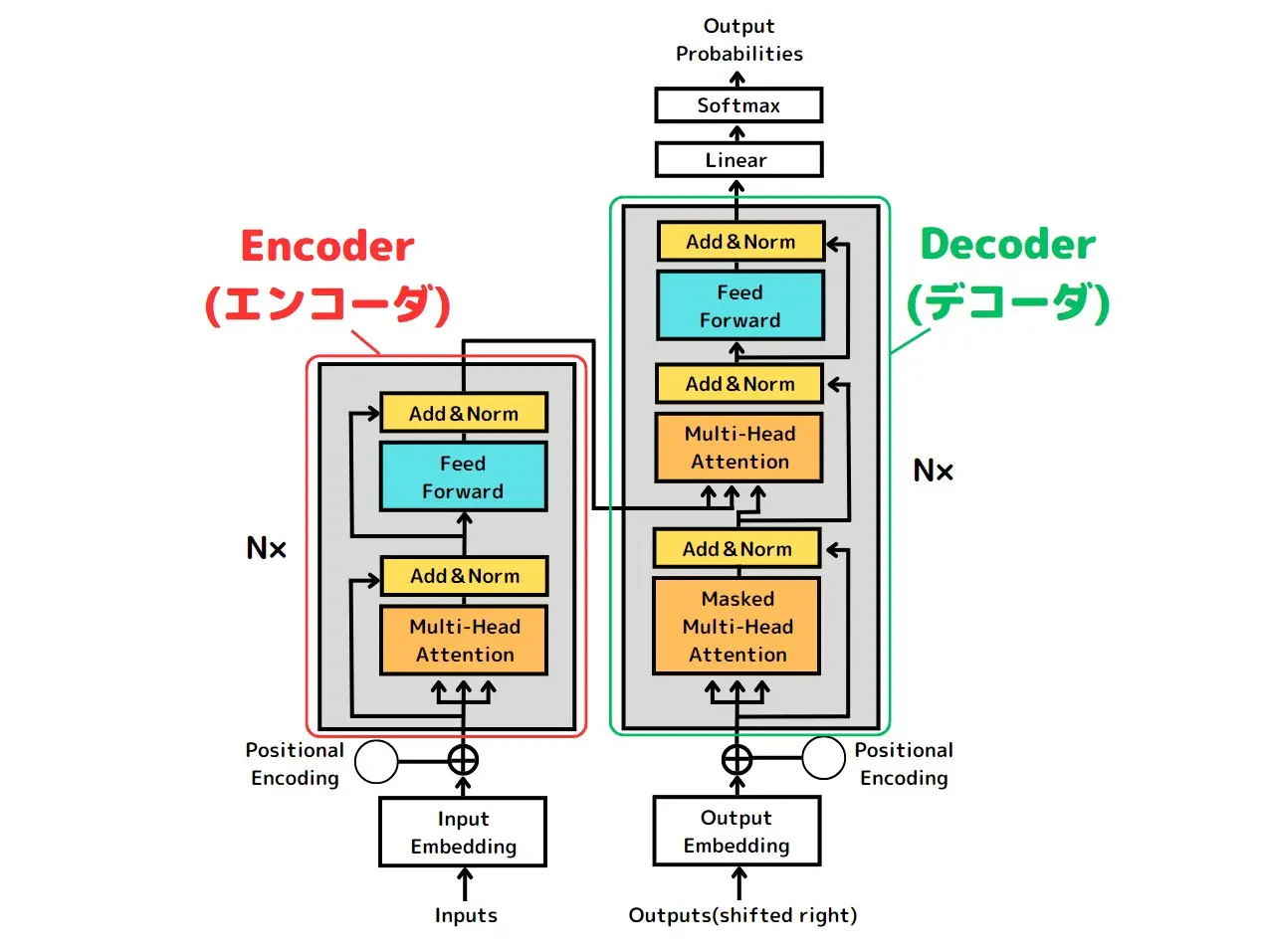
-
エンコーダ
- 入力データを解析し、その結果をデコーダに渡す役割を担っています。
- 処理の流れとしては、
- 入力データの文章を単語ごとに区切る
- 各単語を数値のベクトルに変換する
- Multi-Head Attention(以下参照)によって各単語と他の単語との関連性を評価する
- FFNN (Feedforward Neural Network;順伝播型ニューラルネットワーク;以下FNN)によって特徴量に変換する
- 解析結果をデコーダに渡す
-
デコーダ
- エンコーダから得た情報と、これまで自身が生成した単語列に基づいて、次に来る単語を予測します。
- 処理の流れとしては、
- Multi-Head Attentionによって生成した単語同士の関連性を計算する
- エンコーダからの情報と現在生成した単語の状態との関連性を計算する
- FNNによって特徴量に変換する
- ソフトマックス関数を使用して次に来る単語の確率分布を出力する
- 確率分布を基に、生成する単語を決定する
この連携によって、Transformerは入力された文章をの意味を深く理解し、それに基づいて精緻かつ自然な文章を生成する能力を実現しています。
-
Self-Attentionとは(自己注意)
- これは、文章中の単語一つ一つが、同じ文章の中にある他のすべての単語とどれだけ関連しているかを計算する仕組みです。
- 例えば、「猫が箱の中に入っているのを見て、私は驚いた」という文があったとします。
- 「驚いた」という単語は、「猫」や「箱」という単語と関連性が高いはずです。
- Self-Attentionはこの関連性を数値で測り、それぞれの単語が文脈の中でどんな役割を果たしているかを理解します。
- この技術により、従来のAIモデルが持っていた「短期記憶」の問題を解決しました。
- 昔のモデルは、文章を一つひとつ順番に読んでいくため、長い文章の最初のほうの情報を忘れてしまうことがありました。
- しかし、自己注意は文章全体を一度に見ることができるので、文章のどこに重要な情報があるかを正確に捉えることができ、より一貫性のある文章を生成する基盤となりました。
-
Multi-Head Attention(マルチヘッド注意)
- Self-Attentionは「一つの視点」から文章を見るのに対して、Multi-Head Attentionは複数の異なる視点から同時に文章を見る仕組みです。
- これは同じ文章を複数の異なる観点から読み解くことで、より複雑な文脈やニュアンスを捉えることを可能にします。
- 例えば、あるヘッドは「主語と動詞の関係」に注目し、別のヘッドは「形容詞と名詞の関係」に注目するといったように、それぞれの「ヘッド」が異なる側面に焦点を当てます。
- これらの異なる視点から得られた情報を統合することで、モデルは単一の自己注意よりもはるかに豊かな表現力を持ち、文章の深い理解を実現します。
知識と能力を獲得する2段階訓練パラダイム
LLMは、膨大なデータをただ詰め込むだけでは知的な振る舞いはできません。
その裏には、広範な知識を獲得する事前学習と、特定のタスクへの適応という、目的の異なる2段階の訓練プロセスが存在します。
広範な知識を獲得する事前学習
LLMの訓練は、まず 「事前学習(Pre-training)」 と呼ばれる段階から始まります。
このプロセスでは、ウェブサイトや書籍、Wikipediaなど、ありとあらゆるテキストデータを大量に読み込ませます。
