Spanner Change Streamsの概要
はじめに
Spanner Change Streamsが先日GAとなったためどのようなものか調査した内容をまとめます。
なお「Goから簡単イイカンジに使うことができないかな?」という動機で触ってみたため本命であるDataflowからの利用感については未調査です。
Spanner Change Streamsとは
Change StreamsはSpannerに加えられたデータ変更(INSERT, UPDATE, DELETE)の内容をニアリアルタイムで取得するための仕組みで、主な用途としては以下のようなものが想定されています。
- 変更内容をBigQuery等にレプリケーションし分析に利用する
- データ変更をトリガーにPub/Sub等へメッセージングする
- GCSに変更内容を保存し監査ログとする
これまでSpannerにはこういった変更検出の機能は存在しなかったため、例えばデータ更新をトリガーにイベントを送る場合Transaction log tailingパターンを実現することは不可能で、代わりにアプリケーション側でTransactional outboxパターンを実装する必要がありました。
配信の完全性
Change Streamsが配信を行うための内部テーブルへの書き込みはアプリケーション側の書き込みと同一のトランザクション内で行われるため、コミットが成功した時点で配信が保証されます。
詳細は後述しますがこの内部テーブルへの書き込みによって遅延が発生しないようデータの局所性を持った動作となっているため恐らくパフォーマンスへの影響はあまり気にしなくてよいと思われます。
配信される値にはテーブル名やカラム名・カラムのデータ型・タイムスタンプ・トランザクションID等のメタデータの他に変更された値やPKが含まれますが、レコード全ての値を取得する場合はPKとコミットタイムスタンプからSpannerのStale Readを使ってレコードを取得する必要があります。
Change Streamsのスケーラビリティ
Spannerでは実データをColossus(分散ストレージ)上にSplit単位のまとまりで保存していますが、このSplitが一定以上の規模になると自動的に分割するという仕組みでスケールを実現しています。
Change Streamsもそれに倣い1つのChange Stream Partitionは1つのSplitに紐付いておりこのPartitionがSplitの増減と連動することでスケーラビリティを確保します。加えてPartitionは可能な限り高速に処理できるようデータのインターリーブのようにSplitに紐付け局所性を持つよう配置されます。
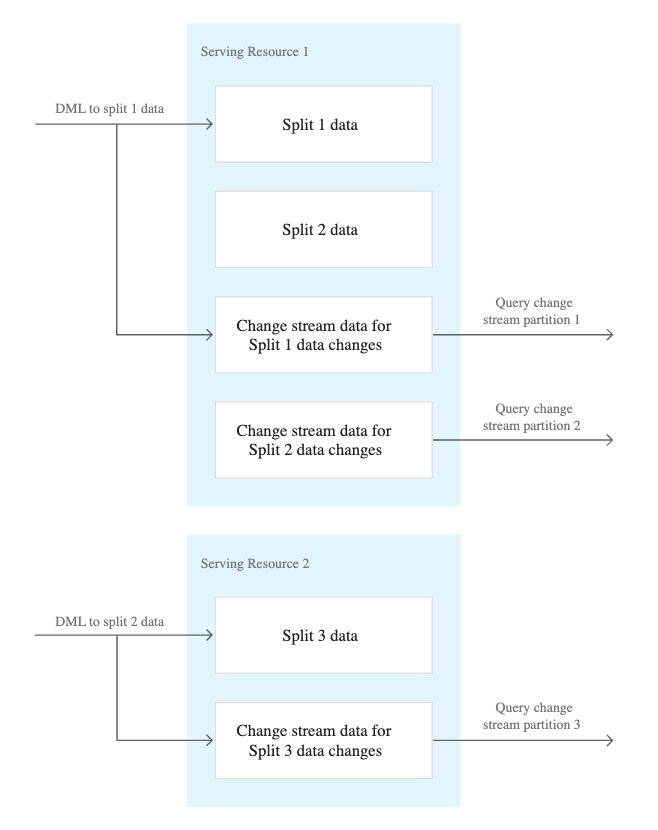
画像出典: https://cloud.google.com/spanner/docs/change-streams/details#change_stream_partitions
有効化
設定を入れることそのものは比較的簡単でインデックスやユニーク制約に類似したDDLを流せばOKです。
スコープとしては
- database全体
- テーブル単位
- カラム単位
の3つがあり例えば以下のようにすると各スコープのサンプルを設定できます。
CREATE TABLE Users (
UserID STRING(MAX) NOT NULL,
Name STRING(MAX) NOT NULL,
Age INT64 NOT NULL,
) PRIMARY KEY (UserID);
CREATE TABLE Items (
ItemID STRING(MAX) NOT NULL,
Name STRING(MAX) NOT NULL,
) PRIMARY KEY (ItemID);
CREATE CHANGE STREAM EverythingStream FOR ALL;
CREATE CHANGE STREAM UsersTableStream FOR Users;
CREATE CHANGE STREAM UsersNameAndItemsNameColumnsStream FOR Users(Name), Items(Name);
ただし設定にあたっては「database毎に10個まで」等といった制約があるためQuotasをよく確認し超過しないように気を付けましょう。
利用方法
公式ドキュメントではDataflowを使う方法とSpanner APIを叩いて直接使う方法が示されていますが、やはり本命はDataflowなようでいくつか実用できそうなテンプレートが提供されています。
