GCP Cloud SpannerのData Boostを試す
始めに
2023/06/23のリリースノートでSpannerにData Boostなる機能がGAリリースされたのでこれをちょこっと触ってみようと思います。
なお、Goのライブラリでは6/20のv1.47.0で対応したバージョンがリリース済みです。
Data Boostの概要
SpannerはOLTPを念頭に設計された分散データベースであり基本的に分析用途には適していません。プロダクション環境で動作中のインスタンスに対し大規模な分析クエリーを投げる場合、高負荷発生によるレイテンシー悪化等の懸念があります。
そのためこれまでは何らかの方法でBigQueryにsyncさせる等ひと手間をかける必要がありましたが、Data Boostはインスタンスとは別に読み取り専用の計算リソースを提供しそこで分析クエリーを実行することによりこの課題を解決しています。
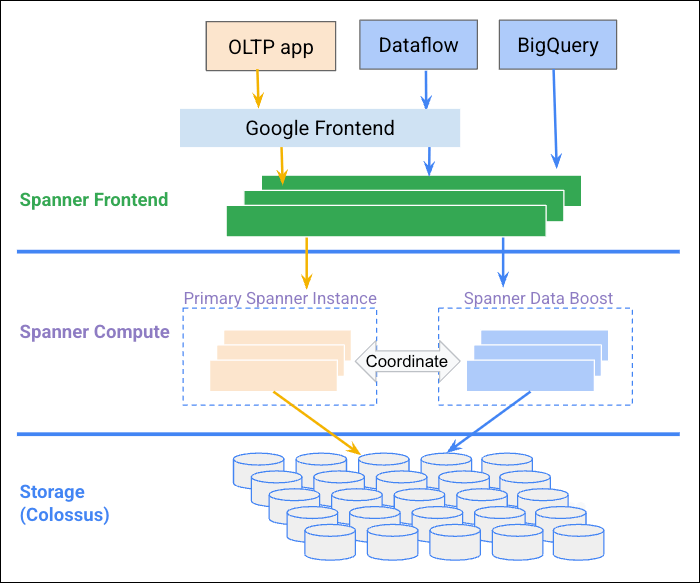
画像出典: https://cloud.google.com/spanner/docs/databoost/databoost-overview
このリソースはフルマネージド且つ従量課金となるためインスタンスのProcessing Unitを意識する必要が無く管理の手間がかかりません。
主な用途としてはレポート生成やバックアップ、DataflowによるGCSエクスポート処理等が想定されています。
使い方
大前提として新たに追加された spanner.databases.useDataBoost が必要なのでその権限が付いたIAMなりSAなりを準備して下さい。
Spannerの準備
適当に作ったSpannerインスタンスで以下のスキーマを適用したDatabaseを作成後DMLでサンプルデータを流し込みます。カラムに特段の意味はありません。
CREATE TABLE Users (
UserID STRING(MAX) NOT NULL,
CreatedAt TIMESTAMP NOT NULL OPTIONS ( allow_commit_timestamp = true ),
) PRIMARY KEY (UserID);
INSERT INTO Users (UserID, CreatedAt) VALUES ("uid1", PENDING_COMMIT_TIMESTAMP());
INSERT INTO Users (UserID, CreatedAt) VALUES ("uid2", PENDING_COMMIT_TIMESTAMP());
INSERT INTO Users (UserID, CreatedAt) VALUES ("uid3", PENDING_COMMIT_TIMESTAMP());
Goのコードからクエリーを流してみる
以下のようにして呼び出すことができます。概ねこれまでの読み出しクエリーと同様ですが、PartitionedQueryを使い且つ QueryOptions.DataBoosEnabled = true にする必要があります。
main.go
package main
import (
"context"
"fmt"
"os"
"time"
"cloud.google.com/go/spanner"
"cloud.google.com/go/spanner/apiv1/spannerpb"
"google.golang.org/api/iterator"
)
type User struct {
UserID string `spanner:"UserID"`
CreatedAt time.Time `spanner:"CreatedAt"`
}
func main() {
if err := run(); err != nil {
fmt.Fprintln(os.Stderr, err)
os.Exit(1)
}
}
func run() error {
ctx := context.Background()
dsn := fmt.Sprintf("projects/%s/instances/%s/databases/%s", os.Getenv("SPANNER_PROJECT_ID"), os.Getenv("SPANNER_INSTANCE_ID"), os.Getenv("SPANNER_DATABASE_ID"))
cli, err := spanner.NewClient(ctx, dsn)
if err != nil {
return err
}
defer cli.Close()
tx, err := cli.BatchReadOnlyTransaction(ctx, spanner.StrongRead())
if err != nil {
return err
}
stmt := spanner.NewStatement("SELECT * FROM Users")
qOpts := spanner.QueryOptions{
Priority: spannerpb.RequestOptions_PRIORITY_LOW,
DataBoostEnabled: true,
}
pts, err := tx.PartitionQueryWithOptions(ctx, stmt, spanner.PartitionOptions{PartitionBytes: 1}, qOpts)
if err != nil {
return err
}
for i, pt := range pts {
iter := tx.Execute(ctx, pt)
defer iter.Stop()
for {
row, err := iter.Next()
if err != nil {
if err == iterator.Done {
break
}
return err
}
var u User
if err := row.ToStruct(&u); err != nil {
return err
}
fmt.Printf("Partition: %d, User: %+v\n", i, u)
}
}
return nil
}
Partition: 0, User: {UserID:uid1 CreatedAt:2023-06-28 07:32:50.949302 +0000 UTC}
Partition: 0, User: {UserID:uid2 CreatedAt:2023-06-28 07:32:50.949302 +0000 UTC}
Partition: 0, User: {UserID:uid3 CreatedAt:2023-06-28 07:32:50.949302 +0000 UTC}
なお、通常のReadOnlyTransactionから呼ぶとエラーになります。
q := cli.ReadOnlyTransaction().QueryWithOptions(ctx, stmt, qOpts)
// (略)
spanner: code = "InvalidArgument", desc = "DataBoost used for non-partitioned query."
