DPU IP+Vitis AIでResNetの量子化+推論実行

初めに
Vitis AIとZynq MPSoCを使ってかなり久しぶりにDNNモデルを動かそうとしたところだいぶ色々と忘れていたので基本に返って手順メモ。FPGA系は毎回手順操作忘れてしまう。。
というかまだTransformerがDPU IPに対応してない?HLSとか書きたくないのでよろしくお願いします
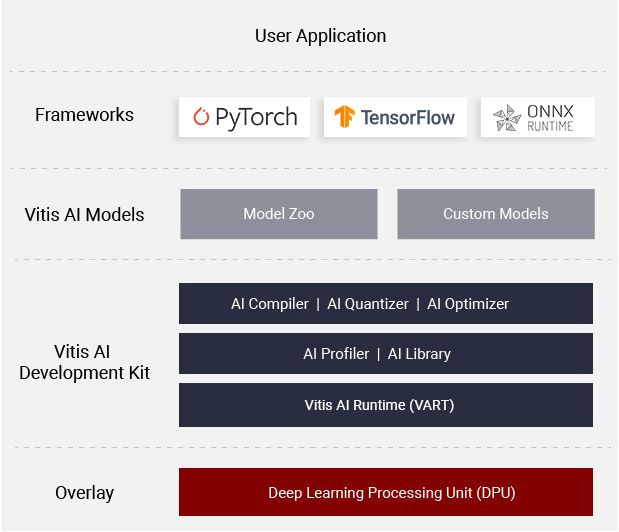
旧Xilinxチュートリアルの手順通りにPyTorchで作成されたResNetをfp32->int8に量子化し、KV260上のDPU IPで推論を実行する。基本的にここまでできれば後はFPGA側で実行時にモデルを任意の物に差し替える+アプリケーションのcppファイルを変更するだけ。
ここを参考にしながらやった
環境
FPGA : AMD KV260 Zynq MPSoC US+
HostPC : WSL2 Ubuntu22.04
開発環境 : Vivado ML edition 2022.1 Linux版
Vitis AI 3.0
HostPC Vitis AI準備
- VitisAIをcloneしてdocker環境のビルドまで行う
- モデルの量子化やクロスコンパイルはVitis AIのDocker環境で行う
mkdir hoge
cd hoge
git clone -b 3.0 https://github.com/Xilinx/Vitis-AI
cd Vitis-AI/docker
./docker_build.sh -t gpu -f pytorch
docker image ls
docker image lsでこんな感じになってればok
REPOSITORY TAG IMAGE ID CREATED SIZE
xilinx/vitis-ai-pytorch-gpu 3.0.0.001 84ac11abb002 38 seconds ago 16.5GB
xilinx/vitis-ai-pytorch-gpu latest 84ac11abb002 38 seconds ago 16.5GB
xiinx/vitis-ai-gpu-base latest bb7e8c8bff9a 17 minutes ago 5.99GB
./VitisAI/以下にdocker_run.shがあるのでそれを使ってdockerを動かす。普通にVitisAI/docker/以下でdocker runしたらホスト側PCのファイルがリンクされず、docker環境から参照できなかった。設定すれば良いのだろうが下記が楽。
docker動かしたらanaconda環境が既にあるのでそれをactivateする。ここまでできればHostPC側は準備OK
cd .. #./VitisAI に戻る
./docker_run.sh xilinx/vitis-ai-pytorch-gpu:3.0.0.001
conda activate vitis-ai-pytorch
FPGA(KV260) Vitis AI準備
今回は簡略化のため、既に公式から配布されているイメージをSDカードに焼いて終わり。
ここのDownload the Vitis AI pre-built SD card image from the appropriate link: から所望のデバイスの物をダウンロードしてきて焼けばOK
中身としてはPetalinux2022.1環境にVivadoですでにDPU IPが組み込まれBitstreamが完了したものが書き込まれていると想定。後はVitis AIも既に入っていた。
自分でDPU IPなりハードウェアをカスタマイズする場合はこの辺を参考にすればよいはず↓
ここまで終わったらFPGAに接続する。SSH接続するまではUSB microB使ってTeraTermなり使ってシリアル通信するのが楽。ボーレート115200
KV260に接続したらlsして中身確認。下記の物が既に入ってた
root@xilinx-kv260-starterkit-20222:~# ls
Vitis-AI
dpu_sw_optimize
ここまできたらFPGA側も準備完了。後は量子化したモデルをwin scpなりでコピーしてあげて呼び出せばDPU IP上で実行してくれる。実行するまでおいておく
ResNet50の量子化・クロスコンパイル
Host PCに戻って必要なファイル一式を入手する
ResNet50モデルの入手
量子化するためのfp32のResNet50を入手する
cd /workspace
wget https://www.xilinx.com/bin/public/openDownload?filename=resnet50-zcu102_zcu104_kv260-r3.0.0.tar.gz -O resnet50-zcu102_zcu104_kv260-r3.0.0.tar.gz
tar -xzvf resnet50-zcu102_zcu104_kv260-r3.0.0.tar.gz
mkdir -p resnet18/model
量子化用のキャリブレーションデータ入手
