🏩
SAM 2: Segmentation Anything Model 2を理解して動かす モデル理解編
Segmentation Anything Model2(SAM2)を理解したい
はじめに
タイトルの通りSAM2を理解し使えるようにしたかったので勉強がてらメモ
最終的には量子化してFPGAに乗せられたらいいなあと思っている(そこまでできる/書くかは不明)
本記事の画像や文章などの引用は各論文や記事のリンク先から
「自分で使うこと」が目的なので性能やデータセット、使い道などは省略
間違って認識してる部分に気づいたら教えてください
- 論文
- Github
Model理解

SAM2は下記ブロックから構成される
Imager Encoder
- 入力された画像をリアルタイムで処理するためのブロック(のはず)
- ビデオの各フレームに対して特徴を抽出。ユーザーからのプロンプトやインタラクションは、この段階では直接関与しないが、後段のプロセス(Memory Attention/Mask Decoder)で使われる
- エンコーダは各フレームから高次元の特徴埋め込み(抽出)を行う
- Hieraを使う
- HieraはMAEで事前学習を行うことでTransformer blockのみを使用したViTモデル。Conv layer、相対位置埋め込みなどのモジュールをなくしている。これにより速度/精度でSoTAを改善
- 感想:リアルタイム性のために軽量なViTであるHieraを使っているのではないか
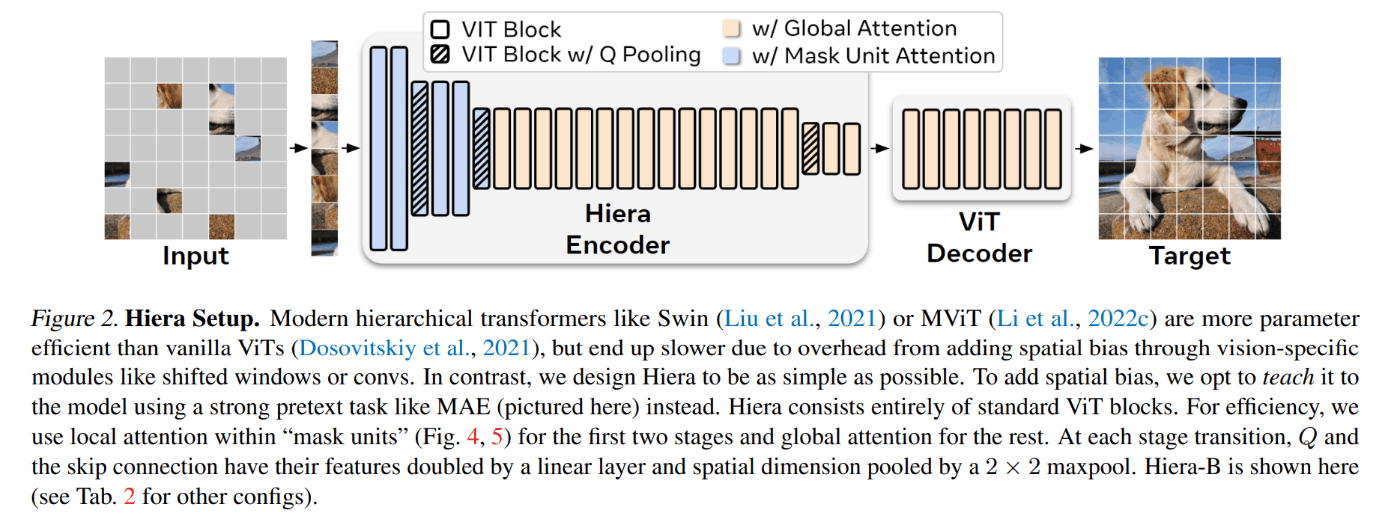
- Hiera Image Encoderはピラミッドネットワークを使用して異なるスケールの特徴を抽出している。Stage3/4ではStride16,32の特徴を合わせて各フレームのイメージ埋め込みを生成している
- Stage1/2のStride 4,8の特徴はMemory Attentionでは使用されずMask DecoderのアップサンプリングレイヤへのSkip Connectionとして使用される(後述)
- 絶対的な位置エンコーディングをウィンドウ化して使用し、グローバルな位置情報をフレームに対して与える(相対位置エンコーディングは使用しない)
Memory Attention
- 現在と過去のフレーム・プロンプトからAttentionを計算するブロック。要はフレームの時系列情報でAttentionを計算することで物体の追尾性能を向上させていると理解
- 最初の1frame目はImager Encoderからの特徴をそのまま使用する
- 2frame以降はMemory Bankに格納されている過去frameの情報からAttentionを計算する
- L個のTransformerブロックにより下記計算をする
- Self Attention : frmae内の各領域が他の領域とどのように関連しているかを学習
- Cross Attention : 現在frameの特徴をメモリバンクに保存されている過去frameの特徴/Objectへのポインタと関連付ける
- 最終的にTransformer内のMLPブロックに入力して特徴量を出力
- ここでAttentionの計算量を削減するため、Flash Attention2を使用して計算量を削減している
- Online Softmaxなどなどを使って高速化する手法
- Online SoftmaxからFlash Attentionの計算解説はここがわかりやすかった
- (余談)Flash attention3も出たらしい
Prompt Encoder and Mask Decoder
- ユーザーからの入力プロンプトを基にセグメンテーションマスクを作成するブロック
- Prompt Encoder
- ユーザーからのPositive/Negativeなプロンプト、BoundigBox、Maskから与えられたフレーム内でSegmentationの範囲を定義する
- Mask promptは畳み込みを使用して埋め込まれフレームの埋め込みと合算される
- Mask Decoder
- two-way transformer blockによりプロンプトとフレームの埋め込みを更新する
- 曖昧なプロンプトが与えられた場合、複数の互換性あるセグメンテーションマスクを予測する
- Videoの場合、フレーム進むに従い曖昧性が増加する可能性があるため、各フレームに対して複数のマスクを予測する。追加のプロンプトが曖昧性を解消しない場合は現在フレームにおいて予測されたマスクの中で最高のIoUを持つマスクのみを伝搬する
- Occlusion(遮蔽)について
- PVS(Promptable Visual Segmentation)タスクではOcculusionによりあるフレーム内に有効なオブジェクトが存在しない場合がある。これに対応するためPromptで与えられたオブジェクトが存在するかどうかを予測するHeadが追加されている(下図Occlusion score)
- Skip connectionについて
- Image EncoderからのSkip connectionを使用してMemory attention経由で高解像度情報をMask Decoderに入れている。これによりセグメンテーション精度を上げる工夫をしている(U-Net的な?)

Memory Encoder
- 出力マスクをConv moduleでダウンサンプリングし、その結果をImage Encoderから得られる未調整のフレーム埋め込みと要素ごとに合算する
- そのあとさらにConv layerを通して情報を統合する
Memory Bank
- 最新のNフレームまでのメモリをFIFOとして保持する
- プロンプトに応じたフレームの情報は最大Mフレームまで別のFIFOで保持される。これらの情報は空間特徴マップとして保持される
- オブジェクトポインタ
- 軽量なベクトルとして各フレームでMask Decoderの出力に基づいたトークンが保持される。
- 時間情報の埋め込み
- Memory Attentionでは空間特徴マップとオブジェクトポインタに対してCross Attentionを計算する
いったん動かす
ローカルPC上で実行する。動作編に続く
PC(GPU)で動かす->量子化する->PC(GPU)で動かす->FPGAで動かす ができたらいいなぁ
Discussion