この段階で、モデルは言語の基本的な文法や、一般的な常識、単語や文脈の関係性を学びます。
しかし、このプロセスには課題も存在します。
学習データは 人間の言葉の「写し鏡」 であるため、データに含まれる偏見や不公正な表現が、モデルの出力に影響を与える可能性があります。
このため、学習データの収集や管理には、細心の注意を払う必要があります。
特定のタスクへ対応するためのファインチューニング
事前学習で広範な知識を獲得したモデルは、次に 「ファインチューニング(Fine-tuning)」 という追加学習を行います。
ここでは、特定の目的に沿って厳選された、比較的小規模なデータセットを使います。
| 観点 | 事前学習 | ファインチューニング |
|---|---|---|
| 目的 | 汎用的な言語知識の取得と言語モデルの基盤構築 | 特定のタスクやドメインへの適応と精度向上 |
| 学習データ | ウェブ、書籍などからなる膨大な量のテキストデータ | 特定のタスクに関連する、比較的小規模なラベル付きデータ |
| 得られる能力 | 文法、文脈理解、世界の常識など、汎用的な言語能力 | 専門知識の獲得、特定のタスク(分類、要約など)への対応力 |
| コスト | 非常に高い(大規模な計算資源と時間が必要) | 比較的低い(事前学習モデルをベースとするため、効率的) |
| ユースケース | 基盤モデル(Foundation Model)の構築 | 医療診断補助、法律文書分析、企業内FAQ、カスタマーサポートなど |
ファインチューニングの最大の利点は、事前学習で得た知識を「転移学習」 として活用できる点です。
これにより、モデルを一から訓練するよりもはるかに少ないデータと計算資源で効率的に特定のタスクの精度を向上させることが可能となります。
LLMの能力を飛躍させるスケールと革新
Transformerアーキテクチャと二段階訓練パラダイムによって可能になったLLMの**「大規模化」**は、単なる性能の改善にとどまらない、質的な変化をモデルにもたらしました。
パラメータ数の増大がもたらす創発能力
LLMの能力は、モデルのサイズ(パラメータ数)が特定の閾値を超えると、これまでできなかったことができるようになります。これを創発能力(Emergent Abilities) と呼びます。
簡単にいうと、学習時には教えられていなかった新しい能力が「ふっと」現れるような形です。例えば、複雑な数学の問題を解いたり、複雑な指示を理解して回答する能力がこれにあたります。
これはLLMが単語の続きを予測するだけでなく、人間のように「推論」「常識」に近い能力を獲得する可能性を示しています。
| メリット | デメリット |
|---|---|
| 深い理解力:文脈を深く理解し、複雑なタスクをこなす能力が飛躍的に向上 | ハルシネーション:事実でないことをまるで本当のように話す傾向が強くなる |
| 思考力:人間が考えるように、推論や常識に基づいた判断ができるようになる | コストと遅延:動かすために膨大な電力と計算資源が必要になり、応答速度が遅くなる |
MoEによる新しい解決
LLMの性能を上げるためには大規模化が必要ですが、それによってコストと遅延が増えるというジレンマがありました。
この問題を解決するために生まれたのが「Mixture of Experts(MoE)」と呼ばれる新しい技術です。
MoEは、たくさんの専門家(Experts)とその専門家の中から最適な人を選ぶ「割り振り役」で構成されています。
MoEの仕組み
従来のLLM(密モデル)は、全ての入力(文章)に対して、全てのパラメータを使って計算を行っています。