ImageNet 1000を入手して量子化時のキャリブに使う。
正直ここのキャリブは変な画像の分布とかにしなければ体感あまりそこまで影響でないイメージがある
cd resnet18
unzip archive.zip
ResNet入手
次にdocker環境を立ち上げる。CPU/GPU環境がある。GPU環境を使う場合は先にdocker用のCuda Toolkitを入手しておくこと。GPU環境だと量子化(QAT/PTQ)にGPU使ってくれてるっぽくて速い
一応入手コマンドはこれ↓
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update
sudo apt-get install -y nvidia-docker2
sudo systemctl restart docker
Docker環境に入る
./docker_run.sh xilinx/vitis-ai-pytorch-gpu:3.0.0.001
conda activate vitis-ai-pytorch
これで先ほど作成された/resnet18がDocker環境の/workspace以下に存在していればOK
Docker環境でFP32のResnetの.pthを入手
cd resnet18/model
wget https://download.pytorch.org/models/resnet18-5c106cde.pth -O resnet18.pth
cd ..
cp ../src/vai_quantizer/vai_q_pytorch/example/resnet18_quant.py ./
量子化前の精度チェック
python resnet18_quant.py --quant_mode float --data_dir imagenet-mini --model_dir model
top-1 / top-5 accuracy: 69.9975 / 88.7586
これが量子化前のResNet18の実力
次にDPUアーキテクチャに対してコンパチかチェックする。DPUCZDX8G_ISA1_B4096というのがDPUIP。DPU IPは規模によっていくつか存在するため、その部分を変更した場合はここを変更する必要がある
python resnet18_quant.py --quant_mode float --inspect --target DPUCZDX8G_ISA1_B4096 --model_dir model
ResNet50の量子化・確認
下記コマンドで量子化
python resnet18_quant.py --quant_mode calib --data_dir imagenet-mini --model_dir model --subset_len 200
cd quantize_result
ResNet.pyとQuant_info.jsonができればok。ここに量子化情報が記載されている
- quant_info.json
{
"param":
{
"ResNet::conv1.weight":[[8,8]],
"ResNet::conv1.bias":[[8,7]],
"ResNet::layer1.0.conv1.weight":[[8,8]],
"ResNet::layer1.0.conv1.bias":[[8,6]],
"ResNet::layer1.0.conv2.weight":[[8,8]],
"ResNet::layer1.0.conv2.bias":[[8,6]],
"ResNet::layer1.1.conv1.weight":[[8,8]],
"ResNet::layer1.1.conv1.bias":[[8,6]],
"ResNet::layer1.1.conv2.weight":[[8,8]],
"ResNet::layer1.1.conv2.bias":[[8,6]],
"ResNet::layer2.0.conv1.weight":[[8,9]],
"ResNet::layer2.0.conv1.bias":[[8,7]],
"ResNet::layer2.0.conv2.weight":[[8,8]],
"ResNet::layer2.0.conv2.bias":[[8,6]],
"ResNet::layer2.0.downsample.0.weight":[[8,7]],
"ResNet::layer2.0.downsample.0.bias":[[8,6]],
"ResNet::layer2.1.conv1.weight":[[8,8]],
"ResNet::layer2.1.conv1.bias":[[8,7]],
"ResNet::layer2.1.conv2.weight":[[8,8]],
"ResNet::layer2.1.conv2.bias":[[8,6]],
"ResNet::layer3.0.conv1.weight":[[8,9]],
"ResNet::layer3.0.conv1.bias":[[8,7]],
"ResNet::layer3.0.conv2.weight":[[8,9]],
