Pythonの並行処理を理解したい [マルチスレッド編]
Python の並行処理についてまとめてみました。
並行処理とは?
並行処理(Concurrent)とは、一定の時間内に複数の処理を同時に進行することを指す用語です。
例えば、コーディング中にアプリのビルドを実行しながら Twitter を見るのもコーディングと Twitter の並行処理です。
並行処理と並列処理の違い
並行処理と類似する処理として、並列処理(Parallel)があります。
2 つの違いを簡単にまとめます。
並行処理(Concurrent)
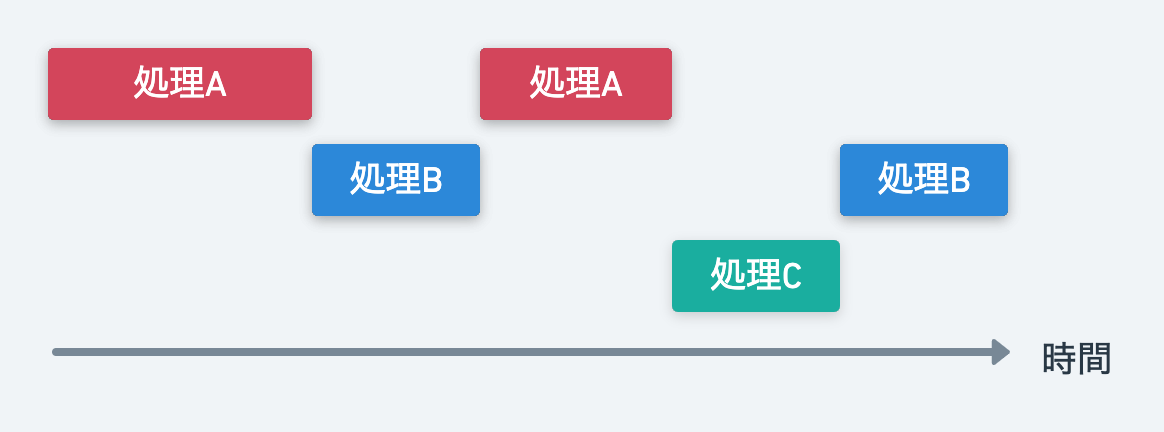
並行処理は瞬間を切り取ったときには 1 つの処理をしているのですが、ある一定の時間でみると処理を切り替えながら複数の処理をこなしているものを指します。
Python では今から説明するマルチスレッド(ThreadPoolExecutor)とイベントループ(asyncio)がこれに当たります。
並行処理での高速化は複数 API のアクセスや、ファイル書き込みなど I/O の待ち時間が発生するものに向いています。
並列処理(Parallel)
並列処理は瞬間を切り取ったときにも複数の処理を同時に実行しているものを指します。
Python でいうと複数コアでのマルチプロセス(ProcessPoolExecutor)がこれに当たります。
並列処理での高速化は暗号の復号化など CPU パワーを使うものに向いています。

Pythonのマルチスレッド処理(ThreadPoolExecutor)
マルチスレッドはその名の通り、プロセスから複数のスレッドを作り処理を並行して行うものです。
Python のマルチスレッドは concurrent.futures モジュールの ThreadPoolExecutor クラスを使います。
コンテキストマネージャで取得出来る ThreadPoolExecutor のインスタンスに対して submit()を呼びマルチスレッドで行いたい関数を登録します。
with ThreadPoolExecutor() as executor
feature = executor.submit(<マルチスレッドで実行したい関数>)
submit の戻値に対してresult()を呼ぶことで関数の処理結果を取得出来ます。
result = feature.result() # submitした関数の結果を取得
他にも実行中の状態を確認するrunning()やdone()、実行をキャンセルするcancelled()などがあります。
import time
from concurrent.futures import ThreadPoolExecutor
def foo():
time.sleep(3)
return 'fooo'
with ThreadPoolExecutor() as executor:
feature = executor.submit(foo)
print(feature.running()) # True
print(feature.done()) # False
feature.cancelled() # 処理のキャンセル
print(feature.running()) # False
print(feature.done()) # True
逐次処理とマルチスレッドの実行速度比較
マルチスレッドの効果検証のために、逐次処理とマルチスレッドで実行速度を比較してみます。
下準備
時間のかかる I/O 処理のモックとなる関数を作ります。
call_slow_requestは time.sleep(3) を使っているので 3 秒の実行時間がかかる処理です。
def call_slow_request():
time.sleep(3)
return 'ok'
また、処理時間の計測をしたいので専用のデコレータを作ります。
実行関数にprocessing_timeのデコレータをつけることで関数の実行時間が出力されます。
def processing_time(func):
@wraps(func)
def wrapper(*args, **keywords):
st = time.time() # 開始前の時間を記録
result = func(*args, **keywords) # 関数を実行
print(f'time: {time.time() - st} s') # 開始後の時間と開始前の時間の差を出力
return result
return wrapper
逐次処理での実行
まず逐次処理です。run_sequentialでcall_slow_requestを 3 回実行しています。
from util import (call_slow_request, processing_time)
@processing_time
def run_sequential():
for arg in range(3):
print(call_slow_request())
if __name__ == '__main__':
run_sequential()
3 秒待つ処理を 3 回順番に実行しているので、run_sequentialの実行時間をは 9 秒弱となります。
$ python3 run_sequential.py
ok
ok
ok
time: 9.011210680007935 s
マルチスレッドで実行
次にマルチスレッドです。
ThreadPoolExecutorを使ってcall_slow_requestを 3 回実行しています。