これは全ての仕事を全員で手分けして行なっているようなものです。
対して、MoEは割り振り役が入力された文章を読み、「この部分は数学の専門家、この部分は歴史の専門家に任せよう」と最適な専門家を1人もしくは2人選びます。
そしてその選ばられた専門家が計算を行うといった形です。
これにより全ての仕事を全員が行うのではなく、「その仕事に最も詳しい人だけが担当する」といったことが実現できます。
-
MoEがもたらすメリット
- 効率的な大規模化
- パラメータの総数は非常に大きいですが、1つの文章を処理するのに使うパラメータはごく一部なので、計算コストが大幅に削減でき効率的に計算することができます。
- 応答速度の向上
- 全体を使う必要がないため、応答が速くなり、待つ時間が短くなります。
- 柔軟な対応
- 入力内容に合わせて担当者が変わるため、モデルがより柔軟になり、個別に対応できるようになります。
MoEは、LLMの能力をさらに引き上げながら、大規模化に伴うコストや遅延の問題を解決する画期的な方法として注目されています。
これからのLLMはただ大きくなるだけでなく、より賢く、より効率的なモデルへと進化していくでしょう。
- 入力内容に合わせて担当者が変わるため、モデルがより柔軟になり、個別に対応できるようになります。
- 効率的な大規模化
2025年のLLMの現在地
巨大モデルの対立
2025年現在、LLM市場は大きく2つの陣営に分かれています。
プロプライエタリ(独占的)モデル
OpenAIのGPT-5やGoogleのGemini 2.5 Proのように、最高性能を追求する有料モデル。
高度な推論能力や、テキストだけでなく画像や音声などを同時に理解するネイティブマルチモーダルな能力が強みとなっているモデルです。
オープンソースモデル
MetaのLlama 4や今年話題となったDeepSeekのような、誰もが無料で利用・可変することができるモデルです。透明性やカスタマイズ性が重視されており、企業や開発者の間で急速に普及しているモデルとなります。
LLMを使いこなすための3つの戦略
このようにLLMは、ただ使うだけでなく、目的に応じて使いこなすための技術が進化しています。
1.プロンプトエンジニアリング
プロンプトエンジニアリングとは、LLMモデルを再学習させることなく、指示(プロンプト)の工夫だけでモデルの振る舞いを制御し、期待通りの応答を得るための技術です。
効果的なプロンプト設計には、モデルがタスクを正確に理解し、最適な結果を生成するための特定の原則が存在しています。
効果的な原則
-
指示の明確さと具体性
- 「短く要約して」のような抽象的な指示は、モデルに誤った解釈をさせる可能性があります。これに対して「50文字程度で要約してください」のような具体的な数値や制約を設けることで、タスクを明確に伝達し、望ましい形式の出力を得ることができるようになります。
-
コンテキストの提供
- 必要な背景情報や前提条件をプロンプトに含めることで、モデルはより深い文脈を理解し、的外れな応答を避けることができます。
-
出力形式の指定
- 出力形式やスタイル(箇条書き、表、特定のトーン)を事前に明示することで、モデルは期待通りの構造を持つ回答を生成しやすくなります。
-
ペルソナ設定
- モデルに特定の役割を演じさせることも有効です。例えば「優秀な経営者として、自社の生産ラインのボトルネックを探すためのアイデアを10個教えてください」と指示することで、出力のトーンや専門性を調整し、より専門的で的確な回答を導き出すことが可能となります。
