Closed7
Spanner change streamsのメモ
とりあえずインスタンスをシュッと立てる。
割と最近入ったProcessing Unitを100にすると従来の1/10の料金で動作検証ができる
$ make spanner-create
gcloud --project $SPANNER_PROJECT_ID spanner instances create $SPANNER_INSTANCE_ID --processing-units 100 --config regional-asia-northeast1 --description $SPANNER_INSTANCE_ID
Creating instance...done.
gcloud --project $SPANNER_PROJECT_ID spanner databases create $SPANNER_DATABASE_ID --instance $SPANNER_INSTANCE_ID --ddl-file schema.sql
Creating database...done.
それらしいスキーマを追加。
schema.sql
CREATE TABLE Users (
UserID STRING(MAX) NOT NULL,
Name STRING(MAX) NOT NULL,
Age INT64 NOT NULL,
) PRIMARY KEY (UserID);
ちなみに最終行を空行にするとコケる。
だいぶハマって時間を浪費した……
$ gcloud --project $SPANNER_PROJECT_ID spanner databases create $SPANNER_DATABASE_ID --instance $SPANNER_INSTANCE_ID --ddl-file schema.sql
ERROR: (gcloud.spanner.databases.create) INVALID_ARGUMENT: Error parsing Spanner DDL statement: \n : Syntax error on line 1, column 1: Encountered \'EOF\' while parsing: ddl_statement
- '@type': type.googleapis.com/google.rpc.LocalizedMessage
locale: en-US
message: |-
Error parsing Spanner DDL statement:
: Syntax error on line 1, column 1: Encountered 'EOF' while parsing: ddl_statement
環境変数はdirenvで設定
.envrc
export SPANNER_PROJECT_ID=xxx
export SPANNER_INSTANCE_ID=yyy