from concurrent.futures.thread import ThreadPoolExecutor
from util import (call_slow_request, processing_time)
@processing_time
def run_concurrent():
with ThreadPoolExecutor() as executor:
features = [executor.submit(call_slow_request) for _ in range(3)]
for feature in features:
print(feature.result())
if __name__ == "__main__":
run_concurrent()
逐次処理と比べて大幅に高速化しているのが分かると思います。
$ python3 concurrent-demo.py
ok
ok
ok
time: 3.0046510696411133 s
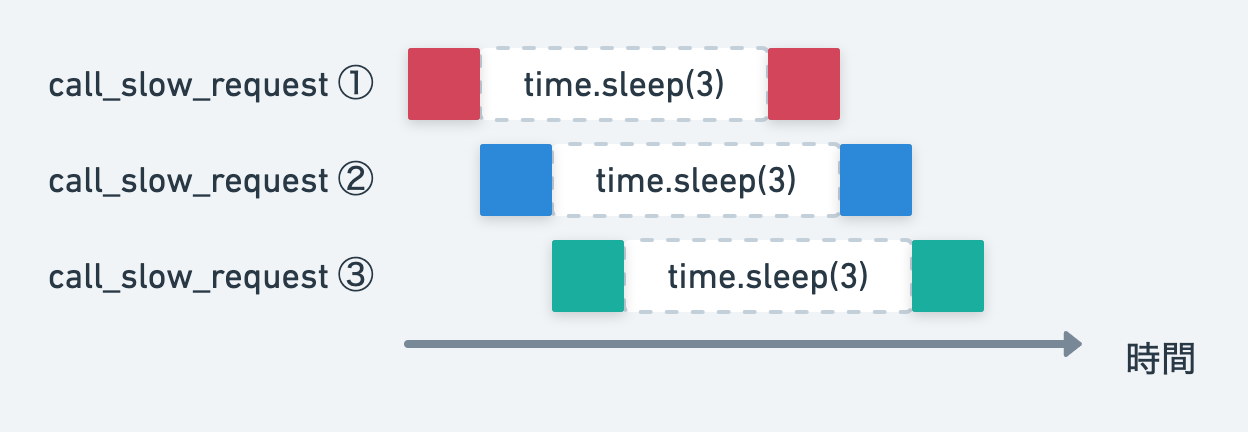
これは処理がスレッドに分かれて並行に実行されるからです。
call_slow_requestのtime.sleep(3)に処理に入った段階で、次のスレッドに処理が移るのでほぼ sleep に指定した秒数とタイムラグなく処理を完了できます。
スレッドセーフとロック
並行処理についてまわる問題としてスレッドセーフがあります。
マルチスレッドで処理を並行実行する際に、共通した値をそれぞれのスレッドが読み書きするなどスレッドセーフではない処理を挟んでしまうとバグの原因になります。
スレッドセーフではない処理の例と、その対処(ロック)についてまとめます。
スレッドセーフではない処理
以下は、Counterというクラスのインスタンス変数をカウントアップする処理です。スレッドセーフではないので、マルチスレッドで処理すると想定通りの値にならず実行ごとに計算結果が変わってしまいます。
from concurrent.futures import (ThreadPoolExecutor, wait)
class Counter:
def __init__(self):
self.count = 0
def count_up_to_1000000(self):
for _ in range(1_000_000):
self.count += 1
def worker(counter):
counter.count_up_to_1000000()
def main():
counter = Counter()
with ThreadPoolExecutor() as executor:
features = [executor.submit(worker, counter) for _ in range(3)]
print(counter.count)
if __name__ == '__main__':
main()
# 300000 0にならない!!!
$ python3 thread_safe.py
1848519
$ python3 thread_safe.py
1802127
$ python3 thread_safe.py
1702320
これは self.countをインクリメントする際の値読み取り中にスレッドが切り替わり、複数スレッドで同じ値に同時にアクセスすることで不整合な状態となってしまうためです。
改善(ロックの導入)
これを改善するためには、インクリメント中にスレッドの排他制御(ロック)をする必要があります。
改善コードはこちらです。出力も想定の 3000000 になっています。
import threading
from concurrent.futures import (ThreadPoolExecutor, wait)
class Counter:
lock = threading.Lock()
def __init__(self):
self.count = 0
def count_up_to_1000000(self):
for _ in range(1_000_000):
with self.lock:
self.count += 1
def worker(counter):
counter.count_up_to_1000000()
def main():
counter = Counter()
with ThreadPoolExecutor() as executor:
features = [executor.submit(worker, counter) for _ in range(3)]
print(counter.count)
if __name__ == '__main__':
main()
$ python3 thread_sage.py
3000000
Counter クラスの中でLockインスタンスを作り、カウントアップをLockインスタンスのコンテキストマネージャ内で実行しています。
with self.lock:のブロック内で行われる処理はロックがかかるので、カウントアップ時の複数スレッドでの値共有という不具合の原因が解消されます。
終わりに
以上「Python の並行処理を理解したい [マルチスレッド編]」でした。
マルチスレッド以外にも、マルチプロセス、イベントループと他の並行処理もあるので続編も書いていきたいです。
参考
ほぼこちらの書籍で学んだ内容です。良書ありがとうございます🙏
Discussion