-
段階的にプロンプトを提供
- 複雑なタスクを与える場合は、一度に与えるのではなく段階的にプロンプトを提供することが推奨されています。 これにより、モデルは情報を整理し、正確な応答を生成しやすくなります。
思考プロセスを促す高度な手法
-
ゼロショット学習
- 「この文章を要約して」のような、指示でタスクをこなす手法です。
- これは汎用性が高い一方、より複雑なタスクでは出力に一貫性をかけたり、重要な情報が省略される可能性があります。
-
フューショット学習
- ゼロショット学習に対して、質問と回答の例をいくつか見せることで、モデルに期待する回答の形式やパターンを「文脈内学習」として教え込む手法です。
- これにより、モデルはデモンストレーションから課題の実行方法を学習し、複雑なタスクにおける性能を向上させることが可能です。
-
Chain-of-Thought (CoT) Prompting
- CoTは、モデルに中間推論のステップを含めることで、複雑なタスクを段階的に解かせる手法です。
- これにより、モデルは論理的に思考し、途中の誤りを自己修正しながら、より正確な答えを導き出す可能性が高まります。
- この思考は「ステップバイステップで考えてください」といった特定のプロンプトを与えることで誘発させることができます。
- CoTは、特に
算術問題や多段階の論理的思考が求められるタスクでその効果を最大限に発揮することができます。
-
Tree-of-Thoughts (ToT) Prompting
- ToTは、CoTをさらに発展させた、人間の意思決定プロセスを模倣した革新的なアプローチです。
- CoTが単一の思考の連鎖であるのに対し、ToTは複数の思考パスを生成し、それぞれを評価・深掘り・選択することで、最適な解決策を導き出します。
- この手法は、課題に対して複数のアイデアを生成し、その実現可能性を評価し最良のものを深く掘り下げるという、思考の「枝分かれ」をモデルに促します。
- そのため、
マーケティング戦略の立案や商品企画など、多角的な視点からのブレインストーミングが求められる複雑な課題に特に有効です。
プロンプトエンジニアリングの進化と未来
最新のLLMは、プロンプトエンジニアリングをより高度な「モデル制御インターフェース」へと進化させています。
例えば、GPT-5に搭載されるとされているreasoning_effortのような新しいパラメーターは、モデルの思考の深さや出力の冗長性まで細かく制御することを可能としています。
また、プロンプトエンジニアリングは個人の技巧から、組織的なナレッジへと移行しつつあります。再利用可能なプロンプトのテンプレートを構築する「プロンプトライブラリ」は、そのトレンドを象徴しています。
プロンプトエンジニアリングは、AIの学習モデル、データ、インフラを含むエコシステム全体で機能する、継続的な学習と改善が必要な技術となっています。
2.ファインチューニング
ファインチューニングは、汎用的なLLMに追加の学習を行い、特定の業務やタスクに特化させることです。
これにより社内FAQやカスタマーサポート、特定の業界文書の作成など、個別性の高いケースに対して汎用モデルの上回る高い精度を実現することが可能となります。
しかし従来のファインチューニング(フルファインチューニング) という手法では、モデル全体のパラメータを再学習しており、膨大な計算リソースとメモリ消費量が要求されるという課題を抱えていました。
そのためファインチューニングはごく一部の企業や研究機関に限定される高コストな手法でした。