export SPANNER_DATABASE_ID=zzz
多分記事には載せないけど作業用のMakefile
spanner-create:
gcloud --project $$SPANNER_PROJECT_ID spanner instances create $$SPANNER_INSTANCE_ID --processing-units 100 --config regional-asia-northeast1 --description $$SPANNER_INSTANCE_ID
gcloud --project $$SPANNER_PROJECT_ID spanner databases create $$SPANNER_DATABASE_ID --instance $$SPANNER_INSTANCE_ID --ddl-file schema.sql
spanner-reset:
gcloud --project $$SPANNER_PROJECT_ID spanner databases delete $$SPANNER_DATABASE_ID --instance $$SPANNER_INSTANCE_ID -q
gcloud --project $$SPANNER_PROJECT_ID spanner databases create $$SPANNER_DATABASE_ID --instance $$SPANNER_INSTANCE_ID --ddl-file schema.sql
spanner-delete:
gcloud --project $$SPANNER_PROJECT_ID spanner instances delete $$SPANNER_INSTANCE_ID -q
用途
- データをBigQueryとかにレプリケーションして分析に使う
- データ変更をトリガーにPub/Sub等にメッセージングする
- GCSとかに変更履歴を送って監査ログ的なものを作る
設定
- インデックスとかテーブルみたいなスキーマオブジェクトとして扱うのでDDLで作成する
- スコープは3種類
- database全体
- テーブル単位
- カラム単位
- change streamの制約
- database毎に10個まで
- 同じカラムは3つの監視元までしか設定できない(違うかも
- 1つのdata partitionを同時にReadできるのは5つまで
- database全体を監視してもシステムテーブルは対象外
- トランザクションで書き込まれる
- つまりレプリケーション遅延やストリーム漏れは無い
- ストリームにはトランザクションIDみたいなメタデータも含まれる
- 変更対象以外の値を見るときはメタデータのタイムスタンプでstale readを使う
ストリームの読み込み
- Apache Beam SpannerIO Connector
- Spanner API
権限周り
- 設定変更は