"ResNet::layer3.0.conv2.bias":[[8,7]],
"ResNet::layer3.0.downsample.0.weight":[[8,9]],
"ResNet::layer3.0.downsample.0.bias":[[8,8]],
"ResNet::layer3.1.conv1.weight":[[8,9]],
"ResNet::layer3.1.conv1.bias":[[8,7]],
"ResNet::layer3.1.conv2.weight":[[8,8]],
"ResNet::layer3.1.conv2.bias":[[8,6]],
"ResNet::layer4.0.conv1.weight":[[8,9]],
"ResNet::layer4.0.conv1.bias":[[8,7]],
"ResNet::layer4.0.conv2.weight":[[8,8]],
"ResNet::layer4.0.conv2.bias":[[8,6]],
"ResNet::layer4.0.downsample.0.weight":[[8,7]],
"ResNet::layer4.0.downsample.0.bias":[[8,7]],
"ResNet::layer4.1.conv1.weight":[[8,8]],
"ResNet::layer4.1.conv1.bias":[[8,6]],
"ResNet::layer4.1.conv2.weight":[[8,8]],
"ResNet::layer4.1.conv2.bias":[[8,5]],
"ResNet::fc.weight":[[8,8]],
"ResNet::fc.bias":[[8,11]]
},
"output":
{
"ResNet::input_0":[[8,5]],
"ResNet::ResNet/ReLU[relu]/2674":[[8,5]],
"ResNet::ResNet/MaxPool2d[maxpool]/input.7":[[8,5]],
"ResNet::ResNet/Sequential[layer1]/BasicBlock[0]/ReLU[relu]/input.13":[[8,5]],
"ResNet::ResNet/Sequential[layer1]/BasicBlock[0]/Conv2d[conv2]/input.15":[[8,5]],
"ResNet::ResNet/Sequential[layer1]/BasicBlock[0]/ReLU[relu]/input.19":[[8,5]],
"ResNet::ResNet/Sequential[layer1]/BasicBlock[1]/ReLU[relu]/input.25":[[8,5]],
"ResNet::ResNet/Sequential[layer1]/BasicBlock[1]/Conv2d[conv2]/input.27":[[8,5]],
"ResNet::ResNet/Sequential[layer1]/BasicBlock[1]/ReLU[relu]/input.31":[[8,5]],
"ResNet::ResNet/Sequential[layer2]/BasicBlock[0]/ReLU[relu]/input.37":[[8,5]],
"ResNet::ResNet/Sequential[layer2]/BasicBlock[0]/Conv2d[conv2]/input.39":[[8,5]],
"ResNet::ResNet/Sequential[layer2]/BasicBlock[0]/Sequential[downsample]/Conv2d[0]/input.41":[[8,6]],
"ResNet::ResNet/Sequential[layer2]/BasicBlock[0]/ReLU[relu]/input.45":[[8,5]],
"ResNet::ResNet/Sequential[layer2]/BasicBlock[1]/ReLU[relu]/input.51":[[8,5]],
"ResNet::ResNet/Sequential[layer2]/BasicBlock[1]/Conv2d[conv2]/input.53":[[8,5]],
"ResNet::ResNet/Sequential[layer2]/BasicBlock[1]/ReLU[relu]/input.57":[[8,5]],
"ResNet::ResNet/Sequential[layer3]/BasicBlock[0]/ReLU[relu]/input.63":[[8,5]],
"ResNet::ResNet/Sequential[layer3]/BasicBlock[0]/Conv2d[conv2]/input.65":[[8,5]],
"ResNet::ResNet/Sequential[layer3]/BasicBlock[0]/Sequential[downsample]/Conv2d[0]/input.67":[[8,7]],