PEFT(パラメータ効率的ファインチューニング)
この課題を根本的に解決したのが、PEFT(Parameter-Efficient Fine-Tuning) です。PEFTは、モデル全体のパラメータのごく一部のみを調整する手法です。
これにより、フルファインチューニングと同等の性能を保ちつつ、計算コストとメモリ使用量を大幅に削減することができます。
この技術的進歩は、リソースが限られた組織でも大規模モデルの追加学習を可能にし、AI活用の民主化を大きく進めました。
-
LoRA vs QLoRA
- PEFTの中でも最も広く普及しているのが LoRA(Low-Rank Adaptation)とその発展形であるQLoRA(Quantized LoRA) です。
- これらは異なる技術的・経済的トレードオフを持っているので、導入判断において重要な要素となります。
| 基準 | LoRA | QLoRA |
|---|---|---|
| GPUメモリ効率 | QLoRAより多く消費」 | LoRAより約75%少ない |
| 学習速度 | QLoRAより約66%高速 | LoRAより遅い |
| 費用対効果 | QLoRAより最大40%費用が少ない | LoRAより費用がかかる |
| 最大シーケンスシーケンス長 | GPUメモリにより制限 | 少ないGPUメモリで長く設定可能 |
| 精度向上 | 同程度 | 同程度 |
| 技術的特徴 | 低ランク行列を追加学習 | モデルを4ビット量子化しLoRAを適用 |
QLoRAは、モデルの重みを4ビットの低精度データ型に量子化することでメモリ消費量を飛躍的に削減し、限られたGPUリソースでも巨大なモデルのファインチューニングを可能にします。
これにより、ファインチューニングの導入ハードルは根本的に下がり、より多くの企業が自社の競争優位性の源泉となる専門性をモデルに組み込む戦略を採択できるようになりました。
ファインチューニングの戦略的活用
ファインチューニングは、モデルに「新たな事実知識」を追加するだけでなく、「特定の行動パターンやスタイル」を教え込むプロセスとして機能します。
このプロセスは、企業の競争優位性そのものをモデルに組み込むことにつながります。
- 具体的な事例とその効果
- 医療分野
- がん細胞の画像データでモデルを追加学習させ、診断支援の精度を向上させたり、文書作成時間を大幅に削減したりする事例が報告されています。
- 例えば、退院時サマリーの自動作成システムは、医師の文書作成時間を67%削減し、全国の病院に導入が進められています。
- 金融分野
- 過去の取引データを学習することで、詐欺検出の精度を向上させた事例があります。
- 法律分野
- 判例データを学習させ、契約書チェックや判例分析を行うAIの構築に活用されています。
- 製造業
- 発電設備データを基に予知保全モデルを構築し、トラブル対応時間を50%短縮した事例があります 。
ファインチューニングの成功には、目的や用途に適した質の高いデータセットの準備に大きく依存します。
特に、ドメイン固有の知識や、人間からのフィードバック(RLHF)を組み込むことで、モデルの振る舞いをより望ましい方向へ調整することが可能になります。
3.RAG(検索拡張生成)
RAGのメカニズムとアーキテクチャ
RAGは、LLMが持つ「知識の静的性」という根本的な限界を、アーキテクチャレベルで解決する技術です。
これは、外部データベースから関連情報を検索・抽出し、その情報を基に回答を生成させる二段階のプロセスを組み合わせたものです。
-
検索フェーズ