spanner.databases.updateDdl権限 - ストリームの読み取りは
spanner.databases.select権限
ベストプラクティス
- 負荷試験をやってCPU使用率とディスク容量に問題が起きないかチェックする
- マルチリージョン時はトレードオフが発生する
- Default Leaderと異なるリージョンで読み取るとLeaderの負荷軽減ができるが遅延が大きめになる
- Default Leaderと同じリージョンで読み取ると遅延は最小化できるがLeaderの負荷が上がる
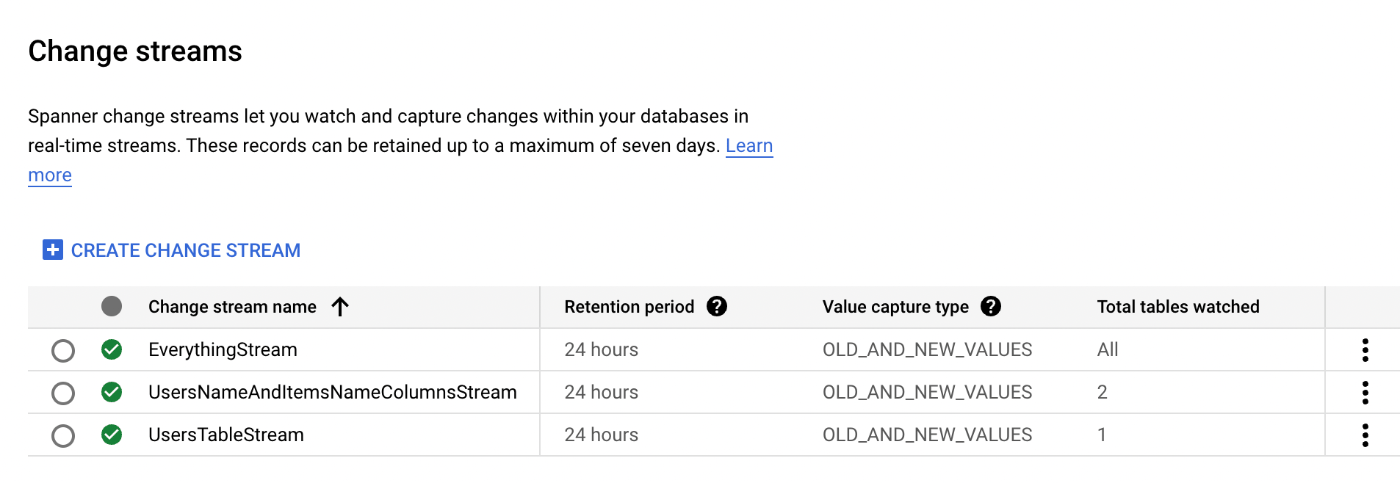
ドキュメント通りに適当にストリーム作ってみた。
できたっぽい
CREATE TABLE Users (
UserID STRING(MAX) NOT NULL,
Name STRING(MAX) NOT NULL,
Age INT64 NOT NULL,
) PRIMARY KEY (UserID);
CREATE TABLE Items (
ItemID STRING(MAX) NOT NULL,
Name STRING(MAX) NOT NULL,
) PRIMARY KEY (ItemID);
CREATE CHANGE STREAM EverythingStream FOR ALL;
CREATE CHANGE STREAM UsersTableStream FOR Users;
CREATE CHANGE STREAM UsersNameAndItemsNameColumnsStream FOR Users(Name), Items(Name);
とりあえず何か値は取れるようになった。
中身の確認はまだできてない。
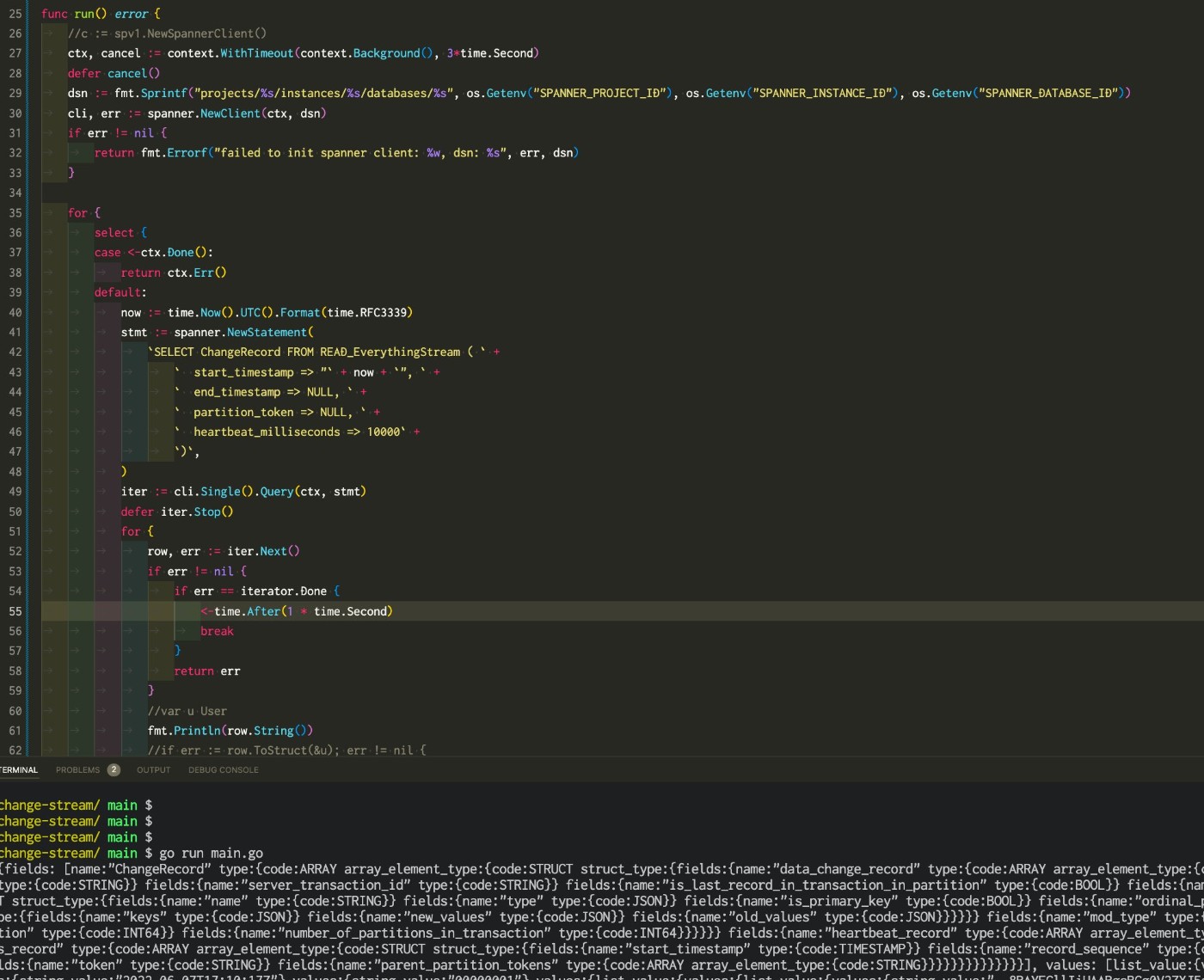
ポイントとしては .Single().Query() を使うこと。
ドキュメントにStrongReadじゃないとダメとか書いてあったので cli.BatchReadOnlyTransaction(ctx, spanner.StrongRead()) とか cli.ReadOnlyTransaction().WithTimestampBound(spanner.StrongRead()).Query(ctx, stmt) 使ったらsingleUseフラグが立たず
spanner: code = "InvalidArgument", desc = "Invalid concurrency mode for change stream query. Change stream queries must be strong reads executed via single use transactions using the ExecuteStreamingSql API"
と怒られた。
このへん
Single()だとフラグが経つ
このスクラップは2022/07/03にクローズされました