"ResNet::ResNet/Sequential[layer3]/BasicBlock[0]/ReLU[relu]/input.71":[[8,5]],
"ResNet::ResNet/Sequential[layer3]/BasicBlock[1]/ReLU[relu]/input.77":[[8,5]],
"ResNet::ResNet/Sequential[layer3]/BasicBlock[1]/Conv2d[conv2]/input.79":[[8,5]],
"ResNet::ResNet/Sequential[layer3]/BasicBlock[1]/ReLU[relu]/input.83":[[8,5]],
"ResNet::ResNet/Sequential[layer4]/BasicBlock[0]/ReLU[relu]/input.89":[[8,5]],
"ResNet::ResNet/Sequential[layer4]/BasicBlock[0]/Conv2d[conv2]/input.91":[[8,5]],
"ResNet::ResNet/Sequential[layer4]/BasicBlock[0]/Sequential[downsample]/Conv2d[0]/input.93":[[8,6]],
"ResNet::ResNet/Sequential[layer4]/BasicBlock[0]/ReLU[relu]/input.97":[[8,5]],
"ResNet::ResNet/Sequential[layer4]/BasicBlock[1]/ReLU[relu]/input.103":[[8,4]],
"ResNet::ResNet/Sequential[layer4]/BasicBlock[1]/Conv2d[conv2]/input.105":[[8,3]],
"ResNet::ResNet/Sequential[layer4]/BasicBlock[1]/ReLU[relu]/input":[[8,3]],
"ResNet::ResNet/AdaptiveAvgPool2d[avgpool]/3211":[[8,4]],
"ResNet::ResNet/Linear[fc]/3215":[[8,2]]
},
"input":
{
},
"fast_finetuned":false,
"bias_corrected":true,
"version":"3.0.0+a44284e+torch1.12.1"
}
量子化による精度劣化評価
量子化したモデルをImageNetで同様に評価する
cd ..
python resnet18_quant.py --model_dir model --data_dir imagenet-mini --quant_mode test
結果:
top-1 / top-5 accuracy: 69.1308 / 88.7076
量子化前が
top-1 / top-5 accuracy: 69.9975 / 88.7586
だったので1%未満の性能劣化、ということがわかる(体感PTQにしては結構いい感じ)
最後にKV260で実行できる.xmodel形式にする
python resnet18_quant.py --quant_mode test --subset_len 1 --batch_size=1 --model_dir model --data_dir imagenet-mini --deploy
DPU実行用クロスコンパイル
先ほど生成されたResNet_int.xmodelをDPUで実行できる形にクロスコンパイルする
MPSoCターゲットの場合、IP情報が必要なので/opt/vitis_ai/compiler/arch/DPUCZDX8Gが存在しなければならない
cd /workspace/resnet18
vai_c_xir -x quantize_result/ResNet_int.xmodel -a /opt/vitis_ai/compiler/arch/DPUCZDX8G/<Target ex:KV260>/arch.json -o resnet18_pt -n resnet18_pt
次にresnet18_pt.prototxtというファイルを作成する。Inputの量子化パラメータが入っている。自分で行う場合はここのKernelのmeanとscaleを変更する。
model {
name : "resnet18_pt"
kernel {
name: "resnet18_pt_0"
mean: 103.53
mean: 116.28
mean: 123.675
scale: 0.017429
scale: 0.017507
scale: 0.01712475
}
model_type : CLASSIFICATION
classification_param {
top_k : 5
test_accuracy : false
preprocess_type : VGG_PREPROCESS
}
}
念のため量子化の式だけのせておく。ここでいうzeropointがmean、scaleがscaleに対応する

これでモデルのINT8量子化は完了!