- ユーザーの質問に関連する情報を外部データソースから効率的に取得します。
- この際に、単語のパターンマッチングを行うキーワード検索だけでなく、文章の意味を数値化して類似性を計算するベクトル検索や、文脈を理解するセマンティック検索を組み合わせることで、より高精度な情報検索を実現しています。
-
生成フェース
- 検索フェーズで収集された情報がユーザーの質問と統合され、LLMに渡されます。
- この情報を基に、LLMは高品質で文脈に沿った回答を生成します。
RAGのビジネス上の優位性
RAGはそのアーキテクチャから様々なビジネス上での優位性をもたらします。
- 最新情報への対応とハルシネーションの抑制
- LLMの学習データに含まれない最新の社内マニュアルやニュース記事を参照することができるため、常に情報の鮮度を維持できます。
- また信頼できる情報源を基に回答を生成することができるため、事実に基づかない「ハルシネーション」の発生を効果的に抑制することができます。
- 回答の透明性と信頼性
- RAGシステムは、解答の元となった文章を明示することができるため、ユーザーは情報の妥当性を容易に確認することが可能です。この信頼性の確保は、特に医療や法律、金融といった厳格かつ正確性が求められる業界でのLLM導入において、法的・論理的なハードルを大きく下げることができます。
- セキュリティとプライバシー
- RAGはLLM自体に追加学習を行うわけではないため、企業の機密情報がモデルのパラメータに恒久的に組み込まれるリスクがありません。
- さらにQuickSolutionのような一部のRAG対応システムは、利用者の閲覧権限を考慮して文書を抽出できるため、安全なナレッジ活用が可能です。
最新のRAG技術とツール
RAG技術は進化を続けており、LLM自身が自己改善を行うSelf-RAGのような高度な技術も登場しています。
Self-RAGは、AI自身が検索結果の質や生成された回答の有用性を評価するプロセスを経ることで、より良い結果を追求します。
この仕組みは、reflection tokenを用いて、自己評価を行い、必要に応じて質問をリライトし、プロセスを繰り返すことで最終的な回答制度を向上させています。
RAGの導入を支援する様々なツールやサービスも登場しています。
OSSツールとしてはDifyやWeaviate、商用サービスとしてはGoogle Cloud Vertex AIやリコーのデジタルバディ、RAGOpsなどがあり、それぞれがベクトルデータベースやGPU環境を統合し、企業の導入を容易にしています。
RAGは既に多くの企業で実用化されています。
例えば、LINEヤフーではRAGを活用した社内ツールを全従業員に導入し、社内規定や問い合わせ先の検索を効率化しています。
また、東洋建設では災害事例検索システムにRAGを応用し、安全事項の確認や新人教育に役立てています。
これらの事例は、RAGが社内ナレッジの活用や業務効率化に大きく貢献していることを示しています。
LLM活用戦略の意思決定
LLM活用戦略の意思決定にあたっては、プロンプトエンジニアリング、ファインチューニング、RAGのそれぞれの特性を包括的に理解することが不可欠です。
| 基準 | プロンプトエンジニアリング | ファインチューニング | RAG |
|---|---|---|---|
| 導入難易度 | 容易 | 複雑 | 中程度 |
| コスト | 低い | 高い(PEFTで中程度) | 中程度 |
| 精度 | 可変 | 高い | 高い |
| メンテナンス性 | 低い | 高い | 中程度 |