BigQueryからクエリーを流してみる
まずBigQuery connection APIをEnableにします。
次にBigQueryを開きADDボタンからExternal connectionを作成します。この時 Use Spanner Data Boost にチェックを入れ忘れないよう気を付けましょう。

無事に作成できたら以下のような形でクエリーを流すとData Boostを使ってSpannerを直接覗くことができます(左メニューで作成したExternal connectionから Query を押すと簡単です)。
SELECT *
FROM EXTERNAL_QUERY("<your project>.asia-northeast1.databoost-test", "SELECT * FROM Users;");

利用具合を確認する
Cloud MonitoringのMetrics explorerから spanner.googleapis.com/instance/data_boost/processing_unit_second_count で処理時間をチェックすることができます。
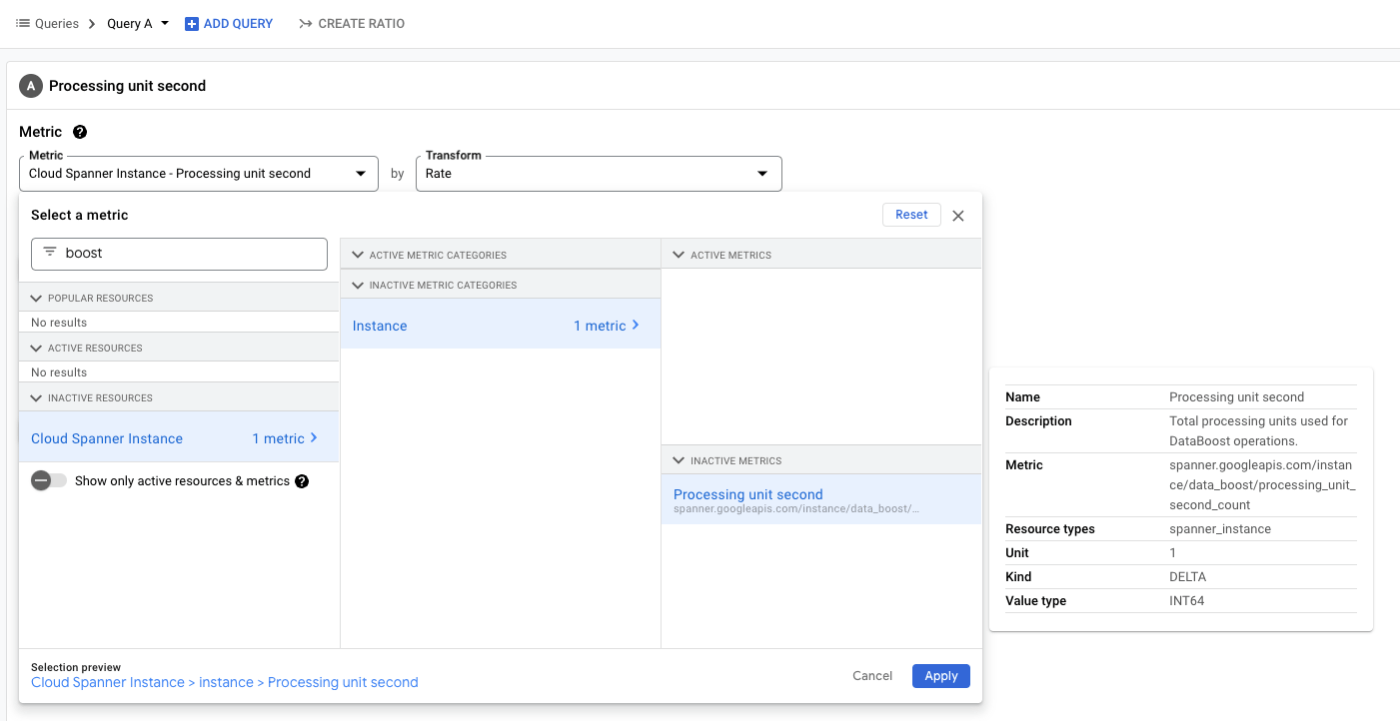
実際の課金は SPU消費時間(1秒単位切上) x 単価 で固定費無しとのことです。
終わりに
比較的簡単な設定やコードからリソースアロケーションを意識することなく従量課金のみで利用することができ中々便利そうです。
仕事でバッチ処理を実装することが多いため機会があれば使ってみたいと思います。
Discussion