APIベースで利用する場合かなり面倒な実装が必要になると思われます。例えば先に述べたPartitionの分割が発生するとその旨を通知するレコードが返却されるため、その通知内容を元に新たに別プロセスを起動して別のテーブルからストリームを取得するような動作が必要と思われます。反対にPartitionのマージ(=Splitのマージ)が発生する場合、不要なプロセスは削除しストリームの受信を止める必要がありそうです。
Dataflowテンプレートであれば当然この辺りは全て網羅され正しく動作するものがすぐに利用できるため、余程の理由が無い限りはDataflowを使う方向で検討した方が賢明でしょう。
一報を見た当初はGoから手軽にTransactional log tailingが実現できるのでは……!?と期待していたのですが、そう単純な話ではありませんでした。
一応ちょろっと触ってみた
とはいえ一応Goから少し触ってみたのでそのコードを供養がてら貼り付けます。色々試行錯誤はしましたがAPIを直接触らなくてもGoのクライアントライブラリから動かすことができました。
なおこのコードは「なんかChange Streamsから受信できた!わーい🥰」というレベルでありサバンナの蟻塚以上の穴だらけ実装で全く使い物にならないためくれぐれも参考にはしないで下さい。
スキーマは「有効化」のところで入れたものを使っています。
package main
import (
"context"
"fmt"
"os"
"time"
"cloud.google.com/go/spanner"
"google.golang.org/api/iterator"
)
func main() {
if err := run(); err != nil {
fmt.Fprintln(os.Stderr, err)
}
}
func run() error {
ctx, cancel := context.WithTimeout(context.Background(), 3*time.Second)
defer cancel()
dsn := fmt.Sprintf("projects/%s/instances/%s/databases/%s", os.Getenv("SPANNER_PROJECT_ID"), os.Getenv("SPANNER_INSTANCE_ID"), os.Getenv("SPANNER_DATABASE_ID"))
cli, err := spanner.NewClient(ctx, dsn)
if err != nil {
return fmt.Errorf("failed to init spanner client: %w, dsn: %s", err, dsn)
}
for {
select {
case <-ctx.Done():
return ctx.Err()
default:
now := time.Now().UTC().Format(time.RFC3339)
stmt := spanner.NewStatement(
`SELECT ChangeRecord FROM READ_EverythingStream ( ` +
` start_timestamp => "` + now + `", ` +
` end_timestamp => NULL, ` +
` partition_token => NULL, ` +
` heartbeat_milliseconds => 1000` +
`)`,
)
iter := cli.Single().Query(ctx, stmt)
defer iter.Stop()
for {
row, err := iter.Next()
if err != nil {
if err == iterator.Done {
<-time.After(1 * time.Second)
break
}
return err
}
fmt.Println(row.String())
}
}
}
}
$ go run main.go
{fields: [name:"ChangeRecord" type:{code:ARRAY array_element_type:{code:STRUCT struct_type:{fields:{name:"data_change_record" type:{code:ARRAY array_element_type:{code:STRUCT struct_type:{fields:{name:"commit_timestamp" type:{code:TIMESTAMP}} fields:{name:"record_sequence" type:{code:STRING}} fields:{name:"server_trans
(略)
context deadline exceeded
TODO
- Dataflowで触ってみる
- Goで超頑張って実装してみる
Discussion