| 主要目的 | モデルの振る舞いを一時的に制御 | 特定タスク・ドメインへのモデルの適応 | 最新・独自知識の活用とハルシネーション抑制 |
| 具体的なユースケース | 複雑な推論タスク、クリエイティブ生成 | 医療診断支援、詐欺検出、専門文書作成 | 社内ヘルプデスク、ナレッジ検索、顧客サポート |
この表が示すように、各手法によってトレードオフの関係を持ちます。低コストで迅速な概念実証(PoC)にはプロンプトエンジニアリングが最適です。
一方、高い精度とカスタマイズが求められる本番運用では、RAGやファインチューニングが選択肢となります。
組み合わせによる相乗効果
最先端のLLM活用は、単一の技術導入だけでなく、各技術の強みを組み合わせて最適な「アーキテクチャスタック」を構築するシステム設計の領域へ進化しています。このハイブリッドアプローチにより、単独の手法では解決できない複雑なビジネス課題に対応することが可能となります。
- ファインチューニング + RAG
- ファインチューニングでモデルの振る舞いを特定のドメインに最適化し、RAGにより最新の社内知識を参照する組み合わせにより、知識と振る舞いの両面を最適化させ、極めて高い精度とドメイン適応性を実現させることができます。
- プロンプト + RAG
- RAGで取得した情報を、CoTやToTといった高度プロンプトでモデルに渡すことで、より複雑な推論を伴う正確な回答を生成させることが可能となります。
実際の成功事例
- メルカリ
- LLMと既存の機械学習モデルを組み合わせるハイブリッドアプローチを採用し、商品カテゴリ分類の精度を向上させ、運用コストを削減。
- サイバーエージェント
- ChatGPT APIと独自の広告効果予測AIを連携したシステムを構築し、広告制作時間を大幅に短縮。
AIと共存する世界へ
「AIが仕事を奪う」は本当に起こるのか?
AIによって仕事が奪われるという懸念が広く聞かれていますが、AIは人間の仕事を完全に奪うのではなく、業務のあり方を根本から変えることが目的です。
PwCのレポートによると、AIの影響が受けやすい(自動化が進むと予想されていた職種) においても、求人数は過去5年間(2019年~2024年)で38%も増加していると報告されています。
また他にもレポートでは、AIの影響を受ける仕事について「自動化される仕事(AIがタスクを代替)」と「拡張される仕事(AIが人間の能力を補強・向上)」に分類しており、どちらのタイプの仕事も求人が増加していることから、AIによって人間の業務が拡張される仕事の成長速度が速いことがわかります。
このことからもAIによって人間の仕事が完全に置き換わるのではなく、人間がAIと共存してより高度な業務を遂行する(業務のあり方が根本から変わる)未来となることがわかると思います。
LLMは単なるツールではなく、パートナーへ
最新のLLMは、単に質問に答えるだけでなく、外部ツールを自律的に操作し、複雑なタスクを完了させるAIエージェントへと進化しています。
例えば「来週の東京出張のホテルを予約して」と指示するだけで、航空券の予約状況を確認し、ホテルを検索・予約してくれる、といった未来が現実になりつつあります。
LLMは私たちの生産性を劇的に向上させる強力なパートナーとなることは間違いありません。
この「魔法」を使いこなせるかどうかで、仕事の進め方や今後のキャリアに大きな差が生まれるでしょう。
LLMを単なるツールとして使うのではなく、その仕組みを理解し、戦略的に活用する。
この視点こそが、AI時代を生き抜くための鍵となるのではないでしょうか。
Discussion