(8/18追記)
ここでの各mean,scaleはチャネル毎に記述しているが実装を見る感じRGBではなくBGRなので注意↓
モデルのKV260デプロイ
量子化によってできた生成物一式をKV260に転送
scp -r resnet18_pt root@[TARGET_IP_ADDRESS]:/usr/share/vitis_ai_library/models/
評価用の画像/ビデオデータ
[Docker] $ cd /workspace
[Docker] $ wget https://www.xilinx.com/bin/public/openDownload?filename=vitis_ai_library_r3.0.0_images.tar.gz -O vitis_ai_library_r3.0.0_images.tar.gz
[Docker] $ wget https://www.xilinx.com/bin/public/openDownload?filename=vitis_ai_librar
[Docker] $ scp -r vitis_ai_library_r3.0.0_images.tar.gz root@[TARGET_IP_ADDRESS]:~/
[Docker] $ scp -r vitis_ai_library_r3.0.0_video.tar.gz root@[TARGET_IP_ADDRESS]:~/
KV260で解凍
[Target] $ tar -xzvf vitis_ai_library_r3.0.0_images.tar.gz -C ~/Vitis-AI/examples/vai_library/
[Target] $ tar -xzvf vitis_ai_library_r3.0.0_video.tar.gz -C ~/Vitis-AI/examples/vai_library/
推論実行
クラス分類テストタスク
今回はテストアプリのクラス分類タスクを行う。KV260上で行う
cd ~/Vitis-AI/vai_library/samples/classification
./build.sh
ビルドできたら実行する。この第一引数が実行する時に動かすモデル(今回はresnet18_pt
./test_jpeg_classification resnet18_pt ~/Vitis
-root@xilinx-kv260-starterkit-20222:~/Vitis-AI/examples/vai_library/samples/classification: ./test_jpeg_classification resnet18_pt ~/Vitis-AI/examples/vai_library/samples/classification/images/002.JPEG
WARNING: Logging before InitGoogleLogging() is written to STDERR
I0817 05:13:14.415813 14515 demo.hpp:1193] batch: 0 image: /home/root/Vitis-AI/examples/vai_library/samples/classification/images/002.JPEG
I0817 05:13:14.416261 14515 process_result.hpp:24] r.index 109 brain coral, r.score 0.999698
I0817 05:13:14.416541 14515 process_result.hpp:24] r.index 955 jackfruit, jak, jack, r.score 0.000203407
I0817 05:13:14.416728 14515 process_result.hpp:24] r.index 973 coral reef, r.score 5.82771e-05
I0817 05:13:14.416895 14515 process_result.hpp:24] r.index 390 eel, r.score 2.14389e-05
I0817 05:13:14.417037 14515 process_result.hpp:24] r.index 5 electric ray, crampfish, numbfish, torpedo, r.score 7.88694e-06
動いていそう。result.jpgが出来るのでHostPC側に持ってきて確認するとこんな感じ

やってることはこの辺呼び出しているだけなので、ここを変えれば実行したいアプリケーションを変えられそう。
↓のcpp変えれば任意のCPU処理追加したりとかモデルの順次実行とかできそう
Lane検出タスク
ついでに他のsampleも実行。既にResnet以外のモデルもSD Imageに入っている。
ここではプルーニングしたVpgNetをDNNモデルとして使っている
cd ../lanedetect
./build.sh
root@xilinx-kv260-starterkit-20222:~/Vitis-AI/examples/vai_library/samples/lanedetect: ./test_jpeg_lanedetect vpgnet_pruned_0_99 sample_lanedetect.jpg
こんな感じになればok
root@xilinx-kv260-starterkit-20222:~/Vitis-AI/examples/vai_library/samples/lanedetect# ./test_jpeg_lanedetect vpgnet_pruned_0_99 sample_lanedetect.jpg
WARNING: Logging before InitGoogleLogging() is written to STDERR
I0817 05:27:53.812021 15245 demo.hpp:1193] batch: 0 image: sample_lanedetect.jpg
I0817 05:27:53.812251 15245 process_result.hpp:26] lines.size 5
I0817 05:27:53.812287 15245 process_result.hpp:28] line.points_cluster.size() 137
I0817 05:27:53.813519 15245 process_result.hpp:28] line.points_cluster.size() 89
I0817 05:27:53.814342 15245 process_result.hpp:28] line.points_cluster.size() 169
I0817 05:27:53.815778 15245 process_result.hpp:28] line.points_cluster.size() 33
I0817 05:27:53.816092 15245 process_result.hpp:28] line.points_cluster.size() 41

動いてそう
おわりに
これで一通りのモデルの量子化&デプロイ、アプリケーションの基礎的な使い方をおさらいした
ZynqでDPU IPを使うと使い勝手的にはNPUに近い印象を受ける
Discussion